Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据;
同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume是一个专门设计用来从大量的源,推送数据到Hadoop生态系统中各种各样存储系统中去的,例如HDFS和HBase。
Guide: http://flume.apache.org/FlumeUserGuide.html
体系架构
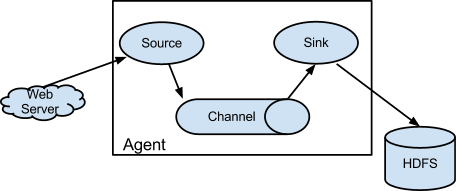
Flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
Flume以Flume Agent为最小的独立运行单位。一个Agent就是一个JVM。单agent由Source、Sink和Channel三大组件构成。一个Flume Agent可以连接一个或者多个其他的Flume Agent;一个Flume Agent也可以从一个或者多个Flume Agent接收数据。
注意:在Flume管道中如果有意想不到的错误、超时并进行了重试,Flume会产生重复的数据最终被被写入,后续需要处理这些冗余的数据。
具体可以参考文章:Flume教程(一) Flume入门教程
组件
Source:source是从一些其他产生数据的应用中接收数据的活跃组件。Source可以监听一个或者多个网络端口,用于接收数据或者可以从本地文件系统读取数据。每个Source必须至少连接一个Channel。基于一些标准,一个Source可以写入几个Channel,复制事件到所有或者某些Channel。
Source可以通过处理器 - 拦截器 - 选择器路由写入多个Channel。
Channel:channel的行为像队列,Source写入到channel,Sink从Channel中读取。多个Source可以安全地写入到相同的Channel,并且多个Sink可以从相同的Channel进行读取。
可是一个Sink只能从一个Channel读取。如果多个Sink从相同的Channel读取,它可以保证只有一个Sink将会从Channel读取一个指定特定的事件。
Flume自带两类Channel:Memory Channel和File Channel。Memory Channel的数据会在JVM或者机器重启后丢失;File Channel不会。
Sink: sink连续轮询各自的Channel来读取和删除事件。
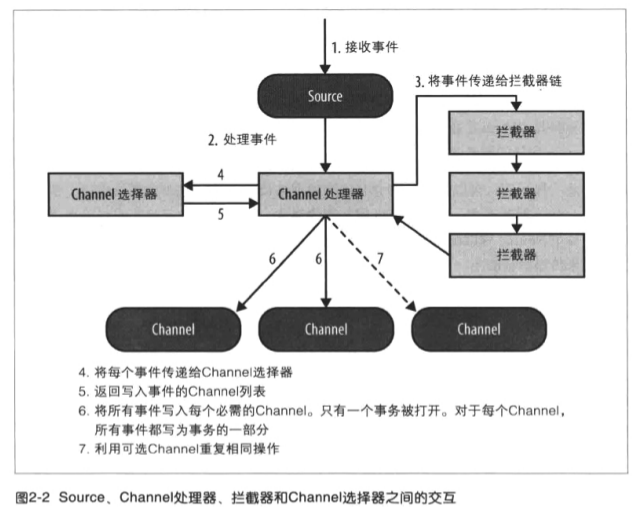
拦截器:每次Source将数据写入Channel,它是通过委派该任务到其Channel处理器来完成,然后Channel处理器将这些事件传到一个或者多个Source配置的拦截器中。
拦截器是一段代码,基于某些标准,如正则表达式,拦截器可以用来删除事件,为事件添加新报头或者移除现有的报头等。每个Source可以配置成使用多个拦截器,按照配置中定义的顺序被调用,将拦截器的结果传递给链的下一个单元。一旦拦截器处理完事件,拦截器链返回的事件列表传递到Channel列表,即通过Channel选择器为每个事件选择的Channel。
|
组件 |
功能 |
|
Agent |
使用JVM运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。 |
|
Client |
生产数据,运行在一个独立的线程。 |
|
Source |
从Client收集数据,传递给Channel。 |
|
Sink |
从Channel收集数据,运行在一个独立线程。 |
|
Channel |
连接sources和sinks,这个有点像一个队列。 |
|
Events |
可以是日志记录、avro对象等。 |
配置文件
Flume Agent使用纯文本配置文件来配置。Flume配置使用属性文件格式,仅仅是用换行符分隔的键值对的纯文本文件,如:key1 = value1;当有多个的时候:agent.sources = r1 r2
参考 flume配置介绍
1. 从file source 到 file sink的配置文件
# ========= Name the components on this agent ========= agent.sources = r1 agent.channels = c1 agent.sinks = s1 agent.sources.r1.interceptors = i1 agent.sources.r1.interceptors.i1.type = Inteceptor.DemoInterceptor$Builder # ========= Describe the source ============= agent.sources.r1.type = spooldir agent.sources.r1.spoolDir = /home/lintong/桌面/data/input # ========= Describe the channel ============= # Use a channel which buffers events in memory agent.channels.c1.type = memory agent.channels.c1.capacity = 100000 agent.channels.c1.transactionCapacity = 1000 # ========= Describe the sink ============= agent.sinks.s1.type = file_roll agent.sinks.s1.sink.directory = /home/lintong/桌面/data/output agent.sinks.s1.sink.rollInterval = 0 # ========= Bind the source and sink to the channel ============= agent.sources.r1.channels = c1 agent.sinks.s1.channel = c1
2. 从kafka source 到 file sink的配置文件,kafka使用zookeeper,但是建议使用bootstrap-server
# ========= Name the components on this agent ========= agent.sources = r1 agent.channels = c1 agent.sinks = s1 agent.sources.r1.interceptors = i1 agent.sources.r1.interceptors.i1.type = Inteceptor.DemoInterceptor$Builder # ========= Describe the source ============= agent.sources.r1.type=org.apache.flume.source.kafka.KafkaSource agent.sources.r1.zookeeperConnect=127.0.0.1:2181 agent.sources.r1.topic=test #不能写成topics #agent.sources.kafkaSource.groupId=flume agent.sources.kafkaSource.kafka.consumer.timeout.ms=100 # ========= Describe the channel ============= # Use a channel which buffers events in memory agent.channels.c1.type = memory agent.channels.c1.capacity = 100000 agent.channels.c1.transactionCapacity = 1000 # ========= Describe the sink ============= agent.sinks.s1.type = file_roll agent.sinks.s1.sink.directory = /home/lintong/桌面/data/output agent.sinks.s1.sink.rollInterval = 0 # ========= Bind the source and sink to the channel ============= agent.sources.r1.channels = c1 agent.sinks.s1.channel = c1
3.kafka source到kafka sink的配置文件
