map /multimap
map是STL里重要容器之一。
它的特性总结来讲就是:所有元素都会根据元素的键值key自动排序(也可根据自定义的仿函数进行自定义排序),其中的每个元素都是<key, value>的键值对,map中不允许有键值相同的元素,
因此map中元素的键值key不能修改,但是可以通过key修改与其对应的value。如果一定要修改与value对应的键值key,可将已存在的key删除掉,然后重新插入。
定义原型:

它作用应用场景可用作 ①字典 ②统计次数
相关操作
(1)插入操作
方式有3种

注:typedef pair<const Key, T> value_type;
通过插入新元素来扩展容器,通过插入元素的数量有效地增加容器容量。
由于映射中的元素键是唯一的,因此插入操作将检查每个插入的元素是否具有与容器中已有元素相同的键,如果是,则不插入该元素,并将迭代器返回给此现有元素如果函数返回一个值)。
对于允许重复元素的类似容器,请参阅multimap。
在map中插入元素的另一种方法是使用成员函数map :: operator []。
在容器内部,map容器按照其比较对象指定的标准,通过键将所有元素进行排序。这些元素总是按照这个顺序插入到相应的位置。
返回值:
1.单个元素版本(1)返回一个pair,其成员pair :: first被设置为一个迭代器,指向新插入的元素或映射中具有等效键的元素。如果插入了新元素,则将pair中的pair :: second元素设置为true;如果已存在相同的键,则将该元素设置为false。
2.带有提示(2)的版本返回一个迭代器,指向新插入的元素或映射中已经具有相同键的元素。 成员类型迭代器是指向元素的双向迭代器类型
1 /*make_pair内敛函数 返回一个pair对象*/
2 //template<class K, class V>
3 //inline pair<K, V> make_pair(const K& k, const V& v)
4 //{
5 // return pair<K, V>( k,v);
6 //}
7 void test_map_insert( )
8 {
9 //实现一个字典
10 typedef map<string, string>::iterator MyIterator;
11 map<string, string> direct;
12 direct.insert( pair<string, string>("insert", "插入" ));
13 direct.insert( pair<string, string>("sort", "排序" ));
14 direct.insert( make_pair("apple", "苹果" ));
15 direct.insert( make_pair("insert", "插入" ));
16 direct.insert( make_pair("insert", "插入" ));
17 direct.insert( make_pair("sort", "排序" ));
18
19 //(1)pair<iterator, bool> insert( const value_type& V);
20 pair<MyIterator, bool> ret = direct.insert(make_pair("apple", "苹果"));
21 if(ret.second == false) //插入元素已经存在,将second置为false
22 {
23 cout<<" 'apple' is inserted!";
24 //first被设置为一个迭代器,指向新插入的元素或映射中具有等效键的元素
25 cout<< "with value of "<<ret.first->second<<endl;
26 }
27 //(2)指定iterator插入
28 direct.insert(direct.begin( ), make_pair("os1", "操作系统1"));
29 direct.insert(direct.begin( ), make_pair("os2", "操作系统2")); //os2仍在os1后面
30
31 //(3)范围插入
32 map<string, string> another;
33 another.insert(direct.begin( ), direct.end( ));
34
35 //遍历(和set方式类似)
36 MyIterator it = direct.begin( );
37 while( it != direct.end( ))
38 {
39 cout<<it->first<<": "<<it->second<<endl;
40 ++it;
41 }
42 }
(2)operator[]接口
原型如下:

