介绍了2种反爬的方式:
- 请求头
- 代理IP
一、反爬手段1——向请求头中添加User-Agent:
请求头、响应头:
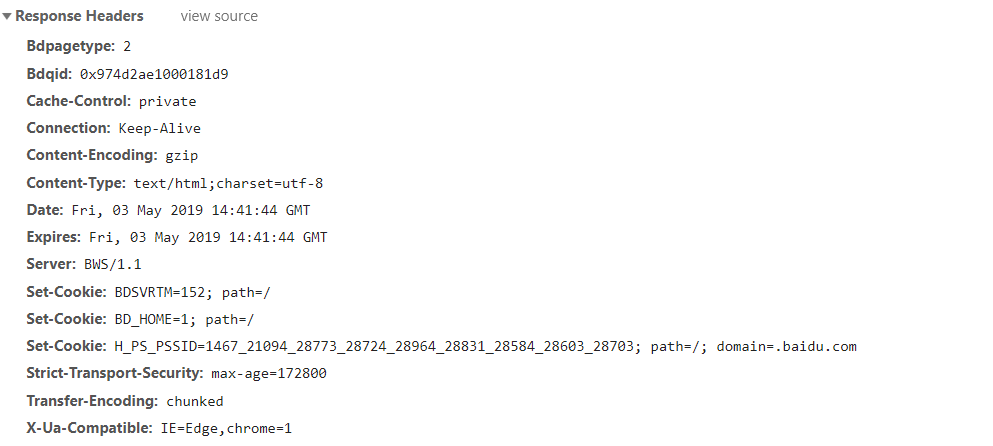
1.响应头:response_header
响应头response_header,可以通过response对象.headers,获取得到。
response.headers,得到的是响应头信息
1 def load():
2 # 1.目标网页URL地址
3 URL = "http://www.baidu.com/"
4
5 # 2.发送网络请求:
6 # 返回response对象,使用response对象接收服务器返回的数据
7 response = urllib.request.urlopen(URL)
8
9 # 得到响应头信息
10 print(response.headers)
11
12 load()
结果为:
1 Bdpagetype: 1
2 Bdqid: 0xbfd0e4790001890b
3 Cache-Control: private
4 Content-Type: text/html
5 Cxy_all: baidu+739fcb9dd92b830634cd2f957c8e6f67
6 Date: Fri, 03 May 2019 15:30:05 GMT
7 Expires: Fri, 03 May 2019 15:29:21 GMT
8 P3p: CP=" OTI DSP COR IVA OUR IND COM "
9 Server: BWS/1.1
10 Set-Cookie: BAIDUID=2D1BE12D094679CAE43187C509B76E5D:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
11 Set-Cookie: BIDUPSID=2D1BE12D094679CAE43187C509B76E5D; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
12 Set-Cookie: PSTM=1556897405; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
13 Set-Cookie: delPer=0; path=/; domain=.baidu.com
14 Set-Cookie: BDSVRTM=0; path=/
15 Set-Cookie: BD_HOME=0; path=/
16 Set-Cookie: H_PS_PSSID=28884_1454_21091_28724_28963_28837_28584; path=/; domain=.baidu.com
17 Vary: Accept-Encoding
18 X-Ua-Compatible: IE=Edge,chrome=1
19 Connection: close
20 Transfer-Encoding: chunked
和浏览器中f12,network中的Response Headers显示的信息对比,基本一致
2.请求头:request_header(重点)
User-Agent是在模拟真实用户发送网络请求
(1)目的:我们要向请求头里面,添加User-Agent信息,这样就可以干掉一部分的反爬手段。
(2)request = urllib.request.Request(目标网页URL地址)
——创建request对象
要想获取请求头request_header,我们需要先创建request对象,然后通过request对象获取请求头。
注意:Request()首字母必须大写
(3)request.headers,就可以得到请求头的信息。
(4)request.add_header('User_Agent', 'xxx')
——向请求头中添加‘User-Agent’信息
使用爬虫,最开始时,请求头request_header中是空的,为了模拟真实用户,需要向请求头request_header中添加信息;必须先创建request对象之后,再向request_header中添加请求头信息。

