有时候我们想了解 各大电商的商品信息就得用爬虫抓取出必要的商品信息
就像etao 一样,一淘的那么多信息 tmall ,淘宝。
像 知我药妆, 买好,米奇 等 美妆网站
或者是团购网站 聚美,乐峰,天天 香舍臻品 。。。。
他们不可能主动给etao,
他怎么来的呢,下面给出一种方法
这只是我个人猜想
爬虫工具很多,我个人喜欢用Jsoup
下面我把例子贴出来供有兴趣的人参考
Jsoup 必须的包,数据库连接包得导入
获得Document的例子:
public static Document readUrlFist(String url) { Document doc = null; Connection conn = Jsoup.connect(url); conn .header( "User-Agent", "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.4; en-US; rv:1.9.2.2) Gecko/20100316 Firefox/3.6.2 Googlebot/2.1"); try { doc = conn.timeout(200 * 1000).get(); } catch (IOException e) { e.printStackTrace(); if ((e instanceof UnknownHostException) || (e instanceof SocketTimeoutException)) { doc = readUrlFist(url); } } return doc; }
这里说明下解析的http://mall.17mh.com/
TaoUtil 会报错,你只要自己建一个 ,把上面的代码复制进你建的TaoUtil 里就行,
package com.xinsearch.meizhuang; import java.util.ArrayList; import java.util.List; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import com.xinsearch.entity.Product; import com.xinsearch.util.TaoUtil; public class Mh17 extends TaoUtil { public static void main(String[] args) { String url = "http://mall.17mh.com/"; getGoods(url); } private static void getGoods(String url) { List<Product> list = new ArrayList<Product>(); Document doc = readUrlFist(url); Elements ones = doc.select("div.hot-cate-content"); Elements twos = ones.first().select("div.hot-cate-content-item"); for (Element element : twos) { Elements firstC = element.select("div.hot-cate-content-item-title"); String firstClass = firstC.first().text(); Elements scondC = element.select("span"); for (Element element2 : scondC) { String scondClass = element2.text(); Elements as = element2.select("a"); String scondurl = as.first().attr("href"); System.out.println(scondurl); if(scondurl.trim().equals("")){ continue; } Document doc1 = readUrlFist(scondurl); Elements pageP = doc1.select("div.pageshow"); List<String> scondUrls = new ArrayList<String>(); scondUrls.add(scondurl); if (pageP.first() != null) { Elements tdP = pageP.first().select("a"); try { if (tdP.get(tdP.size() - 1).className().trim().equals( "nolast")) { } else { int page = Integer.parseInt(tdP.get(tdP.size() - 1) .attr("href").split("p=")[1]); for (int j = 2; j <= page; j++) { String myUrl = scondurl + "?p=" + j; scondUrls.add(myUrl); } } } catch (Exception e) { } } for (String string : scondUrls) { Document doc3 = readUrlFist(string); Elements productP = doc3.select("div.product-list"); Elements products = productP .select("div.product-list-item"); for (Element element3 : products) { Elements soldP = element3 .select("div.product-list-item-soldout"); if (soldP.first() != null) { continue; } Product product = new Product(); product.setP_first(firstClass); product.setP_second(scondClass); Elements nameP = element3 .select("div.product-list-item-name"); Elements aps = nameP.first().select("a"); String productName = aps.first().text(); System.out.println(productName); product.setP_title(productName); Elements imageP = element3 .select("div.product-list-item-pic"); Elements aP = imageP.first().select("a"); String productUrl = aP.first().attr("href"); product.setP_Link(productUrl); Elements image = aP.first().select("img"); String productImage = image.first().attr("src"); product.setP_img(productImage); Elements txtP = element3 .select("div.product-list-item-info"); Elements txtB = txtP.first().select("font"); String txt = txtB.text(); String productPrice = txt; product.setP_price(productPrice); list.add(product); } } } } System.out.println(list.size()); new InsertPro().add(list); } }
