13.0 序
这一章我们就来看看python中类是怎么实现的,我们知道C不是一个面向对象语言,而python却是一个面向对象的语言,那么在python的底层,是如何使用C来支持python实现面向对象的功能呢?带着这些疑问,我们下面开始剖析python中类的实现机制。另外,在python2中存在着经典类(classic class)和新式类(new style class),但是到Python3中,经典类已经消失了。并且python2官网都快不维护了,因此我们这一章只会介绍新式类。
13.1 python中的对象模型
我们在第一章python对象初探的时候就说了,在面向对象的理论中,有两个核心的概念:类和实例。类可以看成是一个模板,那么实例就是根据这个模板创建出来的对象。可以想象成docker的镜像和容器。但是在python中,一切都是对象,所以类和实例都是对象,类叫做类对象,实例叫做实例对象。如果想用大白话来描述清楚的话,这无疑是一场灾难,我们还是需要使用一些专业术语来描述:
首先我们这里把python中的对象分为三种
内建对象:python中的内建对象,比如int、str、list、type、object等等class对象:程序员通过python中的class关键字定义的类。当然后面我们也会把内建对象和class对象统称为类对象的实例对象:表示由内建对象或者class对象创建的实例
13.1.1 对象间的关系
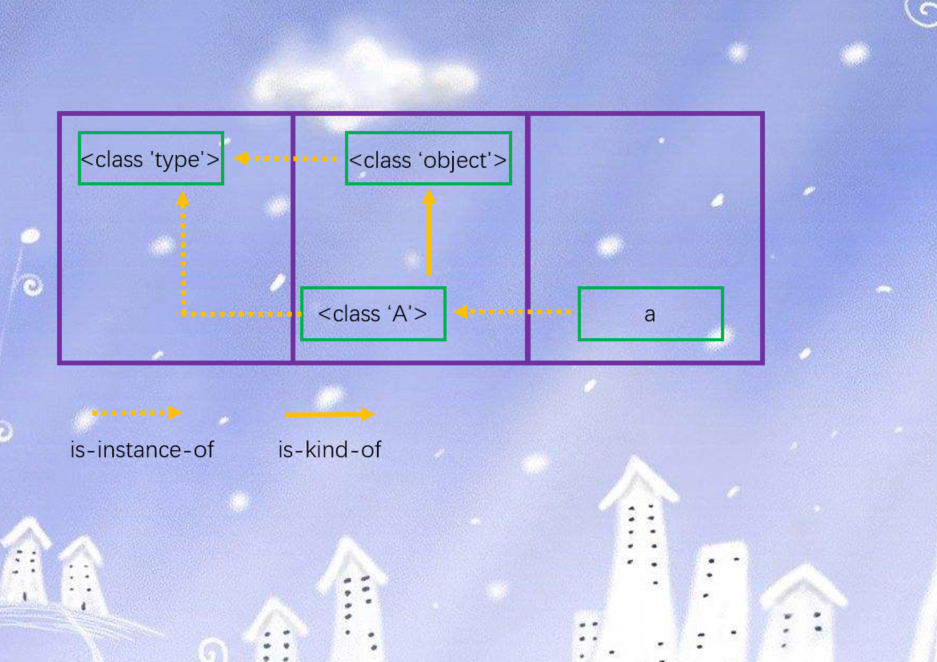
python的三种对象之间,存在着两种关系
is-kind-of:对应面向对象理论中父类和子类之间的关系is-instance-of:对应面向对象理论中类和实例之间的关系
class A(object):
pass
a = A()
这段代码中便包含了上面的三种对象:object(内建对象),A(class对象),a(实例对象)。显然object和A之间是is-kind-of关系,即object是A的父类,另外值得一提的是,在python3中所有定义的类都是默认继承自object,即便我们这里不显式写继承object,也会默认继承的,为了说明,我们就写上了。除了object是A的父类,我们还能看出a和A存在is-instance-of关系,即a是A的实例。当然如果再进一步的话,a和object之间也存在is-instance-of关系,a也是object的实例。我们可以使用python查看一下
class A(object):
pass
a = A()
print(type(a)) # <class '__main__.A'>
print(isinstance(a, object)) # True
我们看到尽管打印a的类型显示的是A(内建对象、class对象除了表示对象之外,还可以用来表示对应实例的类型,比如这里a的类型就是A),但是a也是object的实例,因为A继承了object,至于这其中的原理,我们会慢慢介绍到。
python中的类型检测
python提供了一些方法可以探测这些关系,除了我们上面的type之外,还可以使用对象的__class__属性探测一个对象和其它的哪些对象之间存在is-instance-of关系,而通过对象的__bases__属性则可以探测一个对象和其它的哪些对象之间存在着is-kind-of关系。此外python还提供了两个方法issubclass和isinstance来验证两个对象之间是否存在着我们期望的关系
class A(object):
pass
a = A()
####################
print(a.__class__) # <class '__main__.A'>
print(A.__class__) # <class 'type'>
# 因为python可以多继承,因为打印的是一个元组
print(A.__bases__) # (<class 'object'>,)
# 另外__class__是查看自己的类型是什么,也就是生成自己的类。
# 而在介绍python对象的时候,我们就看到了,任何一个对象都至少具备两个东西,一个是引用计数、一个是对象的类型
# 所以__class__在python中,是所有的对象都具备的
# 但是__bases__的话就不一定了,这个属性实例对象是没有的。只有class对象、内建对象才有
# 因此是无法调用a.__bases__的
估计看到这张图就应该知道我想说什么了,里面有着一个非常关键、也是非常让人费解的一个点。我记得之前说过,但是在这里我们再来研究一遍。
13.1.2 <class 'type'>和<class 'object'>
首先记住python中关于类的两句话:
所有的类对象(内建对象+class对象)都是由type生成的所有的类对象都继承object
逻辑性比较强的人,可能马上就发现了,这两句话组合起来是存在矛盾的,但是在python中是不矛盾的。我们来看几个例子
class A:
pass
print(type(A)) # <class 'type'>
print(type(int)) # <class 'type'>
print(type(dict)) # <class 'type'>
print(A.__bases__) # (<class 'object'>,)
print(int.__bases__) # (<class 'object'>,)
print(dict.__bases__) # (<class 'object'>,)
# 相信上面的都没有什么问题,但是令人费解的是下面
print(type(object)) # <class 'type'>
print(type.__bases__) # (<class 'object'>,).
我们看到object这个对象是由type创建的,但是object又是type的父类,那么这就先入了先有鸡还是先有蛋的问题。其实这两者是同时出现的,只不过在python中把两者形成了一个闭环,也正因为如此,python才能把一切皆对象的理念贯彻的如此彻底。至于type是由谁创建的,很容易猜到是由type自身创建的,连自己都不放过,更不要说其他的类对象了,因次我们也把type称之为metaclass(元类),创建类对象的类。更具体的解释请在前面的章节中翻一翻
我们刚才把python中的对象分成了三类:内建对象、class对象、实例对象。但是class对象也可以称之为实例对象,因为它是type生成的,那么自然就是type的一个实例对象,但是它同时也能生成实例,因此又叫做class对象。但是一般我们就认为实例对象就只是除了type之外的类生成的实例对象
因此现在我们可以总结一下:
在python中,任何一个对象都有一个类型,可以通过对象的__class__属性获取,也可以通过type函数去查看。任何一个实例对象的类型都是一个类对象,而类对象的类型则是<class 'type'>。而在python底层,它实际上对应的就是PyType_Type在python中,任何一个类对象都与<class 'object'>之间存在is-kind-of关系,包括<class 'type'>。在python内部,<class 'object'>对应的类型是PyBaseObject_Type
13.2 深入♂class
我们知道python里面有很多以双下划线开头、双下划线结尾的方法,我们称之为魔法方法。python中的每一个对象所能进行操作,那么在生成该对象的对象中一定会定义相应的魔法方法。比如整型3,整型可以相加,这就代表int这个类里面肯定定义了__add__方法
class MyInt(int):
def __add__(self, other):
return int.__add__(self, other) * 3
a = MyInt(1)
b = MyInt(2)
print(a + b) # 9
我们自己实现了一个类,继承自int,那么肯定可以接收一个整型。当我执行a+b的时候,肯定执行对应的__add__方法,然后调用int的__add__方法,得到结果之后再乘上3,逻辑上没有问题。但是问题来了,首先调用int.__add__的时候,python是怎么相加的呢?而且我们知道int.__add__(self, other)里面的参数显然都应该是int,但是我们传递的是MyInt,那么python虚拟机是怎么寻找的呢?先来看一张草图:

当python虚拟机需要调用int.__add__时,会从对应类型(PyObject里面ob_type域,这是一个PyTypeObject对象)的tp_dict域里面查找符号为__add__的对应的值,通过这个值找到long_as_number中对应的操作,从而完成对int.__add__的调用。
注意:我们上面说通过这个值找到long_as_number中对应的操作,并没有说指向它,对,很明显了,tp_dict中__add__对应的值不是直接指向long_add的,而是它的调用(也就是加上括号)才指向它。虽然是调用,但是并不代表这个值就一定是一个PyFunctionObject,在python中一切都有可能被调用,只要对应的类型对象(比如A加上括括号生成了a,那么就把A称之为a的类型对象,这样秒速会方便一些)定义了__call__方法,即在底层中的ob_type域中定义的tp_call方法不为NULL。
一言以蔽之:在python中,所谓调用,就是执行类型对象对应的ob_type域中定义的tp_call方法
class A:
def __call__(self, *args, **kwargs):
return "我是CALL,我被尻了"
a = A()
print(a()) # 我是CALL,我被尻了
在python内部,实际上是通过一个PyObject_Call的函数对实例对象a进行操作。
def foo():
a = 1
print(a())
# TypeError: 'int' object is not callable
foo()
我们看到一个整数对象是不可调用的,这显然意味着int这个类里面没有__call__方法,换言之PyLongObject结构体对应的ob_type域里面的tp_call为NULL。
# 但是我们通过反射打印的时候,发现int是有__call__方法的啊
print(hasattr(int, "__call__")) # True
# 其实所有的类都由type生成的,这个__call__不是int里面的,而是type的
print("__call__" in dir(int)) # False
print("__call__" in dir(type)) # True
print(int.__call__) # <method-wrapper '__call__' of type object at 0x00007FFAE22C0D10>
# hasattr和类的属性查找一样,如果找不到会自动到对应的类型对象里面去找
# type生成了int,那么如果type里面有__call__的话,即便int里面没有,hasattr(int, "__call__")依旧是True
a1 = int("123")
a2 = int.__call__("123")
a3 = type.__call__(int, "123")
# 以上三者的本质是一样的
print(a1, a2, a3) # 123 123 123
# 之前说过,当一个对象加上括号的时候,本质上调用其类型对象里面的__call__方法
# a = 3
# 那么a()就相当于调用int里面的__call__方法,但是int里面没有,就直接报错了
# 可能这里就有人问了,难道不会到type里面找吗?答案是不会的,因为type是元类,是用来生成类的
# 如果还能到type里面找,那么调用type的__call__生成的结果到底算什么呢?是类对象?可它又明明是实例对象加上括号调用的。显然这样就乱套了
# 因此实例对象找不到,会到类对象里面找,如果类对象再找不到,就不会再去元类里面找了,而是会去父类里面找
class A:
def __call__(self, *args, **kwargs):
print(self)
return "我被尻了"
class B(A):
pass
class C(B):
pass
print(C()())
"""
<__main__.C object at 0x000002282F3D9B80>
我被尻了
"""
# 此时我们看到,给C的实例对象加括号的时候,C里面没有__call__方法,这个时候是不会到元类里面找的
# 还是之前的结论,实例对象找不到属性,会去类对象里面找,然而即便此时类对象里面也没有,也不会到元类type里面找,这时候就看父类了
# 只有当类对象去找属性找不到的时候,才会去元类里面找,正如上面的__call__方法
# int里面没有,但它的类型对象type里面有,所以会去type里面找。如果type再找不到,肯定报错了
# 我们看对于我们上面的例子,给C的实例对象加括号的时候,会执行C这个类里面的__call__
# 但是它没有,所以找不到。然而它继承的父类里面有__call__
# 因此会执行继承的父类的__call__方法,并且里面的self还是C的实例对象
看,一个整数对象是不可调用的,但是我们发现这并不是在编译的时候就能够检测出来的错误,而是在运行时才能检测出来、会在运行时通过函数PyObject_CallFunctionObjArgs确定。所以a = 1;a()明明会报错,但是python还是成功编译了。
为什么会是这样呢?我们知道一个对象对应的类型都会有tp_dict这个域,这个域指向一个PyDictObject,表示这个对象支持哪些操作,而这个PyDictObject对象必须要在运行时动态构建。所以都说python效率慢,一个原因是所有对象都分配在堆上,还有一个原因就是一个对象很多属性或者操作、甚至是该对象是什么类型都需要在运行时动态构建,从而也就造成了python运行时效率不高。
而且我们发现,像int、str、dict等内建对象可以直接使用。这是因为python在启动时,会对这些内建对象进行初始化的动作。这个初始化的动作会动态地在这些内建对象对应的PyTypeObject中填充一些重要的东西,其中当然也包括填充tp_dict,从而让这些内建对象具备生成实例对象的能力。这个对内建对象进行初始化的动作就从函数PyType_Ready拉开序幕。
python通过调用函数PyType_Ready对内建对象进行初始化。实际上,PyType_Ready不仅仅是处理内建对象,还会处理class对象,并且PyType_Ready对于内建对象和class对象的作用还不同。比如说:list和class A:,list就已经作为PyList_Type(PyTypeObject)在python中存在了,咦,PyList_Type是个啥,和PyListObject有关系吗?估计到这里可能有人已经懵了,或者说前面章节介绍的已经忘记了。以python中的list为例:
PyListObject:对应python中的list实例对象,一个list()就是一个PyListObject结构体实例PyList_Type:就是python中list这个类本身,它被PyListObject中的ob_type域指向
PyListObject支持哪些操作,都会通过ob_type到PyList_Type里面去找。
言归正传,我们刚才说,在python解释器启动的时候,PyList_Type就已经存在了,并且是全局对象,仅仅再需要小小的完善一下。但是对于自定的class对象A来说(为了解释方便,假设在底层就叫做PyA_Type吧,当然我们只是假设这么对应的,至于到底是什么我们后面会说,但是目前为了解释方便就这么叫吧),底层对应的PyA_Type则并不存在,需要申请内存、创建、初始化整个动作序列。所以对于list来说,初始化就只剩下PyType_Ready了(也就上面说的小小的完善一下),但是对于自定义的class对象A来说,PyType_Ready仅仅是很小的一部分。
