1 SQL Server中的索引
索引是与表或视图关联的磁盘上结构,可以加快从表或视图中检索行的速度。索引包含由表或视图中的一列或多列生成的键。这些键存储在一个结构(B 树)中,使 SQL Server 可以快速有效地查找与键值关联的行。
表或视图可以包含以下类型的索引:
聚集索引
聚集索引根据数据行的键值在表或视图中排序和存储这些数据行。索引定义中包含聚集索引列。每个表只能有一个聚集索引,因为数据行本身只能按一个顺序排序。
只有当表包含聚集索引时,表中的数据行才按排序顺序存储。如果表具有聚集索引,则该表称为聚集表。如果表没有聚集索引,则其数据行存储在一个称为堆的无序结构中。
每个表几乎都对列定义聚集索引来实现下列功能:
1、可用于经常使用的查询。
2、提供高度唯一性。
在创建聚集索引之前,应先了解数据是如何被访问的。考虑对具有以下特点的查询使用聚集索引:
使用运算符(如 BETWEEN、>、>=、< 和 <=)返回一系列值。
使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行物理相邻。例如,如果某个查询在一系列采购订单号间检索记 录,PurchaseOrderNumber 列的聚集索引可快速定位包含起始采购订单号的行,然后检索表中所有连续的行,直到检索到最后的采购订单号。
返回大型结果集。
使用 JOIN 子句;一般情况下,使用该子句的是外键列。
使用 ORDER BY 或 GROUP BY 子句。
在 ORDER BY 或 GROUP BY 子句中指定的列的索引,可以使数据库引擎 不必对数据进行排序,因为这些行已经排序。这样可以提高查询性能。
聚集索引不适用于具有下列属性的列:
频繁更改的列
这将导致整行移动,因为数据库引擎 必须按物理顺序保留行中的数据值。这一点要特别注意,因为在大容量事务处理系统中数据通常是可变的。
宽键
宽键是若干列或若干大型列的组合。所有非聚集索引将聚集索引中的键值用作查找键。为同一表定义的任何非聚集索引都将增大许多,这是因为非聚集索引项包含聚集键,同时也包含为此非聚集索引定义的键列。 非聚集索引
非聚集索引具有独立于数据行的结构。非聚集索引包含非聚集索引键值,并且每个键值项都有指向包含该键值的数据行的指针。
从非聚集索引中的索引行指向数据行的指针称为行定位器。行定位器的结构取决于数据页是存储在堆中还是聚集表中。对于堆,行定位器是指向行的指针。对于聚集表,行定位器是聚集索引键。
在 SQL Server 2005 中,可以向非聚集索引的叶级别添加非键列以跳过现有的索引键限制(900 字节和 16 键列),并执行完整范围内的索引查询。
非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点:
1、基础表的数据行不按非聚集键的顺序排序和存储。
2、非聚集索引的叶层是由索引页而不是由数据页组成。
设计非聚集索引时需要注意数据库的特征:
更新要求较低但包含大量数据的数据库或表可以从许多非聚集索引中获益从而改善查询性能。
决策支持系统应用程序和主要包含只读数据的数据库可以从许多非聚集索引中获益。查询优化器具有更多可供选择的索引用来确定最快的访问方法,并且数据库的低更新特征意味着索引维护不会降低性能。
联机事务处理应用程序和包含大量更新表的数据库应避免使用过多的索引。此外,索引应该是窄的,即列越少越好。
一个表如果建有大量索引会影响 INSERT、UPDATE 和 DELETE 语句的性能,因为所有索引都必须随表中数据的更改进行相应的调整。
唯一索引
唯一索引确保索引键不包含重复的值,因此,表或视图中的每一行在某种程度上是唯一的。
聚集索引和非聚集索引都可以是唯一索引。
包含性列索引
一种非聚集索引,它扩展后不仅包含键列,还包含非键列。
索引涵盖
指查询中的SELECT与WHERE子句的所用列同时也属于非聚集索引的情况。这样就可以更快检索数据,因为所有信息都可以直接来自于索引页,从而SQL Server可以避免访问数据页。加上独立的索引文件组,可以用最快速度访问数据。
请看如下表示例:
A.创建简单非聚集索引 以下示例为 Purchasing.ProductVendor 表的 VendorID 列创建非聚集索引。
USE AdventureWorks;
GO
CREATE INDEX IX_ProductVendor_VendorID
ON Purchasing.ProductVendor (VendorID);
GO
B. 创建简单非聚集组合索引
以下示例为 Sales.SalesPerson 表的 SalesQuota 和 SalesYTD 列创建非聚集组合索引。
CREATE NONCLUSTERED INDEX IX_SalesPerson_SalesQuota_SalesYTD
ON Sales.SalesPerson (SalesQuota, SalesYTD);
GO
C. 创建唯一非聚集索引
以下示例为 Production.UnitMeasure 表的 Name 列创建唯一的非聚集索引。该索引将强制插入 Name 列中的数据具有唯一性。
USE AdventureWorks;
GO
CREATE UNIQUE INDEX AK_UnitMeasure_Name
ON Production.UnitMeasure(Name);
GO
