1 SUN RGB-D
论文:SUN RGB-D: A RGB-D Scene Understanding Benchmark Suite
数据集地址:http://3dvision.princeton.edu/projects/2015/SUNrgbd/
简介:用于室内场景理解的RGBD数据集。
数据:共10335张RGBD图像。来源于自己采集(3784+1159张),NYU Depth V2数据集(1449张),Berkeley B3DO数据集挑选(554张),SUN3D视频中挑选(3389张)。采集设备包括Intel Realsense,Asus Xtion,Kinect v1,Kinect v2。
标注:除了NYU数据集中的分割标注被直接采用,其他所有图像都进行了重新标注。
任务:
- 场景分类(Scene Categorization):对给定的一张RGBD图片所在场景进行分类。
- 语义分割(Semantic Segmentation):对RGB-D图像中的每一个像素的语义标签进行预测。
- 物体检测(Object Detection):2D和3D的物体检测。
- 物体朝向预测(Object Orientation):预测物体bounding box的方向,由于预先进行了对齐,所有只有一个自由度的偏向角。

- 房间布局预测(Room Layout Estimation):场景的空间布局预测,用于推测自由空间。

- 场景完全理解(Total Scene Understanding):预测整个场景中的3D物体和空间布局。

2 SUN3D
论文:SUN3D: A Database of Big Spaces Reconstructed using SfM and Object Labels
数据集地址:http://sun3d.cs.princeton.edu/
简介:用于室内场景理解的RGBD视频数据集。
数据:共415段视频序列,取自41个不同建筑内的254个不同的空间。
标注:相机位姿,视频实例分割标注。先通过SFM获取初始相机位姿;然后进行视频物体标注,具体做法是利用估计的初始位姿和补全的深度图(TSDF方法)对视频中关键帧的标注进行传播,因此只需要手动修正传播错误的部分,降低了对视频标注的工作量;最后利用标注进一步优化修正估计的位姿。
3 ScanNet
论文:ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes
数据集地址:http://www.scan-net.org/
简介:室内场景理解数据集。
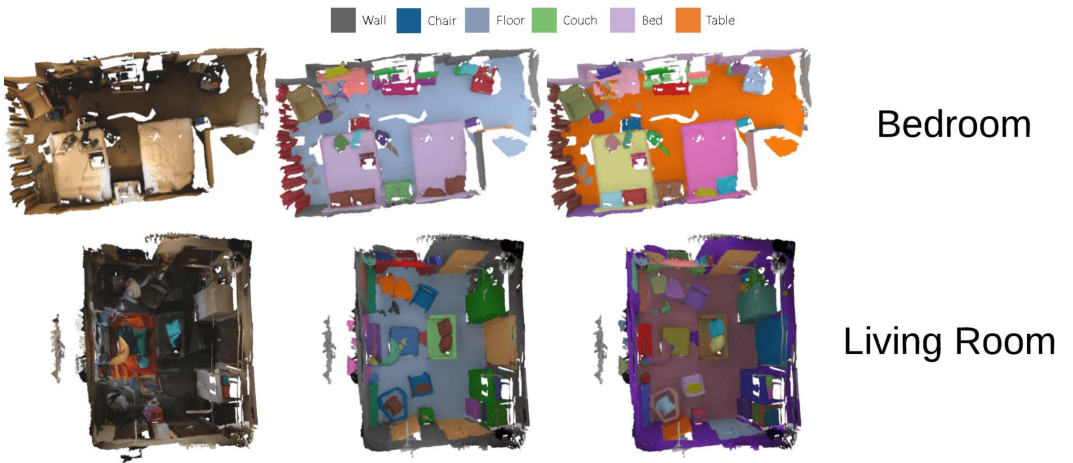
数据:共1513个场景扫描数据。提供了重建的mesh,但是一般都不直接处理mesh。
标注:相机位姿,表面重建和实例级语义分割。
任务:
- 3D物体分类:对给定Bounding box内的物体进行分类。
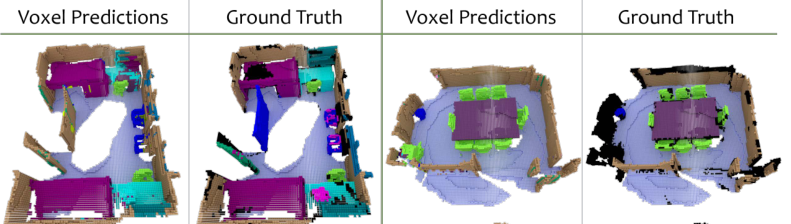
- 语义体素标记:2D语义分割的推广,对每一个体素(voxel)进行语义预测。
- CAD模型检索:给定一个扫描的RGBD物体,检索出相应的CAD模型。这需要学习到两者的几何结构相似性。