本文为原创,转载请注明:http://www.cnblogs.com/tolimit/
引言
之前的文章已经将调度器的数据结构、初始化、加入进程都进行了分析,这篇文章将主要说明调度器是如何在程序稳定运行的情况下进行进程调度的。
系统定时器
因为我们主要讲解的是调度器,而会涉及到一些系统定时器的知识,这里我们简单讲解一下内核中定时器是如何组织,又是如何通过通过定时器实现了调度器的间隔调度。首先我们先看一下内核定时器的框架
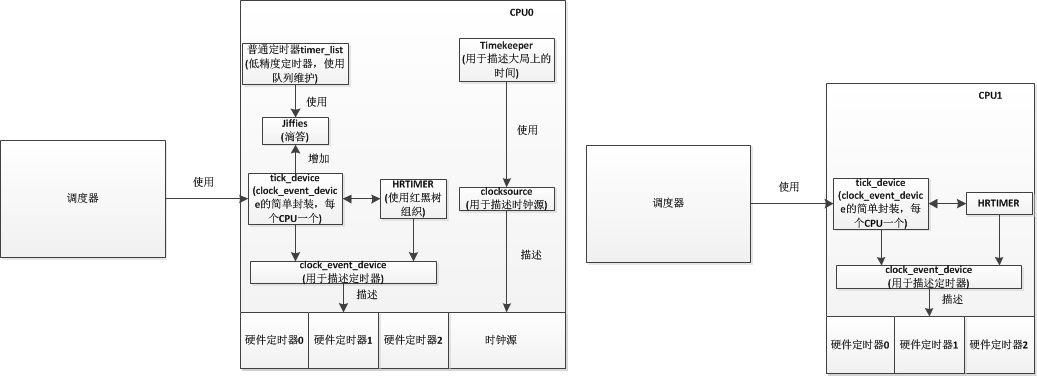
在内核中,会使用strut clock_event_device结构描述硬件上的定时器,每个硬件定时器都有其自己的精度,会根据精度每隔一段时间产生一个时钟中断。而系统会让每个CPU使用一个tick_device描述系统当前使用的硬件定时器(因为每个CPU都有其自己的运行队列),通过tick_device所使用的硬件时钟中断进行时钟滴答(jiffies)的累加(只会有一个CPU负责这件事),并且在中断中也会调用调度器,而我们在驱动中常用的低精度定时器就是通过判断jiffies实现的。而当使用高精度定时器(hrtimer)时,情况则不一样,hrtimer会生成一个普通的高精度定时器,在这个定时器中回调函数是调度器,其设置的间隔时间同时钟滴答一样。
所以在系统中,每一次时钟滴答都会使调度器判断一次是否需要进行调度。
时钟中断
当时钟发生中断时,首先会调用的是tick_handle_periodic()函数,在此函数中又主要执行tick_periodic()函数进行操作。我们先看一下tick_handle_periodic()函数:
1 void tick_handle_periodic(struct clock_event_device *dev) 2 { 3 /* 获取当前CPU */ 4 int cpu = smp_processor_id(); 5 /* 获取下次时钟中断执行时间 */ 6 ktime_t next = dev->next_event; 7 8 tick_periodic(cpu); 9 10 /* 如果是周期触发模式,直接返回 */ 11 if (dev->mode != CLOCK_EVT_MODE_ONESHOT) 12 return; 13 14 /* 为了防止当该函数被调用时,clock_event_device中的计时实际上已经经过了不止一个tick周期,这时候,tick_periodic可能被多次调用,使得jiffies和时间可以被正确地更新。 */ 15 for (;;) { 16 /* 17 * Setup the next period for devices, which do not have 18 * periodic mode: 19 */ 20 /* 计算下一次触发时间 */ 21 next = ktime_add(next, tick_period); 22 23 /* 设置下一次触发时间,返回0表示成功 */ 24 if (!clockevents_program_event(dev, next, false)) 25 return; 26 /* 27 * Have to be careful here. If we're in oneshot mode, 28 * before we call tick_periodic() in a loop, we need 29 * to be sure we're using a real hardware clocksource. 30 * Otherwise we could get trapped in an infinite(无限的) 31 * loop, as the tick_periodic() increments jiffies, 32 * which then will increment time, possibly causing 33 * the loop to trigger again and again. 34 */ 35 if (timekeeping_valid_for_hres()) 36 tick_periodic(cpu); 37 } 38 }
此函数主要工作是执行tick_periodic()函数,然后判断时钟中断是单触发模式还是循环触发模式,如果是循环触发模式,则直接返回,如果是单触发模式,则执行如下操作:
- 计算下一次触发时间
- 设置下次触发时间
- 如果设置下次触发时间失败,则根据timekeeper等待下次tick_periodic()函数执行时间。
- 返回第一步
而在tick_periodic()函数中,程序主要执行路线为tick_periodic()->update_process_times()->scheduler_tick()。最后的scheduler_tick()函数则是跟调度相关的主要函数。我们在这具体先看看tick_periodic()函数和update_process_times()函数:
1 /* tick_device 周期性调用此函数 2 * 更新jffies和当前进程 3 * 只有一个CPU是负责更新jffies的,其他的CPU只会更新当前自己的进程 4 */ 5 static void tick_periodic(int cpu) 6 { 7 8 if (tick_do_timer_cpu == cpu) { 9 /* 当前CPU负责更新时间 */ 10 write_seqlock(&jiffies_lock); 11 12 /* Keep track of the next tick event */ 13 tick_next_period = ktime_add(tick_next_period, tick_period); 14 15 /* 更新 jiffies计数,jiffies += 1 */ 16 do_timer(1); 17 