无论何时对基础数据执行插入、更新或删除操作,SQL Server 2005 数据库引擎都会自动维护索引。随着时间的推移,这些修改可能会导致索引中的信息分散在数据库中(含有碎片)。当索引包含的页中的逻辑排序(基于键值)与数 据文件中的物理排序不匹配时,就存在碎片。碎片非常多的索引可能会降低查询性能,导致应用程序响应缓慢。这个时候,我们需要做得就是重新组织和重新生成索 引。重新生成索引将删除该索引并创建一个新索引。此过程中将删除碎片,通过使用指定的或现有的填充因子设置压缩页来回收磁盘空间,并在连续页中对索引行重 新排序(根据需要分配新页)。这样可以减少获取所请求数据所需的页读取数,从而提高磁盘性能。
可以使用下列方法重新生成聚集索引和非聚集索引:
带 REBUILD 子句的 ALTER INDEX。此语句将替换 DBCC DBREINDEX 语句。
带 DROP_EXISTING 子句的 CREATE INDEX。
示例如下:
A. 重新生成索引
以下示例将重新生成单个索引。
USE AdventureWorks;
GO
ALTER INDEX PK_Employee_EmployeeID ON HumanResources.Employee
REBUILD;
GO
B.重新生成表的所有索引并指定选项
下面的示例指定了 ALL 关键字。这将重新生成与表相关联的所有索引。其中指定了三个选项。
ALTER INDEX ALL ON Production.Product
REBUILD WITH (FILLFACTOR = 80, SORT_IN_TEMPDB = ON,
STATISTICS_NORECOMPUTE = ON);
GO
2 Oracle 中的索引
索引是Oracle使用的加速表中数据检索的数据库对象。
下面的情况,可以考虑使用索引:
1) 大表
2) 主键(自动索引)
3) 单键列(自动索引)
4) 外键列(自动索引)
5) 大表上WHERE子句常用的列
6) ORDER BY 或者GROUP BY子句中使用的列。
7) 至少返回表中20%行的查询
8) 不包含null值的列。
Oracle中的索引包含有如下几种类型:
B*树索引:这是Oracle中最常用的索引,它的构造类似于二叉树,能根据键提供一行或一个行集的快速访问,通常只需要很少的读操作就能找到正确的行。B*树索引由两列组成,第一列是ROWID, 它是行的位置;第二列是正被索引列的值。
图:典型的B*树索引布局
这个树底层的块称为叶子节点(leaf node) 或(leaf block),其中分别包含各个索引键以及一个rowid(它是指向所索引的行)。叶子节点之上的内部块称为分支块(branch block),这些节点用于实现导航。例如,如果想在索引中找到值20,要从树顶开始,找到左分支,我们检查这个块,并发现需要找到范围"20..25" 的块,这个块将是叶子块,其中会指示包含数20的行。索引的叶子节点实际上构成了一个双向链表。一旦发现要从叶子节点中的那里开始,执行值的有序扫描 (index range scan)就会很容易,我们就不必再在索引结构中导航:而只需根据叶子节点向前或向后扫描就可以了。
B*树的特点之一是:所有叶子块都应该在树的同一层上,这一层称之为索引的高度, 它说明所有从索引的根块到叶子块的遍历都会访问同样数目的块。也就是说,对于形如"SELECT INDEX_column FROM TABLE WHERE INXDEX_column =:X"的索引,要达到叶子块来获取第一行,不论使用的:X值是什么,都会执行同样数目的I/O,由此可见B*树的B代表的是balanced,所谓的"Height balanced"。大多数B*树索引的高度都是2或3,即使索引中有数百万行记录也是如此,这说明,一般而言,在索引中找到一个键只需要2到3次I/O , 这确实不错。
B*树是一个极佳的通用索引机制,无论是大表还是小表都很适用,随着底层表大小增长,获取数据的性能仅会稍有恶化。
比如,我们为customers表建立一个常见的B*树索引:
CREATE INDEX IDX_Cus_City on customers(city)
B*树索引有以下子类型:
复合索引
复合索引也是一种B*树索引,它由多列组成。当我们拥有使用两列或超过两列的频繁查询时,就使用B*树复合索引,而其所使用的两列或多列在 where子句中and逻辑操作符连接。因为复合索引中列的顺序很重要,所以确信以最有效的索引能排列他们,可以参考用作列排序的下面的两个准则 :
1) 前导列应该是查询中使用最频繁的列。
2) 前导列应该是选择最多的列,这意味着它比后面的列具有更高的基数。
复合索引在下列情况中具有优势:
1)假定在WHERE子句中频繁使用下面的条件:order_status_id = 1 和order_date = ‘dd-mon-yyyy’。如果为每一列创建一个索引,那么为了搜索列的值,两个索引都要被读取,但是如果为两列都创建一个复合索引,那么只有一个索引 被读取,这样无疑比两个索引要求更少的I/O。
2) 使用前面例子中同样的条件,如果创建一个复合索引,将更快地检索行,因为你正在排除了所有order_status_id 不是1的行,从而减少了搜索order_date的行数。
反向键索引
B*树索引的另一个特点是能够将索引键“反转”。首先,你可以问问自己“为什么想这么做?” B*树索引是为特定的环境、特定的问题而设计的。实现B*树索引的目的是为了减少“右侧”索引中对索引叶子块的竞争,比如在一个Oracle RAC 环境中,某些列用一个序列值或时间戳填充,这些列上建立的索引就属于“右侧”(right-hand-side)索引。