下面我们就以python中的type对象入手,因为它比较特殊。python中的type在底层对应PyType_Type。我们说python中type生成了int、str、dict等内建对象,但是type、object也是内建对象,当然这两个老铁的类型也依旧是type。但是在底层,这个所有的内建类型都是一个PyTypeObject对象。
int: PyLong_Typestr: PyUnicode_Typetuple: PyTuple_Typedict: PyDict_Typetype: PyType_Type
从名字也能看出来规律,这些内建对象在cpython、也就是python底层中,都是一个PyTypeObject对象、或者说一个PyTypeObject结构体实例。尽管在python中说type生成了所有的类对象(所有内建对象+class对象),但是在cpython中它们都是同一个类型、也就是同一个结构体(各个域的值不同)的不同实例。
13.2.1 处理基类和type信息
//typeobject.c
int
PyType_Ready(PyTypeObject *type)
{
//这里的参数显然是PyType_Type
//tp_dict,和继承的基类,因为是多个所以是bases,当然不用想这些基类也都是PyTypeObject对象
PyObject *dict, *bases;
//还是继承的基类,显然这个是object,对应PyBaseObject_Type,因为py3中,所有的类都是默认继承的
PyTypeObject *base;
Py_ssize_t i, n;
/* Initialize tp_base (defaults to BaseObject unless that's us) */
// 获取type中tp_base域指定的基类
base = type->tp_base;
if (base == NULL && type != &PyBaseObject_Type) {
//设置
base = type->tp_base = &PyBaseObject_Type;
Py_INCREF(base);
}
/* Initialize the base class */
//如果基类没有tp_dict,那么会初始化基类
if (base != NULL && base->tp_dict == NULL) {
if (PyType_Ready(base) < 0)
goto error;
}
//设置type信息
if (Py_TYPE(type) == NULL && base != NULL)
Py_TYPE(type) = Py_TYPE(base);
}
python虚拟机会尝试获取待初始化的type(PyType_Ready的参数名,这里是PyType_Type)的基类,这个信息是在PyTypeObject.tp_base中指定的,可以看看一些常见内建对象的tp_base信息。

对于指定了tb_base的内建对象,当然就使用指定的基类,而对于没有指定tp_base的内置class对象,python将为其指定一个默认的基类:PyBaseObject_Type,当然这个东西就是python中的object。现在我们看到PyType_Type的tp_base指向了PyBaseObject_Type,这在python中体现的就是type继承自object、或者说object是type的父类。但是所有的类底层对应的结构体的ob_type域又都指向了PyType_Type,包括object,因此我们又说type生成了包括object的所有类。
在获得了基类之后,就会判断基类是否被初始化,如果没有,则需要先对基类进行初始化。可以看到, 判断初始化是否完成的条件是base->tp_dict是否为NULL,这符合之前的描述,对于内建对象的初始化来说,在python解释器启动的时候,就已经作为全局对象存在了,剩下的就是小小的完善一下,也就是对tp_dict进行填充。
然后设置ob_type信息,实际上这个ob_type就是__class__返回的信息。首先PyType_Ready函数里面接收的是一个PyTypeObject,我们知道这个在python中就是python的类对象。因此这里是设置这些类对象的ob_type,那么对应的ob_type显然就是元类metaclass,我们自然会想象到python中的type。但是我们发现Py_TYPE(type) = Py_TYPE(base);这一行代码是把父类的ob_type设置成了当前类的ob_type,也就是说A类是由XX生成的,那么B在继承A的时候,B也会由XX生成。这里之所以用XX代替,是因为python中不仅仅是type可以生成类对象,那些继承了type的子类也可以。
# 必须要继承自type,否则无法作为一个类的metaclass
class MyType(type):
def __new__(mcs, name, bases, attrs):
# 控制类的实例化过程
# 自动添加一个属性
attrs.update({"哈哈": "蛤蛤"})
return super().__new__(mcs, name, bases, attrs)
# 指定A的metaclass是MyType
class A(metaclass=MyType):
pass
# 然后让B去继承A
# 因为A是由MyType生成的,那么B继承A之后,B的元类也会是MyType
class B(A):
pass
print(B.__class__) # <class '__main__.MyType'>
print(B.哈哈) # 蛤蛤
所以大家应该明白下面的代码是做什么的了,python虚拟机就是将基类的metaclass设置到了子类的metaclass里面,对于我们当前的PyType_Type来说,其metaclass就是object的metaclass,只不过还是它自己,而在源码的PyBaseObject_Type中可以看到其ob_type是被设置成了PyType_Type的。如果经常使用元类的话,那么上面这个例子很容易明白。
//设置type信息
if (Py_TYPE(type) == NULL && base != NULL)
Py_TYPE(type) = Py_TYPE(base);
既然继承了PyBaseObject_Type,那么便会首先初始化PyBaseObject_Type,我们下面来看看这个PyBaseObject_Type、python中的object是怎么被初始化的。
13.2.2 处理基类列表
接下来,python虚拟机会处理类型的基类列表,因为python支持多重继承,所以每一个python的类对象都会有一个基类、或者说父类列表。
int
PyType_Ready(PyTypeObject *type)
{
PyObject *dict, *bases;
PyTypeObject *base;
Py_ssize_t i, n;
/* Initialize tp_base (defaults to BaseObject unless that's us) */
//获取tp_base中指定的基类
base = type->tp_base;
if (base == NULL && type != &PyBaseObject_Type) {
base = type->tp_base = &PyBaseObject_Type;
Py_INCREF(base);
}
...
...
...
/* Initialize tp_bases */
//处理bases:基类列表
bases = type->tp_bases;
//如果bases为空
if (bases == NULL) {
//如果base也为空,说明这个对象一定是PyBaseObject_Type
//因为python中任何类都继承自object,除了object自身
if (base == NULL)
//那么这时候bases就是个空元组,元素个数为0
bases = PyTuple_New(0);
else
//否则的话,就申请只有一个空间的元素,然后将base(PyBaseObject_Type)塞进去
bases = PyTuple_Pack(1, base);
if (bases == NULL)
goto error;
//设置bases
type->tp_bases = bases;
}
}
因此我们看到有两个属性,一个是tp_base,一个是tp_bases,我们看看这俩在python中的区别。
class A:
pass
class B(A):
pass
class C:
pass
class D(B, C):
pass
print(D.__base__) # <class '__main__.B'>
print(D.__bases__) # (<class '__main__.B'>, <class '__main__.C'>)
print(C.__base__) # <class 'object'>
print(C.__bases__) # (<class 'object'>,)
print(B.__base__) # <class '__main__.A'>
print(B.__bases__) # (<class '__main__.A'>,)
我们看到D同时继承多个类,那么tp_base就是先出现的那个基类,而tp_bases则是继承的所有基类,但是基类的基类是不会出现的,比如object。对于class B也是一样的。然后我们看看class C,因为C没有显式地继承任何类,那么tp_bases就是NULL,但是python3中所有的类都默认继承了object,所以tp_base就是PyBaseObject_Type,那么就会把tp_base拷贝到tp_bases里面,因此也就出现了这个结果。
print(C.__base__) # <class 'object'>
print(C.__bases__) # (<class 'object'>,)
13.2.3 填充tp_dict
下面python虚拟机就进入了激动人心的tp_dict的填充阶段,这是一个极其繁复的过程。
int
PyType_Ready(PyTypeObject *type)
{
PyObject *dict, *bases;
PyTypeObject *base;
Py_ssize_t i, n;
/* Initialize tp_dict */
//初始化tp_dict
dict = type->tp_dict;
if (dict == NULL) {
dict = PyDict_New();
if (dict == NULL)
goto error;
type->tp_dict = dict;
}
/* Add type-specific descriptors to tp_dict */
//将与type相关的操作加入到tp_dict中
if (add_operators(type) < 0)
goto error;
if (type->tp_methods != NULL) {
if (add_methods(type, type->tp_methods) < 0)
goto error;
}
if (type->tp_members != NULL) {
if (add_members(type, type->tp_members) < 0)
goto error;
}
if (type->tp_getset != NULL) {
if (add_getset(type, type->tp_getset) < 0)
goto error;
}
}
在这个截断,完成了将("__add__", &long_add)加入tp_dict的过程,这个阶段的add_operators、add_methods、add_members、add_getset都是完成这样的填充tp_dict的动作。那么这时候一个问题就出现了,python是如何知道__add__和long_add之间存在关联的呢?其实这种关联显然是一开始就已经定好了的,而且存放在一个名为slotdefs的数组中。
13.2.3.1 slot与操作排序
在进入填充tp_dict的复杂操作之前,我们先来看一下python中的一个概念:slot。在python内部,slot可以视为表示PyTypeObject中定义的操作,一个操作对应一个slot,但是slot又不仅仅包含一个函数指针,它还包含一些其它信息,我们看看它的结构。在python内部,slot是通过slotdef这个结构体来实现的。
//typeobject.c
typedef struct wrapperbase slotdef;
//descrobject.h
struct wrapperbase {
const char *name;
int offset;
void *function;
wrapperfunc wrapper;
const char *doc;
int flags;
PyObject *name_strobj;
};
在一个slot中,就存储着PyTypeObject中一种操作对应的各种信息,比如:int实例对象(PyLongObject)支持哪些操作,就看int(PyTypeObject实例PyLong_Type)支持哪些操作,而PyTypeObject中的一个操作就会有一个slot与之对应。比如slot里面的name就是操作对应的名称,比如字符串__add__,offset则是操作的函数地址在PyHeapTypeObject中的偏移量,而function则指向一种称为slot function的函数
python中提供了多个宏来定义一个slot,其中最基本是TPSLOT和ETSLOT
//typeobject.c
#define TPSLOT(NAME, SLOT, FUNCTION, WRAPPER, DOC)
{NAME, offsetof(PyTypeObject, SLOT), (void *)(FUNCTION), WRAPPER,
PyDoc_STR(DOC)}
#define ETSLOT(NAME, SLOT, FUNCTION, WRAPPER, DOC)
{NAME, offsetof(PyHeapTypeObject, SLOT), (void *)(FUNCTION), WRAPPER,
PyDoc_STR(DOC)}
TPSLOT和ETSLOT的区别就在于TPSLOT计算的是操作对应的函数指针(比如nb_add)在PyTypeObject中的偏移量,而ETSLOT计算的是函数指针在PyHeapTypeObject中的偏移量,但是我们看一下,PyHeapTypeObject的定义,就能发现端倪
typedef struct _heaptypeobject {
/* Note: there's a dependency on the order of these members
in slotptr() in typeobject.c . */
PyTypeObject ht_type;
PyAsyncMethods as_async;
PyNumberMethods as_number;
PyMappingMethods as_mapping;
PySequenceMethods as_sequence; /* as_sequence comes after as_mapping,
so that the mapping wins when both
the mapping and the sequence define
a given operator (e.g. __getitem__).
