介绍
selenium相当于是一个机器人,可以模拟人类登陆浏览器的行为,比如点击、填充数据、删除cookie等等。Chromedriver是一个驱动Chrome的程序,使用它才可以驱动浏览器,其实Chromedriver之前是用来做自动化测试的,但是发现很适合爬虫。当然这里的是Chromedriver,不同的浏览器有不同的driver,但是这里我们只介绍Chrome。毕竟谷歌浏览器在浏览器这一层面上基本算是主宰天下了。关于selenium一般是为了获取动态数据的,对于那些使用ajax技术的网站,直接获取会很麻烦,因为你在查看网页源代码里面找不到,当然如果会分析ajax接口的话,是可以获取到的。而通过selenium驱动driver的话,不管是什么技术,只要在页面上能看得到,那么就能获取到。因此如果是静态页面的话,建议使用requests,动态页面推荐selenium+driver
安装
对于selenium,直接pip install selenium即可

对于driver,我们直接下载对应版本的driver即可,关于版本可以看一下自己Chrome的安装路径,一般默认是C:Program Files (x86)GoogleChromeApplication下面
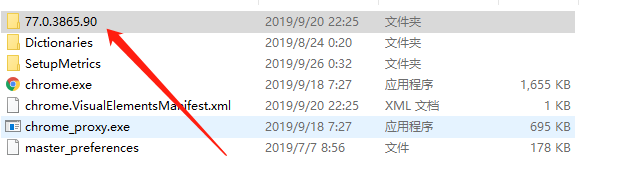
文件名就是对应的版本号,我们可以去http://npm.taobao.org/mirrors/chromedriver/这个网站里面找到与Chrome相对应的driver即可。一般来说,只要前三部分一样就没问题,像最后部分的90,我下载的是40,但是用着也没问题。当然有一样的就用完全一致的,主要是那个网站上面没有77.0.3865.90的driver,只有77.0.3865.40的driver,但是也可以用。
快速入门
下面我们就看看这个selenium怎么操作这个webdriver
from selenium import webdriver # 从selenium包中导入webdriver
# 指定driver的路径,就是我们刚才下载的。
driver_path = r"D:chromedriver_win32chromedriver.exe"
# 通过webdriver调用Chrome这个类,指定executable_path,传入driver_path,得到对应的driver
driver = webdriver.Chrome(executable_path=driver_path)
# 那么我们就可以使用driver这个驱动去请求应页面了,调用get方法,传入url
driver.get("http://www.baidu.com/s?wd=komeijisatori")
# 调用driver下的page_source得到源代码,查看前100个字符
print(driver.page_source[0: 100])
"""
<html><head>
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta http-equiv=
"""
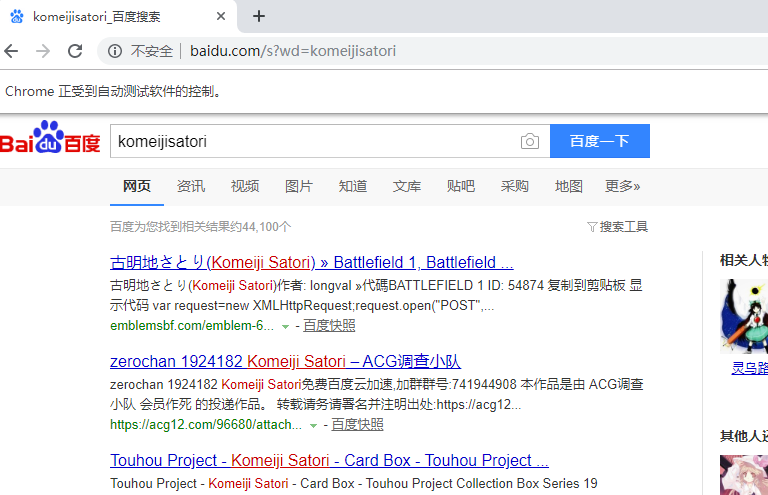
可以看到,自动地会打开相应的页面。如果能打开页面并获取到数据,说明是安装成功了的,如果失败那么就根据报错信息查找一下原因吧。
selenium关闭页面和浏览器
关闭可以是关闭页面,和关闭浏览器。
driver.close():关闭当前页面driver.quit():关闭浏览器
from selenium import webdriver
import time
driver_path = r"D:chromedriver_win32chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("http://www.baidu.com/s?wd=komeijisatori")
time.sleep(5) # 为了观察到现象,这里sleep 5秒
# driver.close()
# driver.quit()
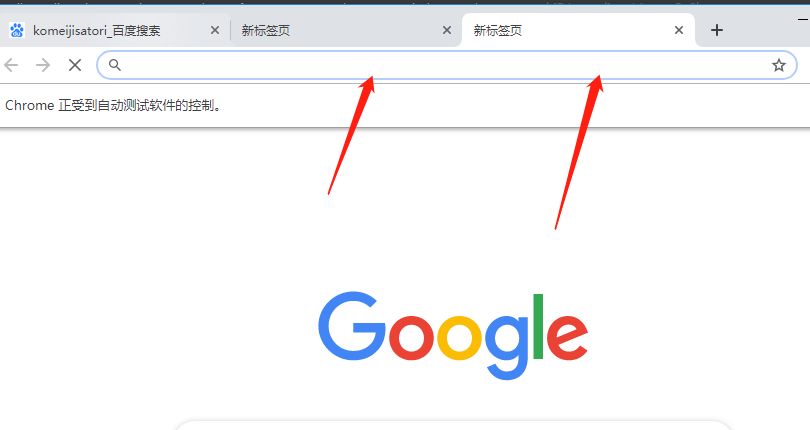
当我们执行程序打开页面的时候,点击加号,新建页面。如果是close的话,那么只会关闭最开始打开的页面,两个新标签页不会关闭。但如果是quit的话,那么不仅页面、整个浏览器都会推出。这个不好截图,可以自行尝试一下。
定位元素
如果我们想找到某些标签,要怎么办呢?selenium也为我们提供了很多的方法。
-
