二次排序的需求说明
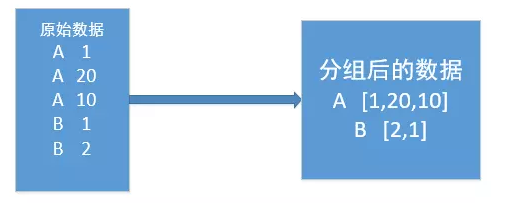
在mapreduce操作时,shuffle阶段会多次根据key值排序。但是在shuffle分组后,相同key值的values序列的顺序是不确定的(如下图)。如果想要此时value值也是排序好的,这种需求就是二次排序。
1.png
测试的文件数据
a 5 a 1 a 7 a 9 b 3 b 8 b 10 c 2 c 4 c 3
第一种实现思路
直接在reduce端对分组后的values进行排序。
- map关键代码
public class myMapper extends Mapper<LongWritable,Text,Text,IntWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { System.out.println("before Mapper <k1,v1>:"+key+"-"+value); String line = value.toString(); String[] str = line.split(" "); context.write(new Text(str[0]),new IntWritable(Integer.parseInt(str[1]))); } }
- reduce关键代码
-
public class myReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { List<Integer> valuesList = new ArrayList<Integer>(); // 取出value for(IntWritable value : values) { valuesList.add(value.get()); } // 进行排序 Collections.sort(valuesList); for(Integer value : valuesList) { context.write(key, new IntWritable(value)); } } }
App关键代码
public class myApp { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "file:///"); Job job = Job.getInstance(conf); //设置job的各种属性 job.setJobName("myAppApp"); //作业名称 job.setJarByClass(myApp.class); //搜索类 //添加输入路径 FileInputFormat.addInputPath(job,new Path("F:\mr\secondsort\input1")); //设置输出路径 FileOutputFormat.setOutputPath(job,new Path("F:\mr\secondsort\output1")); job.setMapperClass(myMapper.class); //mapper类 job.setReducerClass(myReducer.class); //reducer类 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // job.waitForCompletion(true); } }
其输出:
a 1 a 5 a 7 a 9 b 3 b 8 b 10 c 2 c 3 c 4
需要注意的是,这样把排序工作都放到reduce端完成,当values序列长度非常大的时候,会对CPU和内存造成极大的负载。还有就是,在reduce端对values进行迭代的时候,不要直接直接存储value值或者key值,因为reduce方法会反复执行多次,但key和value相关的对象只有两个,reduce会反复重用这两个对象。需要用相应的数据类型.get()取出后再存储。
第二种实现思路
用二次排序来实现
二次排序,从字面上可以理解为在对key排序的基础上对key所对应的值value排序,也叫辅助排序。一般情况下,MapReduce框架只对key排序,而不对key所对应的值排序,因此value的排序经常是不固定的。但是我们经常会遇到同时对key和value排序的需求,例如Hadoop权威指南中的求一年的高高气温,key为年份,value为最高气温,年份按照降序排列,气温按照降序排列。还有水果电商网站经常会有按天统计水果销售排行榜的需求等等,这些都是需要对key和value同时进行排序。
根据相关博客加上书本的理解:
得到如下的流程:
input file ---> split ---> recordreader(生成键值对)---> 形成复合键ComboKey(key和value的复合键) ---> 分区 (setPartitionerClass设置分区函数--可以是自定义的分区函数,这里主要根据的是组合键的第一个字段(key)进行分区) ----> 在每个分区内进行排序(分区内部排序,setSortComparatorClass设定特定的排序对比器进行排序,实际上这已经算是进行了一次二次排序) ---> shuffle阶段--->内部排序(shuffle阶段从不同节点读取了相应的map输出文件,所以在此处进行第二次排序,同样的setSortComparatorClass设定特定的排序对比器进行排序,进行第二次排序)--->reduce阶段进行分组(会对键值相同的项进行分组操作,其默认操作的键。对于我们生产的键值对<key1,value1>,key1是一个复合键值对,我们对他的操作是针对复合键值对key1的第一个值为准的,setGroupingComparatorClass设定的分组函数)---> 执行reduce函数--->输出结果。
具体事例:
事例文件如上:
-
-
- 组合键值对comboKey
public class pairWritable implements WritableComparable<pairWritable> { //组合key private String first; private int second; public pairWritable() { } public pairWritable(String first, int second) { this.set(first,second); } public String getFirst() { return first; } public void setFirst(String first) { this.first = first; } public int getSecond() { return second; } public void setSecond(int second) { this.second = second; } /** * 方便设置字段 */ public void set(String first, int second) { this.first = first; this.second = second; } public int compareTo(pairWritable o) { int comp=this.first.compareTo(o.first); if (comp!=0){ return comp; }else { return Integer.valueOf(this.second).compareTo(Integer.valueOf(o.getSecond())); } } /** * 序列化 * @param dataOutput * @throws IOException */ public void write(DataOutput dataOutput) throws IOException { dataOutput.writeUTF(first); dataOutput.writeInt(second); } /** * 反序列化 * @param dataInput * @throws IOException */ public void readFields(DataInput dataInput) throws IOException { this.first = dataInput.readUTF(); this.second=dataInput.readInt(); } }