see add_operators() in typeobject.c . */
PyBufferProcs as_buffer;
PyObject *ht_name, *ht_slots, *ht_qualname;
struct _dictkeysobject *ht_cached_keys;
/* here are optional user slots, followed by the members. */
} PyHeapTypeObject;
我们发现PyHeapTypeObject的第一个域就是PyTypeObject,因此可以发现TPSLOT计算出的也是PyHeapTypeObject的偏移量。
对于一个PyTypeObject来说,有的操作,比如long_add,其函数指针是在PyNumberMethods里面存放的,而PyTypeObject中却是通过一个tp_as_number指针指向另一个PyNumberMethods结构,因此这种情况是没办法计算出long_add在PyTypeObject中的偏移量的,只能计算出在PyHeapTypeObject中的偏移量。这种时候TPSLOT就失效了
因此与long_add对应的slot必须是通过ETSLOT来定义的,但是我们说PyHeapTypeObject里面的offset表示的是基于PyHeapTypeObject得到的偏移量,而PyLong_Type却是一个PyTypeObject,那么通过这个偏移量显然无法得到PyLong_Type中为int准备的long_add,那~~~这个offset有什么用呢?
答案非常诡异,这个offset是用来对操作进行排序的。排序?整个人都不好了不过在理解为什么需要对操作进行排序之前,需要先看看python预先定义的slot集合--slotdefs
//typeobject.c
#define SQSLOT(NAME, SLOT, FUNCTION, WRAPPER, DOC)
ETSLOT(NAME, as_sequence.SLOT, FUNCTION, WRAPPER, DOC)
static slotdef slotdefs[] = {
//不同操作名(__add__、__radd__)对象,对应相同操作nb_add
//这个nb_add在PyLong_Type就是long_add,表示+
BINSLOT("__add__", nb_add, slot_nb_add,
"+"),
RBINSLOT("__radd__", nb_add, slot_nb_add,
"+"),
BINSLOT("__sub__", nb_subtract, slot_nb_subtract,
"-"),
RBINSLOT("__rsub__", nb_subtract, slot_nb_subtract,
"-"),
BINSLOT("__mul__", nb_multiply, slot_nb_multiply,
"*"),
RBINSLOT("__rmul__", nb_multiply, slot_nb_multiply,
"*"),
//相同操作名(__getitem__)对应不同操作(mp_subscript、mp_ass_subscript)
MPSLOT("__getitem__", mp_subscript, slot_mp_subscript,
wrap_binaryfunc,
"__getitem__($self, key, /)
--
Return self[key]."),
SQSLOT("__getitem__", sq_item, slot_sq_item, wrap_sq_item,
"__getitem__($self, key, /)
--
Return self[key]."),
};
其中BINSLOT,SQSLOT等这些宏实际上都是对ETSLOT的一个简单包装,并且在slotdefs中,可以发现,操作名(比如__add__)和操作并不是一一对应的,存在多个操作对应同一个操作名、或者多个操作名对应同一个操作的情况,那么在填充tp_dict时,就会出现问题,比如对于__getitem__,在tp_dict中与其对应的是mp_subscript还是sq_item呢?
为了解决这个问题,就需要利用slot中的offset信息对slot(也就是对操作)进行排序。回顾一下前面列出的PyHeapTypeObject的代码,它与一般的struct定义不同牟其中定义中各个域的顺序是非常关键的,在顺序中隐含着操作优先级的问题。比如在PyHeapTypeObject中,PyMappingMethods的位置在PySequenceMethods之前,mp_subscript是PyMappingMethods中的一个域:PyObject *,而sq_item又是PySequenceMethods中的的一个域:PyObject *,那么最终计算出的偏移量就存在如下关系:offset(mp_subscript) < offset(sq_item)。因此如果在一个PyTypeObject中,既定义了mp_subscript,又定义了sq_item,那么python虚拟机将选择mp_subscript与__getitem__发生关系。
而对slotdefs的排序在init_slotdefs中完成:
//typeobject.c
static int slotdefs_initialized = 0;
/* Initialize the slotdefs table by adding interned string objects for the
names. */
static void
init_slotdefs(void)
{
slotdef *p;
//init_slotdefs只会进行一次
if (slotdefs_initialized)
return;
for (p = slotdefs; p->name; p++) {
/* Slots must be ordered by their offset in the PyHeapTypeObject. */
//注释也表名:slots一定要通过它们在PyHeapTypeObject中的offset进行排序
//而且是从小到大排
assert(!p[1].name || p->offset <= p[1].offset);
//填充slotdef结构体中的name_strobj
p->name_strobj = PyUnicode_InternFromString(p->name);
if (!p->name_strobj || !PyUnicode_CHECK_INTERNED(p->name_strobj))
Py_FatalError("Out of memory interning slotdef names");
}
//将值赋为1,这样的话下次执行的时候,执行到上面的if就直接return了
slotdefs_initialized = 1;
}
13.2.3.2 从slot到descriptor
在slot中,包含了很多关于一个操作的信息,但是很可惜,在tp_dict中,与__getitem__关联在一起的,一定不会是slot。因为它不是一个PyObject,无法放在dict对象中。当然如果再深入思考一下,会发现slot也无法被调用。既然slot不是一个PyObject,那么它就没有ob_type这个域,也就无从谈起什么tp_call了,所以slot是无论如也无法满足python中的可调用这一条件的。前面我们说过,python虚拟机在tp_dict找到__getitem__对应的操作后,会调用该操作,所以tp_dict中与__getitem__对应的只能是包装了slot的PyObject。在python中,我们称之为descriptor。
在python内部,存在多种descriptor,与descriptor相对应的是PyWrapperDescrObject。在后面的描述中也会直接使用descriptor代表PyWrapperDescrObject。一个descriptor包含一个slot,其创建是通过PyDescr_NewWrapper完成的
//descrobject.h
#define PyDescr_COMMON PyDescrObject d_common
typedef struct {
PyObject_HEAD
PyTypeObject *d_type;
PyObject *d_name;
PyObject *d_qualname;
} PyDescrObject;
typedef struct {
PyDescr_COMMON;
struct wrapperbase *d_base;
void *d_wrapped; /* This can be any function pointer */
} PyWrapperDescrObject;
//descrobject.c
static PyDescrObject *
descr_new(PyTypeObject *descrtype, PyTypeObject *type, const char *name)
{
PyDescrObject *descr;
//申请空间
descr = (PyDescrObject *)PyType_GenericAlloc(descrtype, 0);
if (descr != NULL) {
Py_XINCREF(type);
descr->d_type = type;
descr->d_name = PyUnicode_InternFromString(name);
if (descr->d_name == NULL) {
Py_DECREF(descr);
descr = NULL;
}
else {
descr->d_qualname = NULL;
}
}
return descr;
}
PyObject *
PyDescr_NewWrapper(PyTypeObject *type, struct wrapperbase *base, void *wrapped)
{
PyWrapperDescrObject *descr;
descr = (PyWrapperDescrObject *)descr_new(&PyWrapperDescr_Type,
type, base->name);
if (descr != NULL) {
descr->d_base = base;
descr->d_wrapped = wrapped;
}
return (PyObject *)descr;
}
python内部的各种descriptor都将包含PyDescr_COMMON,其中的d_type被设置为PyDescr_NewWrapper的参数type,而d_wrapped则存放着最重要的信息:操作对应的函数指针,比如对于PyList_Type来说,其tp_dict["__getitem__"].d_wrapped就是&mp_subscript。而slot则被存放在了d_base中。
PyWrapperDescrObject的type是PyWrapperDescr_Type,其中的tp_call是wrapperdescr_call,当python虚拟机调用一个descriptor时,也就会调用wrapperdescr_call。对于descriptor的调用过程,我们将在后面详细介绍。
13.2.3.3 建立联系
排序后的结果仍然存放在slotdefs中,python虚拟机这下就可以从头到尾遍历slotdefs,基于每一个slot建立一个descriptor,然后在tp_dict中建立从操作名到descriptor的关联,这个过程是在add_operators中完成的。
//typeobject.c
static int
add_operators(PyTypeObject *type)
{
PyObject *dict = type->tp_dict;
slotdef *p;
PyObject *descr;
void **ptr;
//对slotdefs进行排序
init_slotdefs();
for (p = slotdefs; p->name; p++) {
//如果slot中没有指定wrapper,则无需处理
if (p->wrapper == NULL)
continue;
//获得slot对应的操作在PyTypeObject中的函数指针
ptr = slotptr(type, p->offset);
if (!ptr || !*ptr)
continue;
//如果tp_dict中已经存在操作名,则放弃
if (PyDict_GetItem(dict, p->name_strobj))
continue;
if (*ptr == (void *)PyObject_HashNotImplemented) {
/* Classes may prevent the inheritance of the tp_hash
slot by storing PyObject_HashNotImplemented in it. Make it
visible as a None value for the __hash__ attribute. */
if (PyDict_SetItem(dict, p->name_strobj, Py_None) < 0)
return -1;
}
else {
//创建descriptor
descr = PyDescr_NewWrapper(type, p, *ptr);
if (descr == NULL)
return -1;
//将(操作名,descriptor)放入tp_dict中
if (PyDict_SetItem(dict, p->name_strobj, descr) < 0) {
Py_DECREF(descr);
return -1;
}
Py_DECREF(descr);
}
}
if (type->tp_new != NULL) {
if (add_tp_new_wrapper(type) < 0)
return -1;
}
return 0;
}
在add_operators中,首先调用前面剖析过的init_slotdefs对操作进行排序,然后遍历排序完成后的slotdefs结构体数组,对其中的每一个slot(slotdef),通过slotptr获得该slot对应的操作在PyTypeObject中的函数指针,并接着创建descriptor,在tp_dict中建立从操作名(slotdef.name_strobj)到操作(descriptor)的关联。
但是需要注意的是,在创建descriptor之前,python虚拟机会检查在tp_dict中操作名是否存在,如果存在了,则不会再次建立从操作名到操作的关联。不过也正是这种检查机制与排序机制相结合,python虚拟机在能在拥有相同操作名的多个操作中选择优先级最高的操作。
在add_operators中,上面的动作都很简单、直观,而最难的动作隐藏在slotptr这个函数当中。它的功能是完成从slot到slot对应操作的真实函数指针的转换。我们知道,在slot中存放着用来操作的offset,但不幸的是,这个offset是相对于PyHeapTypeObject的偏移,而操作的真实函数指针却是在PyTypeObject中指定的,而且PyTypeObject和PyHeapTypeObject不是同构的,因为PyHeapTypeObject中包含了PyNumberMethods结构体,但PyTypeObject只包含了PyNumberMethods *指针。所以slot中存储的关于操作的offset对PyTypeObject来说,不能直接用,必须通过转换。
举个栗子,假如说调用slotptr(&PyList_Type, offset(PyHeapTypeObject, mp_subscript)),首先判断这个偏移量大于offset(PyHeapTypeObject, as_mapping),所以会先从PyTypeObject对象中获得as_mapping指针p,然后在p的基础上进行偏移就可以得到实际的函数地址,所以偏移量delta为:
offset(PyHeapTypeObject, mp_subscript) - offset(PyHeapTypeObject, as_mapping)
而这个复杂的过程就在slotptr中完成
static void **
slotptr(PyTypeObject *type, int ioffset)
{
char *ptr;
long offset = ioffset;
/* Note: this depends on the order of the members of PyHeapTypeObject! */
assert(offset >= 0);
assert((size_t)offset < offsetof(PyHeapTypeObject, as_buffer));
//判断从PyHeapTypeObject中排在后面的PySequenceMethods开始,然后向前,依次判断PyMappingMethods和PyNumberMethods呢。
/*
为什么要这么做呢?假设我们首先从PyNumberMethods开始判断,如果一个操作的offset大于在PyHeapTypeObject中,as_numbers在PyNumberMethods的偏移量,那么我们还是没办法确认这个操作到底是属于谁的。只有从后往前进行判断,才能解决这个问题。
*/
if ((size_t)offset >= offsetof(PyHeapTypeObject, as_sequence)) {
ptr = (char *)type->tp_as_sequence;
offset -= offsetof(PyHeapTypeObject, as_sequence);
}
else if ((size_t)offset >= offsetof(PyHeapTypeObject, as_mapping)) {
ptr = (char *)type->tp_as_mapping;
offset -= offsetof(PyHeapTypeObject, as_mapping);
}
else if ((size_t)offset >= offsetof(PyHeapTypeObject, as_number)) {
ptr = (char *)type->tp_as_number;
offset -= offsetof(PyHeapTypeObject, as_number);
}
else if ((size_t)offset >= offsetof(PyHeapTypeObject, as_async)) {
ptr = (char *)type->tp_as_async;
offset -= offsetof(PyHeapTypeObject, as_async);
}
else {
ptr = (char *)type;
}
if (ptr != NULL)
ptr += offset;
return (void **)ptr;
}
好了,我想到现在我们应该能够摸清楚Python在改造PyTypeObject对象时对tp_dict做了什么了,我们以PyList_Type举例说明:

在add_operators完成之后,PyList_Type如图所示。从PyList_Type.tp_as_mapping中延伸出去的部分是在编译时就已经确定好了的,而从tp_dict中延伸出去的部分则是在python运行时环境初始化的时候才建立的。
PyType_Ready在通过add_operators添加了PyTypeObject对象中定义的一些operator后,还会通过add_methods、add_numbers和add_getsets添加在PyTypeObject中定义的tp_methods、tp_members和tp_getset函数集。这些add_xxx的过程和add_operators类似,不过最后添加到tp_dict中descriptor就不再是PyWrapperDescrObject,而分别是PyMethodDescrObject、PyMemberDescrObject、PyGetSetDescrObject。
从目前来看,基本上算是解析完了,但是还有一点:
class A(list):
def __repr__(self):
return "xxx"
a = A()
print(a) # xxx
显然当我们print(a)的时候,应该调用A.tp_repr函数,对照PyList_Type的布局,应该调用list_repr这个函数,然而事实却并非如此,python虚拟机调用的是我们在A中重写的__repr__方法。这意味着python在初始化A的时候,对tp_repr进行了特殊处理。为什么python虚拟机会知道要对tp_repr进行特殊处理呢?当然肯定有人会说:这是因为我们重写了__repr__方法啊,确实如此,但这是python层面上的,在底层的话,答案还是在slot身上。
在slotdefs中,存在:
//typeobject.c
static slotdef slotdefs[] = {
...