RAC 是一种Oracle 配置,其中多个实例可以装载和打开同一个数据库。如果两个实例需要同时修改同一个数据块,它们会通过一个硬件互连(interconnect)来回传递这 个块来实现共享,互连是两个(或多个)机器之间的一条专用网络连接。如果某个利用一个序列填充,这个列上有一个主键索引 ,那么每个人插入新值时,都会视图修改目前索引结构右侧的左块(见本文图一,其中显示出索引中较高的值都放在右侧,而较低的值放在左侧)。如果对用序列填 充的列上的索引进行修改,就会聚集在很少的一组叶子块上。倘若将索引的键反转,对索引进行插入时,就能在索引中的所有叶子键上分布开(不过这往往会使索引 不能得到充分地填充)。
反向键索引创建语句语法如下:
CREATE INDEX index_name on table_name(column_name) REVERSE ;
降序索引
降序索引(descending index)是oracle 8i引入的,用以扩展B*树索引的功能,它允许在索引中以降序(从大到小的顺序)存储一列。在oracle8i及以上版本中,DESC关键字确实会改变创建和使用索引的的方式。
我们可以这样创建降序索引
CREATE INDEX IDX_jobs_title on hr.jobs (job_title DESC);
SET autotrace traceonly EXPLAIN;
SELECT * FROM hr.jobs
WHERE job_title Between 'a' AND 'ZZZZZZZZZZZ '; Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=1 Card=1 Bytes=33)
1 0 FILTER
2 1 TABLE ACCESS (BY INDEX ROWID) OF 'JOBS' (Cost=1 Card=1 B
ytes=33)
3 2 INDEX (RANGE SCAN) OF 'IDX_JOBS_TITLE' (NON-UNIQUE) (C
ost=2 Card=1)
SQL> SELECT * from hr.jobs
2 WHERE job_title between 'a' and 'ZZZZZZZZZZZ ';
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=1 Bytes=33)
1 0 FILTER
2 1 TABLE ACCESS (FULL) OF 'JOBS' (Cost=2 Card=1 Bytes=33)
SQL> DROP INDEX IDX_jobs_title ;
SQL> CREATE INDEX IDX_jobs_title on hr.jobs (job_title );
SQL> Select * FROM hr.jobs
2 Where job_title between 'a' and 'ZZZZZZZZZZZ ';
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=1 Bytes=33)
1 0 FILTER
2 1 TABLE ACCESS (FULL) OF 'JOBS' (Cost=2 Card=1 Bytes=33)
位图索引
位图索引(bitmap index)是从Oracle7.3 版本开始引入的。目前Oracle企业版和个人版都支持位图索引,但标准版不支持。位图索引是为数据仓库/在线分析查询环境设计的,在此所有查询要求的数据在系统实现时根本不知道。位图索引特别不适用于OLTP 系统,如果系统中的数据会由多个并发会话频繁地更新,这种系统也不适用位图索引。
位图索引是这样一种结构,其中用一个索引键条目存储指向多行的指针;这与B*树结构不同,在B*树结构中,索引键和表中的行存在着对应关系。在位图索引中,可能只有很少的索引条目,每个索引条目指向多行。而在传统的B*树中,一个索引条目就指向一行。
B*树索引一般来讲应当是选择性的。与之相反,位图索引不应是选择性的,一般来讲它们应该“没有选择性“。如果有大量在线分析查询,特别是查询 以一种即席方式引用了多列或者会生成诸如COUNT 之类的聚合,在这样的环境中,位图索引就特别有用 。位图索引使用 CREATE BITMAP INDEX index_name ON table_name(column_name1,column_name2) TABLESPACE tablespace_name命令语法创建。
SQL Server查询优化技术及索引
From: http://www.cnblogs.com/lovewindy/archive/2005/02/19/105959.html
在《数据库原理》里面,对聚簇索引的解释是:聚簇索引的顺序就是数据的物理存储顺序,而对非聚簇索引的解释是:索引顺序与数据物理排列顺序无关。正式因为如此,所以一个表最多只能有一个聚簇索引。
不过这个定义太抽象了。在SQL Server中,索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。如下图:
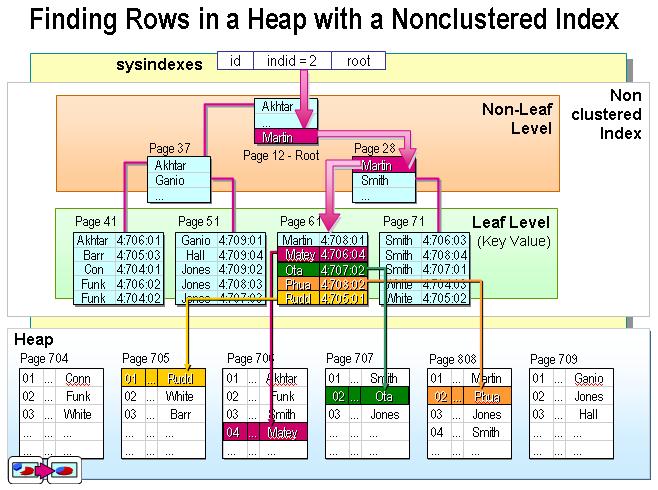
非聚簇索引
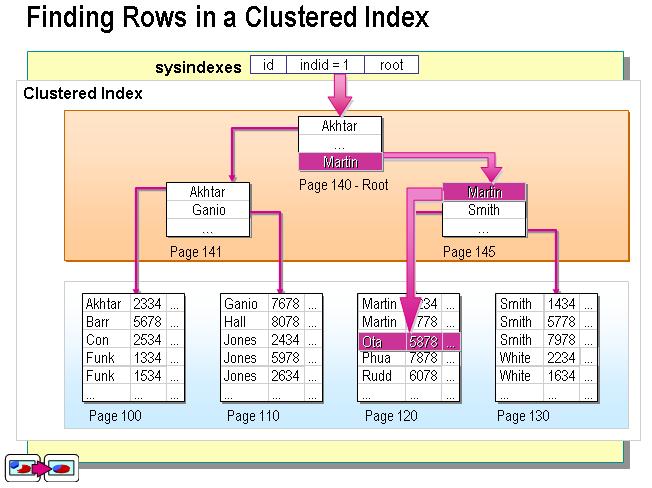
聚簇索引
聚簇索引与非聚簇索引的本质区别到底是什么?什么时候用聚簇索引,什么时候用非聚簇索引?
