1、List,Set,Map三者的区别?
List:用于存储一个有序元素的集合。
Set:用于存储一组不重复的元素。
Map:使用键值对存储。Map会维护与Key有关联的值。两个Key可以引用相同的对象,但Key不能重复,典型的Key是String类型,但也可以是任何对象。
补充:
Stack用于存储采用后进先出方式处理的对象。
Queue用于存储采用先进先出方式处理的对象。
PriorityQueue用于存储按照优先级顺序处理的对象。
2、Arraylist 与 LinkedList 区别?
-
(相同点)是否保证线程安全:
ArrayList和LinkedList都是不同步的,也就是不保证线程安全; -
1. 底层数据结构:
Arraylist底层使用的是Object数组;LinkedList底层使用的是双向链表(JDK1.6之前为循环链表,JDK1.7取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!) -
2. 插入和删除是否受元素位置的影响: ①
ArrayList采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候,ArrayList会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ②LinkedList采用链表存储,所以插入、删除元素时间复杂度不受元素位置的影响,都是近似 O(1) 而数组为近似 O(n)。 -
3. 是否支持快速随机访问:
LinkedList不支持高效的随机元素访问,而ArrayList支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。 -
4. 内存空间占用: ArrayList的空间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
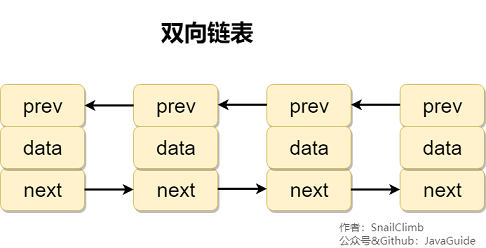
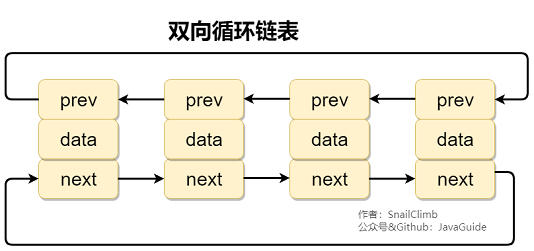
双向链表和双向循环链表:
双向链表: 包含两个指针,一个prev指向前一个节点,一个next指向后一个节点。
双向循环链表: 最后一个节点的 next 指向head,而 head 的prev指向最后一个节点,构成一个环。
3、ArrayList 与 Vector的区别?为什么要用Arraylist取代Vector呢?
Vector类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector的话代码要在同步操作上耗费大量的时间。
Arraylist不是同步的,所以在不需要保证线程安全时建议使用Arraylist。
4、说一说 ArrayList 的扩容机制
( ArrayList扩容发生在add(E e)方法调用的时候)
1. 以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时(add),才真正分配容量。即向数组中添加第一个元素时,数组容量扩为10。(默认初始容量DEFAULT_CAPACITY = 10)
2. 当数组首次扩容的10个空间用完需要扩容后,会走grow方法来扩容(每次扩容为1.5倍)
private void grow(int minCapacity) { // 获取到ArrayList中elementData数组的内存空间长度 int oldCapacity = elementData.length; // 扩容至原来的1.5倍 int newCapacity = oldCapacity + (oldCapacity >> 1); //然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量 if (newCapacity - minCapacity < 0) newCapacity = minCapacity; //若预设值大于默认的最大值检查是否溢出 if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // 调用Arrays.copyOf方法将elementData数组指向新的内存空间时newCapacity的连续空间,并将elementData的数据复制到新的内存空间 elementData = Arrays.copyOf(elementData, newCapacity); }
从此方法中我们可以清晰的看出其实ArrayList扩容的本质就是计算出新的扩容数组的size后实例化,并将原有数组内容复制到新数组中去。
3. 如果新容量大于 MAX_ARRAY_SIZE,执行)hugeCapacity()方法来比较 minCapacity 和 MAX_ARRAY_SIZE,如果minCapacity大于最大容量,则新容量则为Integer.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 Integer.MAX_VALUE - 8。
https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/ArrayList-Grow.md
5、HashMap的底层实现?怎么put、get?put中的resize?(重要!)
