4.介绍一下java的数据结构,然后手写一个栈的类
主要可以分为两类:
1)Java中定义了一个接口collection,用来存储一个元素集合
2)另一种是定义了映射(map)用来存储键/值对。
Collection接口为线性表(list)、向量(vector)、栈(stack)、队列(queue)、优先队列(priority queue)以及规则集(set)定义了通用的操作
- Set(规则集)用于存储一组不重复的元素。 重要的实现类:HashSet。
- List(线性表)用于存储一个有序元素的集合(允许重复)。两个重要的实现类:ArrayList(数组线性表类)和 LinkedList(链表类)。
- Stack(栈)用于存储采用后进先出方式处理的对象。
- Queue(队列)用于采用先进先出方式处理的对象。不过队列用双向链表LinkedList实现更好
- PriorityQueue用于存储按照优先级顺序处理的对象。
map(映射)是一个存储“键/值对”集合的容器对象。键很像索引,在List中,索引是整数;在Map中,键可以是任意类型的对象。映射中不能有重复的键,每个键都对于一个值。
线性表、栈、队列、优先队列:
ArrayList、LinkedList 都是线程不安全的。vector是线程安全的。
ArrayList:用数组存储元素。这个数组是动态创建的,如果元素个数超过数组容量,就会创建一个更大的新数组,并将当前数组中的所有元素都复制到新数组中。
- ArrayList的默认容量大小是10。当ArrayList容量不足以容纳全部元素时,ArrayList会重新设置容量:新的容量=“(原始容量x3)/2 + 1”
-
ArrayList实现java.io.Serializable的方式:当写入到输出流时,先写入“容量”,再依次写入“每一个元素”;当读出输入流时,先读取“容量”,再依次读取“每一个元素”。
- ArrayList中的操作不是线程安全的。
-
ArrayList的克隆函数clone(),即是将全部元素克隆到一个数组中。
LinkedList:LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
- LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
- LinkedList中的操作不是线程安全的。
- LinkedList的克隆函数,即是将全部元素克隆到一个新的LinkedList对象中。
vector:向量类,是AbstractList的子类。vector除了包含用于访问和修改向量的同步方法外,与ArrayList是一样的。
- vector是线程安全的。对许多不需要同步的应用程序来说,使用ArrayList比vector效率更高。
stack:栈类,继承自vector,提供了后进先出的数据结构。
- push(o:E)、pop()、peek()
Queue:队列,但一般使用双向链表LinkedList进行队列操作,因为它可以高效的在列表两端插入和删除元素。(LinkedList实现了双端队列Deque接口,Deque又继承自Queue接口)
- offer(o:E)、poll()、peek() (poll()和remove()都获取并移除队列头元素,但如果队列为空poll会返回null,而remove会抛出异常)
PriorityQueue:优先队列,默认情况下,使用Comparable以元素的自然顺序进行排序。
- 拥有最小数值的元素被赋予最高优先级,因此最先从队列中删除。如果几个元素具有相同优先级,则任意选一个。
- 也可使用构造方法 PriorityQueue( initialCapacity, comparator ) 中的 comparator 来指定一个顺序。
规则集和映射:
规则集:HashSet、LinkedHashSet、TreeSet (HashSet与TreeSet都是基于Set接口的实现类。其中TreeSet是Set的子接口SortedSet的实现类)
- HashSet(包括LinkedHashSet)、TreeSet都是线程不安全的。如果有多个线程同时访问一个Set集合,并且有超过一条线程修改了该Set集合,则必须手动保证该Set集合的同步性。
通常可以通过Collections工具类的synchronizedSet方法来"包装"该Set集合。此操作最好在创建时进行,以防止对Set集合的意外非同步访问。
例如:Set hs = Collections.synchronizedSet(new HashSet());
HashSet:实现了Set接口的具体类。默认初始容量16,负载系数0.75。当元素个数超过了容量与负载系数的乘积,容量就会自动翻倍。
- 存储不重复元素,其中的元素没有顺序。
- 集合元素可以是null,但只能放入一个null。
LinkedHashSet:用一个链表实现来扩展HashSet。支持规则集内的元素顺序。
- 存储不重复元素,并按它们插入的顺序获取。