根据id来查找from selenium.webdriver.support.select import By # 两种方式等价的 driver.find_element_by_id("id_name") driver.find_element(By.ID, "id_name") -
根据类名查找元素driver.find_element_by_class_name("class_name") driver.find_element(By.CLASS_NAME, "class_name") -
根据name属性的值来查找元素driver.find_element_by_name("username") driver.find_element(By.NAME, "username") -
根据标签名来查找元素driver.find_element_by_tag_name("div") driver.find_element(By.TAG_NAME, "div") -
根据xpath语法来选择元素driver.find_element_by_xpath("//div[@class='哈哈哈']/a") driver.find_element(By.XPATH, "//div[@class='哈哈哈']/a") -
根据css选择器选择元素driver.find_element_by_css_selector("banner") driver.find_element(By.CSS_SELECTOR, "banner")
以上便是6中获取标签的方式,足够用了。但是以上所有的方法都是获取符合条件的第一个标签,如果获取多个,只需要把element改成elements。比如:find_elements_by_name("username")、find_elements(By.NAME, "username")
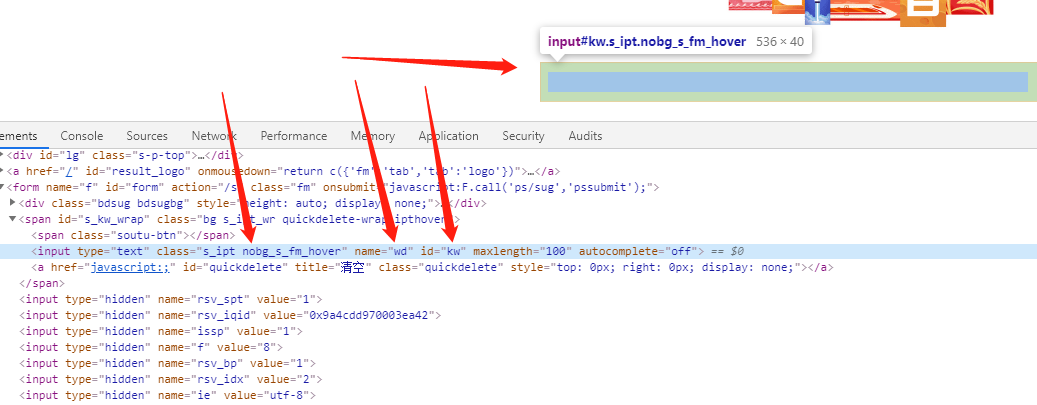
比如我想获取"百度一下你就知道"这个输入框,我有很多种方式,比如通过id="kw" name="wd" class="有点长不写了"等等。
from selenium import webdriver
driver_path = r"D:chromedriver_win32chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("http://www.baidu.com")
tag = driver.find_element_by_id("kw")
# 得到的tag依旧可以使用find_element_by_xxx等方法
# 但除此之外还有哪些属性呢
# 拿到当前的标签名,既然我们获取的是输入框,应该是input
print(tag.tag_name) # input
# 拿到标签对应的文本,有可能为空,所以我们用%r打印
print("%r" % tag.text) # ''
# 获取位置
print(tag.location) # {'x': 152, 'y': 310}
# 获取尺寸
print(tag.size) # {'height': 22, 'width': 500}
# 说实话这些都没啥用,至于其他的方法,会之后介绍
之前说了,我们有很多种方式获取
from selenium import webdriver
driver_path = r"D:chromedriver_win32chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("http://www.baidu.com")
tag1 = driver.find_element_by_name("wd")
tag2 = driver.find_element_by_class_name("s_ipt")
print(tag1.tag_name) # input
print(tag2.tag_name) # input
由于selenium获取元素的方式是通过python原生实现的,速度肯定没有底层使用C语言实现的lxml模块快,但是它能够对标签进行操作。因此如果我们只是想获取指定内容、不对标签进行操作的话,建议使用driver.page_source获取网页源代码,然后使用lxml或者pyquery进行解析,pyquery底层是使用lxml。
selenium操作表单元素
常见的表单元素有哪些呢?type="text/username/password/email等"的input标签,我们通过selenium是可以往里面输入内容的。
from selenium import webdriver
driver_path = r"D:chromedriver_win32chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("http://www.baidu.com")