TPSLOT("__repr__", tp_repr, slot_tp_repr, wrap_unaryfunc,
"__repr__($self, /)
--
Return repr(self)."),
...
}
python虚拟机在初始化A时,会检查A的tp_dict中是否存在__repr__,在后面剖析自定义class对象的创建时会看到,因为在定义class A的时候,重写了__repr__这个操作,所以在A.tp_dict中,__repr__一开始就会存在,python虚拟机会检测到,然后会根据__repr__对应的slot顺藤摸瓜,找到tp_repr,并且将这个函数指针替换为slot中指定的&slot_tp_repr。所以当后来虚拟机找A.tp_repr的时候,实际上找的是slot_tp_repr。
//typeobject.c
static PyObject *
slot_tp_repr(PyObject *self)
{
PyObject *func, *res;
_Py_IDENTIFIER(__repr__);
int unbound;
//查找__repr__属性
func = lookup_maybe_method(self, &PyId___repr__, &unbound);
if (func != NULL) {
//调用__repr__对应的对象
res = call_unbound_noarg(unbound, func, self);
Py_DECREF(func);
return res;
}
PyErr_Clear();
return PyUnicode_FromFormat("<%s object at %p>",
Py_TYPE(self)->tp_name, self);
}
在slot_tp_repr中,会寻找__repr__属性对应的对象,正好就会找到在A中重写的函数,后面会看到,这个对象实际上就一个PyFunctionObject对象。这样一来,就完成了对默认的list的repr行为的替换。所以对于A来说,内存布局就是下面这样。

当然这仅仅是针对于__repr__,对于其他的操作还是会指向PyList_Type中指定的函数,比如tp_iter还是会指向list_iter
对于A来说,这个变化是在fixup_slot_dispatchers这个函数中完成的,对于内建对象则不会进行此操作。
static void
fixup_slot_dispatchers(PyTypeObject *type)
{
slotdef *p;
init_slotdefs();
for (p = slotdefs; p->name; )
//遍历、更新slot
p = update_one_slot(type, p);
}
13.2.3.4 确定MRO
MRO,即method resolve order,说白了就是类继承之后、属性或方法的查找顺序。如果python是单继承的话,那么这就不是问题了,但是python是支持多继承的,那么在多继承时,继承的顺序就成为了一个必须考虑的问题。
class A:
def foo(self):
print("A")
class B(A):
def foo(self):
print("B")
class C(A):
def foo(self):
print("C")
self.bar()
def bar(self):
print("bar C")
class D(C, B):
def bar(self):
print("bar D")
d = D()
d.foo()
"""
C
bar D
"""
首先我们看到,打印的是C,说明调用的是C的foo函数,这说明把C写在前面,会调用C的方法,但是下面打印了bar D,这是因为C里面的self,实际上是D的实例对象。D在找不到foo函数的时候,会到父类里面找,但是同时也会将self传递过去,所以调用self.bar的时候,会到D里面找,如果找不到再去父类里面找。
在底层则是先在PyType_Ready中通过mro_internal确定mro的顺序,python虚拟机将创建一个tuple对象,里面存放一组类对象,这些对象的顺序就是虚拟机确定的mro的顺序,最终这个tuple会被保存在PyTypeObject.tp_mro中。
由于mro_internal内部的实现机制相当复杂,所以我们将会只从python的代码层面来理解。首先我们说python早期有经典类和新式类两种类,现在则只存在新式类。而经典类的类搜索方式采用的是深度优先,而新式类则是广度优先(当然现在用的是新的算法,具体什么算法后面说,暂时理解为广度优先即可),举个例子:

对于上图来说,如果是经典类:显然是属性查找是先从A找到I,再从C找到G。而对于新式类,也是同样的结果,对于上图这种继承结构,至于两边是否一样多则不重要,经典类和新式类是一样的。我们先看结论,我们下面显示的都只是新式类。
# 这里是python3.7 新式类
I = type("I", (), {})
H = type("H", (I,), {})
F = type("F", (H,), {})
G = type("G", (), {})
D = type("D", (F,), {})
E = type("E", (G,), {})
B = type("B", (D,), {})
C = type("C", (E,), {})
A = type("A", (B, C), {})
for _ in A.__mro__:
print(_)
"""
<class '__main__.A'>
<class '__main__.B'>
<class '__main__.D'>
<class '__main__.F'>
<class '__main__.H'>
<class '__main__.I'>
<class '__main__.C'>
<class '__main__.E'>
<class '__main__.G'>
<class 'object'>
"""
对于A继承两个类,这个两个类分别继续继承,如果最终没有继承公共的类(暂时先忽略object),那么经典类和新式类是一样的,像这种泾渭分明、各自继承各自的,都是先一条路找到黑,然后再去另外一条路去找。
如果是下面这种,最终分久必合、两者最终又继承了同一个类,那么经典类还是跟以前一样,按照每一条路都走到黑的方式。但是对于新式类,则是先从A找到H,而I这个两边最终继承的类不找了,然后从C找到I,也就是在另一条路找到头。

# 新式类
I = type("I", (), {})
H = type("H", (I,), {})
F = type("F", (H,), {})
G = type("G", (I,), {}) # 这里让G继承I
D = type("D", (F,), {})
E = type("E", (G,), {})
B = type("B", (D,), {})
C = type("C", (E,), {})
A = type("A", (B, C), {})
for _ in A.__mro__:
print(_)
"""
<class '__main__.A'>
<class '__main__.B'>
<class '__main__.D'>
<class '__main__.F'>
<class '__main__.H'>
<class '__main__.C'>
<class '__main__.E'>
<class '__main__.G'>
<class '__main__.I'>
<class 'object'>
"""
因此对于最下面的类继承两个类,然后继承的两个类再次继承的时候,向上只继承一个类,对于这种模式,那么结论、也就是mro顺序就是我们上面分析的那样。不过对新式类来说,因为所有类默认都是继承object,所以第一张图中,即使我们没画完,但是也能想到,两条泾渭分明的继承链的上方最终应该都指向class object。那么我们依旧可以用刚才的理论来解释,在第一条继承链中找到object的前一个类不找了,然后在第二条继承链中一直找到object。
但是python的多继承远比我们想象的要复杂,原因就在于可以任意继承,如果B和C再分别继承两个类呢?那么我们这里的线路就又要多出两条了,不过既然要追求刺激,就贯彻到底喽。但是下面我们就只会介绍新式类了,经典类了解一下就可以了。
另外我们之前说新式类采用的是广度优先,但是实际上这样有一个问题:
假设我们调用A的foo方法,但是A里面没有,那么理所应当会去B里面找,但是B里面也没有,而C和D里面有,那么这个时候是去C里面找还是去D里面找呢?根据我们之前的结论,显然是去D里面找,可如果按照广度优先的逻辑来说,那么应该是去C里面找啊。所以广度优先理论在这里就不适用了,因为B继承了D,而B和C并没有直接关系,我们应该把B和D看成一个整体。因此python中的广度优先实际上是采用了一种叫做C3的算法。
这个C3算法比较复杂,涉及到拓扑学,如果再去研究拓扑学就本末倒置了。因此,对于python的多继承来说,我只希望记住一句不是很好理解的话:当沿着一条继承链寻找类时,如果这个类出现在了另一条继承链当中,那么当前的继承链的搜索就会结束,然后在"最开始"出现分歧的地方转向下一条继承链的搜索。这是我个人总结的,或许比较难理解,但是通过例子就能明白了。

这个箭头表示继承关系,继承顺序是从左到右,比如这里的A就相当于class A(B, C),下面我们来从头到尾分析一下。
首先最开始的顺序是A,如果我们获取A的mro的话然后A继承B和C,由于是两条路,因此我们说A这里就是一个分歧点,但是由于B在前,所以接下来是B。现在mro的顺序是A B但是B这里也出现了分歧点,不过不用管,我们关注的是最开始出现分歧的地方。现在mro的顺序是A B D然后从D开始寻找,这里注意了,按理说会找G的,但是G不止被一个人继承,也就是意味着沿着当前的继承链查找G时,G还出现在了其它的继承链当中。怎么办?显然要回到最初的分歧点,转向下一条继承链的搜索最初的分歧点是A,那么该去找C了,现在mro的顺序就是A B D C注意C这里出现了分歧点,而A的分支已经结束了,所以现在C就是最初的分歧点了。而C继承自E和F,显然要搜索E,那么此时mro的顺序就是A B D C E然后从E开始搜索,显然要搜索G,此时mro顺序是A B D C E G从G要搜索I,注意这里I可没有被H继承哦。此时mro顺序是A B D C E G I从I开始搜索谁呢?J显然出现在了其它的继承链中,那么要回到最初分歧的地方,也就是C,那么下面显然要找F,此时mro顺序是A B D C E G I FF只继承了H,那么肯定要找H,此时mro顺序是 A B D C E G I F HH显然只能找J了,因此最终A的mro顺序就是A B D C E G I F H J object
J = type("J", (object, ), {})
I = type("I", (J, ), {})
H = type("H", (J, ), {})
G = type("G", (I, ), {})
F = type("F", (H, ), {})
E = type("E", (G, H), {})
D = type("D", (G, ), {})
C = type("C", (E, F), {})
B = type("B", (D, E), {})
A = type("A", (B, C), {})
# A B D C E G I F H J
for _ in A.__mro__:
print(_)
"""
<class '__main__.A'>
<class '__main__.B'>
<class '__main__.D'>
<class '__main__.C'>
<class '__main__.E'>
<class '__main__.G'>
<class '__main__.I'>
<class '__main__.F'>
<class '__main__.H'>
<class '__main__.J'>
<class 'object'>
"""
我们再看一个例子
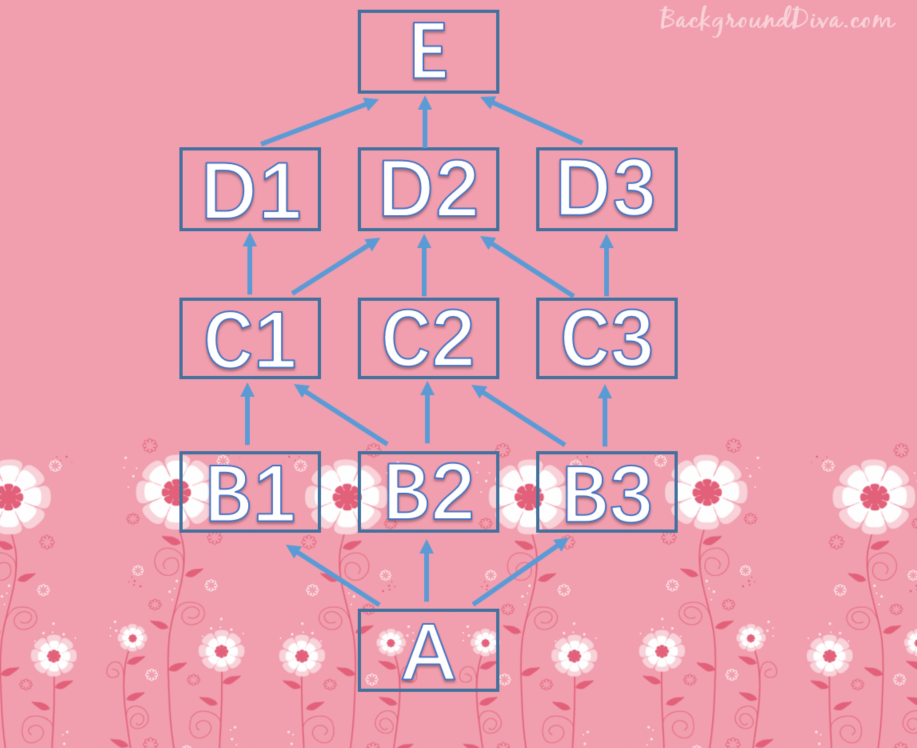