TreeSet:实现了SortedSet接口,SortedSet是Set的一个子接口。
- TreeSet并不是根据元素的插入顺序进行排序,而是根据元素实际值来进行排序的,支持两种排序方式:自然排序 和定制排序,其中自然排序为默认的排序方式。
- 如果试图把一个对象添加进TreeSet时,则该对象的类必须实现Comparable接口,否则程序将会抛出ClassCastException异常。
如果需要实现定制排序(我们这实现倒序),则需要在创建TreeSet集合对象时,并提供一个Comparator对象与该TreeSet集合关联,由该Comparator对象负责集合元素的排序逻辑:
class Person{ Integer age; public Person(int age){ this.age = age; } @Override public String toString() { return "Person [age=" + age + "]"; } } public class Test { public static void main(String[] args){ //实现定制顺序(倒序排) TreeSet<Person> persons = new TreeSet<Person>(new Comparator<Person>(){ @Override public int compare(Person o1, Person o2) { if(o1.age > o2.age){ return -1; }else if(o1.age == o2.age){ return 0; }else{ return 1; } } }); persons.add(new Person(2)); persons.add(new Person(5)); persons.add(new Person(6)); System.out.println(persons); } } //打印结果为[Person [age=6], Person [age=5], Person [age=2]]
映射:HashMap、LinkedHashMap、TreeMap、ConcurrentHashMap
- 如果更新映射时不需要保持映射中元素的顺序,用HashMap;
- 如果需要保持映射中元素的插入顺序或访问顺序,用LinkedHashMap;
- 如果需要使用映射按照键排序,用TreeMap。
HashMap、LinkedHashMap、TreeMap都是线程不安全的,ConcurrentHashMap是线程安全的。
HashMap :
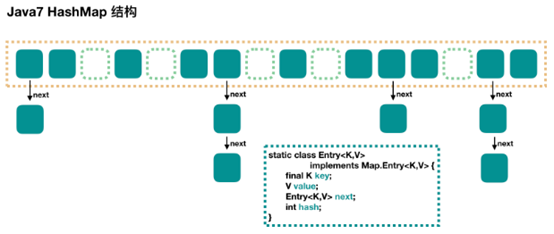
HashMap的主体是一个数组,数组中的每个元素是一个单向链表,链表的一个节点是嵌套类Entry的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next。
- capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。默认的初始容量为16。
- loadFactor:负载因子,默认为 0.75。
- threshold:扩容的阈值,等于 capacity * loadFactor。当HashMap的大小>=阈值,并且新值要插入的数组位置已经有元素了,则进行扩容。
Put方法:
HashMap会对null值key进行特殊处理,总是放到table[0]位置。
put过程是先计算key的hash然后通过hash与table.length取模计算index值,然后将键值对放到table[index]位置,当table[index]已存在其它元素时,会在table[index]位置形成一个单向链表,将新添加的元素放在table[index]所对应链表的头部,原来的元素通过Entry的next进行链接,这样以链表形式解决hash冲突问题,当元素数量达到临界值(capactiy*factor)时,则进行扩容,是table数组长度变为table.length*2
get方法:
同样当key为null时会进行特殊处理,在table[0]的链表上查找key为null的元素。
get的过程是先计算key的hash然后通过hash与table.length取摸计算index值,然后遍历table[index]上的链表,直到找到目标值,然后返回。
resize方法:
这个方法实现了非常重要的hashmap扩容,具体过程为:先创建一个容量为table.length*2的新数组,修改临界值,然后把table里面元素计算hash值并使用hash与table.length*2重新计算index放入到新的table里面。
这里需要注意下是用每个元素的hash全部重新计算index,而不是简单的把原table对应index位置元素简单的移动到新table对应位置。
clear方法:
遍历table然后把每个位置置为null,同时修改元素个数为0。
需要注意的是clear方法只会清除里面的元素,并不会重置capactiy。
