一 概述
1.Redis
Redis是使用C语言编写的基于内存且支持持久化的、高性能的key-value的noSQL数据库,主要储存访问量较大、更改频繁、安全要求不高的数据。
2.NoSQL
非关系型数据库。关系型数据库是基于关系模型建立的数据库,关系模型体现的是现实世界中实体间的关联关系。
3.BSD协议
BSD开源协议是一个给予使用者极大自由的协议,使用者可以修改源码,发布修改后的代码。
4.消息中间件
支持与保障分布式应用程序间同步或者异步收发消息的中间件。
5.消息队列
为了有效地控制消息的收发过程而在消息中间件中内置的存储消息的数据结构,采用队列,先进先出。
6.SOA
Service-Oriented Architecture,面向服务的架构,将应用程序分为若干个粗粒度、松耦合的应用模块,再通过中立的接口将这些模块联系起来。
二 key命名
key01::key02:多层,相邻层用:隔开
三 常用操作
- redis-server.exe redis-windows-conf:启动服务器。
- redis-cli.exe -h 127.0.0.1 -p 6379:通过IP与端口连接某个redis服务。
- keys *:查看当前数据库中所有的key。
- config get *:获取全部配置信息。
- help command:查看操作含义。
- help @string:查看string全部操作。
- rename key01 key02:为key重命名。
- type key:获取数据类型。
- del key:删除key。
- flushdb:清空当前数据库。
- flushall:清空所有数据库。
四 string
1.增
- set key value:赋值。
- mset key01 value01 key02 value02:为多个键赋值,具有原子性,同时成功,同时失败。
- set key value nx:只有在键不存在时才可以设置。
- set key value xx:只有在键存在时才可以设置。
- set key value ex seonds:设置键的超时。
- getset key value:先取值,后赋值。
2.删
del key:删除key。
3.改
- incr key:增1。
- incrby key increment:增指定的量。
- incrbyfloat key increment:增float型数据指定的量。
- decr key:减1。
- decrby key decrement:减指定的量。
4.查
- get key:取值。
- strlen key:获取字符串长度。
- exists key:存在返回1,不存在返回0.
5.索引
从头开始,索引从0开始,1,2....
从尾开始,索引从-1开始,-2.-3...
- setrange key index value:替换指定索引位置的值。
- getrange key begin end:获取指定索引区间的值。
- getrange key 0 -1:获取全部。
五 LinkedList
1.LinkedList,双向链表,查询效率低,增删效率高。
2.增
- LPUSH key value01 value02:从左侧压入元素。
- RPUSH key value02 value02:从右侧压入元素。
3.删
- LPOP KEY:从左侧弹出一个元素,相当于从list中删除该元素。
- RPOP KEY:从右侧弹出一个元素。
- ltrim key start end :删除指定范围外的元素。
lrem key count value:删除链表中值为value的元素count个。
- count>0:从左侧开始删除。
- count<0:从右侧开始删除。
- count=0:删除全部。
4.改
LINSERT key before/after oldValue newValue:在指定元素前后插入元素,如果指定元素不存在,则不进行任何操作。如果指定元素存在多个,只操作第一个元素。
RPOPLPUSH key01 key02:从key01右侧弹出一个元素压入key02左侧。
5.查
llen key:长度即列表中元素个数。
6.索引
从左至右,从0开始;从右至左,从-1开始。
- LRANGE key start end:获取指定索引区间的元素。
- LRANGE key 0 -1:获取全部元素。
- LINDEX key index:获取指定索引位置的值。
- LSET key index value:设置指定索引位置的值。
六 hash