这是一个很复杂的问题,很难用三言两语说清楚。我在这里从SQL Server索引优化查询的角度简单谈谈(如果对这方面感兴趣的话,可以读一读微软出版的《Microsoft SQL Server 2000数据库编程》第3单元的数据结构引论以及第6、13、14单元)。
一、索引块与数据块的区别
大家都知道,索引可以提高检索效率,因为它的二叉树结构以及占用空间小,所以访问速度块。让我们来算一道数学题:如果表中的一条记录在磁盘上占用1000字节的话,我们对其中10字节的一个字段建立索引,那么该记录对应的索引块的大小只有10字节。我们知道,SQL Server的最小空间分配单元是“页(Page)”,一个页在磁盘上占用8K空间,那么这一个页可以存储上述记录8条,但可以存储索引800条。现在我们要从一个有8000条记录的表中检索符合某个条件的记录,如果没有索引的话,我们可能需要遍历8000条×1000字节/8K字节=1000个页面才能够找到结果。如果在检索字段上有上述索引的话,那么我们可以在8000条×10字节/8K字节=10个页面中就检索到满足条件的索引块,然后根据索引块上的指针逐一找到结果数据块,这样IO访问量要少的多。
二、索引优化技术
是不是有索引就一定检索的快呢?答案是否。有些时候用索引还不如不用索引快。比如说我们要检索上述表中的所有记录,如果不用索引,需要访问8000条×1000字节/8K字节=1000个页面,如果使用索引的话,首先检索索引,访问8000条×10字节/8K字节=10个页面得到索引检索结果,再根据索引检索结果去对应数据页面,由于是检索所有数据,所以需要再访问8000条×1000字节/8K字节=1000个页面将全部数据读取出来,一共访问了1010个页面,这显然不如不用索引快。
SQL Server内部有一套完整的数据检索优化技术,在上述情况下,SQL Server的查询计划(Search Plan)会自动使用表扫描的方式检索数据而不会使用任何索引。那么SQL Server是怎么知道什么时候用索引,什么时候不用索引的呢?SQL Server除了日常维护数据信息外,还维护着数据统计信息,下图是数据库属性页面的一个截图:
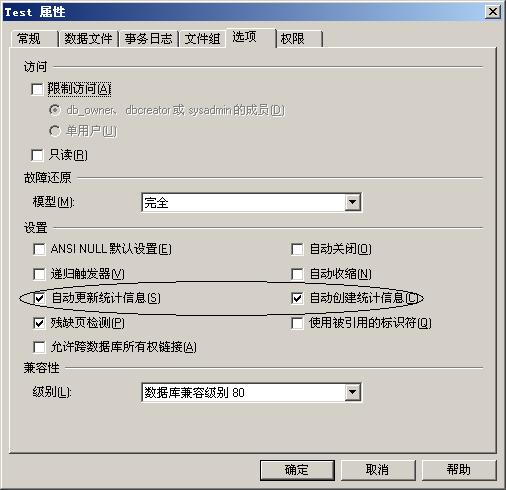
从图中我们可以看到,SQL Server自动维护统计信息,这些统计信息包括数据密度信息以及数据分布信息,这些信息帮助SQL Server决定如何制定查询计划以及查询是是否使用索引以及使用什么样的索引(这里就不再解释它们到底如何帮助SQL Server建立查询计划的了)。我们还是来做个实验。建立一张表:tabTest(ID, unqValue,intValue),其中ID是整形自动编号主索引,unqValue是uniqueidentifier类型,在上面建立普通索引,intValue 是整形,不建立索引。之所以挂上一个没有索引的intValue字段,就是防止SQL Server使用索引覆盖查询优化技术,这样实验就起不到作用了。向表中录入10000条随机记录,代码如下:
![]() CREATE TABLE [dbo].[tabTest] (
CREATE TABLE [dbo].[tabTest] ( ![]() [ID] [int] IDENTITY (1, 1) NOT NULL ,
[ID] [int] IDENTITY (1, 1) NOT NULL , ![]() [unqValue] [uniqueidentifier] NOT NULL ,
[unqValue] [uniqueidentifier] NOT NULL , ![]() [intValue] [int] NOT NULL
[intValue] [int] NOT NULL ![]() ) ON [PRIMARY]
) ON [PRIMARY] ![]() GO
GO ![]()
![]() ALTER TABLE [dbo].[tabTest] WITH NOCHECK ADD
ALTER TABLE [dbo].[tabTest] WITH NOCHECK ADD ![]() CONSTRAINT [PK_tabTest] PRIMARY KEY CLUSTERED
CONSTRAINT [PK_tabTest] PRIMARY KEY CLUSTERED ![]() (
( ![]() [ID]
[ID] ![]() ) ON [PRIMARY]
) ON [PRIMARY] ![]() GO
GO ![]()
![]() ALTER TABLE [dbo].[tabTest] ADD
ALTER TABLE [dbo].[tabTest] ADD ![]() CONSTRAINT [DF_tabTest_unqValue] DEFAULT (newid()) FOR [unqValue]
CONSTRAINT [DF_tabTest_unqValue] DEFAULT (newid()) FOR [unqValue] ![]() GO
GO ![]()
![]() CREATE INDEX [IX_tabTest_unqValue] ON [dbo].[tabTest]([unqValue]) ON [PRIMARY]
CREATE INDEX [IX_tabTest_unqValue] ON [dbo].[tabTest]([unqValue]) ON [PRIMARY] ![]() GO
GO ![]()
![]() declare @i int
declare @i int ![]() declare @v int
declare @v int ![]()
![]() set @i=0
set @i=0 ![]() while @i<10000
while @i<10000 ![]() begin
begin ![]() set @v=rand()*1000
set @v=rand()*1000 ![]() insert into tabTest ([intValue]) values (@v)
insert into tabTest ([intValue]) values (@v) ![]() set @i=@i+1
set @i=@i+1 ![]() end
end ![]()
![]()
然后我们执行两个查询并查看执行计划,如图:(在查询分析器的查询菜单中可以打开查询计划,同时图上第一个查询的GUID是我从数据库中找的,大家做实验的时候可以根据自己数据库中的值来定):
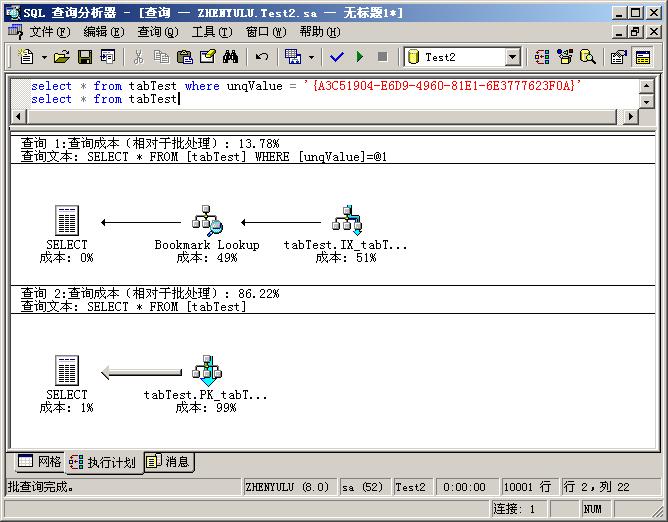