containsKey和containsValue:
containsKey方法是先计算hash然后使用hash和table.length取模得到index值,遍历table[index]元素查找是否包含key相同的值。
containsValue方法就比较粗暴了,就是直接遍历所有元素直到找到value
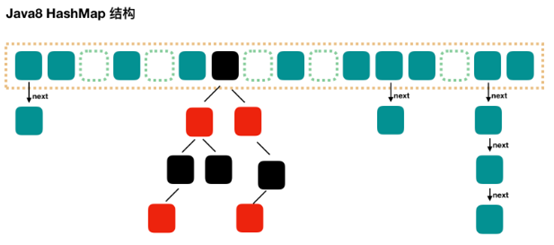
Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑树 组成。在 Java8 中,当链表中的元素超过了 8 个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。

ConcurrentHashMap :
HashMap在并发环境下使用中最为典型的一个问题,就是在HashMap进行扩容重哈希时导致Entry链形成环。一旦Entry链中有环,势必会导致在同一个桶中进行插入、查询、删除等操作时陷入死循环。
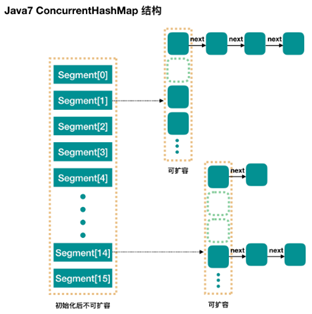
ConcurrentHashMap允许多个修改(写)操作并发进行,其关键在于使用了锁分段技术,它使用了不同的锁来控制对哈希表的不同部分进行的修改(写),而 ConcurrentHashMap 内部使用段(Segment)来表示这些不同的部分。实际上,每个段就是一个小的哈希表,每个段都有自己的锁(Segment 类继承了 ReentrantLock 类)。这样,只要多个修改(写)操作发生在不同的段上,它们就可以并发进行。
ConcurrentHashMap实现线程安全的关键点:
- Segment类继承了ReentrantLock类,对每个段进行写操作时都会加锁。
- 在HashEntry类中,key,hash和next域都被声明为final的,value域被volatile所修饰,因此HashEntry对象几乎是不可变的,这是ConcurrentHashmap读操作并不需要加锁的一个重要原因。
- ConcurrentHashMap中key和value都不允许为空,但在读操作时有可能会出现键值对存在但读出来的value值为空的情形。这种情形发生的场景是:初始化HashEntry时发生的指令重排序导致的,也就是在HashEntry初始化完成之前便返回了它的引用。这时,JDK给出的解决之道就是加锁重读。
- size方法主要思路是先在没有锁的情况下对所有段大小求和,这种求和策略最多执行RETRIES_BEFORE_LOCK次(默认是两次);在超过RETRIES_BEFORE_LOCK之后,如果还不成功就在持有所有段锁的情况下再对所有段大小求和。
相较于JDK1.7,在JDK1.8中,对ConcurrentHashMap做了较大的改动,主要有两方面:
- 取消segments字段,直接采用transient volatile HashEntry<K,V>[] table保存数据,采用table数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。
- 将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构。
参考 https://www.cnblogs.com/be-forward-to-help-others/p/6708130.html
栈基于数组实现: 手写实现一个栈类:
public class Stack { private int maxSize; //栈的大小 private int top; //栈顶的索引号 private char[] arr; public Stack(int size){ maxSize = size; top = -1; arr = new char[maxSize]; } //入栈 public void push(char value){ arr[++top] = value; } //出栈 public char pop(){ return arr[top--]; } //访问栈顶元素 public char peek(){ return arr[top]; } //栈是否为空 public boolean isEmpty(){ return top == -1; } }
5.子类继承父类时,父类的构造方法什么时候调用
父类的构造方法不会被子类继承,它们只能使用关键字super从子类的构造方法中调用。
调用父类构造方法必须使用关键字super , 调用语法:
super() 或 super(参数) (无参构造或有参构造)
//例如B继承自A,假设B想调用A的有参构造方法A(int b, String s) public B (int a, int b, String s) { super(b, s); //调用父类构造方法 this.a = a; }
注意:虽然父类构造方法不会被子类继承,但创建一个子类对象会调用其父类的构造方法!