# 获取标签
tag1 = driver.find_element_by_id("kw")
# 调用send_keys方法,往里面输入内容
tag1.send_keys("古明地觉")
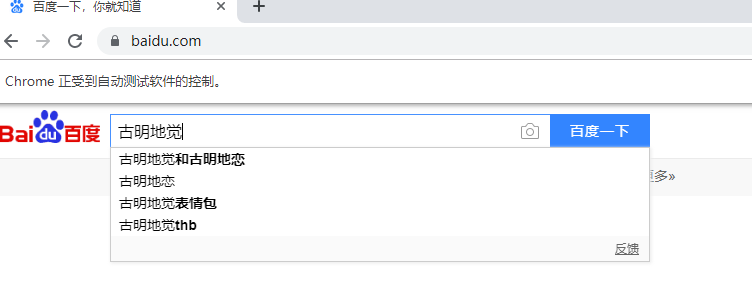
自动帮我们输入了,既然能输入那就能清除
from selenium import webdriver
driver_path = r"D:chromedriver_win32chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("http://www.baidu.com")
# 获取标签
tag1 = driver.find_element_by_id("kw")
# 调用send_keys方法,往里面输入内容
tag1.send_keys("古明地觉")
import time
time.sleep(5)
# 调用clear方法,5s后就自动删除了
tag1.clear()
操作checkbox,就是我们一般登陆的时候,会有一个类似于"记住我"的那个小方框
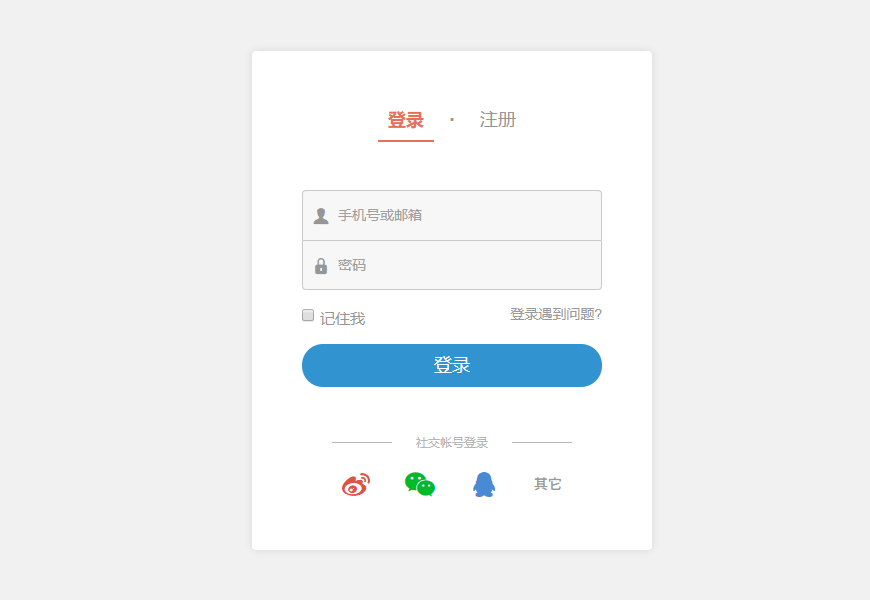
from selenium import webdriver
driver_path = r"D:chromedriver_win32chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.jianshu.com/sign_in")
# 获取对应按钮
tag1 = driver.find_element_by_id("session_remember_me")
# 调用click方法表示点击
tag1.click()
如果想取消怎么办?那么就再调用一次click方法
操作select,就是有很多选项可以让我们选择的标签。个人觉的操作select很少,我没找到对应网站,就不演示了。
from selenium import webdriver
driver_path = r"D:chromedriver_win32chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.xxxx.com")
# 获取select对应按钮
selectBtn = driver.find_element_by_id("select_id")
# 有了select还不行,必须要包装一下
from selenium.webdriver.support.ui import Select
selectBtn = Select(selectBtn)
# 通过索引
# selectBtn.select_by_index(1)
# 通过值
# selectBtn.select_by_value("http://xxx")
# 根据可视的文本选择
# selectBtn.select_by_visible_text("xxx")
# 取消所有选择
# selectBtn.deselect_all()
鼠标的点击事件。我们模拟百度搜索,这就意味着我们要找到输入框,输入内容,然后找到百度一下那个按钮,然后点击
from selenium import webdriver
driver_path = r"D:chromedriver_win32chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.baidu.com")
# 获取input输入框
input_btn = driver.find_element_by_id("kw")
input_btn.send_keys("古明地觉")
# 获取百度一下按钮
baidu_btn = driver.find_element_by_id("su")
baidu_btn.click()

可以看到,自动进入了相应的页面。
行为链
有时候在页面中的操作有很多步,比如点击、输入内容、点击等等,那么这一串的动作可以使用一个链子串起来,就是行为链
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains # 导入相关的类
driver_path = r"D:chromedriver_win32chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.baidu.com")
# 获取input输入框
input_btn = driver.find_element_by_id("kw")
