(一)效果图
先来两个效果图看看
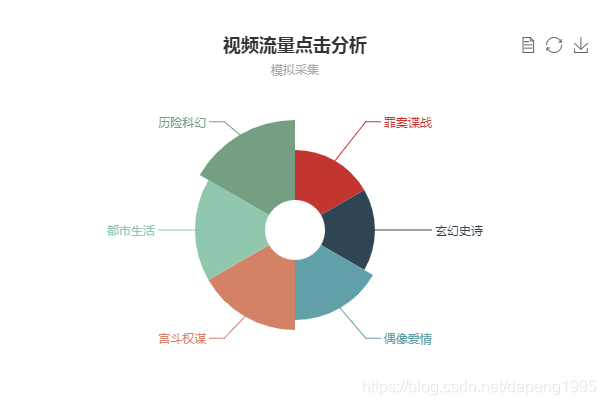
图1
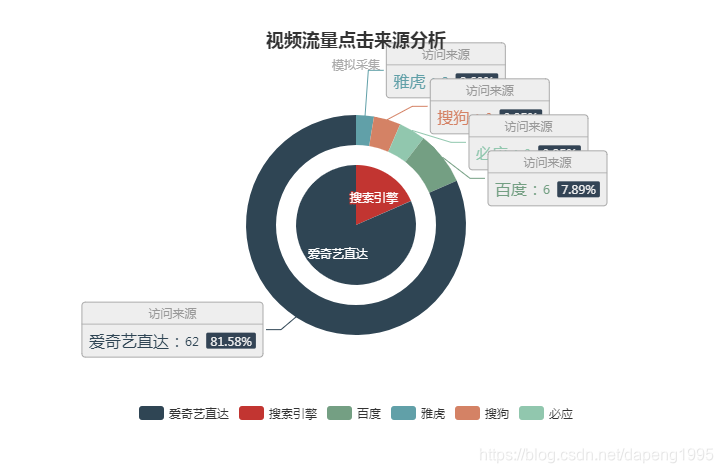
图2
(二)日志产生
图1显示的效果表示的是对于某个视频网站的访问的视频类别,做的模拟统计示意效果图,比如爱奇艺视频,对于爱奇艺视频中的每个类别的视频的访问流量:
https://list.iqiyi.com/www/2/-24------------11-1-1-iqiyi--.html 对应的是爱奇艺视频中的电视剧中的古装剧
https://list.iqiyi.com/www/2/-20------------11-1-1-iqiyi--.html 对应的是爱奇艺视频中的电视剧中的言情剧
https://list.iqiyi.com/www/2/-23------------11-1-1-iqiyi--.html 对应的是爱奇艺视频下的电视剧中的家庭剧
https://list.iqiyi.com/www/1/----------------iqiyi--.html 对应的是爱奇艺下的电影栏目
根据这样的信息,我们可以分析了解到对于某一个视频网站下的视频分类大概的网址后缀 ‘www/2’ ‘www/1’有这样的类似的分类。
因此可以通过程序来产生类似这样的程序。(generate.py)
#coding=UTF-8
import random
import time
url_paths = [ //
"/www/2",
"/www/1",
"/www/6",
"/www/4",
"/www/3",
"/www/5",
"/pianhua/130",
"/toukouxu/821"
]
status_code =[404,302,200]
ip_slices=[132,156,124,10,29,167,143,187,30,100]
http_referers = [
"https://www.baidu.com/s?wd={query}",
"https://www.sogou.com/web?qu={query}",
"http://cn.bing.com/search?q={query}",
"https://search.yahoo.com/search?p={query}"
]
search_keyword = [
"猎场",
"快乐人生",
"极限挑战",
"我的体育老师",
"幸福满院"
]
#ip地址
def sample_ip():
slice = random.sample(ip_slices,4)
return ".".join([str(item) for item in slice])
def sample_url():
return random.sample(url_paths,1)[0]
def sample_status():
return random.sample(status_code,1)[0]
def sample_referer():
if random.uniform(0,1) > 0.2:
return "-"
refer_str = random.sample(http_referers,1)
#print refer_str[0]
query_str = random.sample(search_keyword,1)
#print query_str[0]
return refer_str[0].format(query=query_str[0])
#产生log
def generate_log(count=10):
time_str = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime())
#f = open("C:\code\logs","w+")
f = open("/home/txp/logs/log","a+")
while count >= 1:
query_log = "{ip} {localtime} "GET {url} HTTP/1.0" {referece} {status1}".format(ip=sample_ip(),url=sample_url(),status1=sample_status(),referece=sample_referer(),localtime=time_str)
#print query_log
f.write(query_log+"
")
count = count-1;
if __name__ == '__main__':
generate_log(10) //产生10条数据 一次
