关注点:
(1)主题模型的应用
(2)文献计量学的实际应用,预测方法
Time gap analysis by the topic model-based temporal technique
使用LDA模型来确定不同资源类型的时间窗划分方法。
Classification of individual articles from all of science by research level
单篇论文分类,但是分的不是学科,而是基础研究和应用研究,一共涉及4个类,学习一下方法。
(假定:应用研究引用基础研究;基础研究引用基础研究)
Forecasting research trends using population dynamics model with Burgers’ type interaction
预测主题趋势,详细看下。
Conceptualizing the interdisciplinary diffusion and evolution of emerging fields: The case of systems biology
学科演化,看摘要好像内容一般,粗略看下
Research dynamics: Measuring the continuity and popularity of research topics
通过主题持续性和流行性来(topic continuity and topic popularity)测度主题演化,这两个词翻译不好,觉得类似于“经典歌曲”和“流行歌曲”的味道,但是还有点小区别吧。
下面在具体介绍过程中仍用原表述(topic continuity and topic popularity)。
文献综述
作者在研究综述中将之前的识别主题演化的方法分为2类:
1、基于网络的方法(Network-based approaches)
基于网络的方法多采用共现方法,对文章、期刊、研究领域等内容进行分析,然后再用聚类方法进行识别。
该方法大多是对“单一时间段内”的主题进行分析,所得到的只是一个时间段内的“快照(snapshot)”。最近呢,也有一些研究对多个时间窗进行分析,作者也说明了这些方法的缺点(个人觉得说的有点牵强),例如
不同的时间窗差别很大,缺少完整的验证;同时,该方法多以经验为主,缺乏领域专家对结果的解释(不能理解)。
2、 主题模型方法(Topic modeling approaches)
主要介绍了LDA的用来识别主题演化的方法(这些方法在博主之前的一篇论文中也有详细说明,详见《主题模型在主题演化方法中的应用研究进展》)。
作者的方法
1、识别主题
作者使用Author-Conference-Topic (ACT)方法来识别主题(ACT方法我还没用看,下面的理解是根据LDA方法的结果的理解,如果错误请指出。)
通过ACT可以计算得到每个词在每个文档中的概率分布情况。例如主题“干细胞”在文档A中的概率是0.1,在文档B中的概率是0.05,在C中的概率是 ...... 等,那么用主题(主题由一堆语义相关的词构成,由LDA直接生成)在所有文档上的概率的平均值来表示 topic popularity,如果这个平均值越大,则该主题就表现的越明显。为了确定popularity的标准,作者用 “1/主题的个数” 来作为一个基准,大于该值则是more popular topic,小于该值则是less visible topic。当然,这些计算都是在一个时间窗内,如果我们把所有数据集分成了20个时间窗,则我们要运行ACT模型20次,然后计算每个主题的popularity。
上述方法的一个问题就是如何确定不同时间窗内的主题是不是一个主题,也就是“主题关联”,这样才能计算一个主题在不同时间窗内的变化,因为不同时间窗内的词不同,因此不能直接计算两个时间窗内的主题相似度,为了解决这个问题,作者将所有时间窗内的所有词都加入到了每个时间窗中,对于原本不存在的词,将其概率设置为0。
作者计算不同时间窗的主题间相似度使用的方法是JS距离(Jensen–Shannon divergence, JSD),JSD通常在文本挖掘中计算多个概率分布之间的信息熵,其实是对KL距离进行对称和平滑的处理(KL距离是非对称的。关于JS距离和KL距离,R语言里面的许多包都提供这种方法,一句命令轻松搞定 ^^)。
具体计算方法如下:

得到计算结果后,如果距离越小,则两个主题越相似,因此对于每个主题i来说,找到之后相邻时间窗中与其JS距离最近的另一个主题j,则认为主题i和主题j是相关的,或者认为二者是一个主题,通过这种方式,可以得到一个主题在所有时间段内的演化路径。
作者将 topic continuity分为了6种类型: steady, concentrating, diluting,sporadic, transforming, and emerging topics;Topic popularity 被分为3类: rising, declining, and fluctuating。用来反映不用形式的主题演化。
并给出了确定不同类型的方法。
(1)首先计算每个主题在每个时间窗的斜率(slope)
(2)计算每个主题的z score
(3)根据如下标准确定主题的类型。
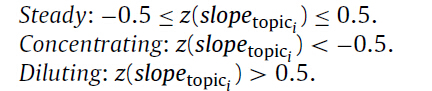
Content-based author co-citation analysis
基于内容的共被引分析,考虑了作者引用的句子的相似度。
Mapping altruism
利他主义全景图,研究非盈利组织的领域分布地图,比较有意思,视角独特,值得一看。

http://www.citnetexplorer.nl/Home
一个新的文献分析可视化工具