write_sequnlock(&jiffies_lock); 18 /* 更新墙上时间,就是我们生活中的时间 */ 19 update_wall_time(); 20 } 21 /* 更新当前进程信息,调度器主要函数 */ 22 update_process_times(user_mode(get_irq_regs())); 23 profile_tick(CPU_PROFILING); 24 } 25 26 27 28 29 void update_process_times(int user_tick) 30 { 31 struct task_struct *p = current; 32 int cpu = smp_processor_id(); 33 34 /* Note: this timer irq context must be accounted for as well. */ 35 /* 更新当前进程的内核态和用户态占用率 */ 36 account_process_tick(p, user_tick); 37 /* 检查有没有定时器到期,有就运行到期定时器的处理 */ 38 run_local_timers(); 39 rcu_check_callbacks(cpu, user_tick); 40 #ifdef CONFIG_IRQ_WORK 41 if (in_irq()) 42 irq_work_tick(); 43 #endif 44 /* 调度器的tick */ 45 scheduler_tick(); 46 run_posix_cpu_timers(p); 47 }
这两个函数主要工作为将jiffies加1、更新系统的墙上时间、更新当前进程的内核态和用户态的CPU占用率、检查是否有定时器到期,运行到期的定时器。当执行完这些操作后,就到了最重要的scheduler_tick()函数,而scheduler_tick()函数主要做什么呢,就是更新CPU和当前进行的一些数据,然后根据当前进程的调度类,调用task_tick()函数。这里普通进程调度类的task_tick()是task_tick_fair()函数。
1 void scheduler_tick(void) 2 { 3 /* 获取当前CPU的ID */ 4 int cpu = smp_processor_id(); 5 /* 获取当前CPU的rq队列 */ 6 struct rq *rq = cpu_rq(cpu); 7 /* 获取当前CPU的当前运行程序,实际上就是current */ 8 struct task_struct *curr = rq->curr; 9 /* 更新CPU调度统计中的本次调度时间 */ 10 sched_clock_tick(); 11 12 raw_spin_lock(&rq->lock); 13 /* 更新该CPU的rq运行时间 */ 14 update_rq_clock(rq); 15 curr->sched_class->task_tick(rq, curr, 0); 16 /* 更新CPU的负载 */ 17 update_cpu_load_active(rq); 18 raw_spin_unlock(&rq->lock); 19 20 perf_event_task_tick(); 21 22 #ifdef CONFIG_SMP 23 rq->idle_balance = idle_cpu(cpu); 24 trigger_load_balance(rq); 25 #endif 26 /* rq->last_sched_tick = jiffies; */ 27 rq_last_tick_reset(rq); 28 } 29 30 31 32 33 /* 34 * CFS调度类的task_tick() 35 */ 36 static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued) 37 { 38 struct cfs_rq *cfs_rq; 39 struct sched_entity *se = &curr->se; 40 /* 向上更新进程组时间片 */ 41 for_each_sched_entity(se) { 42 cfs_rq = cfs_rq_of(se); 43 /* 更新当前进程运行时间,并判断是否需要调度此进程 */ 44 entity_tick(cfs_rq, se, queued); 45 } 46 47 if (numabalancing_enabled) 48 task_tick_numa(rq, curr); 49 50 update_rq_runnable_avg(rq, 1); 51 }
显然,到这里最重要的函数应该是entity_tick(),因为是这个函数决定了当前进程是否需要调度出去。我们必须先明确一点就是,CFS调度策略是使用红黑树以进程的vruntime为键值进行组织的,进程的vruntime越小越在红黑树的左边,而每次调度的下一个目标就是红黑树最左边的结点上的进程。而当进行运行时,其vruntime是随着实际运行时间而增加的,但是不同权重的进程其vruntime增加的速率不同,正在运行的进程的权重约大(优先级越高),其vruntime增加的速率越慢,所以其所占用的CPU时间越多。而每次时钟中断的时候,在entity_tick()函数中都会更新当前进程的vruntime值。当进程没有处于CPU上运行时,其vruntime是保持不变的。