map重载了“[]”运算符。重载的运算符“[]”实质上调用了前面中版本(1)的insert接口,它利用了insert的返回值(一个pair<iterator, bool>类型),最后返回pair中的迭代器所指元素value值的引用。如此,便可通过“[]” 来进行map的插入操作,与此同时,还可对新插入的元素(或插入元素在map已经存在的元素)的value值进行修改。重载[]具体实现如下:
(*((this->insert(make_pair(k,mapped_type()))).first)).second
对它进行大致解析后,可将其修改为:
template<class K, class V>
typedef map<K, V>::iterator MyIterator;
mapped_type& operator[](const K& k)
{
//mapped_type是V值(value)的默认值,value为int的话则默认为0
pair<MyIterator, bool> ret = this->insert(make_pair(k, mapped_type()));
return ret.first->second; //或者 *(ret.first ).second; ret.first是MyIterator迭代器,最后返回迭代器所指元素的second值(也即是value)的引用。
}
例子
// accessing mapped values
#include <iostream>
#include <map>
#include <string>
int main ()
{
std::map<char,std::string> mymap;
mymap['a']="an element";
mymap['b']="another element";
mymap['c']=mymap['b']; //插入key为‘c’的元素,随后将其对应value值修改。
//key为'a'的元素已经插入,此时返回‘a’所对应value的值
std::cout << "mymap['a'] is " << mymap['a'] << '
';
//key为'b'的元素已经插入,此时返回‘b’所对应value的值
std::cout << "mymap['b'] is " << mymap['b'] << '
';
//key为'c'的元素已经插入,此时返回‘c’所对应value的值
std::cout << "mymap['c'] is " << mymap['c'] << '
';
//直接插入key为‘a’的元素,元素对应value值为默认的“”
std::cout << "mymap['d'] is " << mymap['d'] << '
';
std::cout << "mymap now contains " << mymap.size() << " elements.
";
return 0;
}
//结果
/*mymap['a'] is an element
mymap['b'] is another element
mymap['c'] is another element
mymap['d'] is
mymap now contains 4 elements*/
值得注意的是,通过"[]"操作,若能确保查找元素在map中存在,还可以用它进行查找操作。因为在执行“[]”操作的过程中,插入失败会返回与查找元素拥有相同key值的一个iterator。
(3)按自定义顺序排序
通常map对传入的元素,默认是按元素中key值进行排序(即前面定义的Less<Key>),通过前面的map原型定义不难看出它同样支持按自定义的顺序进行比较排序。例如我们自定义的Stu的对象,就可按对象中的年龄来进行排序:
struct Stu
{
string name;
int age;
Stu(const string& na="", int a = 0)
:name( na), age(a) { };
};
//定置一个仿函数
struct compare
{
bool operator( )(const Stu& l, const Stu& r)
{ return l.age < r.age;}
};
void test_insert_compare()
{//按传入Stu对象的年龄排序
multimap<Stu, int, compare>sortmap;
Stu s1("jack", 18);
sortmap.insert(make_pair(s1, 1));
Stu s2( "mike", 20);
sortmap.insert(make_pair(s2, 1));
Stu s3( "zede", 19);
sortmap.insert(make_pair(s3, 1));
map<Stu,int, compare>::iterator it = sortmap.begin( );
while( it != sortmap.end( ))
{
cout<<it->first.name<<": "<<it->first.age<<" --"<<it->second<<endl;
++it;
}
//结果:
//jack: 18 --1
//zede: 19 --1