xxx就是冒号(:)后面的那些
(5)response = urllib.request.urlopen(request)
发送网络请求,这个方法的参数,既可以是URL地址,也可以是request对象。
(6)request.get_header('User-agent')
——获取请求头信息的第二种方式
注意:
a. 这里的参数是'User-agent',只有U大写,A小写;
request.add_header()中,"User-Agent",U和A都大写。
b. request.get_header(),这个方法只能得到请求头的一部分信息
如:request.get_header('User-agent')只会得到User-Agent信息
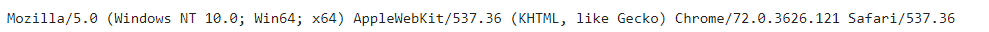
而request.headers,得到的是请求头的全部信息
(7)request.get_full_url()
可以得到完整的URL
(8)添加User-Agent信息,爬取百度首页
1 import urllib.request
2 import urllib.parse
3
4 #爬取百度首页https://www.baidu.com/
5 def load():
6 #1.目标网页URL
7 URL = "https://www.baidu.com/"
8
9 #2.向请求头中添加User-Agent信息
10 #2.1创建request对象,参数为目标网页的URL
11 request = urllib.request.Request(URL)
12
13 #打印最开始时请求头的User-Agent
14 print(request.get_header('User-agent'))
15 #2.2向请求头中添加User-Agent信息
16 request.add_headers('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36')
17
18 #再次打印请求头的User-Agent
19 print(request.get_header('User-agent'))
20
21 #3.发送网络请求,response接收返回数据
22 #参数填写添加User-Agent信息之后的request对象
23 response = urllib.request.urlopen(request)
24
25 load()
结果:

可以看到,一开始时,User-Agent的信息为None,添加之后,为我们添加的信息
注意:发送网络请求的代码,urllib.request.urlopen(request)参数填写request对象,而非URL;
如果填URL,则发送请求的请求头没有添加我们添加的User-Agent信息,还是为空None。
1.5 使用多个User-Agent:
(1)由于爬虫会在极短的时间内(一秒钟),访问服务器很多次(几百次)。所以,如果只使用一个User-Agent,很容易被服务器识别为爬虫。
(2)反爬手段2.5:使用多个User-Agent
- 百度搜索:User-Agent大全
- 使用fake User-Agent(包含250个User-Agent)
- User-Agent池(推荐)
——这样,每次发送网络请求的浏览器信息和个人信息都不一样,就可以干掉反爬了
(3)思路:设置一个User-Agent的列表,每次从中随机选取一个User-Agent
(4)代码:
import urllib.request
import urllib.parse
import random
#爬取百度首页https://www.baidu.com/
def load():
#1.目标网页URL
URL = "https://www.baidu.com/"
#2.向请求头中添加User-Agent信息
#2.1 设置User-Agent池:
user_agent_list = ['Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10;',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
]
#2.2 从User-Agent池中随机选择一个User-Agent
choose_user_agent = random.choice(user_agent_list)
#2.2创建request对象,参数为目标网页的URL
request = urllib.request.Request(URL)
#打印最开始时请求头的User-Agent
print(request.get_header('User-agent'))
#2.2向请求头中添加User-Agent信息
request.add_headers('User-Agent', choose_user_agent)
#再次打印请求头的User-Agent
print(request.get_header('User-agent'))
#3.发送网络请求,response接收返回数据
#参数填写添加User-Agent信息之后的request对象
response = urllib.request.urlopen(request)
load()
二、反爬手段2——代理IP:
理论:
(1)IP分为免费IP和付费IP:
1.1 免费IP:时效性差,错误率高
1.2 付费IP:时效性强,错误率低,但是也有失效的IP
(2)IP的三种叫法:
2.1 透明IP:对方知道我自己的真实IP
2.2 匿名IP:对方不知道我自己的真实IP,但是知道我使用了代理IP
2.3 高匿名IP:对方不知道我自己的真实IP,也不知道我使用了代理IP
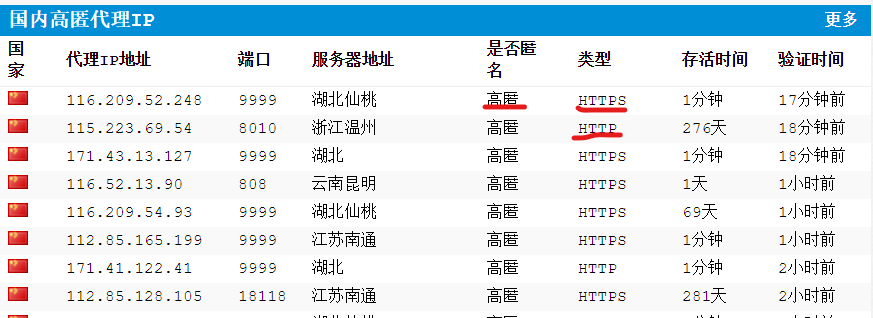
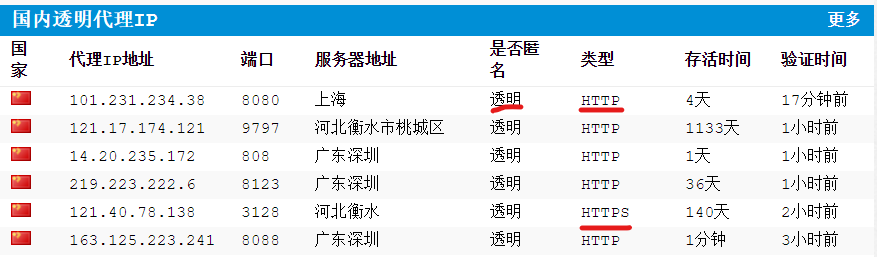
注:由图可以发现,代理IP分为HTTP和HTTPS,可以根据自己的需求,找自己要的类型IP
(3)IP分为免费IP写法和付费IP写法
(4)发送网络请求,需要使用我们自己添加的代理IP。看上面的爬虫代码,可以发现:在发送网络请求之前,只涉及到两个东西,一个是request对象、另一个是urllib.request.urlopen()方法。
查看request和urlopen()
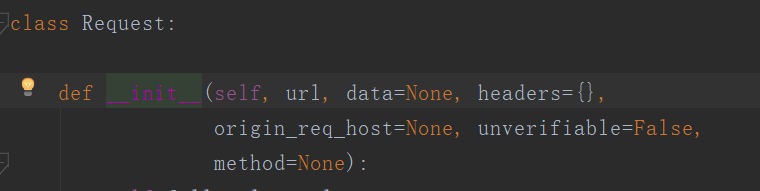

