=========================Hadoop目录==============================
bin:一些普通执行脚本
sbin:系统执行脚本,包含启动,停止的脚本
included:跟本地库相关的一些文件
etc:配置文件
lib:老版本的hadoop的话放jar,新版的则用来放本地库。
share:存放大量的java jar包,用来实现功能(用hadoop来写应用程序),share文件夹里面是doc 和 hadoop两个文件夹,doc里面是英文文档,可以删掉来加快速度,hadoop里面就是功能jar包。share/hadoop 里面是以工程分类的,包括如下工程:

=========================Linux机器记录============================
虚拟机(笔记本):
[hadoop-0]:hostname:hadoop-0 password:hadoop
[hadoop-1]:hostname:hadoop-1 password:hadoop
公司电脑:
[hadoop-0]:hostname:hadoop-0 password:hadoop
======================搭建虚拟机环境==========================
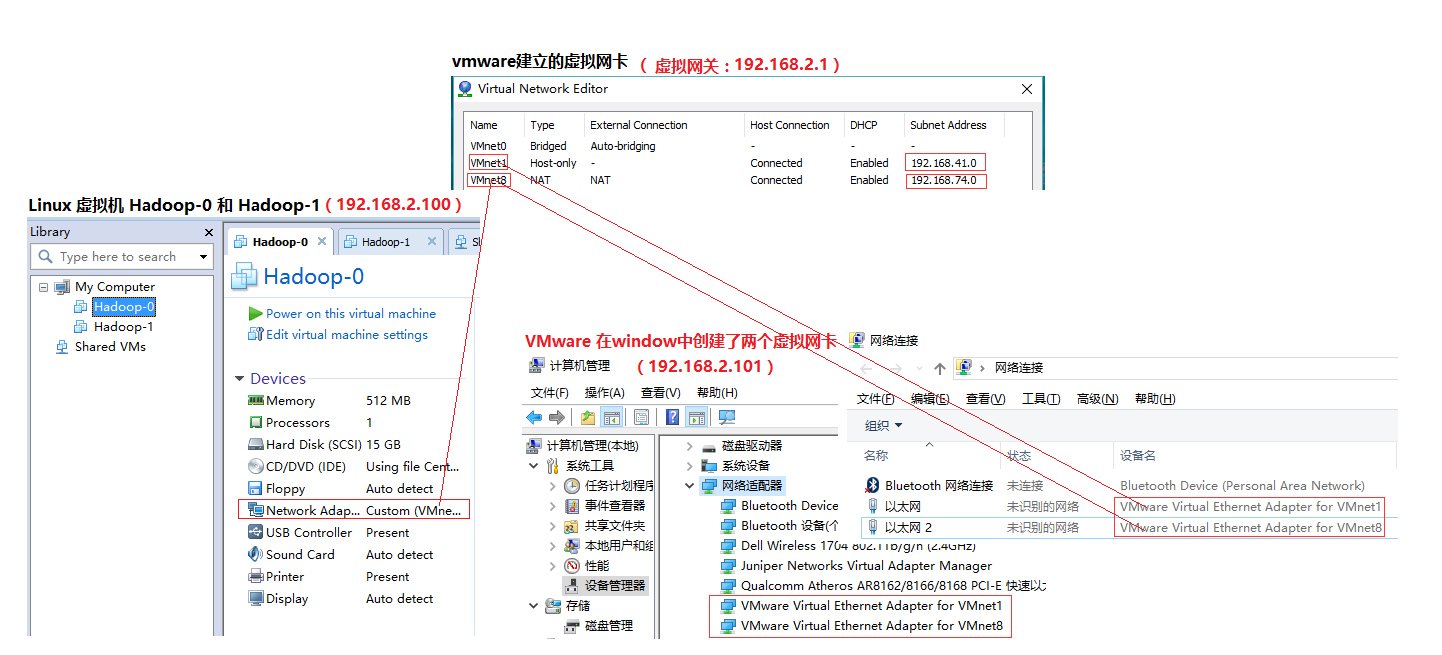
1.配置网络:
VMware在window中生成的那个虚拟网的网关和window是的真实网卡没有任何关系:
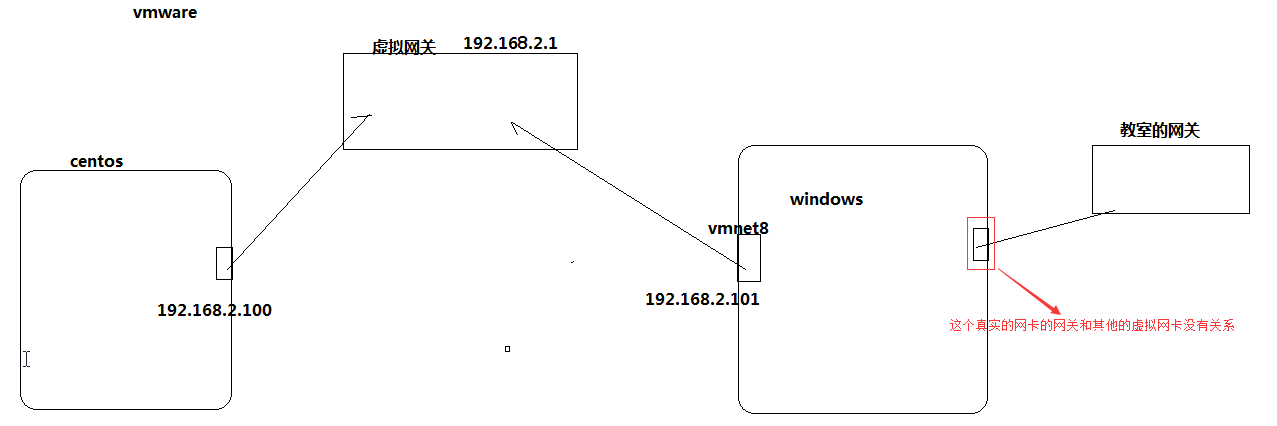
