RocketMQ的具体消息存储结构是怎样的呢?如何尽量保证顺序写的呢?先来看看整体的架构图,
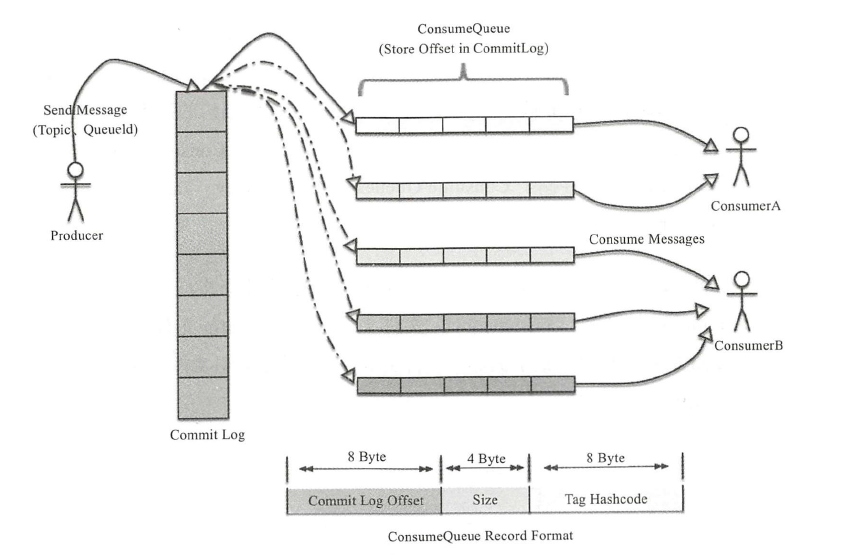
RocketMQ消息的存储是由ConsumeQueue和CommitLog配合完成的,消息真正的物理存储文件是
CommitLlog,ConsumeQueue是消息的逻辑队列,类似数据库的索引文件,存储的是指向物理存储的地址。
每个Topic下的每个Message Queue都有一个对应的ConsumeQueue文件。文件地址在${$storeRoot}consu
-mequeue${topicName}${queueId}${fileName}。
例如:有一个broker_a,有4个写队列queue0-4,4个读队列queue0-4,这是有两个producer,producer A
发送topic_A 消息,producer B 发送topic_B消息;producer A和producer B属于不同的
consumerGroup(相同会异常 https://www.cnblogs.com/toUpdating/p/10009218.html),这时对于producer A来说
发现有queue0-4都可以发送消息,topic_A对应queue0-4,consumequeue为${$storeRoot}consumequeue opic_Aqueue0-4${fileName}
对于producer B来说,因为producer A和producer B不属于同一group,相互不影响,topic_B也对应queue0-4,
consumequeue为${$storeRoot}consumequeue opic_Bqueue0-4${fileName},
以队列queue0的角度来看,即收到topic_A的消息,有接受到topic_B的消息,最终按照收到的顺序保存到commitLog中,consumequeue中则保存着相应的索引。
CommitLog以物理文件的方式存放,每台Broker上的CommitLog被本机器所有ConsumeQueue共享,
文件,文件地址:${user.home}store${commitlog}${fileName}。在CommitLog中,一个消息的存储长度
是不固定的,RocketMQ采取一些机制,尽量向CommitLog中顺序写,但是随机读。ConsumeQueue的内容
也会被写到磁盘里作持久存储。
存储机制这样设计有以下几个好处:
1)CommitLog顺序写,可以大大提高写入效率。
2)虽然是随机读,但是利用操作系统的pagecache机制,可以批量地从磁盘读取,作为cache存到
内存中,加速后续的读取速度。
3)为了保证完全的顺序写,需要ConsumeQueue这个中间结构,因为ConsumeQueue里只存偏移量
信息,所以尺寸是有限的,在实际情况中,大部分的ConsumeQueue能够被全部读入内存,所以这个中间
结构的操作速度很快,可以认为是内存读取的速度。此外为了保证CommitLog和ConsumeQueue的一致性,
CommitLog里存储了Consume Queues、Message Key、Tag等所有信息,即使ConsumeQueue丢失,也可
以通过commitLog完全恢复出来。
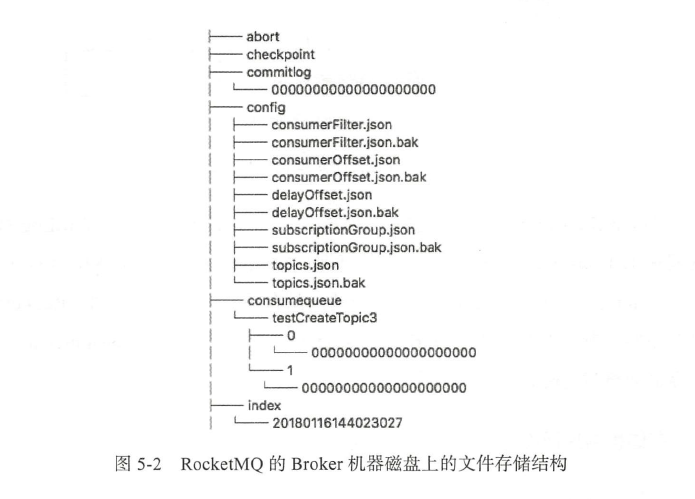
如下图所示是一个Broker在文件系统中存储的各个文件。我们可以看到commitlog文件夹、consume
-queue文件夹、还有在config文件夹中Topic、Consumer的相关信息。最下面那个文件夹index存的是索引
文件,这个文件用来加快消息查询的速度。