从图中可以看出,在第一个查询中,SQL Server使用了IX_tabTest_unqValue索引,根据箭头方向,计算机先在索引范围内找,找到后,使用Bookmark Lookup将索引节点映射到数据节点上,最后给出SELECT结果。在第二个查询中,系统直接遍历表给出结果,不过它使用了聚簇索引,为什么呢?不要忘了,聚簇索引的页节点就是数据节点!这样使用聚簇索引会更快一些(不受数据删除、更新留下的存储空洞的影响,直接遍历数据是要跳过这些空洞的)。
下面,我们在SQL Server中将ID字段的聚簇索引更改为非聚簇索引,然后再执行select * from tabTest,这回我们看到的执行计划变成了:

SQL Server没有使用任何索引,而是直接执行了Table Scan,因为只有这样,检索效率才是最高的。
三、聚簇索引与非聚簇索引的本质区别
现在可以讨论聚簇索引与非聚簇索引的本质区别了。正如本文最前面的两个图所示,聚簇索引的叶节点就是数据节点,而非聚簇索引的页节点仍然是索引检点,并保留一个链接指向对应数据块。
还是通过一道数学题来看看它们的区别吧:假设有一8000条记录的表,表中每条记录在磁盘上占用1000字节,如果在一个10字节长的字段上建立非聚簇索引主键,需要二叉树节点16000个(这16000个节点中有8000个叶节点,每个页节点都指向一个数据记录),这样数据将占用8000条×1000字节/8K字节=1000个页面;索引将占用16000个节点×10字节/8K字节=20个页面,共计1020个页面。
同样一张表,如果我们在对应字段上建立聚簇索引主键,由于聚簇索引的页节点就是数据节点,所以索引节点仅有8000个,占用10个页面,数据仍然占有1000个页面。
下面我们看看在执行插入操作时,非聚簇索引的主键为什么比聚簇索引主键要快。主键约束要求主键不能出现重复,那么SQL Server是怎么知道不出现重复的呢?唯一的方法就是检索。对于非聚簇索引,只需要检索20个页面中的16000个节点就知道是否有重复,因为所有主键键值在这16000个索引节点中都包含了。但对于聚簇索引,索引节点仅仅包含了8000个中间节点,至于会不会出现重复必须检索另外1000个页数据节点才知道,那么相当于检索10+1000=1010个页面才知道是否有重复。所以聚簇索引主键的插入速度要比非聚簇索引主键的插入速度慢很多。
让我们再来看看数据检索的效率,如果对上述两表进行检索,在使用索引的情况下(有些时候SQL Server执行计划会选择不使用索引,不过我们这里姑且假设一定使用索引),对于聚簇索引检索,我们可能会访问10个索引页面外加1000个数据页面得到结果(实际情况要比这个好),而对于非聚簇索引,系统会从20个页面中找到符合条件的节点,再映射到1000个数据页面上(这也是最糟糕的情况),比较一下,一个访问了1010个页面而另一个访问了1020个页面,可见检索效率差异并不是很大。所以不管非聚簇索引也好还是聚簇索引也好,都适合排序,聚簇索引仅仅比非聚簇索引快一点。
结语
好了,写了半天,手都累了。关于聚簇索引与非聚簇索引效率问题的实验就不做了,感兴趣的话可以自己使用查询分析器对查询计划进行分析。SQL Server是一个很复杂的系统,尤其是索引以及查询优化技术,Oracle就更复杂了。了解索引以及查询背后的事情不是什么坏事,它可以帮助我们更为深刻的了解我们的系统。
SQL Server基础知识之:设计和实现视图
设计和实现视图可谓是数据库物理设计中的一个非常重要的步骤。从一般意义上说,设计和实现视图应该遵循下面的一些建议和原则。
以下内容摘在文档,我对某些重点进行了补充说明(红色部分)
- 分布式视图是可行的,但随着SQL Server本身能力的提高,例如SQL Server 2005开始支持表分区等技术之后,分布式视图应该尽量少用。
- 所谓分布式视图的一个最大的问题就是将表物理上分开在多个数据库甚至服务器中,这增加了维护和查询的难度
- 一个可以借鉴的做法是:在视图名称之前添加一个前缀 vw
- 一般不建议超过2层
- 除非万不得已,一般不建议使用触发器
- 很多朋友不知道:COMPUTER和COMPUTER BY语句仅仅用于一些特殊场合,用于生成总计行。大致有如下的效果

该特性不能用于视图,但可以直接用于查询
- 这个很有意思,如果要访问所有的呢,还必须是写TOP 100 PERCENT
- 关于TABLESAMPLE语句,大家可能也比较陌生,这是一个用于对数据进行抽样的。它和TOP语句不同,TOP语句是有固定大小的,而TABLESAMPLE返回的数据,可能多,可能少,甚至可能没有
- 我之前有一篇文章讲述这个语法 http://www.cnblogs.com/chenxizhang/archive/2009/05/19/1460040.html
- 在SQL Server 2005中,可以通过CTE(Common Table Expression)来实现该功能
- 之前的版本,大致的做法是使用临时表,表变量,函数等等
- 如果未使用 SCHEMABINDING 子句创建视图,则对视图下影响视图定义的对象进行更改时,应运行 sp_refreshview。 否则,当查询视图时,可能会生成意外结果。
- 如果你修改了一个表,那么如何刷新所有与该表有关的视图呢
- 强烈建议对某些非常重要的视图,添加SCHEMABINDING 子句。

- 视图中的任何列都是从算术表达式、内置函数或常量派生而来。
- 视图中有两列或多列原应具有相同名称(通常由于视图定义包含联接,因此来自两个或多个不同表的列具有相同的名称)。
- 希望为视图中的列指定一个与其源列不同的名称。 (也可以在视图中重命名列。) 无论重命名与否,视图列都会继承其源列的数据类型。
若要创建视图,您必须获取由数据库所有者授予的此操作执行权限,如果使用 SCHEMABINDING 子句创建视图,则必须对视图定义中引用的任何表或视图具有相应的权限。
默认情况下,由于行通过视图进行添加或更新,当其不再符合定义视图的查询的条件时,它们即从视图范围中消失。 例如,创建一个定义视图的查询,该视图从表中检索员工的薪水低于 $30,000 的所有行。如果员工的薪水涨到 $32,000,因其薪水不符合视图所设条件,查询时视图不再显示该特定员工。 但是,WITH CHECK OPTION 子句强制所有数据修改语句均根据视图执行,以符合定义视图的 SELECT 语句中所设条件。 如果使用该子句,则对行的修改不能导致行从视图中消失。 任何可能导致行消失的修改都会被取消,并显示错误。
本文由作者:陈希章 于 2009/6/15 17:31:29 发布在:http://www.cnblogs.com/chenxizhang/
本文版权归作者所有,可以转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
更多博客文章,以及作者对于博客引用方面的完整声明以及合作方面的政策,请参考以下站点:陈希章的博客中心
0
0
(请您对文章做出评价)
« 上一篇:Web Service
» 下一篇:[转]细说Sql Server中的视图
