一、使用官方的log类型,通过改造challenge来实现parallel的功能,实现对同一个index进行读写混合的测试需求
{
"name": "append-no-conflicts",
"description": "Indexes the whole document corpus using Elasticsearch default settings. We only adjust the number of replicas as we benchmark a single node cluster and Rally will only start the benchmark if the cluster turns green. Document ids are unique so all index operations are append only. After that a couple of queries are run.",
"default": true,
"schedule": [
{
"operation": "delete-index"
},
{
"operation": {
"operation-type": "create-index",
"settings": {{index_settings | default({}) | tojson}}
}
},
{
"name": "check-cluster-health",
"operation": {
"operation-type": "cluster-health",
"index": "logs-*",
"request-params": {
"wait_for_status": "{{cluster_health | default('green')}}",
"wait_for_no_relocating_shards": "true"
},
"retry-until-success": true
}
},
{
"parallel": {
"completed-by": "index-append", #表示当index-append完成时结束并发
"tasks": [
{
"operation": "index-append",
"warmup-time-period": 240,
"clients": {{bulk_indexing_clients | default(8)}}
},
{
"operation": "default",
"clients": 1,
"warmup-iterations": 500,
"iterations": 100,
"target-throughput": 8
},
{
"operation": "term",
"clients": 1,
"warmup-iterations": 500,
"iterations": 100,
"target-throughput": 50
},
{
"operation": "range",
"clients": 1,
"warmup-iterations": 100,
"iterations": 100,
"target-throughput": 1
},
{
"operation": "hourly_agg",
"clients": 1,
"warmup-iterations": 100,
"iterations": 100,
"target-throughput": 0.2
},
{
"operation": "scroll",
"clients": 1,
"warmup-iterations": 100,
"iterations": 200,
"#COMMENT": "Throughput is considered per request. So we issue one scroll request per second which will retrieve 25 pages",
"target-throughput": 1
}
]
}
}
]
},
二、根据实际业务日志来生成data和track使性能测试结果更加贴合实际业务
1、从已有集群中的数据自动生成log和track
esrally版本要求2.0以上
参考:https://esrally.readthedocs.io/en/2.1.0/adding_tracks.html?highlight=custom
esrally create-track --track=acme --target-hosts=127.0.0.1:9200 --indices="products,companies" --output-path=~/tracks
最终生成效果:

airkafka_pm02_2021-02-01-documents-1k.json:xxx-1k表示用于test_mode模式,数据量较小,用于测试
airkafka_pm02_2021-02-01.json:是对应log的index
airkafka_pm02_2021-02-01-documents.json.offset:log日志偏移量
{
"version": 2,
"description": "Tracker-generated track for nsh",
"indices": [
{
"name": "airkafka_pm02_2021-02-12",
"body": "airkafka_pm02_2021-02-12.json", #可以改成track.json所在目录下的其他自定义的index
"types": ["doc"] #由于es7以上版本不支持type字段,因此生成的track.json没有该字段。如果是对es7以下版本进行测试,需要增加该字段
},
{
"name": "airkafka_pm02_2021-02-01",
"body": "airkafka_pm02_2021-02-12.json",
"types": ["doc"]
}
],
"corpora": [
{
"name": "nsh",
"target-type": "doc", #该字段对应的是bulk插入的_type字段,必须要指定,不然会报type missing的错误
"documents": [
{
"target-index": "airkafka_pm02_2021-02-12",
"source-file": "airkafka_pm02_2021-02-12-documents.json.bz2",
"document-count": 14960567,
"compressed-bytes": 814346714,
"uncompressed-bytes": 12138377222
},
{
"target-index": "airkafka_pm02_2021-02-01",
"source-file": "airkafka_pm02_2021-02-01-documents.json.bz2",
"document-count": 24000503, #需要跟实际的documents文件里的数量一致
"compressed-bytes": 1296215463,
"uncompressed-bytes": 19551041674
}
]
}
],
"operations": [ #自动生成的track.json里不会区分operatin和challenge,可以自己拆分定义,按照这个模板来就行
{
"name": "index-append",
"operation-type": "bulk",
"bulk-size": {{bulk_size | default(5000)}},
"ingest-percentage": 100,
"corpora": "nsh" #要改成上面corpora的name
},
{
"name": "default", #name可以改成其他自定义的
"operation-type": "search", #operation-type只支持search
"index": "airkafka_pm02_2021-*",
"body": {
"query": {
"match_all": {}
}
}
},
{
"name": "term",
"operation-type": "search",
"index": "airkafka_pm02_2021-*", #index也可以自定义
"body": { #body里的query语句可以根据业务需求自定义
"query": {
"term": {
"log_id.raw": {
"value": "gm_client_app_profile_log"
}
}
}
}
},
{
"name": "range",
"operation-type": "search",
"index": "airkafka_pm02_2021-*",
"body": {
"query": {
"range": {
"deveice_level": {
"gte": 0,
"lt": 3
