## scrapy的安装 scrapy的底层依赖于lxml, twisted, openssl,涉及到系统C库,所以有可能会导致安装失败。 ```` pip install scrapy apt install python3-scrapy ```` ## scrapy命令 ###创建项目 ``` scrapy startproject qianmu ``` ###生成spider文件 注意:爬虫名字不要和项目名字重复 ```bash #scrapy genspider [爬虫名字] [目标网站域名] scrapy genspider usnews qianmu.iguye.com ``` ### 运行爬虫 ```bash # 运行名为usnewz的爬虫 scrapy crawl usnews # 将爬到的数据导出为Json文件 scrapy crawl usnews -o usnews.json # 导出为csv文件 scrapy crawl usnews -o usnews.csv -t csv # 单独运行爬虫文件 scrapy runspider usnews.py ``` 调试爬虫 ```bash # 进入到scrapy控制台,使用的是项目的环境 scrapy shell # 带一个URL参数,将会自动请求这个url,并在请求成功后进入控制台 scxrapy shell http://url.com ``` 进入到控制台以后,可以使用以下函数和对象 | A | B | | -------- | ------------------------------------------------------------ | | fetch | 请求url或者Requesrt对象,注意:请求成功以后会自动将当前作用域内的request和responsne对象重新赋值 | | view | 用浏览器打开response对象内的网页 | | shelp | 打印帮助信息 | | spider | 相应的Spider类的实例 | | settings | 保存所有配置信息的Settings对象 | | crawler | 当前Crawler对象 | | scrapy | scrapy模块 | ```bash # 用项目配置下载网页,然后用浏览器打开网页 scrapy view url # 用项目配置下载网页,然后输出至控制台 scrapy fetch url ```
创建scrapy_test项目,将会生成一下的路径。
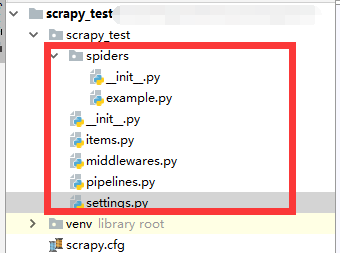
item表示文件的数据储存地方
piplines表示数据的处理
setting配置文件的处理地方
实现爬取top250的页面信息:
#使用命令行运行 from scrapy import cmdline cmdline.execute("scrapy crawl doubanMovie".split())
配置setting


# -*- coding: utf-8 -*- # Scrapy settings for douban project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # http://doc.scrapy.org/en/latest/topics/settings.html # http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html # http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html BOT_NAME = 'douban' SPIDER_MODULES = ['douban.spiders'] NEWSPIDER_MODULE = 'douban.spiders' FEED_URI=u'doubanFile.csv' FEED_FORMAT='CSV' USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0' # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'douban (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'douban.middlewares.DoubanSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'douban.middlewares.MyCustomDownloaderMiddleware': 543, #} # Enable or disable extensions # See http://scrapy.readthedocs.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html #ITEM_PIPELINES = { # 'douban.pipelines.DoubanPipeline': 300, #} # Enable and configure the AutoThrottle extension (disabled by default) # See http://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
写item
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html from scrapy import Item,Field class doubanItem(Item): # define the fields for your item here like: # name = scrapy.Field() title=Field() movieInfo=Field() star =Field() quote =Field()
主文件:
#coding=utf-8 from scrapy.spiders import CrawlSpider from scrapy.http import Request from scrapy.selector import Selector from douban.items import doubanItem '''爬取准备 *目标网站:豆瓣电影TOP250 *目标网址:http://movie.douban.com/top250 *目标内容: *豆瓣电影TOP250部电影的以下信息 *电影名称 *电影信息 *电影评分 *输出结果:生成csv文件 ''' class Douban(CrawlSpider): name = "doubanMovie" redis_key='douban:start_urls' start_urls=['http://movie.douban.com/top250'] url='http://movie.douban.com/top250' def parse(self,response): item=doubanItem() selector=Selector(response) Movies=selector.xpath('//div[@class="info"]') print('Movies',Movies) for eachMoive in Movies: print('eachMoive',eachMoive) title=eachMoive.xpath('div[@class="hd"]/a/span/text()').extract() fullTitle='' print('title',title) for each in title: fullTitle+=each print('eachtitle', each) movieInfo=eachMoive.xpath('div[@class="bd"]/p/text()').extract() star=eachMoive.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract()[0] quote=eachMoive.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract() if quote: quote=quote[0] else: quote='' print('fullTitle',fullTitle) print('movieInfo', movieInfo) print('star', star) print('quote', quote) item['title']=fullTitle item['movieInfo'] = ';'.join(movieInfo) item['star'] = star item['quote'] = quote yield item nextLink=selector.xpath('//span[@class="next"]/link/@href').extract() if nextLink: nextLink=nextLink[0] print(nextLink) yield Request(self.url+nextLink,callback=self.parse)