1 torch.Tensor
操作函数
torch.cat(tensors, dim=0, *, out=None) → Tensor
torch.chunk(input, chunks, dim=0) → List of Tensors
torch.index_select(input, dim, index, *, out=None) → Tensor
torch.masked_select(input, mask, *, out=None) → Tensor
原位修改
PyTorch中,在对tensor进行操作的一个函数后加下划线,则表明这是一个in-place类型函数,直接修改该tensor.
x=torch.tensor([2.])
x.mul_(0.5)
检查模型和数据所在设备:
print(next(model.parameters()).is_cuda)
print(data.device)
复制张量
| Operation | New/Shared memory | Still in computation graph |
|---|---|---|
| tensor.clone() | New | Yes |
| tensor.detach() | Shared | No |
| tensor.detach().clone() | New | No |
总结来说,clone()复制到一块新的内存,保留了原张量的梯度,但因为是新的内存,不受原张量计算的影响;
detach()从计算图中剥离原张量,新的张量不保留梯度计算,但因为与原张量共享内存,所以受原张量计算的影响;
最保险的复制方法就是tensor.detach().clone()。
举个栗子:
x=torch.tensor([1,2,3])
x1=x.clone()
x2=x.detach()
x3=x.detach().clone()
x.add_(1)
# x: tensor([2, 3, 4])
# x1: tensor([1, 2, 3])
# x2: tensor([2, 3, 4])
# x3: tensor([1, 2, 3])
x=x.float().requires_grad_()
x1=x.clone()
x2=x.detach()
x3=x.detach().clone()
# x: tensor([2., 3., 4.], requires_grad=True)
# x1: tensor([2., 3., 4.], grad_fn=<CloneBackward>)
# x2: tensor([2, 3, 4])
# x3: tensor([2, 3, 4])
2 torch.nn
模型保存与加载
- 训练时每个epoch都保存模型,一般保存最好模型和当前epoch模型
net.cuda()和torch.nn.DataParallel()两者的顺序不影响- 如果保存的模型是多GPU训练的,则
load_state_dict()之前必须使用torch.nn.DataParallel() load_state_dict(, strict=False)只会加载键值相同的参数
上采样
- 上采样用
torch.nn.functional.interpolate,torch.nn.functional.upsample被淘汰
3 平衡GPU多卡的显存占用
参考方法
修改前:
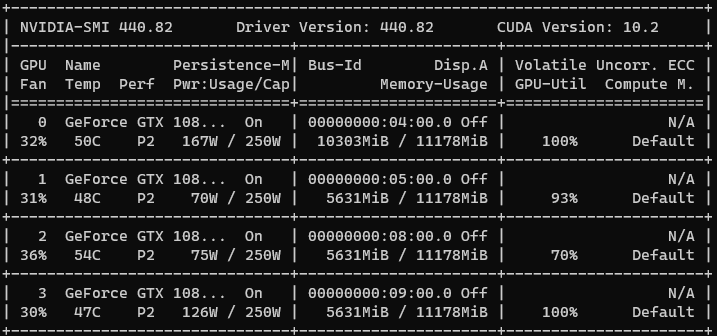
修改后:
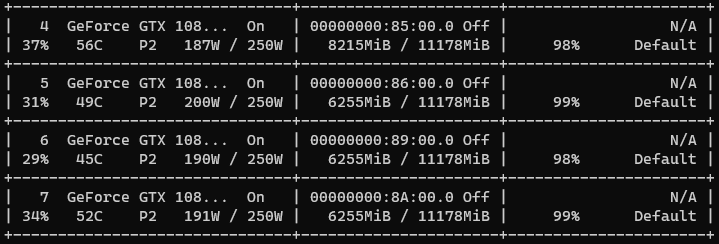
4 跨卡同步BN
跨卡同步 Batch Normalization 也称为 SyncBN。因为现有的标准 Batch Normalization 因为使用数据并行(Data Parallel),是单卡的实现模式,只对单个卡上对样本进行归一化,相当于减小了批量大小(batch-size)。 对于比较消耗显存的训练任务时,往往单卡上的相对批量过小,影响模型的收敛效果。 跨卡同步 Batch Normalization 可以使用全局的样本进行归一化,这样相当于‘增大‘了批量大小,这样训练效果不再受到使用 GPU 数量的影响。 最近在图像分割、物体检测的论文中,使用跨卡BN也会显著地提高实验效果,所以跨卡 BN 已然成为竞赛刷分、发论文的必备神器。
深度学习平台在多卡(GPU)运算的时候都是采用的数据并行(DataParallel),如下图:
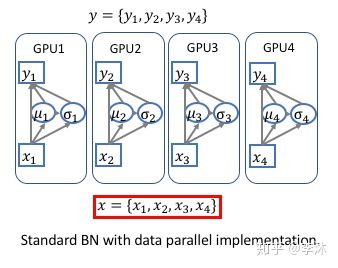
每次迭代,输入被等分成多份,然后分别在不同的卡上前向(forward)和后向(backward)运算,并且求出梯度,在迭代完成后合并 梯度、更新参数,再进行下一次迭代。因为在前向和后向运算的时候,每个卡上的模型是单独运算的,所以相应的Batch Normalization 也是在卡内完成,所以实际BN所归一化的样本数量仅仅局限于卡内,相当于批量大小(batch-size)减小了。跨卡同步BN的关键是在前向运算的时候拿到全局的均值和方差,在后向运算时候得到相应的全局梯度。
参考:跨卡同步 Batch Normalization
5 避免在gpu上操作tensor
尽量在cpu上进行tensor的操作,一旦转移到gpu上,很多错误非常难调试。
如下:
>>> x=torch.tensor([0,0,0,1,1,1])
>>> x=x.cuda()
>>> y=torch.tensor([4,6,3,7,10])
>>> x[y]
tensor([1, 0, 1, 0, 0], device='cuda:0')
甚至连index越界都不进行检查报错!!使用前面提到的torch.index_select也无法解决,但是在cpu上就会提示越界错误。
6 模型eval模式下结果远差于train模式
eval模式和train模式不同之处在于Batch Normalization和Dropout。
Dropout比较简单,在train时会丢弃一部分连接,在eval时则不会。
Batch Normalization,在train时不仅使用了当前batch的均值和方差,也使用了历史batch统计上的均值和方差,并做一个加权平均(momentum参数)。在test时,由于此时batchsize不一定一致,因此不再使用当前batch的均值和方差,仅使用历史训练时的统计值。
设置track_running_stats为False,是完全不跟踪之前的均值和方差,相当于将动量设置成了1,历史系数设置为0,此时bn层的均值和方差完全就是当前BATCH的均值和方差。然而正常训练肯定是不推荐这样做的,因为batch再大,一个batch内的数据分布情况也不可能完全代表整个数据集,所以在训练的时候还是要设置track_running_stats为true,让bn层的均值和方差能随着训练进行变化,但这个变化幅度不能过大,这就要求每个batch的数据都具有几乎相同的均值和方差,这就需要通过z-score标准化来进行,而不是归一化。
https://blog.csdn.net/yucong96/article/details/88652964
https://blog.csdn.net/LoseInVain/article/details/86476010