# 获取百度一下按钮
baidu_btn = driver.find_element_by_id("su")
# 这个类接收一个driver
action_chains = ActionChains(driver)
# 下面可以进行操作
# 首先我们要把鼠标移动到input输入框里面去
action_chains.move_to_element(input_btn)
# 向指定的输入框里面输入内容
action_chains.send_keys_to_element(input_btn, "古明地恋")
# 然后移动到百度一下按钮上面
action_chains.move_to_element(baidu_btn)
# 点击相应的按钮
action_chains.click(baidu_btn)
# 以上相当于数据库里面的事务,然后调用perform执行链子上的操作
action_chains.perform()

以上打开页面、输入内容、点击都是程序自动完成的
行为链还有很多操作
click_and_hold(element):点击但不松开鼠标context_click(element):右键点击double_click(element):双击
cookie操作
-
获取所有cookiefrom selenium import webdriver driver_path = r"D:chromedriver_win32chromedriver.exe" driver = webdriver.Chrome(executable_path=driver_path) driver.get("https://www.baidu.com") for cookie in driver.get_cookies(): print(cookie) """ {'domain': '.baidu.com', 'httpOnly': False, 'name': 'H_PS_PSSID', 'path': '/', 'secure': False, 'value': '1432_21103_18560_29073_29523_29720_29567_29220_26350_22160'} {'domain': '.baidu.com', 'expiry': 3717332129.99234, 'httpOnly': False, 'name': 'BIDUPSID', 'path': '/', 'secure': False, 'value': 'ABEDD46CE6CCC56548E54C1159D892B6'} {'domain': '.baidu.com', 'httpOnly': False, 'name': 'delPer', 'path': '/', 'secure': False, 'value': '0'} {'domain': '.baidu.com', 'expiry': 3717332129.992357, 'httpOnly': False, 'name': 'PSTM', 'path': '/', 'secure': False, 'value': '1569848483'} {'domain': '.baidu.com', 'expiry': 1569934883.162394, 'httpOnly': False, 'name': 'BDORZ', 'path': '/', 'secure': False, 'value': 'B490B5EBF6F3CD402E515D22BCDA1598'} {'domain': 'www.baidu.com', 'expiry': 1570712483, 'httpOnly': False, 'name': 'BD_UPN', 'path': '/', 'secure': False, 'value': '12314753'} {'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BD_HOME', 'path': '/', 'secure': False, 'value': '0'} {'domain': '.baidu.com', 'expiry': 3717332129.99231, 'httpOnly': False, 'name': 'BAIDUID', 'path': '/', 'secure': False, 'value': 'ABEDD46CE6CCC56548E54C1159D892B6:FG=1'} """ -