# ========= Name the components on this agent ========= agent.sources = r1 agent.channels = c1 agent.sinks = s1 s2 agent.sources.r1.interceptors = i1 agent.sources.r1.interceptors.i1.type = com.XXX.interceptor.XXXInterceptor$Builder # ========= Describe the source ============= agent.sources.r1.type = org.apache.flume.source.kafka.KafkaSource agent.sources.r1.channels = c1 agent.sources.r1.zookeeperConnect = localhost:2181 agent.sources.r1.topic = input # ========= Describe the channel ============= # Use a channel which buffers events in memory agent.channels.c1.type = memory agent.channels.c1.capacity = 100000 agent.channels.c1.transactionCapacity = 1000 # ========= Describe the sink ============= agent.sinks.s1.type = org.apache.flume.sink.kafka.KafkaSink agent.sinks.s1.topic = test agent.sinks.s1.brokerList = localhost:9092 # 避免死循环 agent.sinks.s1.allowTopicOverride = false agent.sinks.s2.type = file_roll agent.sinks.s2.sink.directory = /home/lintong/桌面/data/output agent.sinks.s2.sink.rollInterval = 0 # ========= Bind the source and sink to the channel ============= agent.sources.r1.channels = c1 agent.sinks.s1.channel = c1 #agent.sinks.s2.channel = c1
4.file source到hbase sink的配置文件
从文件读取实时消息,不做处理直接存储到Hbase
# ========= Name the components on this agent ========= agent.sources = r1 agent.channels = c1 agent.sinks = s1 # ========= Describe the source ============= agent.sources.r1.type = exec agent.sources.r1.command = tail -f /home/lintong/桌面/test.log agent.sources.r1.checkperiodic = 50 # ========= Describe the sink ============= agent.channels.c1.type = memory agent.channels.c1.capacity = 100000 agent.channels.c1.transactionCapacity = 1000 # agent.channels.file-channel.type = file # agent.channels.file-channel.checkpointDir = /data/flume-hbase-test/checkpoint # agent.channels.file-channel.dataDirs = /data/flume-hbase-test/data # ========= Describe the sink ============= agent.sinks.s1.type = org.apache.flume.sink.hbase.HBaseSink agent.sinks.s1.zookeeperQuorum=master:2183 #HBase表名 agent.sinks.s1.table=mikeal-hbase-table #HBase表的列族名称 agent.sinks.s1.columnFamily=familyclom1 agent.sinks.s1.serializer = org.apache.flume.sink.hbase.SimpleHbaseEventSerializer #HBase表的列族下的某个列名称 agent.sinks.s1.serializer.payloadColumn=cloumn-1 # ========= Bind the source and sink to the channel ============= agent.sources.r1.channels = c1 agent.sinks.s1.channel=c1
5.source是http,sink是kafka
# ========= Name the components on this agent ========= agent.sources = r1 agent.channels = c1 agent.sinks = s1 s2 # ========= Describe the source ============= agent.sources.r1.type=http agent.sources.r1.bind=localhost agent.sources.r1.port=50000 agent.sources.r1.channels=c1 # ========= Describe the channel ============= # Use a channel which buffers events in memory agent.channels.c1.type = memory agent.channels.c1.capacity = 100000 agent.channels.c1.transactionCapacity = 1000 # ========= Describe the sink ============= agent.sinks.s1.type = org.apache.flume.sink.kafka.KafkaSink agent.sinks.s1.topic = test_topic agent.sinks.s1.brokerList = master:9092 # 避免死循环 agent.sinks.s1.allowTopicOverride = false agent.sinks.s2.type = file_roll agent.sinks.s2.sink.directory = /home/lintong/桌面/data/output agent.sinks.s2.sink.rollInterval = 0 # ========= Bind the source and sink to the channel ============= agent.sources.r1.channels = c1 agent.sinks.s1.channel = c1 #agent.sinks.s2.channel = c1