VMware会在windows中提供两个虚拟网卡(VMnet1和VMnet8),如下图

如果想让VMware中的虚拟机(Linux)和本地的windows通信,则必须保证虚拟机和虚拟网卡在同一网段。所以我们需要做如下设置:
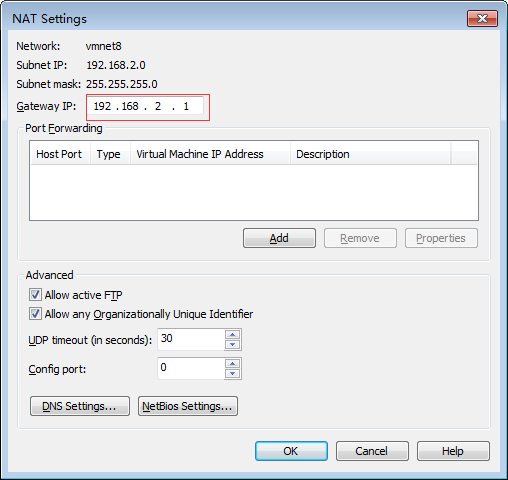
1.1在VMware中设置网关
进入vmware的菜单,Edit->VirtualNetworkEditor
GATEWAY:192.168.2.1
Subnet IP:192.168.2.0
NETMASK:255.255.255.0
修改成功后,可以查看本地系统的网络,VMware的虚拟网卡(VMnet8),应该已经同步到了。

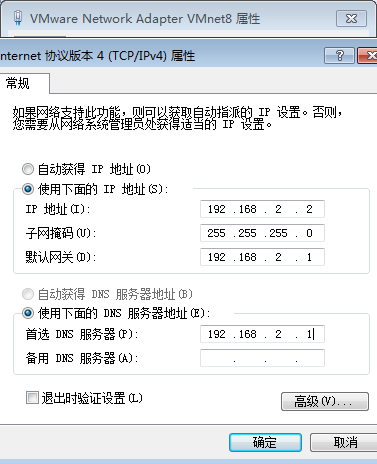
1.2设置虚拟网卡
windows中的VMnet8网卡也要设置成同一网段(如下图)
1.3设置Linux的网络
如果是刚刚新建的Linux,则右键网络图标,选择Edit connections,选择IPv4,新建一个manual的静态IP
如果不是新建的Linux,则可以直接通过setup 命令进行修改 //编辑ifcfg-eth0文件(vi /etc/sysconfig/network-scripts/ifcfg-eth0)
192.168.2.100 255.255.255.0 192.168.2.1 8.8.8.8
然后重启网络:service network restart
ping {网关} ping {linux ip} ping {百度},如果拼通了,则说明成功了!