首先是A,A继承B1,B2,B3,会先走B1,此时mro是A B1,注意现在A是分歧点从B1本来该找C1,但是C1还被其他类继承,也就是出现在了其它的继承链当中,因此要回到最初分歧点A,从下一条继承链开始找,显然要找B2,此时mro就是A B1 B2从B2开始,显然要找C1,此时mro顺序就是A B1 B2 C1从C1开始,显然要找D1,因为D1只被C1继承,此时mro顺序是A B1 B2 C1 D1从D1显然不会找E的,咋办,回到最初的分歧点,注意这里显然还是A,因为A的分支还没有走完。显然此时要走B3,那么mro顺序就是A B1 B2 C1 D1 B3从B3开始找,显然要找C2,注意:A的分支已经走完,此时B3就成了新的最初分歧点。现在mro顺序是A B1 B2 C1 D1 B3 C2C2会找D2吗?显然不会,因为它还被C3继承,所以它出现在了其他的继承链中。所以要回到最初分歧点,这里是B3,显然下面要找C3,另外由于B3的分支也已经走完,所以现在C3就成了新的最初分歧点。此时mro顺序是A B1 B2 C1 D1 B3 C2 C3从C3开始,显然要找D2,此时mro顺序是A B1 B2 C1 D1 B3 C2 C3 D2但是D2不会找E,因此回到最初分歧点C3,下面就找D3,然后显然只能再找E了,显然最终mro顺序A B1 B2 C1 D1 B3 C2 C3 D2 D3 E object
E = type("E", (), {})
D1 = type("D1", (E,), {})
D2 = type("D2", (E,), {})
D3 = type("D3", (E,), {})
C1 = type("C1", (D1, D2), {})
C2 = type("C2", (D2,), {})
C3 = type("C3", (D2, D3), {})
B1 = type("B1", (C1,), {})
B2 = type("B2", (C1, C2), {})
B3 = type("B3", (C2, C3), {})
A = type("A", (B1, B2, B3), {})
for _ in A.__mro__:
print(_)
"""
<class '__main__.A'>
<class '__main__.B1'>
<class '__main__.B2'>
<class '__main__.C1'>
<class '__main__.D1'>
<class '__main__.B3'>
<class '__main__.C2'>
<class '__main__.C3'>
<class '__main__.D2'>
<class '__main__.D3'>
<class '__main__.E'>
<class 'object'>
"""
底层源码我们就不再看了,个人觉得从目前这个层面来理解已经足够了。
13.2.3.5 继承基类操作
python虚拟机确定了mro顺序列表之后,就会遍历mro列表(第一个类对象会是其自身,比如A.__mro__的第一个元素就是A本身,所以遍历是从第二项开始的)。在mro列表中实际上存储的就是类对象的所有直接基类、间接基类,python虚拟机会将自身没有、但是基类(注意:包括间接基类,比如基类的基类)中存在的操作拷贝到该类当中,从而完成对基类操作的继承动作。
而这个继承操作的动作是发生在inherit_slots中
//typeobject.c
int
PyType_Ready(PyTypeObject *type)
{
PyObject *dict, *bases;
PyTypeObject *base;
Py_ssize_t i, n;
...
...
bases = type->tp_mro;
assert(bases != NULL);
assert(PyTuple_Check(bases));
n = PyTuple_GET_SIZE(bases);
for (i = 1; i < n; i++) {
PyObject *b = PyTuple_GET_ITEM(bases, i);
if (PyType_Check(b))
inherit_slots(type, (PyTypeObject *)b);
}
...
...
}
在inherit_slots中会拷贝相当多的操作,这里就拿nb_add(整型则对应long_add)来举个栗子
static void
inherit_slots(PyTypeObject *type, PyTypeObject *base)
{
PyTypeObject *basebase;
#undef SLOTDEFINED
#undef COPYSLOT
#undef COPYNUM
#undef COPYSEQ
#undef COPYMAP
#undef COPYBUF
#define SLOTDEFINED(SLOT)
(base->SLOT != 0 &&
(basebase == NULL || base->SLOT != basebase->SLOT))
#define COPYSLOT(SLOT)
if (!type->SLOT && SLOTDEFINED(SLOT)) type->SLOT = base->SLOT
#define COPYASYNC(SLOT) COPYSLOT(tp_as_async->SLOT)
#define COPYNUM(SLOT) COPYSLOT(tp_as_number->SLOT)
#define COPYSEQ(SLOT) COPYSLOT(tp_as_sequence->SLOT)
#define COPYMAP(SLOT) COPYSLOT(tp_as_mapping->SLOT)
#define COPYBUF(SLOT) COPYSLOT(tp_as_buffer->SLOT)
/* This won't inherit indirect slots (from tp_as_number etc.)
if type doesn't provide the space. */
if (type->tp_as_number != NULL && base->tp_as_number != NULL) {
basebase = base->tp_base;
if (basebase->tp_as_number == NULL)
basebase = NULL;
COPYNUM(nb_add);
COPYNUM(nb_subtract);
COPYNUM(nb_multiply);
COPYNUM(nb_remainder);
COPYNUM(nb_divmod);
COPYNUM(nb_power);
COPYNUM(nb_negative);
COPYNUM(nb_positive);
COPYNUM(nb_absolute);
COPYNUM(nb_bool);
...
...
}
我们在里面看到很多熟悉的东西,如果你常用魔法方法的话。而且我们知道PyBool_Type中并没有设置nb_add,但是PyLong_Type中却设置了nb_add操作,而bool继承int。所以对布尔类型是可以直接进行运算的,当然和整型、浮点型运算也是可以的。所以在numpy中,判断一个数组中多少个满足条件的元素,可以使用numpy提供的机制进行比较,会得到一个同样长度的数组,里面的每一个元素为是否满足条件所对应的布尔值。然后直接通过sum运算即可,因为运算的时候,True会被解释成1,False会被解释成0。
import numpy as np
arr = np.array([2, 4, 7, 3, 5])
print(arr > 4) # [False False True False True]
print(sum(arr > 4)) # 2
print(2.2 + True) # 3.2
所以在python中,整型是可以和布尔类型进行运算的,看似不可思议,但又在情理之中。
不过下面有一个例子,想一想为什么是这个结果
d = {1: "aaa"}
d[True] = "bbb"
print(d) # {1: 'bbb'}
我们说True在被当成int的时候会被解释成1,而原来的字典里面已经有1这个key了,所以此时True和1是等价的。原来的1还是1,d[True]等价于d[1],所以value被换成了"bbb"
d = {1: "aaa1", False: "bbb1"}
d[True] = "aaa2"
d[0] = "bbb2"
print(d) # {1: 'aaa2', False: 'bbb2'}
d[1.0] = "aaa3"
d[0.0] = "bbb3"
print(d) # {1: 'aaa3', False: 'bbb3'}
可见,对于字典的存储来说,True、1、1.0三者等价,False、0、0.0三者等价。
d = {1: "a", True: "b", 1.0: "c"}
print(d) # {1: 'c'}
# 尽管等价,但是key就是最先出现的key,比如这里先出现的是1,那么后续只会把1对应的value换掉,而不会换掉1这个key
13.2.3.6 填充基类中的子类列表
到这里,PyType_Ready还剩下最后一个重要的动作了:设置基类中的子类列表。在每一个PyTypeObject中,有一个tp_subclasses,这个东西在PyType_Ready完成之后,将会是一个list对象。其中存放着所有直接继承自类的类对象,PyType_Ready是通过调用add_subclass完成向这个tp_subclasses中填充子类的动作。
int
PyType_Ready(PyTypeObject *type)
{
PyObject *dict, *bases;
PyTypeObject *base;
Py_ssize_t i, n;
//填充基类的子类列表
bases = type->tp_bases;
n = PyTuple_GET_SIZE(bases);
for (i = 0; i < n; i++) {
PyObject *b = PyTuple_GET_ITEM(bases, i);
if (PyType_Check(b) &&
add_subclass((PyTypeObject *)b, type) < 0)
goto error;
}
}
print(object.__subclasses__())
# [<class 'type'>, <class 'weakref'>, <class 'weakcallableproxy'>,
# <class 'weakproxy'>, <class 'int'>, <class 'bytearray'>, <class 'bytes'>,
# <class 'list'>, <class 'NoneType'>, <class 'NotImplementedType'>,
# <class 'traceback'>, <class 'super'>, ... ... ...
果然,python里面的object不愧是万物之父,这么多的内建对象都是继承自object的。到了这里,我们才算是完整的剖析了PyType_Ready的动作,可以看到,python虚拟机对python的内建对象对应的PyTypeObject进行了多种繁杂的改造工作,可以包括以下几部分:
设置type信息,基类及基类列表
填充tp_dict
确定mro列表
基于mro列表从基类继承操作
设置基类的子类列表,
不同的类型,有些操作也会有一些不同的行为,但整体是一致的。因此具体某个特定类型,可以自己跟踪PyType_Ready的操作。
13.3 自定义class
下面就对用户自定义的class、也就是我们最开始分类的class对象的剖析。
# a.py
class A:
name = "Python"
def __init__(self):
print("A->__init__")
def f(self):
print("A->self")
def g(self, value):
self.value = value
print(self.value)
a = A()
a.f()
a.g(10)
"""
A->__init__
A->self
10
"""
通过之前对函数机制的分析中,我们知道,对于一个包含函数定义的python源文件,在编译之后,会得到一个和源文件对应的PyCodeObject对象,假设叫module,而与函数对应的PyCodeObject对象,假设叫func,那么func显然存储在module中。那么对于包含类的python源文件,编译之后的结果又是怎么样的呢?