通过查看request对象和urlopen()方法源码,发现这两个对象,都没有提供加入代理IP的位置。
所以,我们应该在哪里加入,我们自己想要伪装的代理IP呢???
查看urlopen()方法代码

发现:该方法的本质是创建了一个opener对象,返回的是opener.open()
而opener对象,又是通过build_opener()一个handler处理器对象得来的

所以说,如果能在handler对象中加入我们要伪装的代理IP,然后用该对象创建opener对象,再调用open()方法,就可以达到我们的目的:伪装使用代理IP向服务器发送网络请求。
总结一下:
- urlopen()和request对象都没有添加IP的方法
- urlopen()的底层本质上是:先创建handler对象,然后创建opener对象,再用opener.open()的方法发送网络请求,爬取数据。
- 我们需要创建一个能够添加代理IP的handler处理器——proxyhandler,然后利用它创建opener对象,最后发送请求。
代码:
import urllib.request
import urllib.parse
import string
import random
# 使用添加的User-Agent和代理IP,爬取搜狗搜索的首页
def load():
# 1.目标网页URL:
URL = 'https://www.sogou.com/'
# 2.向请求头添加User-Agent
# 2.1创建request对象
request = urllib.request.Request(URL)
# 2.2设置User-Agent池
User_Agent_List = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10;',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
]
# 2.3每次请求随机选择一个User-Agent
choose_User_Agent = random.choice(User_Agent_List)
# 2.4向请求头信息中,添加User-Agent
request.add_header('User-Agent', choose_User_Agent)
# 3.添加代理IP
# 3.1设置代理IP
proxy_ip = {'https': '116.52.13.90:808'}
# 3.2创建handler处理器对象
proxy_handler = urllib.request.ProxyHandler(proxy_ip)
# 3.3创建opener对象(因为真正发送网络请求的是opener而非handler)
opener = urllib.request.build_opener(proxy_handler)
# 3.4调用open方法,发送网络请求
response = opener.open(request)
# 4.发送网络请求,使用response对象接收数据
#因为3.4中已经做了
# 5.读取response对象里面的数据,转码为字符串格式
str_data = response.read().decode('utf-8')
# 6.保存数据
with open('sougou.com02.html', 'w', encoding='utf-8') as f:
f.write(str_data)
load()
注意:
(1)代理IP的设置格式:
1.1 使用字典放置
1.2 键key:相应的代理IP的类型(http或者https)
1.3 值value:代理IP:端口号
1.4 键http/https;值IP地址+端口号,均使用字符串格式
eg:
proxy = {'http': "115.223.69.54:8010", "https": "116.209.52.248:9999"}
(2)opener.open()中的参数,既可以是目标网页的URL也可以是request对象。这里由于,我们要使用添加的User-Agent,所以参数用request对象。