获取指定cookiefrom selenium import webdriver driver_path = r"D:chromedriver_win32chromedriver.exe" driver = webdriver.Chrome(executable_path=driver_path) driver.get("https://www.baidu.com") print(driver.get_cookie("H_PS_PSSID")) """ {'domain': '.baidu.com', 'httpOnly': False, 'name': 'H_PS_PSSID', 'path': '/', 'secure': False, 'value': '1461_21115_29522_29721_29568_29221_26350'} """ -
删除指定cookiefrom selenium import webdriver driver_path = r"D:chromedriver_win32chromedriver.exe" driver = webdriver.Chrome(executable_path=driver_path) driver.get("https://www.baidu.com") print(driver.get_cookie("H_PS_PSSID")) """ {'domain': '.baidu.com', 'httpOnly': False, 'name': 'H_PS_PSSID', 'path': '/', 'secure': False, 'value': '1445_21084_29523_29721_29568_29221'} """ driver.delete_cookie("H_PS_PSSID") # 删除之后,再获取一次 print(driver.get_cookie("H_PS_PSSID")) # None -
删除所有cookiefrom selenium import webdriver driver_path = r"D:chromedriver_win32chromedriver.exe" driver = webdriver.Chrome(executable_path=driver_path) driver.get("https://www.baidu.com") # 删除所有的cookie driver.delete_all_cookies() # 得到是空列表 print(driver.get_cookies()) # []
页面等待
现在的网站很多都采用了ajax技术,这样程序便不能确定某个元素合适会全部加载出来。如果实际页面等待时间过长导致某个dom元素还没有加载出来,而去获取响应标签,那么就会找不到导致报错。为了解决这种问题,所以selenium提供了两种等待方式,隐式等待和显式等待。
隐式等待:直接指定一个等待时间,通过driver.implicitly_wait指定,不管页面加载情况如何,只要过了指定的等待时间,就开始获取元素
from selenium import webdriver
driver_path = r"D:chromedriver_win32chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.baidu.com")
# 表示隐式等待10s
driver.implicitly_wait(10)
# todo:可以隐式等待10s之后,再去做相应的操作
显示等待:相较于隐式等待比较智能一些,需要等待某个条件成立之后才去执行获取指定元素的操作。在可以同时指定一个最大时间间隔,如果超过了这个时间间隔,那么会抛出一个异常。显示等待应该使用selenium.webdriver.support.excepted_conditions(期望条件)和selenium.webdriver.support.ui.WebDriverWait(显示等待)来配合完成。
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as ec
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.select import By
driver_path = r"D:chromedriver_win32chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.baidu.com")
# 让driver等待10s,直到
WebDriverWait(driver, 10).until(
# 某个id="xxx"的元素出现
ec.presence_of_element_located((By.ID, "ID_NAME"))
)