-
我们的mapper如下
public class myMapper extends Mapper<LongWritable,Text,pairWritable,NullWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] str = line.split(" "); pairWritable keyOut = new pairWritable(); keyOut.set(str[0],Integer.valueOf(str[1])); context.write(keyOut,NullWritable.get()); } }
-
然后是分区类
ublic class myPartition extends Partitioner<pairWritable, IntWritable> { public int getPartition(pairWritable key, IntWritable value, int numPartitions) { /** * 默认的实现 (key.hashCode() & Integer.MAX_VALUE) % numPartitions * 让key中first字段作为分区依据 */ return (key.getFirst().hashCode() & Integer.MAX_VALUE) % numPartitions; } }
-
组合键排序比较方法需要自己写一下,默认情况下key不是排序的,所以我们需要先进行排序。然后才是分组
public class pairWritableComparator extends WritableComparator { protected pairWritableComparator() { super(pairWritable.class, true); } @Override public int compare(WritableComparable a, WritableComparable b) { System.out.println("ComboKeyComparator"); pairWritable k1=(pairWritable)a; pairWritable k2=(pairWritable)b; return k1.compareTo(k2); } }
-
重新分组方法,同一key的需要放在同一组中
public class myGroupComparator implements RawComparator<pairWritable> { /** * 字节比较 * arg0,arg3为要比较的两个字节数组 * arg1,arg2表示第一个字节数组要进行比较的收尾位置,arg4,arg5表示第二个 * 从第一个字节比到组合key中second的前一个字节,因为second为int型,所以长度为4 */ public int compare(byte[] arg0, int arg1, int arg2, byte[] arg3, int arg4, int arg5) { return WritableComparator.compareBytes(arg0, 0, arg2-4, arg3, 0, arg5-4); } /** * 对象比较 */ public int compare(pairWritable o1, pairWritable o2) { return o1.getFirst().compareTo(o2.getFirst()); } }
-
reducer
public class myReducer extends Reducer<pairWritable,NullWritable,Text,IntWritable> { @Override protected void reduce(pairWritable key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { Text keyOut = new Text(); IntWritable valueOut=new IntWritable(); //迭代输出 for(NullWritable value : values){ keyOut.set(key.getFirst()); valueOut.set(key.getSecond()); context.write(keyOut,valueOut); } } }
-
App
public class myApp { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "file:///"); //判断文件是否存在 Path path = new Path("F:\mr\secondsort\output3"); FileSystem fileSystem = path.getFileSystem(conf); if(fileSystem.isDirectory(path)){ fileSystem.delete(path,true); } Job job = Job.getInstance(conf); //设置job的各种属性 job.setJobName("myApp"); //作业名称 job.setJarByClass(myApp.class); //搜索类 job.setInputFormatClass(TextInputFormat.class); //设置输入格式 //添加输入路径 FileInputFormat.addInputPath(job,new Path("F:\mr\secondsort\input1")); //设置输出路径 FileOutputFormat.setOutputPath(job,new Path("F:\mr\secondsort\output3")); //map输出类型 job.setMapOutputKeyClass(pairWritable.class); // job.setMapOutputValueClass(NullWritable.class); // job.setMapperClass(myMapper.class); job.setReducerClass(myReducer.class); //设置分区函数 job.setPartitionerClass(myPartition.class); //设置排序对比起 job.setSortComparatorClass(pairWritableComparator.class); //设置分组对比器 job.setGroupingComparatorClass(myGroupComparator.class); job.waitForCompletion(true); } }
- 组合键值对comboKey
-