2.设置虚拟机
2.1开启sshd service,切换到ScureCRT去操作Linux
进入root:su
开启sshd:service sshd start
运行ScureCRT,连接linux,hostname填ip地址
2.2给用户加sudo权限(让普通用户可以执行admin权限的任务):
增加sudoers文件的写权限: su chmod u+w /etc/sudoers
在"root All=(ALL)ALL"下面加 {user name} All=(ALL)ALL: vi /etc/sudoers
去掉sudoers文件的写权限:sudo chmod u-w /etc/sudoers
2.3禁用图形界面:
sudo vi /etc/inittab 将id改成3.
2.4设置sshd service为开机启动项
检查自启动列表:chkconfig --list
设置sshd开机启动:sudo chkconfig sshd on
2.5修改hostname(有两种方式)(由于未来会有多个host,不能都叫locahost,所以要改成hadoop-0之类的名字)
方式一:改配置文件,但是得重启之后才生效。
修改network配置文件:sudo vi /etc/sysconfig/network
重新启动虚拟机之后:可以看到[hadoop@localhost ~]变成[hadoop@hadoop-0 ~]
方式二:、
命令修改 :sudo hostname {hostname}
退出客户端:exit
重新连接客户端(SecureCRT):可以看到效果
2.6修改主机名和IP的映射关系(想要通过hostname访问这台机器,就得做IP映射)
修改hosts文件:sudo vi /etc/hosts 192.1668.2.100 hadoop-0
验证:ping {host name},如果ping通了,则成功了
查看防火墙:
查看 service iptables status
关闭 service iptables stop
查看防火墙开机启动状态:chkconfig iptables --list
关闭开机启动:chkconfig iptables off
重启Linux:
reboot
查看sshd service 状态:
sudo service sshd status 启动sshd service:sudo service sshd start
启动secureCRT,点击Quick connection。(hostname要写成ip)
3.安装JDK
3.1上传JDK:
在SecureCRT中按 Alt+p,打开SFTP窗口,然后输入命令:put {文件路径/文件名}
3.2创建app文件夹:
mkdir app
3.3解压JDK到app文件夹:
tar -zxvf jdk-7u65-linux-i586.tar.gz -C app/
-z:解压编码
x:解压
v:打印
f:文件
-C:解压的目的地
3.4配置环境变量:
在profile文件(/etc/profile)末尾加上以下变量,这个profile文件配置好了以后,对每个用户都生效而不仅仅是当前用户。
export JAVA_HOME=/home/hadoop/app/jdk-7u_65-i585 (javahome 的路径可以先进到app文件里面的jdk文件,然后用命令 pwd 打印出完整路径,然后复制就行了)
export PATH=$PATH:$JAVA_HOME/bin
如果写变量时不记得jdk路径了,则按Esc键退出编辑模式,然后Shift+;,然后输入cd,然后输入文件夹开头字符,然后按Tab键智能提示。
3.5刷新配置:
source /etc/profile
3.6检验配置成功:
回到根目录:cd 验证:java
4.安装Hadoop
4.1上传:
在SecureCRT中按 Alt+p,打开SFTP窗口,然后输入命令:put {文件路径/文件名}
4.2解压:
tar -zxvf {文件名} -C app/
4.3修改Hadoop的配置
进入/home/hadoop/app/hadoop-2.4.1/etc/hadoop。
修改下面的几个文件:
第一个:hadoop-env.sh(环境变量)
位置 : # The java implementation to use. 下面已经有一个缺省的JAVA_HOME变量
修改:export JAVA_HOME=/{JDK路径}/java/jdk1.6.0_45
如果不记得JDK的路径了,在SecureCRT的session tab上右键,选择克隆一个session,输入echo $JAVA_HOME,就可以查出来了,然后鼠标选中,转到原来的session tab 右键就可以复制了
第二个:core-site.xml(启动时需要读这个配置文件)
<configuration>
<!-- 指定HDFS的namenode的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://{主机名}:9000/</value>
</property>
<!-- 指定hadoop运行时产生文件的存放目录,如果不记得路径了,输入pwd可以查看完整路径-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-2.4.1/data/</value>
</property>
</configuration>
第三个:hdfs-site.xml(启动时需要读这个配置文件)
<configuration>
<!-- 配置HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
第四个:mapred-site.xml(启动时需要读这个配置文件)(需要改文件名,mapred-site.xml 原始名加了template,需要去掉,如果不去掉,hadoop将不会读取。命令:mv mapred-site.xml.template mapred-site.xml)
<configuration>
<!-- 指定你的mapreduce程序,应该放到哪个资源调度集群上面去跑。资源调度负责把你的程序的jar,分发,分配给你运行的虚拟机。如果不指定为yarn,则程序只会在本地跑,那么将变成单机版程序,则变得无意义 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
第五个:yarn-site.xml(启动时需要读这个配置文件)
<configuration>
<!-- 指定yarn的老大resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>{主机名}</value>
</property>
<!--reduce获取数据的方式,map出的中间结果怎么传递给reduce,采用哪种机制传,目前只有shuffle这种机制-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
第6个:slaves(datanode的hostname)
cd /home/hadoop/app/hadoop-2.4.1/etc/hadoop
vi slaves
4.4将hadoop添加到环境变量
vim /etc/profile
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
export HADOOP_HOME=/home/hadoop/app/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
4.5格式化HDFS
hadoop namenode -format
验证:log的倒数第5行:Storage directory /tmp/hadoop-hadoop/dfs/name has been successfully formatted.