我们可以照葫芦画瓢,根据以前的经验,推测a.py对应的PyCodeObject对象包含与class对应的PyCodeObject,而与class对应的PyCodeObject会包含3个与函数对应的PyCodeObject,然而事实正是如此。
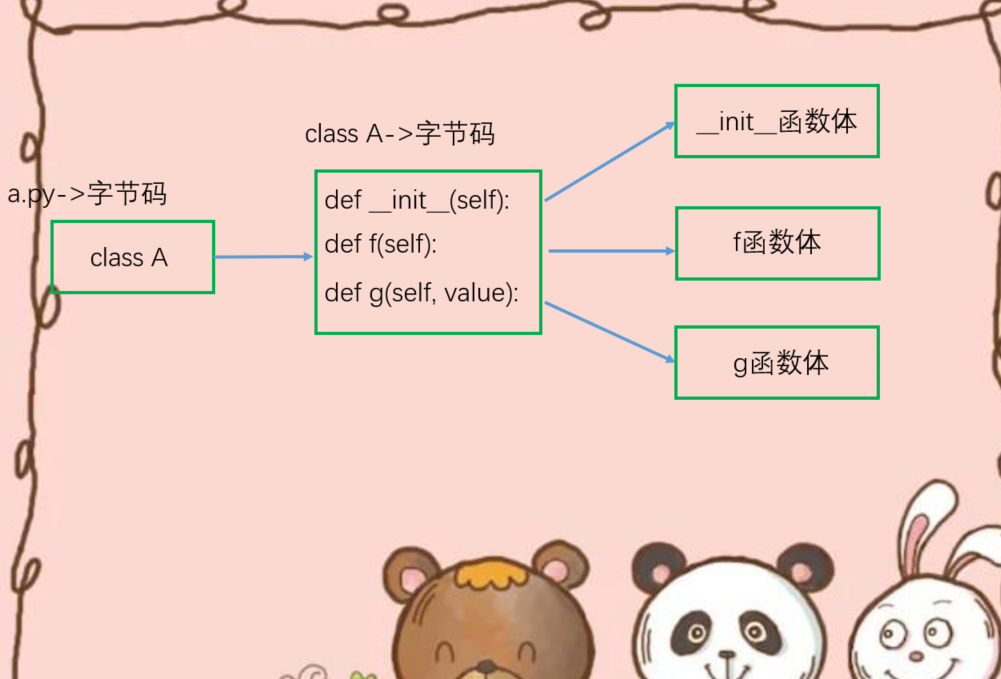
在介绍函数的时候,我们看到函数的声明、def语句和函数的实现代码虽然是一个逻辑整体,但是它们的字节码指令确实分离在两个PyCodeObject对象中的。在类中,同样存在这样的分离现象。声明类的class语句,编译后的字节码指令存储在模块对应的PyCodeObject中,而类的实现、也就是类里面的逻辑,编译后的字节码指令序列则存储在类对应的的PyCodeObject中。所以我们在模块级别中只能找到类,无法直接找到类里面的成员。
另外还可以看到,类的成员函数和一般的函数相同,也会有这种声明和实现分离的现象。其实也很好理解,就把类和函数想象成变量就行了,类名、函数名就是变量名,而类、函数里面的逻辑想象成值,一个变量对应一个值。
13.3.1 class对象的动态元信息
class对应(class关键字创建的类)的元信息指的就是关于class的信息,比如说class的名称、它所拥有的的属性、方法,该class实例化时要为实例对象申请的内存空间大小等。对于a.py中定义的class A来说,我们必须知道这样的信息:在class A中,有一个符号f,这个f对应一个函数;还有一个符号g,这个g也对应了一个函数。有了这些关于A的元信息,才能创建class对象,否则我们是没办法创建的。元信息是一个非常重要的概念,比如说hive,数据的元信息就是存储在mysql里面的,而在编程语言中,正是通过元信息才实现了反射等动态特性。而在python中,元信息的概念被发挥的淋漓尽致,因此python也提供了其他编程语言所不具备的高度灵活的动态特征。
下面还是老规矩,查看a.py的字节码
class A(object):
name = "Python"
def __init__(self):
print("A->__init__")
def f(self):
print("A->self")
def g(self, value):
self.value = value
print(self.value)
1 0 LOAD_BUILD_CLASS
2 LOAD_CONST 0 (<code object A at 0x0000027F75147C90, file "a.py", line 1>)
4 LOAD_CONST 1 ('A')
6 MAKE_FUNCTION 0
8 LOAD_CONST 1 ('A')
10 LOAD_NAME 0 (object)
12 CALL_FUNCTION 3
14 STORE_NAME 0 (A)
16 LOAD_CONST 2 (None)
18 RETURN_VALUE
Disassembly of <code object A at 0x0000027F75147C90, file "a.py", line 1>:
1 0 LOAD_NAME 0 (__name__)
2 STORE_NAME 1 (__module__)
4 LOAD_CONST 0 ('A')
6 STORE_NAME 2 (__qualname__)
3 8 LOAD_CONST 1 ('Python')
10 STORE_NAME 3 (name)
5 12 LOAD_CONST 2 (<code object __init__ at 0x0000027F750DA870, file "a.py", line 5>)
14 LOAD_CONST 3 ('A.__init__')
16 MAKE_FUNCTION 0
18 STORE_NAME 4 (__init__)
8 20 LOAD_CONST 4 (<code object f at 0x0000027F75145190, file "a.py", line 8>)
22 LOAD_CONST 5 ('A.f')
24 MAKE_FUNCTION 0
26 STORE_NAME 5 (f)
11 28 LOAD_CONST 6 (<code object g at 0x0000027F751457C0, file "a.py", line 11>)
30 LOAD_CONST 7 ('A.g')
32 MAKE_FUNCTION 0
34 STORE_NAME 6 (g)
36 LOAD_CONST 8 (None)
38 RETURN_VALUE
Disassembly of <code object __init__ at 0x0000027F750DA870, file "a.py", line 5>:
6 0 LOAD_GLOBAL 0 (print)
2 LOAD_CONST 1 ('A->__init__')
4 CALL_FUNCTION 1
6 POP_TOP
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
Disassembly of <code object f at 0x0000027F75145190, file "a.py", line 8>:
9 0 LOAD_GLOBAL 0 (print)
2 LOAD_CONST 1 ('A->self')
4 CALL_FUNCTION 1
6 POP_TOP
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
Disassembly of <code object g at 0x0000027F751457C0, file "a.py", line 11>:
12 0 LOAD_FAST 1 (value)
2 LOAD_FAST 0 (self)
4 STORE_ATTR 0 (value)
13 6 LOAD_GLOBAL 1 (print)
8 LOAD_FAST 0 (self)
10 LOAD_ATTR 0 (value)
12 CALL_FUNCTION 1
14 POP_TOP
16 LOAD_CONST 0 (None)
18 RETURN_VALUE
字节码比较长,我们逐行分析,当然很多字节码我们都见过了,因此有的字节码介绍的时候就不会特别详细了。
我们仔细观察一下字节码,发现分为五个部分,模块的字节码、class的字节码、class的三个函数的字节码。
我们先来看看模块的字节码:
1 0 LOAD_BUILD_CLASS
2 LOAD_CONST 0 (<code object A at 0x0000027F75147C90, file "a.py", line 1>)
4 LOAD_CONST 1 ('A')
6 MAKE_FUNCTION 0
8 LOAD_CONST 1 ('A')
10 LOAD_NAME 0 (object)
12 CALL_FUNCTION 3
14 STORE_NAME 0 (A)
16 LOAD_CONST 2 (None)
18 RETURN_VALUE
0 LOAD_BUILD_CLASS,我们注意到这又是一条我们没见过的新指令。从名字也能看出来这是要构建一个类,其实对于A这个类来说,也是要先MAKE_FUNCTION的,但是要转化为类,所以要LOAD_BUILD_CLASS
//ceval.c
TARGET(LOAD_BUILD_CLASS) {
_Py_IDENTIFIER(__build_class__);
PyObject *bc;
if (PyDict_CheckExact(f->f_builtins)) {
//从f_builtins里面获取PyId___build_class__
bc = _PyDict_GetItemId(f->f_builtins, &PyId___build_class__);
if (bc == NULL) {
PyErr_SetString(PyExc_NameError,
"__build_class__ not found");
goto error;
}
Py_INCREF(bc);
}
else {
PyObject *build_class_str = _PyUnicode_FromId(&PyId___build_class__);
if (build_class_str == NULL)
goto error;
bc = PyObject_GetItem(f->f_builtins, build_class_str);
if (bc == NULL) {
if (PyErr_ExceptionMatches(PyExc_KeyError))
PyErr_SetString(PyExc_NameError,
"__build_class__ not found");
goto error;
}
}
//入栈
PUSH(bc);
DISPATCH();
}
LOAD_BUILD_CLASS是从python的内置函数中取得__build_class__将其入栈,然后下面的几个指令很好理解,但是却出现了一个CALL_FUNCTION是做什么的,我们目前还没有调用啊,其实这个CALL_FUNCTION使用来生成类的,我们看到它的参数个数是3个,分别是:A的PyFunctionObject、A、__build_class_class__,因此:
class A(object):
pass
# 在底层将会被翻译成
A = __build_class__(<PyFunctionObject A>, A, object)
# 所以我们发现这个函数至少需要两个参数
import sys
# 在python中我们需要使用builtins模块来导入,才能使用__build_class__
import builtins
try:
builtins.__build_class__()
except Exception as e:
exc_type, exc_value, _ = sys.exc_info()
print(exc_type, exc_value) # class 'TypeError'> __build_class__: not enough arguments
try:
builtins.__build_class__("", "")
except Exception as e:
exc_type, exc_value, _ = sys.exc_info()
print(exc_type, exc_value) # <class 'TypeError'> __build_class__: func must be a function
try:
builtins.__build_class__(lambda: 123, 123)
except Exception as e:
exc_type, exc_value, _ = sys.exc_info()
print(exc_type, exc_value) # <class 'TypeError'> __build_class__: name is not a string
但是报了三种错误,记住这几个报错信息,后面马上就会看到。
所以现在就明白为什么会出现CALL_FUNCTION这条指令,__build_class__就是用来将一个函数对象变成一个class对象。其实这个过程有点像闭包,如果把class想象成def的话,那么是可以当成闭包的,而这个__build_class__正是将闭包函数build成class之后,通过实例调用内部方法(闭包)时,会将实例本身传给方法(闭包)的第一个参数。
class的字节码:
Disassembly of <code object A at 0x0000027F75147C90, file "a.py", line 1>:
1 0 LOAD_NAME 0 (__name__)
2 STORE_NAME 1 (__module__)
4 LOAD_CONST 0 ('A')
6 STORE_NAME 2 (__qualname__)
3 8 LOAD_CONST 1 ('Python')
10 STORE_NAME 3 (name)
5 12 LOAD_CONST 2 (<code object __init__ at 0x0000027F750DA870, file "a.py", line 5>)
14 LOAD_CONST 3 ('A.__init__')
16 MAKE_FUNCTION 0
18 STORE_NAME 4 (__init__)
8 20 LOAD_CONST 4 (<code object f at 0x0000027F75145190, file "a.py", line 8>)
22 LOAD_CONST 5 ('A.f')
24 MAKE_FUNCTION 0
26 STORE_NAME 5 (f)
11 28 LOAD_CONST 6 (<code object g at 0x0000027F751457C0, file "a.py", line 11>)
30 LOAD_CONST 7 ('A.g')
32 MAKE_FUNCTION 0
34 STORE_NAME 6 (g)
36 LOAD_CONST 8 (None)
38 RETURN_VALUE
这里插一嘴,有些人可能对这个字节码顺序不是很理解,对于dis.dis来说,是先对整个模块、然后是类和变量和函数等等。比如:这里的创建类,执行模块的字节码,只是提示要build一个类,当我们调用的时候,也只是告诉我们要进行调用。对于类的字节码,只是提示创建了几个函数,但是函数的细节并没有说,然后函数的字节码,才是真正解析里面的逻辑。因此一个模块里面有个类,类里面有一个函数,函数有里面写逻辑,那么这个字节码会分成三部分。模块的字节码,dis.dis会告诉我们创建了一个类,解释类的字节码,dis.dis会告诉我们创建一个函数,调用也仅仅是LOAD_CONST、CALL_FUNCTION,告诉我们函数调用了。解释函数的字节码的时候,才会告诉我们函数的执行逻辑。如果函数里面还有个闭包,那么闭包的逻辑也是不会告诉我们,仅仅是说创建了一个闭包,只有执行闭包的字节码的时候,dis.dis会告诉我们闭包里面的逻辑是如何执行的。说的很绕口,但是dis.dis打印出的字节码的执行流程是分层级的,个人觉得这样的展示方式是很合理的,很清晰。
对于class A的字节码。开始的LOAD_NAME和STORE_NAME是将符号__module__和全局命名空间中符号__name___的值(__main_)关联了起来,并放入到local命名空间(PyFrameObject的f_locals)中。需要说明的是,我们在介绍函数的时候提过,当时我们说:"函数的局部变量是不可变的,在编译的时候就已经确定了,是以一种静态方式放在了运行时栈前面的那段内存中,并没有放在f_locals中,f_locals其实是一个NULL,我们通过locals()拿到的只是对运行时栈前面的内存的一个拷贝,函数里面的局部变量是通过静态方式来访问的。而类就不一样了,类是可以动态修改的,可以随时增加属性、方法,这就意味着类是不可能通过静态方式来查找属性的"。而事实上也确实如此,类也有一个f_locals,但它指向的就不再是NULL了,而和f_globals一样,也是一个PyDictObject对象。然后是LOAD_CONST,将字符串"A"load进来,和__qualname__组成一个entry存储在A的locals中。
class Cls:
pass
# 将__name__ load进来,对于当前模块来说就是__main__
print(__name__) # __main__
# 然后和Cls中的locals中的__module__关联起来,所以这两者是一样的
print(Cls.__module__) # __main__
# 将字符串Cls load进来,和__qualname__关联起来
# 从字节码的分析,显然是这个结果
print(Cls.__qualname__) #Cls
下面的字节码就不用分析了,看过之前的章节的话,会清楚在干什么。连续执行了三个(LOAD_CONST、MAKE_FUNCTION、STORE_NAME),显然每个指令序列都会创建一个与类中成员函数对应的PyFunctionObject对象,并将函数名和其对应的PyFunctionObject对象通过STORE_NAME指令存入到local命名空间中。
到了这时,我们看到已经创建了很多东西。这些东西就是class A的元信息,被放到了local命名空间中,准确的说是动态元信息,既然有动态元信息,那就有静态元信息,关于这两者的区别我们后面介绍。
13.3.2 metaclass
我们说LOAD_BUILD_CLASS是将一个PyFunctionObject变成一个类,尽管它写在最前面,但实际上是需要将class A对应的PyCodeObject对象包装成一个PyFunctionObject对象之后才能执行。我们说__build_class__是用来将PyFunctionObject变成类的函数,我们来看看它长什么样子
//python/bltinmodule.c
static PyMethodDef builtin_methods[] = {
{"__build_class__", (PyCFunction)builtin___build_class__,
METH_FASTCALL | METH_KEYWORDS, build_class_doc},
...