}
}
}
}
},
{
"name": "hourly_agg",
"operation-type": "search",
"index": "airkafka_pm02_2021-*",
"body": {
"size": 0,
"aggs": {
"by_hour": {
"date_histogram": {
"field": "@timestamp",
"interval": "hour"
}
}
}
}
},
{
"name": "scroll",
"operation-type": "search",
"index": "airkafka_pm02_2021-*",
"pages": 25,
"results-per-page": 1000,
"body": {
"query": {
"match_all": {}
}
}
}
],
"challenges": [ #可以自定义多个不同的challenge,然后命令行里指定需要运行的challenge
{
"name": "append-no-conflicts",
"description": "Indexes the whole document corpus using Elasticsearch default settings. We only adjust the number of replicas as we benchmark a single node cluster and Rally will only start the benchmark if the cluster turns green. Document ids are unique so all index operations are append only. After that a couple of queries are run.",
"default": true,
"schedule": [
{
"operation": "delete-index"
},
{
"operation": {
"operation-type": "create-index",
"settings": {}
}
},
{
"name": "check-cluster-health",
"operation": {
"operation-type": "cluster-health",
"index": "airkafka_pm02_2021-*",
"request-params": {
"wait_for_status": "green",
"wait_for_no_relocating_shards": "true"
},
"retry-until-success": true
}
},
{
"parallel": {
"completed-by": "index-append",
"tasks": [
{
"operation": "index-append",
"warmup-time-period": 240,
"clients": {{bulk_indexing_clients | default(8)}}
},
{
"operation": "default",
"clients": 1,
"warmup-iterations": 500,
"iterations": 100,
"target-throughput": 8 #限定最大的tps,类似于jmeter里的目标加压。此时service time和letency的大小不一致,service time小于letency,真正具有参考意义的是service time
},
{
"operation": "term",
"clients": 1,
"warmup-iterations": 500,
"iterations": 100,
"target-throughput": 50
},
{
"operation": "range",
"clients": 1,
"warmup-iterations": 100,
"iterations": 100,
"target-throughput": 1
},
{
"operation": "hourly_agg",
"clients": 1,
"warmup-iterations": 100,
"iterations": 100,
"target-throughput": 0.2
},
{
"operation": "scroll",
"clients": 1,
"warmup-iterations": 100,
"iterations": 200,
"#COMMENT": "Throughput is considered per request. So we issue one scroll request per second which will retrieve 25 pages",
"target-throughput": 1
}
]
}
}
]
},
{
"name": "append-no-conflicts-index-only",
"description": "Indexes the whole document corpus using Elasticsearch default settings. We only adjust the number of replicas as we benchmark a single node cluster and Rally will only start the benchmark if the cluster turns green. Document ids are unique so all index operations are append only.",
"schedule": [
{
"operation": "delete-index"
},
{
"operation": {
"operation-type": "create-index",
"settings": {}
}
},
{
"name": "check-cluster-health",
"operation": {
"operation-type": "cluster-health",
"index": "airkafka_pm02_2021-*",
"request-params": {
"wait_for_status": "green",
"wait_for_no_relocating_shards": "true"
},
"retry-until-success": true
}
},
{
"operation": "index-append",
"warmup-time-period": 240,
"clients": 8
},
{
"name": "refresh-after-index",
"operation": "refresh"
},
{
"operation": {
"operation-type": "force-merge",
"request-timeout": 7200
}
},
{
"name": "refresh-after-force-merge",
"operation": "refresh"
},
{
"name": "wait-until-merges-finish",
"operation": {
"operation-type": "index-stats",
"index": "_all",
"condition": {
"path": "_all.total.merges.current",
"expected-value": 0
},
"retry-until-success": true,
"include-in-reporting": false
}
}
]
}
]
}
"target-throughput": 50 #不指定则表示esrally尽最大可能发送消息,即测最大的性能,指定则是按照指定的tps发送。注意,如果指定,service time和letency是不一样的,letency要大于service time,实际的es性能需要看service time
在自定义track的时候出现的一些错误以及解决办法
1、https://discuss.elastic.co/t/esrally-got-the-benchmark-ended-already-during-warmup-when-running-custom-track/186076/3
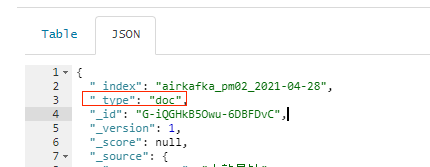
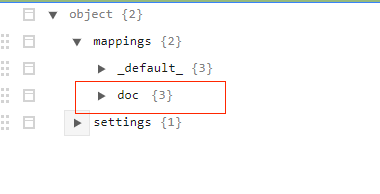
2、--on-error=abort 打开该开关,esrally将会在第一次出错时就停止,同时记录错误日志,建议调试tracks打开
3、在调试track的时候,把bulk_size设置小一点,这样error时同样的日志会比较少,方便查看完整日志

4、service time和letency的区别