#print "1111"
产生的日志
187.30.156.143 2018-11-03 14:55:01 "GET /www/6 HTTP/1.0" - 200
156.132.30.124 2018-11-03 14:56:01 "GET /toukouxu/821 HTTP/1.0" - 404
132.124.10.29 2018-11-03 14:56:01 "GET /www/5 HTTP/1.0" - 404
29.187.167.156 2018-11-03 14:56:01 "GET /toukouxu/821 HTTP/1.0" - 200
167.156.187.143 2018-11-03 14:56:01 "GET /www/2 HTTP/1.0" - 404
156.143.10.100 2018-11-03 14:56:01 "GET /www/4 HTTP/1.0" - 200
156.10.143.29 2018-11-03 14:56:01 "GET /www/4 HTTP/1.0" http://cn.bing.com/search?q=快乐人生 200
在这里为了和真实的场景类似可以采用linux的调度器工具每一分钟产生一批数据–linux crontab
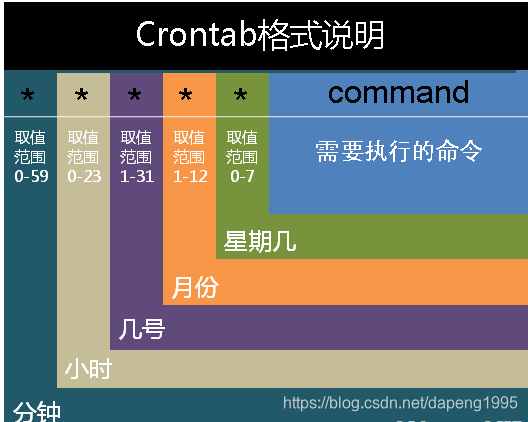
在以上各个字段中,还可以使用以下特殊字符:
星号(*):代表所有可能的值,例如month字段如果是星号,则表示在满足其它字段的制约条件后每月都执行该命令操作。
逗号(,):可以用逗号隔开的值指定一个列表范围,例如,“1,2,5,7,8,9”
中杠(-):可以用整数之间的中杠表示一个整数范围,例如“2-6”表示“2,3,4,5,6”
正斜线(/):可以用正斜线指定时间的间隔频率,例如“0-23/2”表示每两小时执行一次。同时正斜线可以和星号一起使用,例如*/10,如果用在minute字段,表示每十分钟执行一次。
在linux中直接运行可能会产生乱码 需要在log产生文件头上加上 #!/usr/bin/python
因此定义一个执行文件来执行产生日志的脚本文件 logs_generator.sh
其内容为 python /home/txp/logs/generator.py
crondtab中的最后一行定义为: * * * * * txp source /etc/profile;~/logs/logs_generator.sh
那么启动调度服务吧------> service crond start
(三)日志收集
(1)首先我们的架构如图
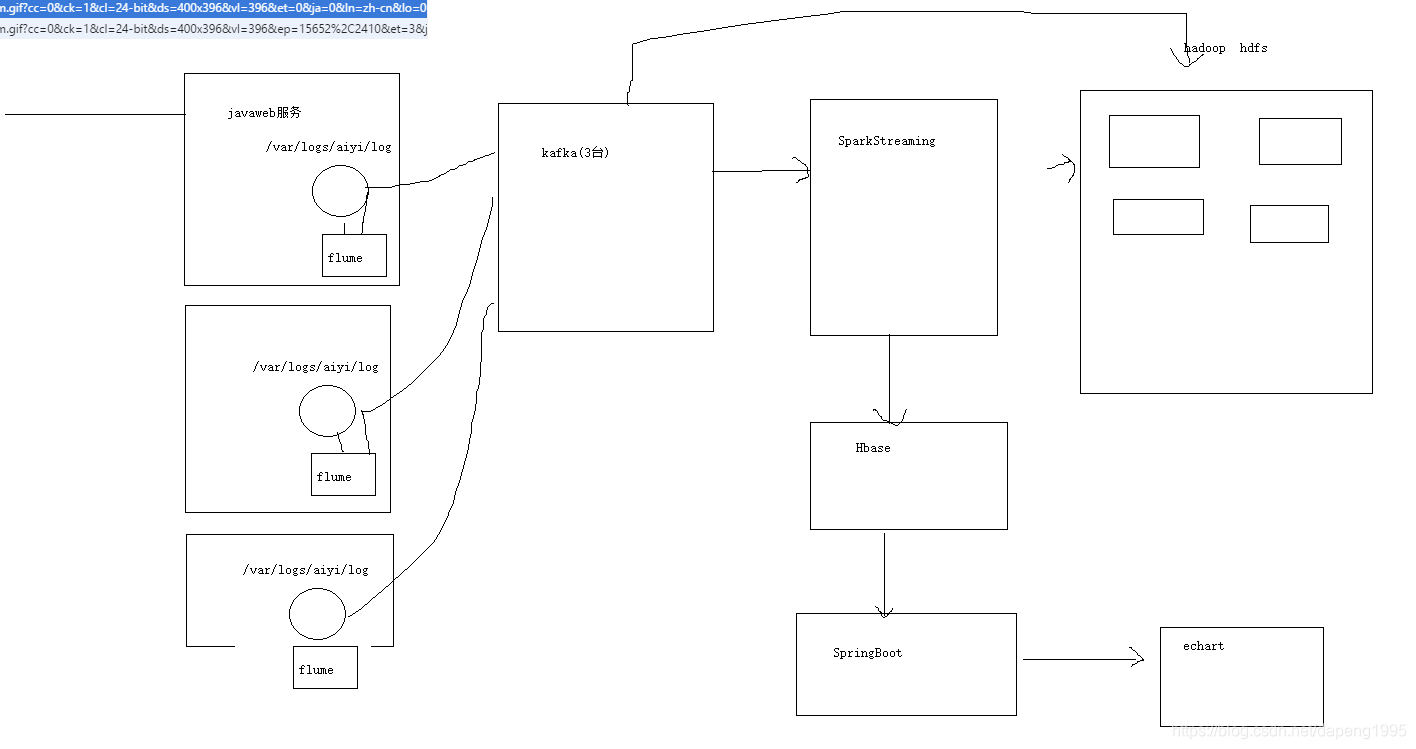
(2)flume监控log的产生,并且发给kafak,以及配置文件的编写
a1.sources=src1
a1.channels=ch1
a1.sinks=k1
#定义 sources
a1.sources.src1.type=exec
a1.sources.src1.command=tail -F /home/txp/logs/log
a1.sources.src1.channels=ch1
#定义channels
a1.channels.ch1.type=memory
a1.channels.ch1.capacity=1000
#定义sinks
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic=flumeTopic
a1.sinks.k1.brokerList=s202:9092
a1.sinks.k1.batchSize=20
a1.sinks.k1.requiredAcks=1
a1.sinks.k1.channels=ch1
#绑定channels
a1.sources.src1.channels=ch1
a1.sinks.k1.channel=ch1
(3)
Spark Streaming 是 Spark Core API 的扩展, 它支持弹性的, 高吞吐的, 容错的实时数据流的处理. 数据可以通过多种数据源获取, 例如 Kafka, Flume, Kinesis 以及 TCP sockets, 也可以通过例如 map, reduce, join, window 等的高级函数组成的复杂算法处理.

这里kafka源和sparkStreaming结合,进行实时的操作
