Python 中进程 Process
import time
import datetime
a = [0,1,2,3,4,5,6]
b = map(lambda x:x*x, a)
now_time1 = datetime.datetime.now()
def f(n):
return n*n
c = map(f,a)
if __name__ == '__main__':
print(a)
for i in b:
print(i,end=", ")
print()
for i in c:
print(i,end=", ")
print()
print("耗时:"+str(datetime.datetime.now()-now_time1))

这里的运算是串行的,耗时约为3.5S
如果我们使用多进程方式计算:
from multiprocessing import Pool import datetime now_time1 = datetime.datetime.now() def f(x): return x*x if __name__ == '__main__': p = Pool(7) print(p.map(f,[1,2,3,4,5,6,7])) print("耗时:"+str(datetime.datetime.now()-now_time1))

结果耗时仅需0.26s
下面我们再来看一下并发的效果:
1 now_time1 = datetime.datetime.now() 2 a = range(50) 3 def f(x): 4 print(x*x) 5 return x*x 6 7 if __name__ == '__main__': 8 p = Pool(10) 9 print(p.map(f,a)) 10 print("耗时:"+str(datetime.datetime.now()-now_time1))
当我们range(50),开启10个进程时,耗时仅仅0.25s,虽然计算成倍数增长,但是没有影响执行效率
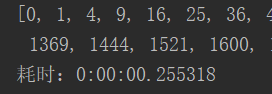
当统同样range(50),如果我们开50个进程是不是更快呢??
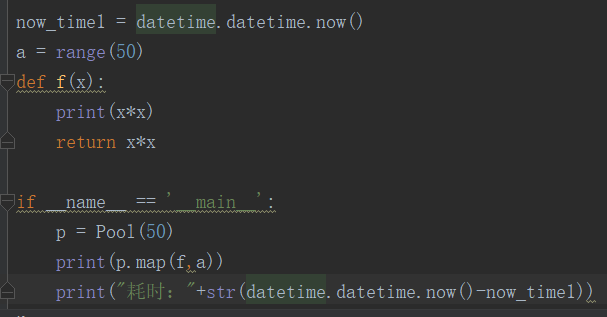

答案并非如此,说明我们计算机开启进程耗时太久。也说明并不是进程越多越好,需要我们合理设置进程数。