当然还有其它的等待条件:presence_of_all_elements_located:所有元素都加载完毕了。element_to_be_clickable:某个元素可以点击了。
打开多窗口和切换窗口
有时候我们想打开一个新的页面,但是原来的页面不能关,而且多个页面要来回切换,这时候怎么办呢?selenium也为我们提供了相应的方法。
from selenium import webdriver
driver_path = r"D:chromedriver_win32chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
# 在介绍之前,肯定会有人思考能不能这么做
driver.get("https://www.baidu.com")
driver.get("https://www.bilibili.com")
# 这样不就打开两个页面了吗?确实没错,但是后一个页面把上一个页面给冲掉了
我们可以调用driver.execute_script,这个方法可以直接执行JavaScript代码
from selenium import webdriver
driver_path = r"D:chromedriver_win32chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.baidu.com")
# 在js中,通过window.open打开新窗口
driver.execute_script("window.open('https://www.bilibili.com')")
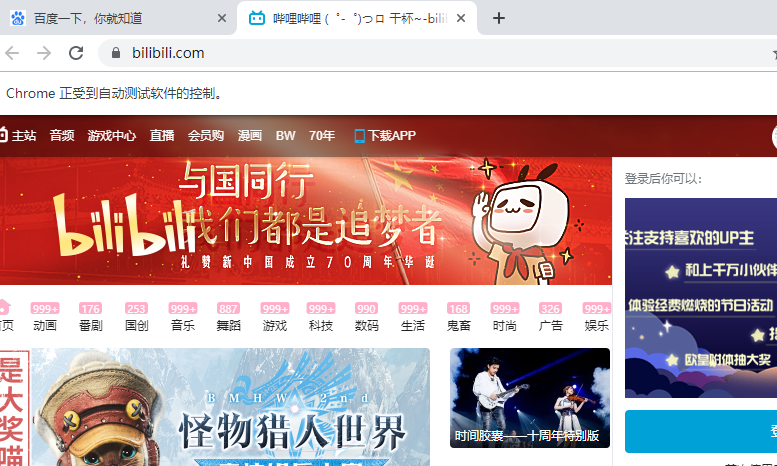
尽管通过图片,我们看到此时切换的是比例比例页面,但是在代码层面上,我们还是在一开始的百度窗口上面,怎么验证呢?可以调用driver.current_url查看一下当前页面的url
print(driver.current_url) # https://www.baidu.com/
打印的依旧是百度的url
那么如何切换呢?可以使用driver.switch_to.window里面传入窗口句柄,这个句柄可以通过driver.window_handler获取,driver.window_handler是一个列表,里面存放打开的窗口句柄,句柄的顺序就是打开页面的顺序,显然对于当前window_handler里面只有两个句柄,第一个是百度页面的句柄,第二个是bilibili页面的句柄
from selenium import webdriver
driver_path = r"D:chromedriver_win32chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.baidu.com")
# 在js中,通过window.open打开新窗口
driver.execute_script("window.open('https://www.bilibili.com')")
# 以前是driver.switch_to_window,这方法此时还能用,但是已经提示我们要被移除了
# 建议我们使用driver.switch_to.window
driver.switch_to.window(driver.window_handles[1]) # 切换到bilibili
# 打印当前页面的url
print(driver.current_url) # https://www.bilibili.com/
现在问题来了,如果有一个页面,页面上面有100个链接,我要获取这100个链接对应的网页源代码,并且只能保持两个窗口,要怎么做呢。显然是,新窗口打开页面的url,获取内容。然后关闭,再新窗口打开页面的第二个url,继续获取,依次往复
那我们就随便举例,先打开百度,然后打开bilibili,关掉bilibili,打开豆瓣,关掉豆瓣,打开知乎,关掉知乎,打开博客园。当然打开新页面的前提是要先回到百度,我们就假设这些链接都在百度上面
from selenium import webdriver
driver_path = r"D:chromedriver_win32chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.baidu.com")
# 通过window.open打开新窗口bilibili
driver.execute_script("window.open('https://www.bilibili.com')")
# 切换到bilibili
driver.switch_to.window(driver.window_handles[1])
