在了解HANA的同时遇到了列存储的概念,因此GOOGLE了些资料,作为笔记记录于此。
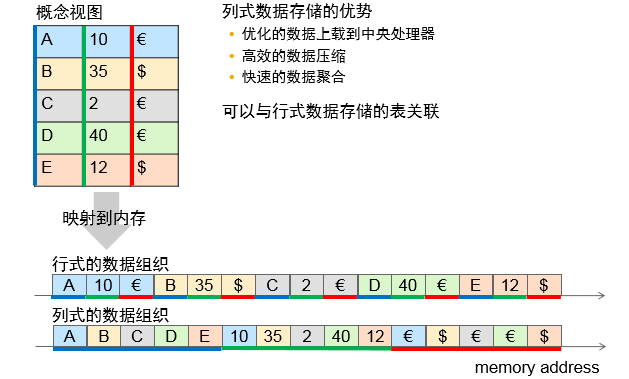
一般的数据库采用行存储,行存储的写入是一次性完成的。由于行存储的存储结构是以数据行为单位聚簇在一起的,这样的实现能够保证数据的完整性,保证写入的过程成功或失败。对于数据写入,行存储只需将磁头移动到相应行的位置即可完成写入操作;对于数据修改,与写入相似,行存储能够保持较高的效率;对于数据的读取,行存储通常将整行的数据读出,如果仅需要读取几列,行存储会在内存中将冗余列消除,这样的处理方式对于常规数据量的数据读取是可以接受的,但对于大数据,过多的冗余必定会造成数据读取的低效。
在1985年SIGMOD会议上就有文章” A decomposition storage model”对列存储DSM(decomposition storage model)做了比较详细的介绍,而Sybase更在2004年左右就推出了列存储的Sybase IQ数据库系统。列存储不同于以行作为聚簇的存储模式,而采用了以列(字段)作为聚簇单元。对于数据写入与修改,列存储的效率相对于行存储的效率较低,主要由于列存储以列为存储聚簇的模式导致每次修改或写入多行数据都需要将磁盘磁头移动到对应位置;而对于数据读取,列存储相对于行存储则有着独特的优势。首先,列存储可以直接将对应列读出,不存在冗余列现象;其次,列存储的每一列数据类型是同质的,不存在二义性问题。比如说某列数据类型为整型(int),那么它的数据集合一定是整型数据。这种情况使数据解析变得十分容易,同时也容易为这种存储设计更好的压缩/解压算法。相比之下,行存储则要复杂得多,因为在一行记录中保存了多种类型的数据,数据解析需要在多种数据类型之间频繁转换,这个操作很消耗CPU,增加了解析的时间。所以,列存储的解析过程更有利于分析大数据。
为了改进列存储的缺点,往往采用多硬盘的解决方案,以多线程并行读写磁盘,有效减少磁盘读写竞用;同时加入类似关系数据库的回滚机制,当某一列发生写入失败时,此前写入的数据全部失效,同时加入散列码校验,进一步保证数据完整性。
综上所述,相对于列存储,行存储更适合于数据挖掘、大数据等类型的应用,这也是SAP HANA采用列存储技术的原因之一,利用HANA的内存计算模式与内存并行计算的方式能够有效提升数据读写效率、降低列存储模式写入/修改速度较慢的弊端。
引用:
1.《大数据存取的选择:行存储还是列存储?》 袁萌 http://www.infoq.com/cn/articles/bigdata-store-choose
2.《说说列存储技术》http://www.cnblogs.com/happyy/archive/2010/04/26/1721481.html