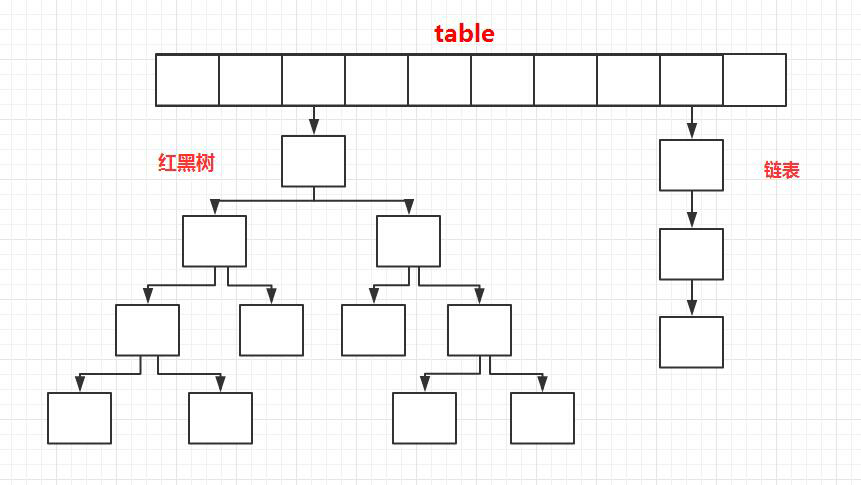
JDK1.8 之前 HashMap 底层是数组+链表结合在一起实现的(HashMap底层就是一个数组结构,数组中的每一项又是一个链表), jdk8 对于链表长度超过 8 的链表将转储为红黑树。
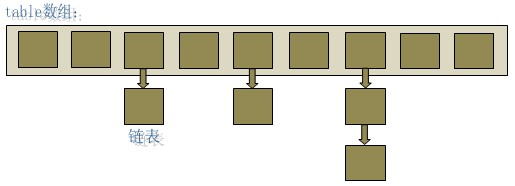
当新建一个HashMap的时候,就会初始化一个数组。Entry就是数组中的元素,每个 Map.Entry 其实就是一个key-value对,它持有一个指向下一个元素的引用,这就构成了链表。
transient Entry[] table; static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; final int hash; ……
HashMap通过key的hashCode得到hash值,然后计算当前元素存放的位置((n - 1) & hash,n指的是数组的长度),如果当前位置存在元素的话,就利用equals方法判断该元素与要存入的元素的key是否相等,如果相等就覆盖其value值,不相等就通过拉链法解决冲突(就是将当前元素与该位置原有元素形成链表,并且当前元素位于链表的头部)。
对于存值和取值,使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。
(1)put(key, value):
- 对key求hash值,然后找到该hash值对应数组中的存储位置。
- 如果当前位置存在元素的话(不为空),就遍历已存在的元素 判断该元素与要存入的元素的key值是否相等,如果相等就覆盖value值;如果不相等就将当前元素添加到到该位置的链表中(当前元素位于链表头部)。
- 如果链表长度超过阀值( TREEIFY THRESHOLD==8),就把链表转成红黑树,当前位置元素长度低于6,就把红黑树转回链表;
- 如果桶满了(容量16*加载因子0.75),就需要 resize(扩容2倍后重排);
public V put(K key, V value) { // HashMap允许存放null键和null值。 // 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。 if (key == null) return putForNullKey(value); // 根据key的keyCode重新计算hash值。 int hash = hash(key.hashCode()); // 搜索指定hash值在对应table中的索引。 int i = indexFor(hash, table.length); // 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素。 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { // 如果发现已有该键值,则存储新的值,并返回原始值 V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } // 如果i索引处的Entry为null,表明此处还没有Entry。 modCount++; // 将key、value添加到i索引处。 addEntry(hash, key, value, i); return null; }
为什么链表长度超过8,就把链表转换为红黑树;桶中元素小于等于6,就将树结构还原为链表?
