上一节介绍了tornado的请求与响应,这一节介绍tornado的接口调用顺序和模板
首先都有哪些接口呢?作用是什么呢?并且都有的时候,执行顺序是怎么样的呢?
接口
1.initialize,表示初始化,会在执行http方法之前调用2.prepare,预处理,会在执行http方法之前调用,任何一种http请求都会执行预处理方法3.http方法:
get,get请求
post,post请求
head,类似get请求,只不过响应中没有具体内容,只获取报头
delete,请求服务器删除指定的资源
put,从客户端向服务端传送指定内容
patch,修改局部内容
options,返回url支持的所有http方法4.set_default_headers,设置请求头5.write_error,处理self.send_error6.on_finish,在请求处理结束之后调用,用于对资源的清理和释放,或者日志处理。并且尽量不要在该方法中响应输出
调用顺序
-
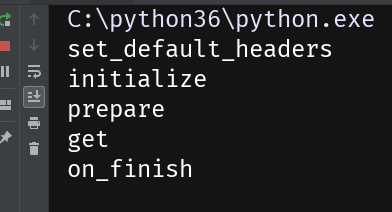
正常执行未抛出错误时,执行顺序从上到下为:
set_default_headers initialize prepare http方法 on_finish -
抛出错误时,执行顺序从上到下为:
set_default_headers initialize prepare http方法 set_default_headers write_error on_finish
测试
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self, *args, **kwargs):
print("get")
def initialize(self):
print("initialize")
def prepare(self):
print("prepare")
def set_default_headers(self):
print("set_default_headers")
def write_error(self, status_code, **kwargs):
print("write_error")
def on_finish(self):
print("on_finish")
在get函数中引发一个error
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self, *args, **kwargs):
print("get")
self.send_error()
def initialize(self):
print("initialize")
def prepare(self):
print("prepare")
def set_default_headers(self):
print("set_default_headers")
def write_error(self, status_code, **kwargs):
print("write_error")
def on_finish(self):
print("on_finish")

模板
首先要在settings里面配置模板路径,"template_path": os.path.join(BASE_DIR, "templates")
使用render方法渲染模板给客户端
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>古明地觉</title>
</head>
<body>
<h1 style="text-align: center">欢迎来到古明地觉的避难小屋</h1>
</body>
</html>
view.py
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self, *args, **kwargs):
self.render("satori.html")

变量与表达式
{{var}}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>古明地觉</title>
</head>
<body>
<h1>my name is {{name}}, which comes from {{place}},
people usually call me {{nickname1}}, {{nickname2}}, {{nickname3}}
</h1>
</body>
</html>
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self, *args, **kwargs):
# 在html中定义了name,place,nickname1,nickname2,nickname3
# 那么在渲染模板的时候,可以将参数传进去,然后进行替换
# 这些参数可以用关键字参数的形式传进去
# 而且通过这一点也能明白渲染的流程,tornado是先将整个html文件以字符串的形式全部读取进来
# 再按照模板语言进行替换,然后将替换之后的字符串返回给用户浏览器
# 浏览器再解析成页面,这就是模板渲染的流程。
# 因此最终交给浏览器的字符串是不包含大括号的
# 而且定义了几个{{var}},就要传几个,否则会报错name 'xxx' is not defined
# 而且写上了{{}},那么{{}}里面必须要传一个变量名,否则会报错,tornado.template.ParseError: Empty expression at xxx
self.render("satori.html", name="古明地觉", place="东方地灵殿",