...
}
static PyObject *
builtin___build_class__(PyObject *self, PyObject *const *args, Py_ssize_t nargs,
PyObject *kwnames)
{
PyObject *func, *name, *bases, *mkw, *meta, *winner, *prep, *ns, *orig_bases;
PyObject *cls = NULL, *cell = NULL;
int isclass = 0; /* initialize to prevent gcc warning */
//我们说了底层调用的是builtin___build_class__
//class A: 会被翻译成builtin.__build_class__(PyFunctionObject, "class name")
//所以这个函数只要需要两个参数
if (nargs < 2) {
//参数不足,报错,还记的这个报错信息吗?上面测试过的
PyErr_SetString(PyExc_TypeError,
"__build_class__: not enough arguments");
return NULL;
}
//类对应的PyFunctionObject
func = args[0]; /* Better be callable */
if (!PyFunction_Check(func)) {
//如果不是PyFunctionObject,报错,这个信息有印象吗?
PyErr_SetString(PyExc_TypeError,
"__build_class__: func must be a function");
return NULL;
}
//类对应的名字,__build_class__的时候 总要给类起一个名字吧
name = args[1];
if (!PyUnicode_Check(name)) {
//如果不是一个PyUnicodeObject,报错,这个有印象吗?
PyErr_SetString(PyExc_TypeError,
"__build_class__: name is not a string");
return NULL;
}
//原始基类
orig_bases = _PyStack_AsTupleSlice(args, nargs, 2, nargs);
if (orig_bases == NULL)
return NULL;
//获取class的基类列表
bases = update_bases(orig_bases, args + 2, nargs - 2);
if (bases == NULL) {
Py_DECREF(orig_bases);
return NULL;
}
//创建时kwnames为NULL
if (kwnames == NULL) {
meta = NULL;
mkw = NULL;
}
else {
mkw = _PyStack_AsDict(args + nargs, kwnames);
if (mkw == NULL) {
Py_DECREF(bases);
return NULL;
}
//这里获取meta
meta = _PyDict_GetItemId(mkw, &PyId_metaclass);
if (meta != NULL) {
Py_INCREF(meta);
if (_PyDict_DelItemId(mkw, &PyId_metaclass) < 0) {
Py_DECREF(meta);
Py_DECREF(mkw);
Py_DECREF(bases);
return NULL;
}
/* metaclass is explicitly given, check if it's indeed a class */
isclass = PyType_Check(meta);
}
}
//如果meta为NULL,这意味着用户没有指定metaclass
if (meta == NULL) {
/* if there are no bases, use type: */
//然后尝试获取基类,如果没有基类
if (PyTuple_GET_SIZE(bases) == 0) {
//指定metaclass为type
meta = (PyObject *) (&PyType_Type);
}
/* else get the type of the first base */
//否则使用第一个继承的基类的metaclass
else {
PyObject *base0 = PyTuple_GET_ITEM(bases, 0); //拿到第一基类
meta = (PyObject *) (base0->ob_type); //拿到第一基类的__class__
}
Py_INCREF(meta);
//meta也是一个类
isclass = 1; /* meta is really a class */
}
//如果isclass
if (isclass) {
/* meta is really a class, so check for a more derived
metaclass, or possible metaclass conflicts: */
//元类也是类
//所以winner这里就是bases[0].__class__
winner = (PyObject *)_PyType_CalculateMetaclass((PyTypeObject *)meta,
bases);
if (winner == NULL) {
Py_DECREF(meta);
Py_XDECREF(mkw);
Py_DECREF(bases);
return NULL;
}
if (winner != meta) {
Py_DECREF(meta);
meta = winner;
Py_INCREF(meta);
}
}
/* else: meta is not a class, so we cannot do the metaclass
calculation, so we will use the explicitly given object as it is */
//根据上面的逻辑,我们知道隐含了一个else,由于meta不是一个类,这就意味着无法使用metaclass的逻辑
//会显式地指定一个对象
//__prepare__方法
if (_PyObject_LookupAttrId(meta, &PyId___prepare__, &prep) < 0) {
ns = NULL;
}
//这个__prepare__方法必须返回一个字典,如果返回None,那么默认返回一个孔子点
else if (prep == NULL) {
ns = PyDict_New();
}
else {
//否则将字典返回
PyObject *pargs[2] = {name, bases};
ns = _PyObject_FastCallDict(prep, pargs, 2, mkw);
Py_DECREF(prep);
}
if (ns == NULL) {
Py_DECREF(meta);
Py_XDECREF(mkw);
Py_DECREF(bases);
return NULL;
}
//如果返回的不是一个字典,那么报错,我们来演示一下
if (!PyMapping_Check(ns)) {
PyErr_Format(PyExc_TypeError,
"%.200s.__prepare__() must return a mapping, not %.200s",
isclass ? ((PyTypeObject *)meta)->tp_name : "<metaclass>",
Py_TYPE(ns)->tp_name);
/*
class Meta(type):
@classmethod
def __prepare__(mcs, name, bases):
return 123
class A(metaclass=Meta):
pass
"""
TypeError: Meta.__prepare__() must return a mapping, not int
"""
*/
goto error;
}
cell = PyEval_EvalCodeEx(PyFunction_GET_CODE(func), PyFunction_GET_GLOBALS(func), ns,
NULL, 0, NULL, 0, NULL, 0, NULL,
PyFunction_GET_CLOSURE(func));
if (cell != NULL) {
if (bases != orig_bases) {
if (PyMapping_SetItemString(ns, "__orig_bases__", orig_bases) < 0) {
goto error;
}
}
PyObject *margs[3] = {name, bases, ns};
cls = _PyObject_FastCallDict(meta, margs, 3, mkw);
...
...
}
我们前面说,python虚拟机获得了关于class的属性表(动态元信息),比如所有的方法、属性,所以我们可以说,class的动态元信息包含了class的所有属性。但是对于这个class对象的类型是什么,应该如何创建、要分配多少内存,却没有任何的信息。而在builtin___build_class__中,metaclass正是关于class对象的另一部分元信息,我们称之为静态元信息。在静态元信息中,隐藏着所有的类对象应该如何创建的信息,注意:是所有的类对象。
从源码中我们可以看到,如果用户指定了metaclass,那么会选择指定的metaclass,如果没有指定,那么会使用第一个继承的基类的__class__作为该class的metaclass。
对于PyLongObject、PyDictObject这些python中的实例对象,所有的元信息存储在对应的类对象中(PyLong_Type,PyDict_Type)。但是对于类对象来说,其元信息的静态元信息存储在对应的元类(PyType_Type)中,动态元信息则存储在本身的local命名空间中。但是为什么这么做呢?为什么对于类对象来说,其元信息要游离成两部分呢?都存在metaclass里面不香吗?这是因为,用户在.py文件中可以定义不同的class,这个元信息必须、且只能是动态的,所以它是不适合保存在metaclass中的,而类对象的创建策略等这些所有class都会共用的元信息,则存储在metaclass里面。
像Python的内建对象都是python静态提供的,它们都具备相同的接口集合,支持什么操作一开始就定义好了。只不过有的可以用,有的不能用。比如PyLongObject可以使用nb_add,但是PyDictObject不能。而PyDictObject可以使用mp_subscript,但是PyLongObject不可以。尽管如此,但这不影响它们的所有元信息都可以完全存储在类型对象中。但是用户自定义的class对象,接口是动态的,不可能再metaclass中静态指定
既然创建了元类,那么下面显然就开始调用了。通过函数_PyObject_FastCallDict调用
//Objects/call.c
PyObject *
_PyObject_FastCallDict(PyObject *callable, PyObject *const *args, Py_ssize_t nargs,
PyObject *kwargs)
{
...
...
else {
PyObject *argstuple, *result;
ternaryfunc call;
/* Slow-path: build a temporary tuple */
//调用了tp_call,指向type_call
call = callable->ob_type->tp_call;
result = (*call)(callable, argstuple, kwargs);
...
...
return result;
}
}
//Objects/typeobject.c
static PyObject *
type_call(PyTypeObject *type, PyObject *args, PyObject *kwds)
{
PyObject *obj;
...