红黑树的平均查找长度是log(n),当长度为8时,查找长度为log(8)=3;链表的平均查找长度为n/2,当长度为8时,平均查找长度为8/2=4,这才有将链表转换为红黑树的必要。
还有选择6和8的原因是:中间有个差值7可以防止链表和树之间频繁地转换。假设链表个数超过8就将链表转换为树结构、小于8就将树结构转换成链表,那么如果一个HashMap不停地插入、删除元素,链表个数在8左右徘徊,就会频繁地发生树转链表、链表转树,效率会很低。
(2)get(key):
当调用get()方法,首先计算key的hashcode来找到桶位置(数组中对应位置),找到桶位置之后,调用key的equals()方法在对应位置的链表中找到需要的元素。

(3)put中的resize(扩容):
当HashMap中的元素个数超过 数组大小*负载因子(loadFactor)时,就会进行数组扩容(把数组大小扩大一倍),然后重新计算元素在数组中的位置。
Entry<K,V>[] table的初始化长度length(数组大小默认值是16),loadFactor的默认值为0.75。
HashMap不是无限扩容的,当达到了实现预定的MAXIMUM_CAPACITY,就不再进行扩容。
void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; //如果当前的数组长度已经达到最大值,则不在进行调整 if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } //根据传入参数的长度定义新的数组 Entry[] newTable = new Entry[newCapacity]; //按照新的规则,将旧数组中的元素转移到新数组中 transfer(newTable); table = newTable; //更新临界值 threshold = (int)(newCapacity * loadFactor); } //旧数组中元素往新数组中迁移 void transfer(Entry[] newTable) { //旧数组 Entry[] src = table; //新数组长度 int newCapacity = newTable.length; //遍历旧数组 for (int j = 0; j < src.length; j++) { Entry<K,V> e = src[j]; if (e != null) { src[j] = null; do { Entry<K,V> next = e.next; int i = indexFor(e.hash, newCapacity);//放在新数组中的index位置 e.next = newTable[i];//实现链表结构,新加入的放在链头,之前的的数据放在链尾 newTable[i] = e; e = next; } while (e != null); } }
6、 HashMap、Hashtable、ConcurrentHashMap 的区别(重要!)
(1)HashMap
实现了Map接口,实现了将唯一键隐射到特定值上。允许一个NULL键和多个NULL值。非线程安全。
(2)HashTable
类似于HashMap,但是不允许NULL键和NULL值,比HashMap慢,因为它是同步的。HashTable是一个线程安全的类,它使用synchronized来锁住整张Hash表来实现线程安全,即每次锁住整张表让线程独占。
(3)ConcurrentHashMap
ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对hash表的不同部分进行的修改。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的Hashtable,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
Hashtable 和 HashMap不同点?
- Hashtable和HashMap都实现了Map接口,但是Hashtable的实现是基于Dictionary抽象类。
- 在HashMap中,null可以作为键,这样的键只有一个,但可以有一个或多个键所对应的值为null;Hashtable不允许NULL键和NULL值。
当get()方法返回null值时,即可以表示HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键,而应该用containsKey()方法来判断。而在Hashtable中,无论是key还是value都不能为null。
- 这两个类最大的不同在于Hashtable是线程安全的,它的方法是同步了的,可以直接用在多线程环境中。而HashMap则不是线程安全的。在多线程环境中,需要手动实现同步机制。
Hashtable 和ConcurrentHashMap的不同?
(1)HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。(所有访问HashTable的线程都必须竞争同一把锁。)因为当一个线程访问HashTable的同步方法时,其他线程访问HashTable的同步方法可能会进入阻塞或轮询状态。
(2)ConcurrentHashMap使用锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。从而有效地提高了并发访问效率。
Hashtable中采用的锁机制是一次锁住整个hash表,从而同一时刻只能由一个线程对其进行操作;而ConcurrentHashMap中则是 一次锁住一个桶。ConcurrentHashMap默认将hash表分为16个桶,诸如get,put,remove等常用操作只锁当前需要用到的桶。 这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。(16个线程指的是写线程,而读操作大部分时候都不需要用到锁。)
- 底层数据结构: JDK1.7的 ConcurrentHashMap 底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
- 实现线程安全的方式(重要): ① 在JDK1.7的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② Hashtable(同一把锁) :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
HashTable:
JDK1.7的ConcurrentHashMap:
JDK1.8的ConcurrentHashMap(TreeBin: 红黑二叉树节点 Node: 链表节点):
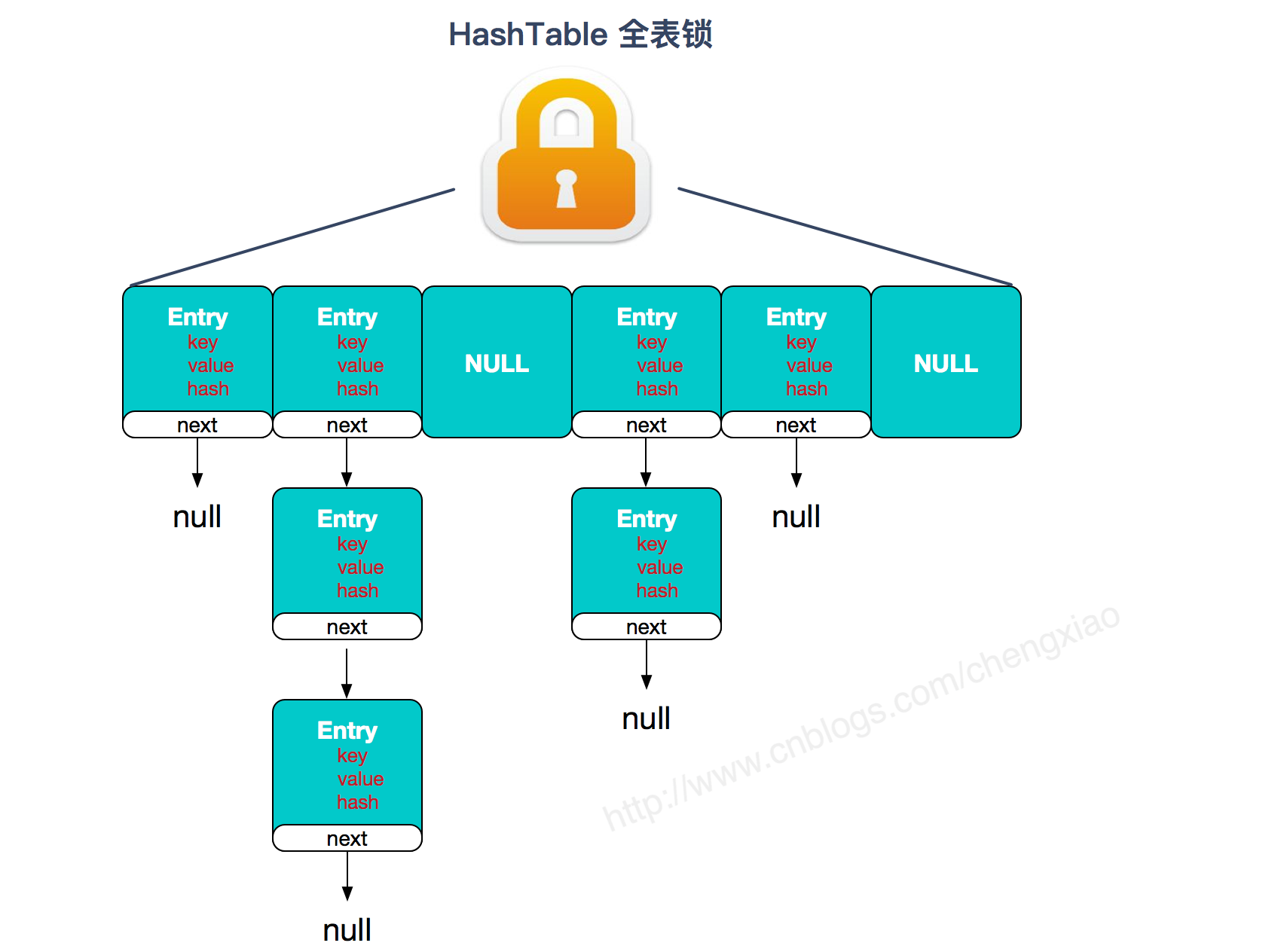

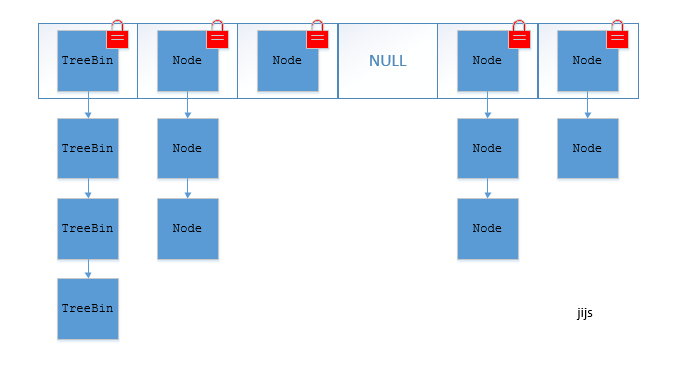
ConcurrentHashMap线程安全的具体实现方式/底层具体实现?