key值空间存储的不仅仅是key值,还有其他信息,比如超时时间,因此key占用空间较大,应该减少key的数目,把相关数据存放到同一个key中,这样就产生了数据类型hash,hash相当于HashMap。
在hash中,超时时长只能设定在key上,不能设定在field上。
1.增
- hset key field value:为key中的一个字段赋值。
- hmset key field01 value01 field02 value02:同时为多个字段赋值。
2.删
- hdel key field:删除key中指定字段。
3.改
- hincrby key filed increment:增加某个整数字段。
- hincrbyfloat field increment:增加某个浮点型字段的值。
4.查
- hget key field:获取key中指定字段的值。
- hmget key field01 field02 :获取多个字段的值。
- hgetall key:获取所有字段及其对应的值。
- hkeys key:获取所有字段名。
- kvals key:获取所有字段的值。
- hexists key field:判断key中是否存在指定字段。
- hlen key:获取key中字段数目。
七 set
无序,不可重复。所谓无序就是不同时间查询同一集合,同一排序处元素不同。
1.增
- sadd key value01 vlaue02:添加元素。
2.删
- srem key value01 value02:删除元素。
- spop key:随机移除一个元素。
3.查
- smembers key:获取全部元素
- srandmember key:随机返回一个元素。
- scard key:返回元素个数。
- sismember key value:判断value是否存在。
4.交并集操作
交并集操作并不会删除被操作集合中的元素。
- sdiff key01 key02:求差集,从key01中删除key02具有的元素,只是一个操作,不会删除key01中的元素。
- sdiffstore destination key01 key02:将差集存入指定集合中。
- suinon key01 key02:求并集。
- sninonstore destination key01 key02:将并集结果存到指定集合中。
- sinter key01 key02:求交集。
- sinterstore destination key01 key02:获取交集并存储到指定集合中。
八 sortedset
有序集合,有序的原因,每一个元素都都关联一个分值,根据分值排序。
1.增
- zadd key score01 value01 score02 value02。
2.删
- zrem key value:删除指定元素。
- zremrangebyrank key start end:删除指定排序区间的元素。
- zremrangebyscore key min max:删除指定分值区间的元素。
3.改
- zincrby key increment value:修改分值。
- zrank key value:获取排序,从小到大,从0开始。
- zrevrank key value:获取排序,从大到小,从0开始。
4.查
- zscore key value01:获取分值。
- zcard key:获取集合中元素数目。
- zrange key start end [withscores]:获取指定索引区间的值。
- zrangebyscore key min max [limit offset count]:获取分值在指定区间的值,limit用于从指定偏移处截取count个数据。min前可以加(表示开区间,只能加载min上。
- zcount key min max:获取指定分值区间内元素个数。
5.并集
zunionstore destination numKeys key[key...] weights weight aggregate max/min/sum
- destination:并集结果存储的集合。
- numKey:参与操作的集合数目。
- weights:权重,即分值参与运算的百分比,为每一个集合分别指定。
- aggregate:整合策略。
- zinterstore destination numKeys key[key...] weights weight aggregate max/min/sum:交集操作。
九 Rdis持久化
1.什么是持久化?
将数据保存到硬盘中的过程叫做持久化。
2.Redis持久化方式
- RDB: Redis DB,将所有数据以二进制形式保存到dump.rdb文件中,默认开启。