nickname1="少女觉",
nickname2="觉大人",
nickname3="小五")

{{expression}}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>古明地觉</title>
</head>
<body>
<h1>my name is {{info["name"]}}, which comes from {{info["place"]}},
people usually call me {{info["nickname1"]}}, {{info["nickname2"]}}, {{info["nickname3"]}}
</h1>
</body>
</html>
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self, *args, **kwargs):
info = {"name": "古明地觉", "place": "东方地灵殿",
"nickname1": "少女觉", "nickname2": "觉大人",
"nickname3": "小五"}
self.render("satori.html", info=info)

打印的结果是一样的,可以看到相比于django,tornado的模板语言更接近于python。如果是django,那么就只能通过 . 来访问了。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>古明地觉</title>
</head>
<body>
<h1>
3 > 2 = {{3 > 2}}
<br>
bin(10) = {{bin(10)}}
<br>
2 << 4 = {{2 << 4}}
<br>
1 + 1 = {{1 + 1}}
<br>
sum(range(100)) = {{sum(range(100))}}
<br>
len("aaabbbccc") = {{len("aaabbbccc")}}
<br>
"aaa".upper() = {{"aaa".upper()}}
</h1>
</body>
</html>
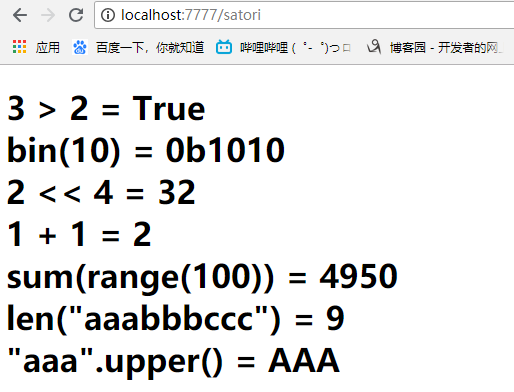
可以看到tornado的模板语言还支持简单的运算、逻辑判断,可以使用python的一些内置函数。所以这也说明了tornado是先将html文件读取进来,对{{}}用我们传进去的值或者python语法进行解释替换
流程控制
判断
{%if 条件%}
语句
{%end%}
{%if 条件%}
语句
{%else%}
语句
{%end%}
{%if 条件%}
语句
{%elif 条件%}
语句
...(可以多个elif)...
{%else%}
语句
{%end%}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>古明地觉</title>
</head>
<body>
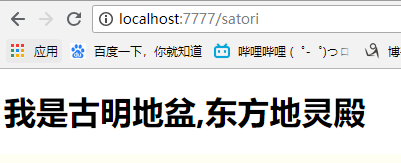
{%if name == "古明地盆"%}
<h1>我是{{name}},东方地灵殿</h1>
{%elif name == "古明地恋"%}
<h1>我是{{name}},东方地灵殿</h1>
{%else%}
<h1>管你是谁,我喜欢古明地两姐妹</h1>
{%end%}
</body>
</html>
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self, *args, **kwargs):
name = "古明地盆"
self.render("satori.html", name=name)
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self, *args, **kwargs):
name = "dadasdasdasdas"
self.render("satori.html", name=name)

循环
{%for variabl in iterable%}
语句
{%end%}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>古明地觉</title>
</head>
<body>
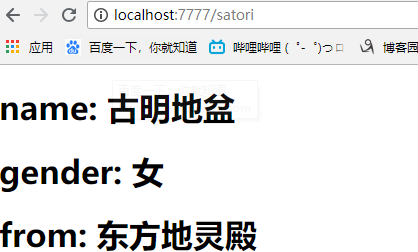
{%for v in info%}
<h1>{{v}}: {{info[v]}}</h1>
{%end%}
</body>
</html>
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self, *args, **kwargs):
info = {"name": "古明地盆",
"gender": "女",
"from": "东方地灵殿"}
self.render("satori.html", info=info)
函数
首先是static_url(),可以获取配置中的静态目录,我们在html中指定静态文件时可以使用,<link rel="stylesheet" href="{{static_url('css/xxx.css')}}"