如果在启动flume的时候遇到
java.lang.NoClassDefFoundError: org/apache/hadoop/hbase/***
解决方案,在 ~/software/apache/hadoop-2.9.1/etc/hadoop/hadoop-env.sh 中添加
HADOOP_CLASSPATH=/home/lintong/software/apache/hbase-1.2.6/lib/*
5.kafka source到hdfs sink的配置文件
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
# The configuration file needs to define the sources,
# the channels and the sinks.
# Sources, channels and sinks are defined per agent,
# in this case called 'agent'
# ========= Name the components on this agent =========
agent.sources = r1
agent.channels = c1
agent.sinks = s1
agent.sources.r1.interceptors = i1
agent.sources.r1.interceptors.i1.type = Util.HdfsInterceptor$Builder
# ========= Describe the source =============
agent.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
agent.sources.r1.channels = c1
agent.sources.r1.zookeeperConnect = localhost:2181
agent.sources.r1.topic = topicB
#agent.sources.r1.kafka.consumer.max.partition.fetch.bytes = 409600000
# ========= Describe the channel =============
# Use a channel which buffers events in memory
agent.channels.c1.type = memory
agent.channels.c1.capacity = 100000
agent.channels.c1.transactionCapacity = 1000
#agent.channels.c1.keep-alive = 60
# ========= Describe the sink =============
agent.sinks.s1.type = hdfs
agent.sinks.s1.hdfs.path = /user/lintong/logs/nsh/json/%{filepath}/ds=%{ds}
agent.sinks.s1.hdfs.filePrefix = test
agent.sinks.s1.hdfs.fileSuffix = .log
agent.sinks.s1.hdfs.fileType = DataStream
agent.sinks.s1.hdfs.useLocalTimeStamp = true
agent.sinks.s1.hdfs.writeFormat = Text
agent.sinks.s1.hdfs.rollCount = 0
agent.sinks.s1.hdfs.rollSize = 10240
agent.sinks.s1.hdfs.rollInterval = 600
agent.sinks.s1.hdfs.batchSize = 500
agent.sinks.s1.hdfs.threadsPoolSize = 10
agent.sinks.s1.hdfs.idleTimeout = 0
agent.sinks.s1.hdfs.minBlockReplicas = 1
agent.sinks.s1.channel = fileChannel
# ========= Bind the source and sink to the channel =============
agent.sources.r1.channels = c1
agent.sinks.s1.channel = c1
hdfs sink的配置参数参考:Flume中的HDFS Sink配置参数说明
因为写HDFS的速度很慢,当数据量大的时候会出现一下问题
org.apache.flume.ChannelException: Take list for MemoryTransaction, capacity 1000 full, consider committing more frequently, increasing capacity, or increasing thread count
可以将内存channel改成file channel或者改成kafka channel
当换成kafka channel的时候,数据量大的时候,依然会问题
16:07:48.615 ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:550 - Error ILLEGAL_GENERATION occurred while committing offsets for group flume
16:07:48.617 ERROR org.apache.flume.source.kafka.KafkaSource:317 - KafkaSource EXCEPTION, {}
org.apache.kafka.clients.consumer.CommitFailedException: Commit cannot be completed due to group rebalance
at org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler.handle(ConsumerCoordinator.java:552)
或者
ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:550 - Error UNKNOWN_MEMBER_ID occurred while committing offsets for group flume
参考:flume1.7使用KafkaSource采集大量数据
修改增大以下两个参数
agent.sources.r1.kafka.consumer.max.partition.fetch.bytes = 409600000 agent.sources.r1.kafka.consumer.timeout.ms = 100
kafka channel 爆了
ERROR org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:550 - Error UNKNOWN_MEMBER_ID occurred while committing offsets for group flume
添加参数
agent.channels.c1.kafka.consumer.session.timeout.ms=100000 agent.channels.c1.kafka.consumer.request.timeout.ms=110000 agent.channels.c1.kafka.consumer.fetch.max.wait.ms=1000
命令
启动
bin/flume-ng agent -c conf -f conf/flume-conf.properties -n agent -Dflume.root.logger=INFO,console