文件夹 /home/hadoop/app/hadoop-2.4.1/data/dfs/name/current 将生成,并且包含如下文件(name 文件夹就是namenode,namenode将去读这个name文件夹):
| 文件名 | 描述 |
| fsimage_0000000000000000000 | fsimage就是“元数据”:hdfs里面的某一个目录,某一个文件对应的有哪些切块,那些切块分别存放在哪些datanode主机上面?这些东西就是元数据,namenode管理着这些信息,namenode将这些信息就存在namenode自己运行的那台主机的data/dfs/name/current文件夹下面的这个fsimage文件里面。 |
| fsimage_0000000000000000000.md5 | |
| seen_txid | |
| VERSION |
4.6启动hadoop
(进入sbin文件夹,如果你已经将sbin加入到了环境变量,则可以不用进去)
不用启动 start-all.sh,因为all太大了
我们可以只需要启动dfs和yarn就可以:
4.6.1 启动dfs(可以修改slaves文件来指定datanode的地址):
4.6.1.1 启动namenode,登录到namenode的主机(这里我们是伪分布式,所以它会登陆自己)去启动namenode。由于namenode是在配置文件里面配置的,所以程序自己namenode主机的地址。
4.6.1.2 启动datanode,(Q: 我们没有在配置文件里面配置datanode主机的地址,它是怎么知道地址的呢?A:在/home/hadoop/app/hadoop-2.4.1/etc/hadoop/salves文件中定义了需要启动datanode的hostname,默认为localhost,我们可以将其改成真实的hostname,当有多台机器时,可以配置多个hostname)
4.6.1.3 启动second namenode
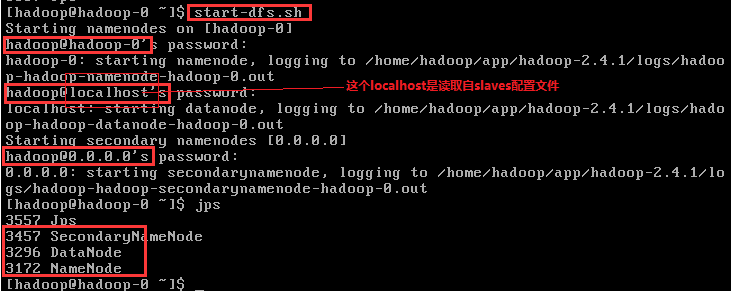
4.6.2.1 启动daemons
启动resourcemanager
启动nodemanager(读取salves文件里面的hostname 列表去登陆host,然后启动每一个host上面的nodemanager,这样的启动有个好处就是,只要在一个主机配置好了机群里面的机器,就可以通过ss登陆去启动集群里面的机器上的进程,不必再去一个一个的登陆host再启动,但是这种方式也有一个缺点,那就是你得不断的输入密码,如果集群里面有大量的机器,那么这样手动的输入密码不但麻烦,而且如果程序等不及,有可能已经timeout了,集群将不能协作了)。
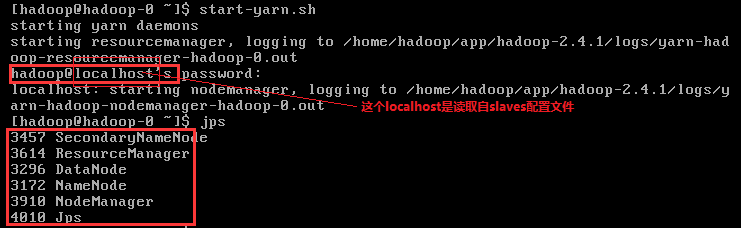
4.7验证集群是否启动成功