posted on 2009-12-09 14:48 RockYang 阅读(2815) 评论(5) 编辑 收藏
1719060
#1楼[楼主] 2009-12-09 15:20 RockYang
浅谈数据库索引
数据库索引是为了增加查询速度而对表字段附加的一种标识。见过很多人机械的理解索引的概念,认为增加索引只有好处没有坏处。这里想把之前的索引学习笔记总结一下:
首先明白为什么索引会增加速度,DB在执行一条Sql语句的时候,默认的方式是根据搜索条件进行全表扫描,遇到匹配条件的就加入搜索结果集 合。如果我们对某一字段增加索引,查询时就会先去索引列表中一次定位到特定值的行数,大大减少遍历匹配的行数,所以能明显增加查询的速度。那么在任何时候 都应该加索引么?这里有几个反例:1、如果每次都需要取到所有表记录,无论如何都必须进行全表扫描了,那么是否加索引也没有意义了。2、对非唯一的字段, 例如“性别”这种大量重复值的字段,增加索引也没有什么意义。3、对于记录比较少的表,增加索引不会带来速度的优化反而浪费了存储空间,因为索引是需要存 储空间的,而且有个致命缺点是对于update/insert/delete的每次执行,字段的索引都必须重新计算更新。
那么在什么时候适合加上索引呢?我们看一个Mysql手册中举的例子,这里有一条sql语句:
SELECT c.companyID, c.companyName FROM Companies c, User u WHERE c.companyID = u.fk_companyID AND c.numEmployees >= 0 AND c.companyName LIKE '%i%' AND u.groupID IN (SELECT g.groupID FROM Groups g WHERE g.groupLabel = 'Executive')
这条语句涉及3个表的联接,并且包括了许多搜索条件比如大小比较,Like匹配等。在没有索引的情况下Mysql需要执行的扫描行数是 77721876行。而我们通过在companyID和groupLabel两个字段上加上索引之后,扫描的行数只需要134行。在Mysql中可以通过 Explain Select来查看扫描次数。可以看出来在这种联表和复杂搜索条件的情况下,索引带来的性能提升远比它所占据的磁盘空间要重要得多。
那么索引是如何实现的呢?大多数DB厂商实现索引都是基于一种数据结构——B树。因为B树的特点就是适合在磁盘等直接存储设备上组织动态查找表。B树的定义是这样的:一棵m(m>=3)阶的B树是满足下列条件的m叉树:
1、每个结点包括如下作用域(j, p0, k1, p1, k2, p2, ... ki, pi) 其中j是关键字个数,p是孩子指针
2、所有叶子结点在同一层上,层数等于树高h
3、每个非根结点包含的关键字个数满足[m/2-1]<=j<=m-1
4、若树非空,则根至少有1个关键字,若根非叶子,则至少有2棵子树,至多有m棵子树
看一个B树的例子,针对26个英文字母的B树可以这样构造:
可以看到在这棵B树搜索英文字母复杂度只为o(m),在数据量比较大的情况下,这样的结构可以大大增加查询速 度。然而有另外一种数据结构查询的虚度比B树更快——散列表。Hash表的定义是这样的:设所有可能出现的关键字集合为u,实际发生存储的关键字记为k, 而|k|比|u|小很多。散列方法是通过散列函数h将u映射到表T[0,m-1]的下标上,这样u中的关键字为变量,以h为函数运算结果即为相应结点的存 储地址。从而达到可以在o(1)的时间内完成查找。
然而散列表有一个缺陷,那就是散列冲突,即两个关键字通过散列函数计算出了相同的结果。设m和n分别表示散列表的长度和填满的结点数,n/m为散列表的填装因子,因子越大,表示散列冲突的机会越大。
因 为有这样的缺陷,所以数据库不会使用散列表来做为索引的默认实现,Mysql宣称会根据执行查询格式尝试将基于磁盘的B树索引转变为和合适的散列索引以追 求进一步提高搜索速度。我想其它数据库厂商也会有类似的策略,毕竟在数据库战场上,搜索速度和管理安全一样是非常重要的竞争点
回复 引用 查看
#2楼[楼主] 2009-12-09 15:22 RockYang

#3楼[楼主] 2009-12-09 15:42 RockYang
据库的查询优化技术
数据库系统是管理信息系统的核心,基于数据库的联机事务处理(OLTP)以及联机分析处理(OLAP)是银行、企业、政府等部门最为重要的计算机应用之一。从大多数系统的应用实例来看,查询操作在各种数据库操作中所占据的比重最大,而查询操作所基于的SELECT语句在SQL语句中又是代价最大的语句。举例来说,如果数据的量积累到一定的程度,比如一个银行的账户数据库表信息积累到上百万甚至上千万条记录,全表扫描一次往往需要数十分钟,甚至数小时。如果采用比全表扫描更好的查询策略,往往可以使查询时间降为几分钟,由此可见查询优化技术的重要性。
笔者在应用项目的实施中发现,许多程序员在利用一些前端数据库开发工具(如PowerBuilder、Delphi等)开发数据库应用程序时,只注重用户界面的华丽,并不重视查询语句的效率问题,导致所开发出来的应用系统效率低下,资源浪费严重。因此,如何设计高效合理的查询语句就显得非常重要。本文以应用实例为基础,结合数据库理论,介绍查询优化技术在现实系统中的运用。
分析问题
许多程序员认为查询优化是DBMS(数据库管理系统)的任务,与程序员所编写的SQL语句关系不大,这是错误的。一个好的查询计划往往可以使程序性能提高数十倍。查询计划是用户所提交的SQL语句的集合,查询规划是经过优化处理之后所产生的语句集合。DBMS处理查询计划的过程是这样的:在做完查询语句的词法、语法检查之后,将语句提交给DBMS的查询优化器,优化器做完代数优化和存取路径的优化之后,由预编译模块对语句进行处理并生成查询规划,然后在合适的时间提交给系统处理执行,最后将执行结果返回给用户。在实际的数据库产品(如Oracle、Sybase等)的高版本中都是采用基于代价的优化方法,这种优化能根据从系统字典表所得到的信息来估计不同的查询规划的代价,然后选择一个较优的规划。虽然现在的数据库产品在查询优化方面已经做得越来越好,但由用户提交的SQL语句是系统优化的基础,很难设想一个原本糟糕的查询计划经过系统的优化之后会变得高效,因此用户所写语句的优劣至关重要。系统所做查询优化我们暂不讨论,下面重点说明改善用户查询计划的解决方案。
解决问题
下面以关系数据库系统Informix为例,介绍改善用户查询计划的方法。
1.合理使用索引
索引是数据库中重要的数据结构,它的根本目的就是为了提高查询效率。现在大多数的数据库产品都采用IBM最先提出的ISAM索引结构。索引的使用要恰到好处,其使用原则如下:
●在经常进行连接,但是没有指定为外键的列上建立索引,而不经常连接的字段则由优化器自动生成索引。