1 static void 2 entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued) 3 { 4 /* 5 * Update run-time statistics of the 'current'. 6 */ 7 /* 更新当前进程运行时间,包括虚拟运行时间 */ 8 update_curr(cfs_rq); 9 10 /* 11 * Ensure that runnable average is periodically updated. 12 */ 13 update_entity_load_avg(curr, 1); 14 update_cfs_rq_blocked_load(cfs_rq, 1); 15 update_cfs_shares(cfs_rq); 16 17 #ifdef CONFIG_SCHED_HRTICK 18 /* 19 * queued ticks are scheduled to match the slice, so don't bother 20 * validating it and just reschedule. 21 */ 22 /* 若queued为1,则当前运行队列的运行进程需要调度 */ 23 if (queued) { 24 /* 标记当前进程需要被调度出去 */ 25 resched_curr(rq_of(cfs_rq)); 26 return; 27 } 28 /* 29 * don't let the period tick interfere with the hrtick preemption 30 */ 31 if (!sched_feat(DOUBLE_TICK) && hrtimer_active(&rq_of(cfs_rq)->hrtick_timer)) 32 return; 33 #endif 34 /* 检查是否需要调度 */ 35 if (cfs_rq->nr_running > 1) 36 check_preempt_tick(cfs_rq, curr); 37 }
之后的文章会详细说说CFS关于进程的vruntime的处理,现在只需要知道是这样就好,在entity_tick()中,首先会更新当前进程的实际运行时间和虚拟运行时间,这里很重要,因为要使用更新后的这些数据去判断是否需要被调度。在entity_tick()函数中最后面的check_preempt_tick()函数就是用来判断进程是否需要被调度的,其判断的标准有两个:
- 先判断当前进程的实际运行时间是否超过CPU分配给这个进程的CPU时间,如果超过,则需要调度。
- 再判断当前进程的vruntime是否大于下个进程的vruntime,如果大于,则需要调度。
清楚了这两个标准,check_preempt_tick()的代码则很好理解了。
1 /* 2 * 检查当前进程是否需要被抢占 3 * 判断方法有两种,一种就是判断当前进程是否超过了CPU分配给它的实际运行时间 4 * 另一种就是判断当前进程的虚拟运行时间是否大于下个进程的虚拟运行时间 5 */ 6 static void 7 check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr) 8 { 9 /* ideal_runtime为进程应该运行的时间 10 * delta_exec为进程增加的实际运行时间 11 * 如果delta_exec超过了ideal_runtime,表示该进程应该让出CPU给其他进程 12 */ 13 unsigned long ideal_runtime, delta_exec; 14 struct sched_entity *se; 15 s64 delta; 16 17 18 /* slice为CFS队列中所有进程运行一遍需要的实际时间 */ 19 /* ideal_runtime保存的是CPU分配给当前进程一个周期内实际的运行时间,计算公式为: 一个周期内进程应当运行的时间 = 一个周期内队列中所有进程运行一遍需要的时间 * 当前进程权重 / 队列总权重 20 * delta_exec保存的是当前进程增加使用的实际运行时间 21 */ 22 ideal_runtime = sched_slice(cfs_rq, curr); 23 delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime; 24 if (delta_exec > ideal_runtime) { 25 /* 增加的实际运行实际 > 应该运行实际,说明需要调度出去 */ 26 resched_curr(rq_of(cfs_rq)); 27 /* 28 * The current task ran long enough, ensure it doesn't get 29 * re-elected due to buddy favours. 30 */ 31 /* 如果cfs_rq队列的last,next,skip指针中的某个等于当前进程,则清空cfs_rq队列中的相应指针 */ 32 clear_buddies(cfs_rq, curr); 33 return; 34 } 35 36 /* 37 * Ensure that a task that missed wakeup preemption by a 38 * narrow margin doesn't have to wait for a full slice. 39 * This also mitigates buddy induced latencies under load. 40 */ 41 if (delta_exec < sysctl_sched_min_granularity) 42 return; 43 /* 获取下一个调度进程的se */ 44 se = __pick_first_entity(cfs_rq); 45 /* 当前进程的虚拟运行时间 - 下个进程的虚拟运行时间 */ 46 delta = curr->vruntime - se->vruntime; 47 48 /* 当前进程的虚拟运行时间 大于 下个进程的虚拟运行时间,说明这个进程还可以继续运行 */ 49 if (delta < 0) 50 return; 51 52 if (delta > ideal_runtime) 53 /* 当前进程的虚拟运行时间 小于 下个进程的虚拟运行时间,说明下个进程比当前进程更应该被CPU使用,resched_curr()函数用于标记当前进程需要被调度出去 */ 54 resched_curr(rq_of(cfs_rq)); 55 } 56 57 58 59 60 /* 61 * resched_curr - mark rq's current task 'to be rescheduled now'. 