因为我们虽然已经配置了静态文件的路径,但和模板不一样,静态路径还需要指定一个"static_url_prefix" : "/static/",然后通过/static/css/xxx.css访问,但是如果我们将/static/改成了别的,那么这就意味着所有的html文件都需要跟着改
因此我们用static_url就代指了static_path,不管改成什么只要在settings里面配置了之后,都可以用static_url来指代,因此引用便可以通过"{{static_url('js/xxx.js')}}",保证了修改目录不会修改href。并且static_url创建一个基于文件的hash值,并自动添加到了相应href的末尾当做一个查询参数,而且这个hash值保证每次加载的文件都是最新的,而不是以前的缓存版本,对于开发和上线都是很有必要的
然后是模板语言的自定义函数
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>古明地觉</title>
</head>
<body>
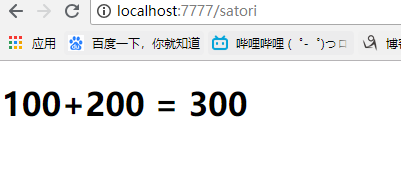
<h1>100+200 = {{func(100, 200)}}</h1>
</body>
</html>
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self, *args, **kwargs):
def func(num1, num2):
return num1 + num2
self.render("satori.html", func=func)
通过以上可以发现,tornado的模板语言是非常强大的,个人觉得比django的模板语言还要好很多。尽管没有django的那些过滤器什么的,但是对于tornado根本就不需要。因为tornado支持使用python的内置函数,所以django能完成的tornado都能完成,而且用起来比django的过滤器更方便。
并且如果传入了一个数字组成的列表li,我想计算列表的长度以及所有元素的和,对于django来说,可以使用{{li | length}}计算长度,但是不能计算总和,因为没有相应的过滤器,不可能使用{{li | sum}},当然django也提供了自定义过滤器的方法,先建一个templatetags文件夹,在文件夹里面定义一个py文件,在py文件里面定义一个函数,写上要处理的逻辑,然后在模板中把文件load进来,那么就可以将定义的函数作为过滤器使用了。但这样很麻烦,tornado的话,直接{{len(li)}}和{{sum(li)}}就可以了。
因此tornado的模板语言比django好用太多了,非常的精简,根本就不需要django的那些过滤器什么的,因为支持在html中直接使用python的语法,而且flask作者也是因为觉得django的模板语言不好用,才设计了jinja2。所以虽然django走的大而全的方向,但是模板语言设计的并不优秀,希望可以把模板语言再完善一下
转义
tornado默认开启了转义功能,会将一些html标签进行转义,让其不具备正常的功能,只让浏览器当成是简单的字符串,可以防止网站受到恶意攻击
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>古明地觉</title>
</head>
<body>
<h1>{{string}}</h1>
</body>
</html>
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self, *args, **kwargs):
string = '<a href="http://www.bilibili.com"/>'
self.render("satori.html", string=string)

结果是这么个东西,说明tornado开启了安全模式,自动转义了
关闭自动转义
1.raw,{%raw string%},只能关闭一行
2.{%autoescape None%},关闭当前html文档的自动转义
3.在配置中修改,在settings中添加,"autoescape": None,关闭当前项目的自动转义,但是不推荐
此外,还有个escape表示在关闭转义之后对某个特定的变量开启转义,{{escape(string)}}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>古明地觉</title>
</head>
<body>
<h1>{%raw string%}</h1>
</body>
</html>
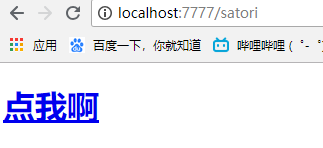
点击之后会跳转到bilibili
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>古明地觉</title>
</head>
<body>
{%autoescape None%}
<h1>{{string}}</h1>
<h1>{{escape(string)}}</h1>
</body>
</html>
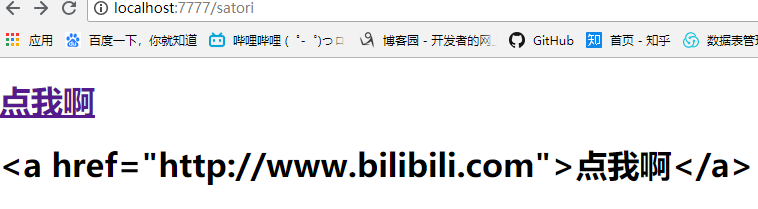
在关闭转义之后,可以使用escape开启转义
模板继承