●在频繁进行排序或分组(即进行group by或order by操作)的列上建立索引。
●在条件表达式中经常用到的不同值较多的列上建立检索,在不同值少的列上不要建立索引。比如在雇员表的“性别”列上只有“男”与“女”两个不同值,因此就无必要建立索引。如果建立索引不但不会提高查询效率,反而会严重降低更新速度。
●如果待排序的列有多个,可以在这些列上建立复合索引(compound index)。
●使用系统工具。如Informix数据库有一个tbcheck工具,可以在可疑的索引上进行检查。在一些数据库服务器上,索引可能失效或者因为频繁操作而使得读取效率降低,如果一个使用索引的查询不明不白地慢下来,可以试着用tbcheck工具检查索引的完整性,必要时进行修复。另外,当数据库表更新大量数据后,删除并重建索引可以提高查询速度。
2.避免或简化排序
应当简化或避免对大型表进行重复的排序。当能够利用索引自动以适当的次序产生输出时,优化器就避免了排序的步骤。以下是一些影响因素:
●索引中不包括一个或几个待排序的列;
●group by或order by子句中列的次序与索引的次序不一样;
●排序的列来自不同的表。
为了避免不必要的排序,就要正确地增建索引,合理地合并数据库表(尽管有时可能影响表的规范化,但相对于效率的提高是值得的)。如果排序不可避免,那么应当试图简化它,如缩小排序的列的范围等。
3.消除对大型表行数据的顺序存取
在嵌套查询中,对表的顺序存取对查询效率可能产生致命的影响。比如采用顺序存取策略,一个嵌套3层的查询,如果每层都查询1000行,那么这个查询就要查询10亿行数据。避免这种情况的主要方法就是对连接的列进行索引。例如,两个表:学生表(学号、姓名、年龄……)和选课表(学号、课程号、成绩)。如果两个表要做连接,就要在“学号”这个连接字段上建立索引。
还可以使用并集来避免顺序存取。尽管在所有的检查列上都有索引,但某些形式的where子句强迫优化器使用顺序存取。下面的查询将强迫对orders表执行顺序操作:
SELECT * FROM orders WHERE (customer_num=104 AND order_num>1001) OR order_num=1008
虽然在customer_num和order_num上建有索引,但是在上面的语句中优化器还是使用顺序存取路径扫描整个表。因为这个语句要检索的是分离的行的集合,所以应该改为如下语句:
SELECT * FROM orders WHERE customer_num=104 AND order_num>1001
UNION
SELECT * FROM orders WHERE order_num=1008
这样就能利用索引路径处理查询。
4.避免相关子查询
一个列的标签同时在主查询和where子句中的查询中出现,那么很可能当主查询中的列值改变之后,子查询必须重新查询一次。查询嵌套层次越多,效率越低,因此应当尽量避免子查询。如果子查询不可避免,那么要在子查询中过滤掉尽可能多的行。
5.避免困难的正规表达式
MATCHES和LIKE关键字支持通配符匹配,技术上叫正规表达式。但这种匹配特别耗费时间。例如:SELECT * FROM customer WHERE zipcode LIKE “98_ _ _”
即使在zipcode字段上建立了索引,在这种情况下也还是采用顺序扫描的方式。如果把语句改为SELECT * FROM customer WHERE zipcode >“98000”,在执行查询时就会利用索引来查询,显然会大大提高速度。
另外,还要避免非开始的子串。例如语句:SELECT * FROM customer WHERE zipcode[2,3] >“80”,在where子句中采用了非开始子串,因而这个语句也不会使用索引。
回复 引用 查看
#4楼[楼主] 2009-12-09 15:42 RockYang
6.使用临时表加速查询
把表的一个子集进行排序并创建临时表,有时能加速查询。它有助于避免多重排序操作,而且在其他方面还能简化优化器的工作。例如:
SELECT cust.name,rcvbles.balance,……other columns
FROM cust,rcvbles
WHERE cust.customer_id = rcvlbes.customer_id
AND rcvblls.balance>0
AND cust.postcode>“98000”
ORDER BY cust.name
如果这个查询要被执行多次而不止一次,可以把所有未付款的客户找出来放在一个临时文件中,并按客户的名字进行排序:
SELECT cust.name,rcvbles.balance,……other columns
FROM cust,rcvbles
WHERE cust.customer_id = rcvlbes.customer_id
AND rcvblls.balance>0
ORDER BY cust.name
INTO TEMP cust_with_balance
然后以下面的方式在临时表中查询:
SELECT * FROM cust_with_balance
WHERE postcode>“98000”
临时表中的行要比主表中的行少,而且物理顺序就是所要求的顺序,减少了磁盘I/O,所以查询工作量可以得到大幅减少。
注意:临时表创建后不会反映主表的修改。在主表中数据频繁修改的情况下,注意不要丢失数据。
7.用排序来取代非顺序存取
非顺序磁盘存取是最慢的操作,表现在磁盘存取臂的来回移动。SQL语句隐藏了这一情况,使得我们在写应用程序时很容易写出要求存取大量非顺序页的查询。
有些时候,用数据库的排序能力来替代非顺序的存取能改进查询。
实例分析
下面我们举一个制造公司的例子来说明如何进行查询优化。制造公司数据库中包括3个表,模式如下所示:
1.part表
零件号零件描述其他列
(part_num)(part_desc)(other column)
102,032Seageat 30G disk……
500,049Novel 10M network card……
……
2.vendor表
厂商号厂商名其他列
(vendor _num)(vendor_name) (other column)
910,257Seageat Corp……
523,045IBM Corp……
……
3.parven表
零件号厂商号零件数量
(part_num)(vendor_num)(part_amount)
102,032910,2573,450,000
234,423321,0014,000,000
……
下面的查询将在这些表上定期运行,并产生关于所有零件数量的报表:
SELECT part_desc,vendor_name,part_amount
FROM part,vendor,parven
WHERE part.part_num=parven.part_num