62 * 63 * On UP this means the setting of the need_resched flag, on SMP it 64 * might also involve a cross-CPU call to trigger the scheduler on 65 * the target CPU. 66 */ 67 /* 标记当前进程需要调度,将当前进程的thread_info->flags设置TIF_NEED_RESCHED标记 */ 68 void resched_curr(struct rq *rq) 69 { 70 struct task_struct *curr = rq->curr; 71 int cpu; 72 73 lockdep_assert_held(&rq->lock); 74 75 /* 检查当前进程是否已经设置了调度标志,如果是,则不用再设置一遍,直接返回 */ 76 if (test_tsk_need_resched(curr)) 77 return; 78 79 /* 根据rq获取CPU */ 80 cpu = cpu_of(rq); 81 /* 如果CPU = 当前CPU,则设置当前进程需要调度标志 */ 82 if (cpu == smp_processor_id()) { 83 /* 设置当前进程需要被调度出去的标志,这个标志保存在进程的thread_info结构上 */ 84 set_tsk_need_resched(curr); 85 /* 设置CPU的内核抢占 */ 86 set_preempt_need_resched(); 87 return; 88 } 89 90 /* 如果不是处于当前CPU上,则设置当前进程需要调度,并通知其他CPU */ 91 if (set_nr_and_not_polling(curr)) 92 smp_send_reschedule(cpu); 93 else 94 trace_sched_wake_idle_without_ipi(cpu); 95 }
好了,到这里实际上如果进程需要被调度,则已经被标记,如果进程不需要被调度,则继续执行。这里大家或许有疑问,只标记了进程需要被调度,但是为什么并没有真正处理它?其实根据我的博文linux调度器源码分析 - 概述(一)所说,进程调度的发生时机之一就是发生在中断返回时,这里是在汇编代码中实现的,而我们知道这里我们是时钟中断执行上述的这些操作的,当执行完这些后,从时钟中断返回去的时候,会调用到汇编函数ret_from_sys_call,在这个函数中会先检查调度标志被置位,如果被置位,则跳转至schedule(),而schedule()最后调用到__schedule()这个函数进行处理。
1 static void __sched __schedule(void) 2 { 3 /* prev保存换出进程(也就是当前进程),next保存换进进程 */ 4 struct task_struct *prev, *next; 5 unsigned long *switch_count; 6 struct rq *rq; 7 int cpu; 8 9 need_resched: 10 /* 禁止抢占 */ 11 preempt_disable(); 12 /* 获取当前CPU ID */ 13 cpu = smp_processor_id(); 14 /* 获取当前CPU运行队列 */ 15 rq = cpu_rq(cpu); 16 rcu_note_context_switch(cpu); 17 prev = rq->curr; 18 19 schedule_debug(prev); 20 21 if (sched_feat(HRTICK)) 22 hrtick_clear(rq); 23 24 /* 25 * Make sure that signal_pending_state()->signal_pending() below 26 * can't be reordered with __set_current_state(TASK_INTERRUPTIBLE) 27 * done by the caller to avoid the race with signal_wake_up(). 28 */ 29 smp_mb__before_spinlock(); 30 /* 队列上锁 */ 31 raw_spin_lock_irq(&rq->lock); 32 /* 当前进程非自愿切换次数 */ 33 switch_count = &prev->nivcsw; 34 35 /* 36 * 当内核抢占时会置位thread_info的preempt_count的PREEMPT_ACTIVE位,调用schedule()之后会清除,PREEMPT_ACTIVE置位表明是从内核抢占进入到此的 37 * preempt_count()是判断thread_info的preempt_count整体是否为0 38 * prev->state大于0表明不是TASK_RUNNING状态 39 * 40 */ 41 if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) { 42 /* 当前进程不为TASK_RUNNING状态并且不是通过内核态抢占进入调度 */ 43 if (unlikely(signal_pending_state(prev->state, prev))) { 44 /* 有信号需要处理,置为TASK_RUNNING */ 45 prev->state = TASK_RUNNING; 46 } else { 47 /* 没有信号挂起需要处理,会将此进程移除运行队列 */ 48 /* 如果代码执行到此,说明当前进程要么准备退出,要么是处于即将睡眠状态 */ 49 deactivate_task(rq, prev, DEQUEUE_SLEEP); 50 prev->on_rq = 0; 51 52 /* 53 * If a worker went to sleep, notify and ask workqueue 54 * whether it wants to wake up a task to maintain 55 * concurrency. 56 */ 57 if (prev->flags & PF_WQ_WORKER) { 58 /* 如果当前进程处于一个工作队列中 */ 59 struct task_struct *to_wakeup; 60 61 to_wakeup = wq_worker_sleeping(prev, cpu); 62 if (to_wakeup) 63 try_to_wake_up_local(to_wakeup); 64 } 65 } 66 switch_count = &prev->nvcsw; 67 } 68 69 /* 更新rq运行队列时间 */ 70 if (task_on_rq_queued(prev) || rq->skip_clock_update < 0) 71 update_rq_clock(rq); 72 73 /* 获取下一个调度实体,这里的next的值会是一个进程,而不是一个调度组,在pick_next_task会递归选出一个进程 */ 74 next = pick_next_task(rq, prev); 75 /* 清除当前进程的thread_info结构中的flags的TIF_NEED_RESCHED和PREEMPT_NEED_RESCHED标志位,这两个位表明其可以被调度调出(因为这里已经调出了,所以这两个位就没必要了) */ 76 clear_tsk_need_resched(prev); 77 clear_preempt_need_resched(); 78 rq->skip_clock_update = 0; 79 80 if (likely(prev != next)) { 81 /* 该CPU进程切换次数加1 */ 82 rq->nr_switches++; 83 /* 该CPU当前执行进程为新进程 */ 84 rq->curr = next; 85 86 ++*switch_count; 87 88 /* 这里进行了进程上下文的切换 */ 89 context_switch(rq, prev, next); /* unlocks the rq */ 90 /* 91 * The context switch have flipped the stack from under us 92 * and restored the local variables which were saved when 93 * this task called schedule() in the past. prev == current 94 * is still correct, but it can be moved to another cpu/rq. 95 */ 96 /* 新的进程有可能在其他CPU上运行,重新获取一次CPU和rq */ 97 cpu = smp_processor_id(); 98 rq = cpu_rq(cpu); 99 } 100 else 101 raw_spin_unlock_irq(&rq->lock); /* 这里意味着下个调度的进程就是当前进程,释放锁不做任何处理 */ 102 /* 上下文切换后的处理 */ 103 post_schedule(rq); 104 105 /* 重新打开抢占使能但不立即执行重新调度 */ 106 sched_preempt_enable_no_resched(); 107 if (need_resched()) 108 goto need_resched; 109 }
在__schedule()中,每一步的作用注释已经写得很详细了,选取下一个进程的任务在__schedule()中交给了pick_next_task()函数,而进程切换则交给了context_switch()函数。我们先看看pick_next_task()函数是如何选取下一个进程的:
1 static inline struct task_struct * 2 pick_next_task(struct rq *rq, struct task_struct *prev) 3 { 4 const struct sched_class *class = &fair_sched_class; 5 struct task_struct *p; 6 7 /* 8 * Optimization: we know that if all tasks are in 9 * the fair class we can call that function directly: 10 */ 11 12 if (likely(prev->sched_class == class && rq->nr_running == rq->cfs.h_nr_running)) { 13 /* 所有进程都处于CFS运行队列中,所以就直接使用cfs的调度类 */ 14 p = fair_sched_class.pick_next_task(rq, prev); 15 if (unlikely(p == RETRY_TASK)) 16 goto again; 17 18 /* assumes fair_sched_class->next == idle_sched_class */ 19 if (unlikely(!p)) 20 p = idle_sched_class.pick_next_task(rq, prev); 21 22 return p; 23 } 24 25 again: 26 /* 在其他调度类中包含有其他进程,从最高优先级的调度类迭代到最低优先级的调度类,并选择最优的进程运行 */ 27 for_each_class(class) { 28 p = class->pick_next_task(rq, prev); 29 if (p) { 30 if (unlikely(p == RETRY_TASK)) 31 goto again; 32 return p; 33 } 34 } 35 36 BUG(); /* the idle class will always have a runnable task */ 37 }
在pick_next_task()中完全体现了进程优先级的概念,首先会先判断是否所有进程都处于cfs队列中,如果不是,则表明有比普通进程更高优先级的进程(包括实时进程)。内核中是将调度类重优先级高到低进行排列,然后选择时从最高优先级的调度类开始找是否有进程需要调度,如果没有会转到下一优先级调度类,在代码27行所体现,27行展开是
#define for_each_class(class) for (class = sched_class_highest; class; class = class->next)
而调度类的优先级顺序为
调度类优先级顺序: stop_sched_class -> dl_sched_class -> rt_sched_class -> fair_sched_class -> idle_sched_class
在pick_next_task()函数中返回了选定的进程的进程描述符,接下来就会调用context_switch()进行进程切换了。
1 static inline void 2 context_switch(struct rq *rq, struct task_struct *prev, 3 struct task_struct *next) 4 { 5 struct mm_struct *mm, *oldmm; 6 7 prepare_task_switch(rq, prev, next); 8 9 mm = next->mm; 10 oldmm = prev->active_mm; 11 /* 12 * For paravirt, this is coupled with an exit in switch_to to 13 * combine the page table reload and the switch backend into 14 * one hypercall. 15 */ 16 arch_start_context_switch(prev); 17 18 if (!mm) { 19 /* 如果新进程的内存描述符为空,说明新进程为内核线程 */ 20 next->active_mm = oldmm; 21 atomic_inc(&oldmm->mm_count); 22 /* 通知底层不需要切换虚拟地址空间 23 * if (this_cpu_read(cpu_tlbstate.state) == TLBSTATE_OK) 24 * this_cpu_write(cpu_tlbstate.state, TLBSTATE_LAZY); 25 */ 26 enter_lazy_tlb(oldmm, next); 27 } else 28 /* 切换虚拟地址空间 */ 29 switch_mm(oldmm, mm, next); 30 31 if (!prev->mm) { 32 /* 如果被切换出去的进程是内核线程 */ 33 prev->active_mm = NULL; 34 /* 归还借用的oldmm */ 35 rq->prev_mm = oldmm; 36 } 37 /* 38 * Since the runqueue lock will be released by the next 39 * task (which is an invalid locking op but in the case 40 * of the scheduler it's an obvious special-case), so we 41 * do an early lockdep release here: 42 */ 43 spin_release(&rq->lock.dep_map, 1, _THIS_IP_); 44 45 context_tracking_task_switch(prev, next); 46 47 /* 切换寄存器和内核栈,还会重新设置current为切换进去的进程 */ 48 switch_to(prev, next, prev); 49 50 /* 同步 */ 51 barrier(); 52 /* 53 * this_rq must be evaluated again because prev may have moved 54 * CPUs since it called schedule(), thus the 'rq' on its stack 55 * frame will be invalid. 56 */ 57 finish_task_switch(this_rq(), prev); 58 }
到这里整个进程的选择和切换就已经完成了。
总结
整个调度器大概原理和源码已经分析完成,其他更多细节,如CFS的一些计算和处理,实时进程的处理等,将在其他文章进行详细解释。