用jps命令查看进程(不包括jps应该有5个):
NameNode
SecondaryNameNode
DataNode
JobTracker
TaskTracker
还可以通过浏览器的方式验证
http://192.168.1.110:50070 (hdfs管理界面)
http://192.168.1.110:50030 (mr管理界面)
在这个文件中添加linux主机名和IP的映射关系
C:WindowsSystem32driversetc
3.配置ssh免登陆
生成ssh免登陆密钥
ssh-keygen -t rsa
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免登陆的机器上
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
=======================hdfs和mapreduce测试=======================
hadoop内置了一个jetty 的文本容器,所以有个web 服务可供我们访问。
1. 在本地访问hadoop的web服务
1.1 配置window的hosts(C:WindowsSystem32driversetc)
1.1.1 加入{ip} {hostname}。例如:192.168.2.100 hadoop-0
1.2 访问http://{hostname}:50070
1.3 上传文件:hadoop fs -put {file name} hdfs://hadoop-0:9000/
1.4 下载文件:hadoop fs -get hdfs://hadoop-0:9000/{file name}
1.5 运行demo程序:
cd /home/hadoop/app/hadoop-2.4.1/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.4.1.jar pi 5 5
=======================hdfs实现机制=======================
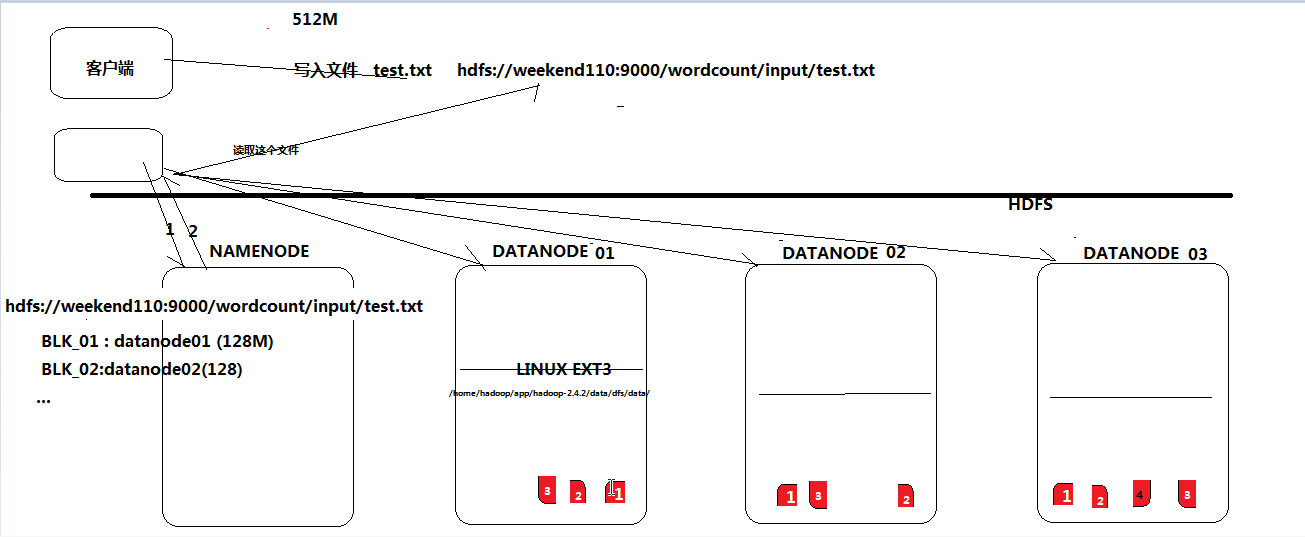
1.hdfs是通过分布式集群来储存文件,不过hadoop为使用者提供了一个便捷的虚拟目录,即:hdfs://{host name}:9000/ ,客户端只需要访问这个虚拟目录就可以访问文件了,不需要知道文件的block文件具体存放在哪里。这些查数据和拿数据的工作,已经被hadoop封装好了
2.文件存储到hdfs集群中时会切成小块(block)存放到若干个datanode节点上
3.hdfs文件系统中的文件与真实的block文件之间的映射关系由namenode管理
4.每个block在集群中会存储多个副本,这样可以提高数据的可靠性和访问的吞吐量