例:
package simplejava; //父类 class Super { String s; public Super() { System.out.println("Super"); } } //子类 class Sub extends Super { public Sub() { System.out.println("Sub"); } } public class Q { public static void main(String[] args) { Sub s = new Sub(); } }
输出:
Super
Sub
当一个类继承了某个类时,在子类的构造方法里,super()必须先被调用;如果你没有写,编译器会自动调用super()方法,即调用了父类的默认无参构造方法;
这并不是创建了两个对象,其实只有一个子类Sub对象;之所以需要调用父类的构造方法是因为在父类中,可能存在私有属性需要在其构造方法内初始化;
注意:出现错误信息:Implicit super constructor is undefined for default constructor
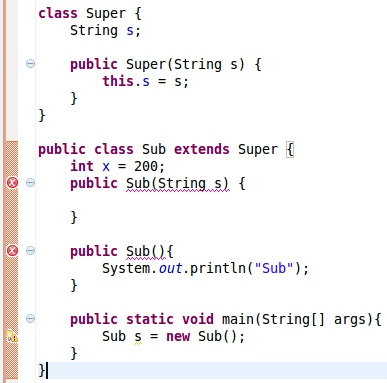
对于子类来说,不管是无参构造方法还是有参构造方法,都会默认调用父类的无参构造方法;当编译器尝试在子类中往这两个构造方法插入super()方法时,因为父类没有一个默认的无参构造方法,所以编译器报错。 (在Java中,如果一个类没有定义构造方法,编译器会默认插入一个无参数的构造方法;但是如果一个构造方法在父类中已定义,在这种情况,编译器是不会自动插入一个默认的无参构造方法,这正是以上demo的情况)
要修复这个错误有以下几种选择:
1、在父类手动定义一个无参构造方法:
public Super(){ System.out.println("Super"); }
2、在子类中自己明确写上父类构造方法的调用;如super(value);

这样就不会报错。
3.移除父类中自定义的构造方法。
参考https://www.cnblogs.com/chenpi/p/5486096.html#_label0
6.static修饰变量、代码块时什么时候执行?执行几次?
在类加载的init阶段,类的类构造器中会收集所有的static块和字段并执行,static块只执行一次,由JVM保证其只执行一次!
public class TestStatic{ public static String name = ""; static{ System.out.println("init ...."); name = "admin"; } public static String getName(){ return name; } public static String getIdAndName(int id){ return id + "---" + name; } public static void main(String[] args) { String name = TestStatic.getName(); String idAndName = TestStatic.getIdAndName(888); System.out.println(name); System.out.println(idAndName); } } 对执行结果分析:
init ....
admin
888---admin
在调用TestStatic类中任何一个方法时,jvm进行类加载,static语句块是在类加载器加载该类的最后阶段进行初始化的。并且只会被初始化一次。
若一次性调用多个方法,则只会执行一次static代码块。
说明:static语句块,不是在实例化的时候被执行的。
static代码块的使用 :
1、项目对某些数据进行初始化,可以在两个地方处理。
第一、就是在项目启动时,加载某个类,对数据进行数据化(如:初始化基础数据或数据库连接池)。
第二、就是在某个工具类中使用static静态代码块,当第一次访问工具类时,就会先进行初始化(只会执行一次),保存到静态全局属性中,当其他类再次访问时,将直接使用初始化数据(如:连接redis数据库,并初始化连接池)。
2、缓存数据