一、前提
爬虫网页(只是演示,切勿频繁请求):https://www.kaola.com/
需要的知识:Python,selenium 库,PyQuery
参考网站:https://selenium-python-zh.readthedocs.io/en/latest/waits.html
二、简单的分析下网站
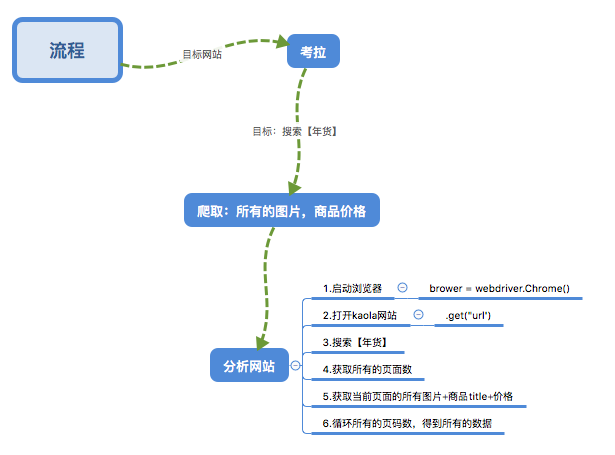
三、步骤
1.目标:
1.open brower
2.open url
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pyquery import PyQuery as py
brower = webdriver.Chrome() //定义一个brower ,声明webdriver,调用Chrome()方法
wait = WebDriverWait(brower,20) //设置一个全局等待时间
brower.get("https://www.kaola.com/")
2.搜索【年货】
def search():
try:
brower.get("https://www.kaola.com/")
//红包
close_windows = wait.until(
EC.presence_of_element_located((By.XPATH,'//div[@class="cntbox"]//div[@class="u-close"]'))
)
//输入框
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#topSearchInput'))
)
//搜索
submit = wait.until(
EC.presence_of_element_located((By.XPATH,'//*[@id="topSearchBtn"]'))
)
close_windows.click()
input.send_keys('年货')
time.sleep(2)
submit.click()
//获取年货所有的页数
total = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#resultwrap > div.splitPages > a:nth-child(11)'))
)
return total.text
except TimeoutException:
return 'error'
3.获取页面的信息
//使用pyQurey解析页面
def get_product(): wait.until( EC.presence_of_element_located((By.XPATH,'//*[@id="result"]//li[@class="goods"]')) ) html = brower.page_source doc = py(html) goods = doc('#result .goods .goodswrap') for good in goods.items(): product = { 'image' : good.find('a').attr('href'), 'title':good.find('a').attr('title'), 'price':good.find('.price .cur').text() } print(product)
def main():
get_product()
brower.close
.....后续更新