AND parven.vendor_num = vendor.vendor_num
ORDER BY part.part_num
如果不建立索引,上述查询代码的开销将十分巨大。为此,我们在零件号和厂商号上建立索引。索引的建立避免了在嵌套中反复扫描。关于表与索引的统计信息如下:
表行尺寸行数量每页行数量数据页数量
(table)(row size)(Row count)(Rows/Pages)(Data Pages)
part15010,00025400
Vendor1501,000 2540
Parven13 15,000300 50
索引键尺寸每页键数量页面数量
(Indexes)(Key Size)(Keys/Page)(Leaf Pages)
part450020
Vendor45002
Parven825060
看起来是个相对简单的3表连接,但是其查询开销是很大的。通过查看系统表可以看到,在part_num上和vendor_num上有簇索引,因此索引是按照物理顺序存放的。parven表没有特定的存放次序。这些表的大小说明从缓冲页中非顺序存取的成功率很小。此语句的优化查询规划是:首先从part中顺序读取400页,然后再对parven表非顺序存取1万次,每次2页(一个索引页、一个数据页),总计2万个磁盘页,最后对vendor表非顺序存取1.5万次,合3万个磁盘页。可以看出在这个索引好的连接上花费的磁盘存取为5.04万次。
实际上,我们可以通过使用临时表分3个步骤来提高查询效率:
1.从parven表中按vendor_num的次序读数据:
SELECT part_num,vendor_num,price
FROM parven
ORDER BY vendor_num
INTO temp pv_by_vn
这个语句顺序读parven(50页),写一个临时表(50页),并排序。假定排序的开销为200页,总共是300页。
2.把临时表和vendor表连接,把结果输出到一个临时表,并按part_num排序:
SELECT pv_by_vn,* vendor.vendor_num
FROM pv_by_vn,vendor
WHERE pv_by_vn.vendor_num=vendor.vendor_num
ORDER BY pv_by_vn.part_num
INTO TMP pvvn_by_pn
DROP TABLE pv_by_vn
这个查询读取pv_by_vn(50页),它通过索引存取vendor表1.5万次,但由于按vendor_num次序排列,实际上只是通过索引顺序地读vendor表(40+2=42页),输出的表每页约95行,共160页。写并存取这些页引发5*160=800次的读写,索引共读写892页。
3.把输出和part连接得到最后的结果:
SELECT pvvn_by_pn.*,part.part_desc
FROM pvvn_by_pn,part
WHERE pvvn_by_pn.part_num=part.part_num
DROP TABLE pvvn_by_pn
这样,查询顺序地读pvvn_by_pn(160页),通过索引读part表1.5万次,由于建有索引,所以实际上进行1772次磁盘读写,优化比例为30∶1。笔者在Informix Dynamic Sever上做同样的实验,发现在时间耗费上的优化比例为5∶1(如果增加数据量,比例可能会更大)。
小结
20%的代码用去了80%的时间,这是程序设计中的一个著名定律,在数据库应用程序中也同样如此。我们的优化要抓住关键问题,对于数据库应用程序来说,重点在于SQL的执行效率。查询优化的重点环节是使得数据库服务器少从磁盘中读数据以及顺序读页而不是非顺序读页。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/ponydph/archive/2008/03/08/2158633.aspx
回复 引用 查看
#5楼[楼主] 2009-12-09 15:43 RockYang
SQL Server中如何快速获取表的记录总数
在数据库应用的设计中,我们往往会需要获取某些表的记录总数,用于判断表的记录总数是否过大,是否需要备份数据等。我们通常的做法是:select count(*) as c from tableA 。然而对于记录数巨大的表,上述做法将会非常耗时。在DELL 4400 服务器上做试验,MS Sqlserver 2000 数据库对于100万记录的简单数据表执行上述语句,时间在1分钟以上。如果在表的某个字段上做聚簇索引,第一次执行该语句的时间和没有索引的时间差不多,之后执行上述语句,速度很快,在1秒中以内,但当表的记录数发生较大变化后,再执行该语句又会经历一次耗时的过程。而且不是每个表都适合做聚簇索引的,对于数量巨大的表,如果需要经常增删操作,建聚簇索引是一个很不明智的做法,将会极大的影响增删的速度。那么有没有一个比较简单的方法快速获取表的记录总数呢?答案是有的。
在MS SQL 数据库中每个表都在sysindexes 系统表中拥有至少一条记录,该记录中的rows 字段会定时记录表的记录总数。
下面是sysindexes 表的相关记录的含义:
列名 数据类型 描述
id int 表ID(如果 indid = 0 或255)。否则为索引所属表的ID
Indid smallint 索引ID:
0=表
1=聚簇索引
>1=非聚簇索引
255=具有text或image数据的表条目。
rows int 基于indid=0 和 indid=1地数据级行数,该值对于indid>1重 复。如果indid=255,rows设置为0。
当表没有聚簇索引时,Indid = 0 否则为 1。
那么现在大家应该知道如何获取表的记录总数了,只需执行如下语句:
select rows from sysindexes where id = object_id(tablename) and indid in (0,1)
该方法获取表的记录总数的速度非常快,在毫秒级就可以完成,相比select count(*) 要快上数万倍,但是大家在运用该方法是一定要主要,该方法得到的表的总记录数不是一个精确值,原因是MS SQL 并不是实时更新该字段的值,而是定时更新,当从实践来看该值和精确值一般误差不大,如果你希望快速的粗略估算表的大小,建议你采用该方法。如果你希望得到精确值,那么请在执行上述语句前执行DBCC UpdateUSAGE(DatabaseName,[TABLENAME]) WITH ROW_COUNTS 强制更新该字段的值,但这样第一次更新时会耗费大量的时间,这样做的效果和建有聚簇索引的表 select count (*) 效果相差不大,所以如果你希望相对快速地得到精确的表的记录总数,那么你有两种选择,建聚簇索引或者先DBCC 再使用上述方法。