//mike: 20 --1
}
小应用:据出现次数,统计前K项语言
//定制一个仿函数
typedef map<string, int>::iterator CountIte;
struct compare
{
bool operator()(CountIte lhs, CountIte rhs){
return lhs->second > rhs->second;
}
};
void get_topK_gramar(const vector<string>& v, int k)
{
//统计vector中各种相同key出现的次数
map<string, int> countMap;
for( int i =0; i< v.size( ); ++i)
{
// map<string, int>::iterator it = countMap.find(v[ i]);
// if(it != countMap.end( ))//countmap中存在v[ i]
// ++it->second;
// else
// countMap.insert( make_pair(v[i], 1);
countMap[v[i]]++;
}
//定置仿函数,以每种编程语言出现次数进行排序
//注意:不能用set来排序,因为它会去重,即其会将具有相同value值的某种语言过滤掉
multiset<CountIte, compare> sortSet;
CountIte cit = countMap.begin( );
while( cit != countMap.end( ))
{
sortSet.insert(cit);
++cit;
}
multiset<CountIte, compare>::iterator it1 = sortSet.begin( );
for(; it1 != sortSet.end( ); ++it1)
{
if( k--)
cout<<(*it1)->first<<":"<<(*it1)->second<<endl;
}
}
void test_map_question( )
{
vector<string> v;
v.push_back("python" );
v.push_back("PHP" );
v.push_back("PHP" );
v.push_back("PHP" );
v.push_back("PHP" );
v.push_back("Java" );
v.push_back("PHP" );
v.push_back("C/C++" );
v.push_back("C/C++" );
v.push_back("python" );
v.push_back("Java" );
v.push_back("Java" );
//统计语言次数,或者前K种语言
get_topK_gramar(v, 3);
}
结果:

multimap
multimap和map的唯一差别是map中key必须是唯一的,而multimap中的key是可以重复的。由于不用再判断是否插入了相同key的元素,所以multimap的单个元素版本的insert的返回值不再是一个pair, 而是一个iterator。也正是如此,所以multimap也不再提供operator[]接口。
multimap和map的其它用法基本类似。
unordered_map/unordered_multimap
在C++11中有新出4个关联式容器:unordered_map/unordered_set/unordered_multimap/unordered_multiset。
这4个关联式容器与map/multimap/set/multiset功能基本类似,最主要就是底层结构不同,使用场景不容。
如果需要得到一个有序序列,使用红黑树系列的关联式容器,如果需要更高的查询效率,使用以哈希表为底层的关联式容器。
此处只列举unordered_map,其它用法类似可自行查阅 可参考cplusplus
unordered_map底层实现是用哈希桶实现的:
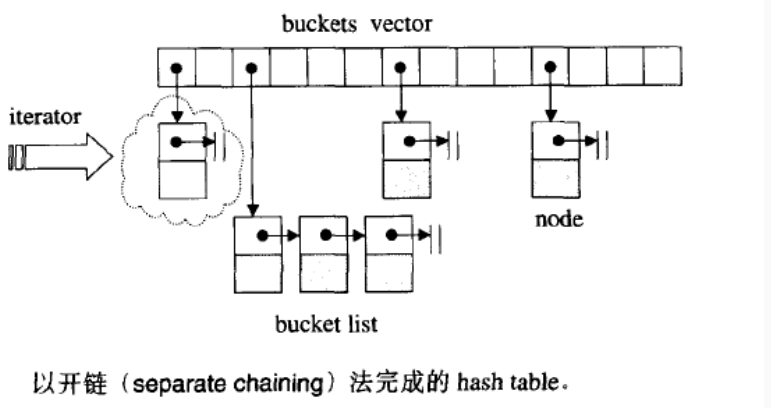
定义原型:

在cplusplus的解释:
无序映射是关联容器,用于存储由键值和映射值组合而成的元素,并允许基于键快速检索各个元素。
在unordered_map中,键值通常用于唯一标识元素,而映射值是与该键关联的内容的对象。键和映射值的类型可能不同。
在内部,unordered_map中的元素没有按照它们的键值或映射值的任何顺序排序,而是根据它们的散列值组织成桶以允许通过它们的键值直接快速访问单个元素(具有常数平均时间复杂度)。
unordered_map容器比映射容器更快地通过它们的键来访问各个元素,尽管它们通过其元素的子集进行范围迭代通常效率较低。
无序映射实现直接访问操作符(operator []),该操作符允许使用其键值作为参数直接访问映射值。
容器中的迭代器至少是前向迭代器。
关键词:无序的 快速的检索 达到的是更快的访问 但是子集的范围迭代效率低
相关操作
1.插入遍历...