# 源代码就不获取了,就用打印url代替吧
print(driver.current_url)
#关掉bilibili,由于窗口已经切换了,所以close掉的是bilibili的页面
# 注意不能是quit,那样的话,整个浏览器页面就关掉了
driver.close()
# 当close之后,此时的窗口还是停留在bilibili,或者说还没有切换到百度
# 但是此bilibili页面的窗口句柄已经不存在了,此时再进行操作就会报错,提示窗口已经关闭
# 切换到百度窗口,此时window_handlers里面就只有一个元素了
driver.switch_to.window(driver.window_handles[0])
# 打开豆瓣
driver.execute_script("window.open('https://www.douban.com')")
# 切换到豆瓣,此时window_handlers里面就又有两个元素
driver.switch_to.window(driver.window_handles[1])
# 打印url
print(driver.current_url)
# 关闭
driver.close()
# 切换到百度
driver.switch_to.window(driver.window_handles[0])
# 打开知乎
driver.execute_script("window.open('https://www.zhihu.com')")
driver.switch_to.window(driver.window_handles[1])
print(driver.current_url)
driver.close()
driver.switch_to.window(driver.window_handles[0])
# 打开博客园
driver.execute_script("window.open('https://www.cnblogs.com')")
driver.switch_to.window(driver.window_handles[1])
print(driver.current_url)
driver.close()
# 最后再切换到百度
driver.switch_to.window(driver.window_handles[0])
print(driver.current_url)
"""
https://www.bilibili.com/
https://www.douban.com/
https://www.zhihu.com/signin?next=%2F
https://www.cnblogs.com/
https://www.baidu.com/
"""
当然这里演示,显得有些啰嗦,实际写代码的时候可以使用循环。
使用代理ip
from selenium import webdriver
driver_path = r"D:chromedriver_win32chromedriver.exe"
# 指定代理
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.110.110.119:6666")
# 设置options参数即可
driver = webdriver.Chrome(executable_path=driver_path, chrome_options=options)
# 然后就可以使用代理访问了
driver.get("https://www.baidu.com")
WebElement类补充
我们使用driver.find_element等方法获取到的都是一个WebElement对象,那么我们在得到这个对象之后,还可以获取相应的属性
from selenium import webdriver
driver_path = r"D:chromedriver_win32chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get("https://www.baidu.com")
tag = driver.find_element_by_id("su")
print(type(tag)) # <class 'selenium.webdriver.remote.webelement.WebElement'>
# 通过get_attribute获取
print(tag.get_attribute("type")) # submit
print(tag.get_attribute("value")) # 百度一下
print(tag.get_attribute("class")) # bg s_btn