val streamingContext = new StreamingContext("local[*]", "StatStreamingApp", Seconds(5))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "s202:9092,s203:9092,s204:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("flumeTopic")
val logs = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
).map(_.value())
SparkStreaming从kafka中得到数据,首先要进行格式的确定
源日志为
29.187.124.167 2018-11-03 13:12:01 “GET /www/6 HTTP/1.0” https://search.yahoo.com/search?p=幸福满院 200
156.124.187.29 2018-11-03 13:12:01 “GET /pianhua/130 HTTP/1.0” - 302
期望得到的数据 (1)以/www开头 (2)要有类目编号比如这里的6
var cleanLog = logs.map(line => {
var infos = line.split(" ")
var url = infos(2).split(" ")(1)
var categoryId = 0
if (url.startsWith("/www")) {
categoryId = url.split("/")(2).toInt
}
ClickLog(infos(0), DateUtils.parseToMin(infos(1)), categoryId, infos(3), infos(4).toInt)
}).filter(log => log.categoryId != 0)
DateUtils完成的是时间格式的转换
接下来主要完成的是统计实时的当天的视频中每个类别的访问量
cleanLog.map(log => {
//获取log里面的时间 类别
(log.time.substring(0, 8) + "_" + log.categoryId, 1)
}).reduceByKey(_ + _).foreachRDD(rdd => {
rdd.foreachPartition(partitions => {
val list = new ListBuffer[CategoryClickCount]
partitions.foreach(pair => {
list.append(CategoryClickCount(pair._1, pair._2))
})
CategoryClickCountDao.save(list)
})
})
CategoryClickCountDao主要完成的是将日志保存到hbase中,从hbase中获取数据等等操作
cleanLog.map(log => {
val url_refer=log.refer
var host=""
if(url_refer=="-"){
host="AiQiYi" //来自爱奇艺视频自己
}else{
val url = url_refer.replace("//", "/")
val splits = url.split("/")
if (splits.length > 2) {
host = splits(1) //得到www.sogou.com
}
}
(host, log.time)
}).filter(x => x._1 != "").map(x => {
(x._2.substring(0, 8) + "_" + x._1, 1)
}).reduceByKey(_ + _).foreachRDD(rdd => {
rdd.foreachPartition(partitions => {
val list = new ListBuffer[CategorySerachCount]
partitions.foreach(pair => {
list.append(CategorySerachCount(pair._1, pair._2))
})
CategorySearchCountDao.save(list)
})
})
这段代码完成的是将收集的日志分析得到视频访问的来源,是来自于直接访问(如在爱奇艺中直接得到),还是其他的搜索引擎得到的,转换得到一定的格式存储到hbase数据库中。
以上完成日志收集到hbase中。
(4)可视化展示
主要采用的是echart中的饼图来完成,配合使用springboot完成前台展示。
展示的部分不再叙述
代码可参考:github代码
代码中 SparkStudy为访问数据的实时收集
SparkWebLearning为前台展示实时展示