保存数据库的代码:
package com.xinsearch.meizhuang; import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.SQLException; import java.util.List; import com.xinsearch.entity.Product; import com.xinsearch.util.ConnectionTools; public class InsertPro { private Connection conn; private PreparedStatement ps; public void add(List<Product> list) { conn = ConnectionTools.getConn(); try { conn.setAutoCommit(false); String sql = "insert pro(p_title,p_Link,p_img,p_price,p_orderPrice,p_sals,p_rebate,p_third,p_second,p_first) values(?,?,?,?,?,?,?,?,?,?)"; ps = conn.prepareStatement(sql); for (Product product : list) { ps.setString(1, product.getP_title()); ps.setString(2, product.getP_Link()); ps.setString(3, product.getP_img()); ps.setString(4, product.getP_price()); ps.setString(5, product.getP_orderPrice()); ps.setString(6, product.getP_sals()); ps.setString(7, product.getP_rebate()); ps.setString(8, product.getP_third()); ps.setString(9, product.getP_second()); ps.setString(10, product.getP_first()); ps.addBatch(); } ps.executeBatch(); conn.commit(); } catch (SQLException e) { try { conn.rollback(); } catch (SQLException e1) { // TODO Auto-generated catch block e1.printStackTrace(); } e.printStackTrace(); } finally { try { ConnectionTools.close(); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } } }
实体类:
package com.xinsearch.entity; public class Product { private int p_id;// ��ƷId private String p_orderPrice; private String p_title;// ��Ʒ�ı��⣨��ƣ� private String P_Link;// ��Ʒ������ private String p_img;// ��Ʒ��ͼƬ private String p_price;// ��Ʒ�ļ۸� private String p_sals;// ��Ʒ������ private String p_rebate;// ��Ʒ�۸���ۿ� private String p_third;// 3���� private String p_second;// 2���� private String p_first;// 1���� public int getP_id() { return p_id; } public String getP_orderPrice() { return p_orderPrice; } public void setP_orderPrice(String price) { p_orderPrice = price; } public void setP_id(int p_id) { this.p_id = p_id; } public String getP_title() { return p_title; } public void setP_title(String p_title) { this.p_title = p_title; } public String getP_Link() { return P_Link; } public void setP_Link(String p_Link) { P_Link = p_Link; } public String getP_img() { return p_img; } public void setP_img(String p_img) { this.p_img = p_img; } public String getP_price() { return p_price; } public void setP_price(String p_price) { this.p_price = p_price; } public String getP_sals() { return p_sals; } public void setP_sals(String p_sals) { this.p_sals = p_sals; } public String getP_rebate() { return p_rebate; } public void setP_rebate(String p_rebate) { this.p_rebate = p_rebate; } public String getP_third() { return p_third; } public void setP_third(String p_third) { this.p_third = p_third; } public String getP_second() { return p_second; } public void setP_second(String p_second) { this.p_second = p_second; } public String getP_first() { return p_first; } public void setP_first(String p_first) { this.p_first = p_first; } }
这样会得到买好网的所有数据,当然过期的我也做了处理
得到的数据 下面是米奇的
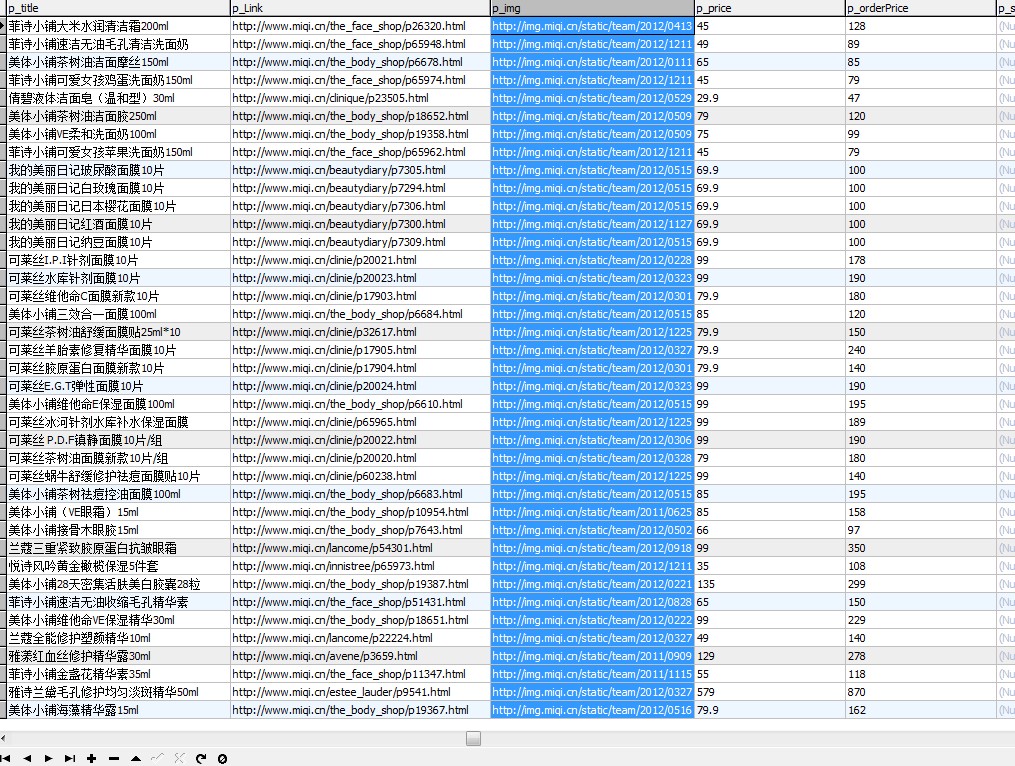
别的网站也可以用类似的方法找到 网站的所有商品信息,
不过你得经常更新你的数据,因为网站更新后你也必须更新你的代码,
只要你想得到她的数据,可以随意的更改代码来得到你想要的信息
etao 一淘 的数据怎么来的呢,爬来的呗。 这样你也可以做一个自己的一淘了。
Jsoup 是不是很强大呢。
不过写在js 里的jsoup 还是很有压力的,
不过不要紧,相信java的强大,读取js里的内容我们可以利用另一种工具
HtmlUnit