JDK1.7(上面有示意图):
首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和HashMap类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个HashEntry数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment的锁。
JDK1.8 (上面有示意图):
ConcurrentHashMap取消了Segment分段锁,采用CAS和synchronized来保证并发安全。数据结构跟HashMap1.8的结构类似,数组+链表/红黑二叉树。Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(log(N)))
synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
7、HashMap 和 HashSet区别
HashSet 底层就是基于HashMap实现的。(HashSet 的源码非常非常少,因为除了 clone()、writeObject()、readObject()是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。
| HashMap | HashSet |
|---|---|
| 实现了Map接口 | 实现Set接口 |
| 存储键值对 | 仅存储对象 |
调用 put()向map中添加元素 |
调用 add()方法向Set中添加元素 |
| HashMap使用键(Key)计算Hashcode | HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性, |
8、HashSet如何检查重复
当你把对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。
hashCode() 与equals() 的相关规定:
- 如果两个对象相等,则hashcode一定也是相同的;
- 两个对象相等,对两个equals方法返回true;
- 两个对象有相同的hashcode值,它们也不一定是相等的;
- 综上,equals方法被覆盖过,则hashCode方法也必须被覆盖
- hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
==与equals的区别:
- ==是判断两个变量或实例是不是指向同一个内存空间,equals是判断两个变量或实例所指向的内存空间的值是不是相同。
- ==是指对内存地址进行比较,equals()是对字符串的内容进行比较。
- ==指引用是否相同,equals()指的是值是否相同。
9、comparable 和 Comparator的区别
- comparable接口实际上是出自java.lang包,它有一个
compareTo(Object obj)方法用来排序 - comparator接口实际上是出自 java.util 包,它有一个
compare(Object obj1, Object obj2)方法用来排序
内置比较器接口:Comparable<T>----------compareTo(Object obj)方法用来排序:
compareTo(Object obj):该方法用于比较此对象与指定对象的顺序。如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数。 根据不同类的实现返回不同,大部分返回1,0和-1三个数。
public class Student implements Comparable<Student>{ private int id; private String name; private double score; @Override public int compareTo(Student o) { //指定排序规则 return +(this.id - o.id); } } -------------------------------------------------------------------- public void Test() { List<Student> studentList = new ArrayList<Student>(); studentList.add(new Student(1, "刘文杰", 100)); studentList.add(new Student(2, "刘洁", 80)); studentList.add(new Student(3, "李雪", 90)); studentList.add(new Student(4, "黄育航", 59.4)); Collections.sort(studentList); for (Student student : studentList) { System.out.println(student.getId() + ":" + student.getName() + ":"+ student.getScore()); } }
外置比较器接口:Comparator<T>接口-----------compare(T o1,T o2)方法用来排序:
compare(T o1,T o2):比较用来排序的两个参数。返回如果是正整数,则交换两个对象的位置。
public class StudentScoreDescComparator implements Comparator<Student> { @Override public int compare(Student o1, Student o2) { if(o1.getScore() > o2.getScore()){ return -1; }else{ return 1; } } } --------------------------------------------------------------------- public void Test() { List<Student> studentList = new ArrayList<Student>(); studentList.add(new Student(1, "刘文杰", 100)); studentList.add(new Student(2, "刘洁", 80)); studentList.add(new Student(3, "李雪", 90)); studentList.add(new Student(4, "诸葛山珍", 59.4)); Collections.sort(studentList, new StudentScoreDescComparator()); for (Student student : stuList) { System.out.println(student.getId() + ":" + student.getName() + ":"+ student.getScore()); } }
10、如何选用集合?
当我们需要根据键值获取到元素值时就选用Map接口下的集合:
- 需要排序时选择TreeMap;
- 不需要排序时就选择HashMap;
- 需要保证线程安全就选用ConcurrentHashMap。
当我们只需要存放元素值时,就选择实现Collection接口的集合:
- 需要保证元素唯一时选择实现Set接口的集合比如TreeSet或HashSet;
- 不需要就选择实现List接口的比如ArrayList或LinkedList,然后再根据实现这些接口的集合的特点来选用。