typedef unordered_map<string, double>::iterator MyIte;
void test_unordered_map( )
{
unordered_map<string, double> umap;
umap.insert(make_pair("苹果", 2.5));
umap.insert(make_pair("香蕉", 3.0));
umap.insert(make_pair("香蕉", 3.0));
umap.insert(make_pair("西瓜", 1.5));
umap.insert(make_pair("哈密瓜", 3.0));
umap["榴莲"] = 4.0;
MyIte it = umap.begin( );
while( it != umap.end( ))
{
cout<<it->first<<" :"<<it->second<<endl;
++it;
}
cout<<"桶数量:"<<umap.bucket_count( )<<endl;
cout<<"负载因子:"<<umap.load_factor( )<<endl;
//结果:
//榴莲 :4
//苹果 :2.5
//哈密瓜 :3
//香蕉 :3
//西瓜 :1.5
//桶数量:11
//负载因子:0.454545
}
2.自定义比较
struct Store { string name; string addr; Store(const string& na="", const string& ad= "") :name(na),addr( ad){ } bool operator==(const Store& s) const //重载==支持等于比较 { return name == s.name && addr == s.addr; } }; struct hash_key //定制返回哈希值的仿函数 { //BKDRHash size_t operator()(const Store& s) const { size_t seed = 131; /* 31 131 1313 13131 131313 etc.. */ size_t hash = 0; size_t i = 0; for( i = 0; i < s.name.size(); ++i) { hash = ( hash * seed) + s.name[i]; } return hash; } }; typedef unordered_map<Store, int, hash_key>::iterator MyIte; void test_unordered_map( ) { unordered_map<Store, int, hash_key> umap; Store s1("火锅店", "重庆"); Store s2("凉皮店", "西安"); Store s3("烤鸭店", "北京"); umap.insert(make_pair(s1, 1)); umap.insert(make_pair(s2, 1)); umap[s3] = 1; MyIte it = umap.begin( ); while( it != umap.end( )) { cout<<it->first.name<<":"<<it->second<<endl; ++it; } }
3. 性能测试
测试insert 比较map和unordered_map性能差异
typedef unordered_map<int, int>::iterator MyIte;
void test_unordered_map( )
{
unordered_map<int, int> umap;
map<int, int>mp;
srand(time( NULL));
const int N = 100000;
vector<int> a;
for(int i=0; i< N; ++i)
a.push_back(rand()%N);
clock_t begin1,end1;
begin1 = clock();
umap.rehash(100000); //通过rehash设置哈希桶数量,进一步提高效率
for(int i =0; i< N; ++i)
umap[a[i]];
end1 = clock( );
clock_t begin2, end2;
begin2 = clock( );
for( int i =0; i< N; ++i)
mp[a[i]];
end2= clock( );
cout<<"负载因子:"<<umap.load_factor()<<" "<<"桶数:"<<umap.bucket_count( )<<endl;
//统计运行的毫秒差
cout<<"unordered_map:"<<(end1-begin1)/1000<<endl;
cout<<"map:"<<(end2-begin2)/1000<<endl;//统计运行的毫秒差
}
//结果 普通
tp@tp:~$ g++ -std=c++11 1.cc
tp@tp:~$ ./a.out
负载因子:0.500463 桶数:126271
unordered_map:49
map:102
//rehash之后
负载因子:0.585883 桶数:107897
unordered_map:37
map:107
unordered_map 与 map之间差异比较(Linux平台下)
·map底层为红黑树查找大致为logN的时间复杂度;unordered_map底层是闭散列的哈希桶,查找为O(1),性能更优。
·调用insert操作,map相较于unordered_map操作慢,大致有2到3倍差异;但是map插入更加稳定
·unordered_map的erase操作会缩容,导致元素重新映射,降低性能。
·unordered_map要求传入的数据能够进行大小比较,“==”关系比较;所以自定义数据需要定置hash_value仿函数同时重载operator==。