所谓模板继承,指的就是父模板挖坑,子模板填坑。我们浏览一些网站,发现大很多时候四周都是不变的,变化的只是一部分。如果每一个页面都要重新写,那么会很麻烦,所以就有了模板继承。把不变的部分先写好,把变的部分留一个坑,这就是父模板。然后子模板继承的时候,会把父模板中写好的,也就是那些不变的部分继承过来,把父模板中挖的坑,也就是变的部分再按照业务用相应的代码给埋上。
base.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>mmp</title>
</head>
<body>
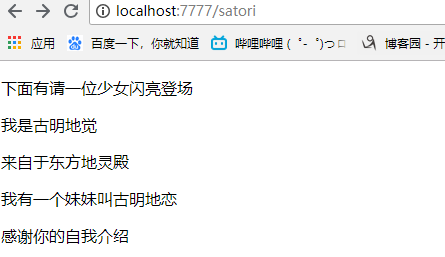
<p>下面有请一位少女闪亮登场</p>
{%block main%}
{%end%}
<p>感谢你的自我介绍</p>
</body>
</html>
satori.html
{%extends "base.html"%}
{%block main%}
<p>我是古明地觉</p>
<p>来自于东方地灵殿</p>
<p>我有一个妹妹叫古明地恋</p>
{%end%}
import tornado.web
class SatoriHandler(tornado.web.RequestHandler):
def get(self, *args, **kwargs):
self.render("satori.html")
UImethod和UImodule
类似于django的自定义标签,先在配置文件中设置好
import os
import uimethod
import uimodule
options = {"port": 7777}
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
settings = {"static_path": os.path.join(BASE_DIR, "static"),
"template_path": os.path.join(BASE_DIR, "templates"),
"compiled_static_cache": True,
"compiled_template_cache": True,
"server_traceback": True,
"ui_methods": uimethod,
"ui_modules": uimodule}
# uimethod.py
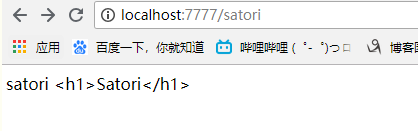
def satori(self):
return "satori"
# uimodule.py
import tornado.web
import tornado.escape
class Satori(tornado.web.UIModule):
def render(self, *args, **kwargs):
return tornado.escape.xhtml_escape("<h1>Satori</h1>")
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>mmp</title>
</head>
<body>
{{satori()}}
{%module Satori()%}
</body>
</html>
静态文件
static_path,告诉tornado从某一个特定的位置提取静态文件,可以直接访问静态文件。
因为对于那些经常被访问的页面,直接做成静态文件
那么便可以通过localhost:7777/static/html/index.html
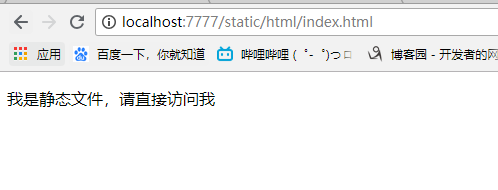
StaticFileHandler
StaticFileHandler是tornado用来提供静态资源文件的handler,可以通过tornado.web.StaticFileHandler来映射静态文件,因为使用localhost:7777/static/html/index.html对于用户来说体验不佳,
使用:(r"/", tornado.web.StaticFileHandler, {"path": os.path.join(config.BASE_DIR, "static/html"), "default_filename": "index.html"}),表示当我什么都不输入的时候直接从path(指定路径)下去找,default_name表示默认文件名,如果不写html,会使用默认的html。
像百度,当我们访问www.baidu.com,实际上访问的是www.baidu.com/index.html,也就是百度的一个静态文件。
需要注意的是:这个路由要放在最后面,否则会导致其他的路由无法匹配
import tornado.web
from views import view
import config
import os
class Application(tornado.web.Application):
def __init__(self):
handlers = [
(r"/satori", view.SatoriHandler),
(r"/(.*)$", tornado.web.StaticFileHandler, {"path": os.path.join(config.BASE_DIR, "static/html"),
"default_name": "index.html"})
]
super(Application, self).__init__(handlers=handlers, **config.settings)