- AOF: AppendOnlyFile,将对数据库的修改操作保存到文件中,默认关闭。
3.RDB
RDB持久化会生成一个dump.rdb文件,覆盖原有文件。RDB方式
- 用户发出save操作:阻塞服务器。
- 用户发出bgsave操作:后台执行,不会阻塞服务器。原理是创建一个子线程用来生成持久化文件。
- 在配置文件中配置,满足指定条件自动持久化,这是常用方式。配置条件:save <seconds><changes>,在指定的时间内至少发生指定次数的写操作,才执行bgsave操作,生成rdb文件。
RDB持久化方式每次都将数据库中的全部数据保存到硬盘当中,耗费系统资源,不能频繁执行,为了保证RDB间隔时间内数据的安全,可以并行使用AOF持久化方式。
4.AOF
⑴系统将内存中的数据写入文件的执行过程:先将数据写入缓冲区,缓冲区满后,再将缓冲区里的内容写入文件。
⑵将对数据库的修改操作追加到文件当中,先执行的操作在前面。
⑶AOF的几种方式
- always:每执行一个修改操作,都立即写入文件。
- everysec:每隔1秒,将修改操作写入文件一次,默认值。
- no:由系统具体,缓冲区满后再写入文件。
⑷AOF文件的重写
为了避免AOF文件过大,可以重写AOF文件,将多个操作合并为一个操作。
重写方式:
第一种方式,BGREWRITEAOP:用于发送该操作,重写AOF文件。
第二种方式,设定配置条件,满足条件时自动重写,以下是重写条件:
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
当AOP文件大小达到某个值时,重写。
十 集群
1.一个Redis服务可以有多个该服务的复制品,这个Redis服务叫做master服务,其他复制品叫做slave服务。
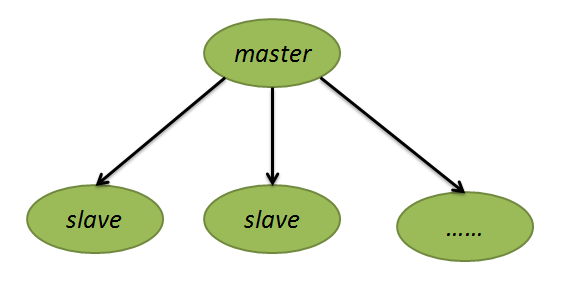
2.master服务会将自己的数据同步给slave服务。
3.master服务既可以读写,slave服务只可以读。
4.将一个服务设定为slave服务有两种方式:
- 客户发出slaveof masterip masterport。
- 在配置文件中配置:slaveof masterip masterport。
5.可以在配置文件取消设定slave的操作,也可以在由客户取消:slaveof no one
6.主从复制存在的问题
只有一个master服务器执行写操作,如果master服务器出现故障,写操作就无法执行。
十一 sentinal哨兵机制
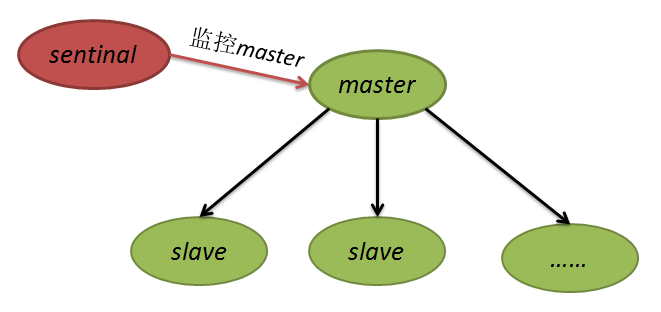
1.什么是哨兵机制?
为主服务器配置一个监听器,这个监听器称作哨兵,当主服务器发生故障时,哨兵自动将某一个从服务器提升为主服务器,从而保证服务器不间断地执行。
十二 Twemproxy集群
1.在主从复制中,写任务依然由一个节点承担,写压力并没有解决,因此产生了Twemproxy集群机制,用户向代理发出请求,由代理将写任务分配到服务器池中的节点。
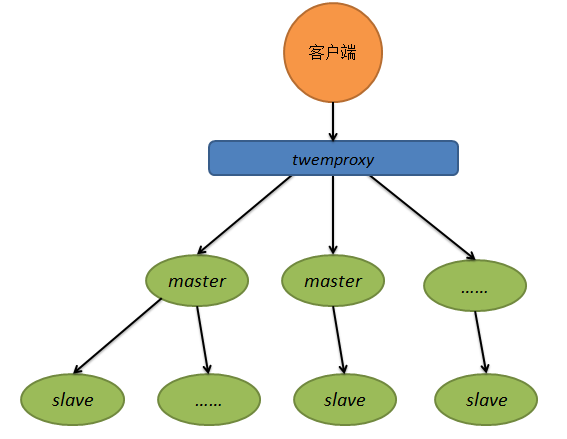
2.Twenproxy基本原理
服务器池中的每一个服务器都有一个接收区间,客户发送请求到代理后,代理获取key的hashcode,该值落在哪个区间,就调用哪个服务器。
3.缺点
有一个中心对象,即代理,如果代理出现问题,整个Redis服务就无法使用,解决方式就是去中心化,使得某一部分出现故障,整体依然可以运行。
十三 原生集群模式
1.什么是原生集群模式?
多个Redis主服务器构成一个集群,其中每一个Redis主服务器都叫做一个节点,节点之间相互通信,节点可以有自己的从服务器来分担读的压力。
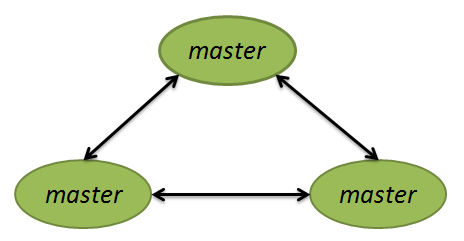
2.节点之间通信的目的之一
每一个节点都可以与其他全部节点通信,充当sentinal角色监控其他节点的运行状况,当某一个节点发生故障时其他多个节点综合信息,如果判断该节点无法正常工作,提升该节点的一个从服务器为节点。
十四 Jedis
1.在java中访问Redis服务器,需要导入架包jedis.jar。
2.Jedis是java语言中连接Redis服务器的客户端工具。
3.Jedis基本保留了命令行访问Redis服务器的方法。
4.正像连接关系型数据库最好建立连接池一样,连接Rdis数据库也最好建立连接池,建立连接池时使用的类JedisPoolConfig/JedisPool。
5.单个Redis服务器压力较大,因此可以构建Redis服务器集群,构建集群使用时使用的类HostAndPort/JedisCluster。