//调用tp_new进行初始化
obj = type->tp_new(type, args, kwds);
...
type = Py_TYPE(obj);
if (type->tp_init != NULL) {
//如果定义了__init__函数,那么会调用__init__函数进行初始化
int res = type->tp_init(obj, args, kwds);
if (res < 0) {
assert(PyErr_Occurred());
Py_DECREF(obj);
obj = NULL;
}
else {
assert(!PyErr_Occurred());
}
}
return obj;
}
tp_new指向type_new,这个type_new是我们创建class对象的第一案发现场。我们看一下type_new的源码,位于Objects/typeobject.c中,这个函数的代码比较长,我们会有删减,像那些检测的代码我们就省略掉了。
static PyObject *
type_new(PyTypeObject *metatype, PyObject *args, PyObject *kwds)
{
//都是类的那些动态元信息
PyObject *name, *bases = NULL, *orig_dict, *dict = NULL;
PyObject *qualname, *slots = NULL, *tmp, *newslots, *cell;
PyTypeObject *type = NULL, *base, *tmptype, *winner;
PyHeapTypeObject *et;
PyMemberDef *mp;
Py_ssize_t i, nbases, nslots, slotoffset, name_size;
int j, may_add_dict, may_add_weak, add_dict, add_weak;
//如果metaclass是type的话
if (metatype == &PyType_Type) {
//获取位置参数和关键字参数个数
const Py_ssize_t nargs = PyTuple_GET_SIZE(args);
const Py_ssize_t nkwds = kwds == NULL ? 0 : PyDict_GET_SIZE(kwds);
//位置参数为1,关键字参数为0,你想到了什么
//type(xxx),是不是这个呀,
if (nargs == 1 && nkwds == 0) {
PyObject *x = PyTuple_GET_ITEM(args, 0);
Py_INCREF(Py_TYPE(x));
//这显然是初学python的时候,就知道的,查看一个变量的类型。
//直接返回
return (PyObject *) Py_TYPE(x);
}
//如果上面的if不满足,会走这里,表示现在不再是查看类型了,而是创建类
//而这里要求位置参数必须是3个,否则报错。
//我们知道type查看类型,输出一个参数即可,但是创建类需要3个
if (nargs != 3) {
//不过这里是nargs,似乎跟nkwds没有关系啊,我们用python来测试一下
//type(name="xx", bases=(object, ), dict={}) #TypeError: type() takes 1 or 3 arguments
//type("xx", (object, ), {}),此时正常执行。
//说明关键字参数不管用,只能通过位置参数来传递,从源码中我们能看到端倪
PyErr_SetString(PyExc_TypeError,
"type() takes 1 or 3 arguments");
return NULL;
}
}
//现在显然是确定参数类型,对于type来说,你传递了三个参数,但是这三个参数是有类型要求的
//必须是PyUnicodeObject、PyTupleObject、PyDictObject
/*
type(123, (object, ), {}) # TypeError: type.__new__() argument 1 must be str, not int
type("xx", [object], {}) # TypeError: type.__new__() argument 2 must be tuple, not list
type("xx", (object, ), []) # TypeError: type.__new__() argument 3 must be dict, not list
*/
if (!PyArg_ParseTuple(args, "UO!O!:type.__new__", &name, &PyTuple_Type,
&bases, &PyDict_Type, &orig_dict))
return NULL;
/* Adjust for empty tuple bases */
//处理元组为空的情况,另外我们使用class关键字定义类,本质上会转为type定义类的方式
/*
class A:
pass
这种形式本质上就是type("A", (), {})
*/
nbases = PyTuple_GET_SIZE(bases);
//但是我们发现这里没有继承基类,因此在python3中要处理这种情况,默认继承object
if (nbases == 0) {
//拿到PyBaseObject_Type,也就是python中的object
base = &PyBaseObject_Type;
//生成一个只有base的元组
bases = PyTuple_Pack(1, base);
if (bases == NULL)
return NULL;
//nbases显然是1
nbases = 1;
}
else {
_Py_IDENTIFIER(__mro_entries__);
//循环遍历bases的所有元素
for (i = 0; i < nbases; i++) {
//依次遍历bases中的每一个元素
tmp = PyTuple_GET_ITEM(bases, i);
//如果是PyType_Type类型,进行下一次循环
if (PyType_Check(tmp)) {
continue;
}
if (_PyObject_LookupAttrId(tmp, &PyId___mro_entries__, &tmp) < 0) {
return NULL;
}
if (tmp != NULL) {
PyErr_SetString(PyExc_TypeError,
"type() doesn't support MRO entry resolution; "
"use types.new_class()");
Py_DECREF(tmp);
return NULL;
}
}
/* Search the bases for the proper metatype to deal with this: */
//寻找父类的metaclass
winner = _PyType_CalculateMetaclass(metatype, bases);
if (winner == NULL) {
return NULL;
}
//如果winner表示PyType_Type
if (winner != metatype) {
if (winner->tp_new != type_new) /* Pass it to the winner */
return winner->tp_new(winner, args, kwds);
metatype = winner;
}
/* Calculate best base, and check that all bases are type objects */
//确定最佳base,存储在PyTypeObject *base中
base = best_base(bases);
if (base == NULL) {
return NULL;
}
Py_INCREF(bases);
}
/* Check for a __slots__ sequence variable in dict, and count it */
//处理用户定义了__slots__属性的逻辑
slots = _PyDict_GetItemId(dict, &PyId___slots__);
nslots = 0;
add_dict = 0;
add_weak = 0;
may_add_dict = base->tp_dictoffset == 0;
may_add_weak = base->tp_weaklistoffset == 0 && base->tp_itemsize == 0;
if (slots == NULL) {
...
...
...
/* Allocate the type object */
//为class对象申请内存
type = (PyTypeObject *)metatype->tp_alloc(metatype, nslots);
if (type == NULL)
goto error;
/* Keep name and slots alive in the extended type object */
et = (PyHeapTypeObject *)type;
Py_INCREF(name);
et->ht_name = name;
et->ht_slots = slots;
slots = NULL;
/* 初始化tp_flags */
type->tp_flags = Py_TPFLAGS_DEFAULT | Py_TPFLAGS_HEAPTYPE |
Py_TPFLAGS_BASETYPE | Py_TPFLAGS_HAVE_FINALIZE;
if (base->tp_flags & Py_TPFLAGS_HAVE_GC)
type->tp_flags |= Py_TPFLAGS_HAVE_GC;
//设置PyTypeObject中的各个域
type->tp_as_async = &et->as_async;
type->tp_as_number = &et->as_number;
type->tp_as_sequence = &et->as_sequence;
type->tp_as_mapping = &et->as_mapping;
type->tp_as_buffer = &et->as_buffer;
type->tp_name = PyUnicode_AsUTF8AndSize(name, &name_size);
if (!type->tp_name)
goto error;
if (strlen(type->tp_name) != (size_t)name_size) {
PyErr_SetString(PyExc_ValueError,
"type name must not contain null characters");
goto error;
}
/* 设置基类和基类列表 */
type->tp_bases = bases;
bases = NULL;
Py_INCREF(base);
type->tp_base = base;
/* 设置属性表 */
Py_INCREF(dict);
type->tp_dict = dict;
/* Set __module__ in the dict */
//设置__module__
if (_PyDict_GetItemId(dict, &PyId___module__) == NULL) {
tmp = PyEval_GetGlobals();
if (tmp != NULL) {
tmp = _PyDict_GetItemId(tmp, &PyId___name__);
if (tmp != NULL) {
if (_PyDict_SetItemId(dict, &PyId___module__,
tmp) < 0)
goto error;
}
}
}
/* Set ht_qualname to dict['__qualname__'] if available, else to
__name__. The __qualname__ accessor will look for ht_qualname.
*/
//设置__qualname__,并且注释也写了,这和__name__是一样的
qualname = _PyDict_GetItemId(dict, &PyId___qualname__);
if (qualname != NULL) {
if (!PyUnicode_Check(qualname)) {
PyErr_Format(PyExc_TypeError,
"type __qualname__ must be a str, not %s",
Py_TYPE(qualname)->tp_name);
goto error;
}
}
et->ht_qualname = qualname ? qualname : et->ht_name;
Py_INCREF(et->ht_qualname);
if (qualname != NULL && _PyDict_DelItemId(dict, &PyId___qualname__) < 0)
goto error;
/* Set tp_doc to a copy of dict['__doc__'], if the latter is there
and is a string. The __doc__ accessor will first look for tp_doc;
if that fails, it will still look into __dict__.
*/
{
PyObject *doc = _PyDict_GetItemId(dict, &PyId___doc__);
if (doc != NULL && PyUnicode_Check(doc)) {
Py_ssize_t len;
const char *doc_str;
char *tp_doc;
doc_str = PyUnicode_AsUTF8(doc);
if (doc_str == NULL)
goto error;
/* Silently truncate the docstring if it contains null bytes. */
len = strlen(doc_str);
tp_doc = (char *)PyObject_MALLOC(len + 1);
if (tp_doc == NULL) {
PyErr_NoMemory();
goto error;
}
memcpy(tp_doc, doc_str, len + 1);
type->tp_doc = tp_doc;
}
}
/* Special-case __new__: if it's a plain function,
make it a static function */
//如果自定义的class中重写了__new__方法,将__new__对应的函数改造为static函数
tmp = _PyDict_GetItemId(dict, &PyId___new__);
if (tmp != NULL && PyFunction_Check(tmp)) {
tmp = PyStaticMethod_New(tmp);
if (tmp == NULL)
goto error;
if (_PyDict_SetItemId(dict, &PyId___new__, tmp) < 0) {
Py_DECREF(tmp);
goto error;
}
Py_DECREF(tmp);
}
/* Special-case __init_subclass__ and __class_getitem__:
if they are plain functions, make them classmethods */
//设置__init_subclass__,如果子类继承了父类,那么会触发父类的__init_subclass__方法
//用法可以参考我的这篇博客:https://www.cnblogs.com/traditional/p/11715511.html
tmp = _PyDict_GetItemId(dict, &PyId___init_subclass__);
if (tmp != NULL && PyFunction_Check(tmp)) {
tmp = PyClassMethod_New(tmp);
if (tmp == NULL)
goto error;
if (_PyDict_SetItemId(dict, &PyId___init_subclass__, tmp) < 0) {
Py_DECREF(tmp);
goto error;
}
Py_DECREF(tmp);
}
//设置__class_getitem__,这个是什么?类似于__getitem__
//__class_getitem__支持通过类["xxx"]的方式访问
tmp = _PyDict_GetItemId(dict, &PyId___class_getitem__);
if (tmp != NULL && PyFunction_Check(tmp)) {
tmp = PyClassMethod_New(tmp);
if (tmp == NULL)
goto error;
if (_PyDict_SetItemId(dict, &PyId___class_getitem__, tmp) < 0) {
Py_DECREF(tmp);
goto error;
}
Py_DECREF(tmp);
}
/* Add descriptors for custom slots from __slots__, or for __dict__ */
...
...
//为class对象对应的instance对象设置内存大小信息
type->tp_basicsize = slotoffset;
type->tp_itemsize = base->tp_itemsize;
type->tp_members = PyHeapType_GET_MEMBERS(et);
/* Initialize the rest */
//调用PyType_Ready对class对象进行初始化
if (PyType_Ready(type) < 0)
goto error;
/* Put the proper slots in place */
fixup_slot_dispatchers(type);
if (type->tp_dictoffset) {
et->ht_cached_keys = _PyDict_NewKeysForClass();
}
if (set_names(type) < 0)
goto error;
if (init_subclass(type, kwds) < 0)
goto error;
Py_DECREF(dict);
return (PyObject *)type;
error:
Py_XDECREF(dict);
Py_XDECREF(bases);
Py_XDECREF(slots);
Py_XDECREF(type);
return NULL;
}
python虚拟机首先会将类名、基类列表和属性表从tuple对象中解析出来,然后会基于基类列表及传入的metaclass(参数metatype)确定最佳的metaclass和base,对于我们的A来说,最佳metaclass是type,最佳的base是object
随后,python虚拟机会调用metatype->tp_alloc尝试为要创建的类对象A分配内存。这里需要注意的是,在PyType_Type中,我们发现tp_alloc是一个NULL,这显然不正常。但是不要忘记,我们之前提到,在python进行初始化时,会对所有的内建对象通过PyType_Ready进行初始化,在这个初始化过程中,有一项动作就是从基类继承各种操作。由于type.__bases__中的第一基类object,所以type会继承object中的tp_alloc操作,即PyType_GenericAlloc。对于我们的A(或者对于任何继承自object的class对象)来说,PyType_GenericAlloc将申请metatype->tp_basicsize + metatype->tp_itemsize大小的内存空间。从PyType_Type的定义中我们看到,这个大小实际就是sizeof(PyHeapTypeObject) + sizeof(PyMemerDef)。因此在这里应该就明白了PyHeapTypeObject这个老铁到底是干嘛用的了,之前因为偏移量的问题,折腾了不少功夫,甚至让人觉得这有啥用啊,但是现在意识到了,这个老铁是为用户自定义class准备的。
此时,就是设置<class A>这个class对象的各个域,其中包括了在tp_dict上设置属性表,也就是__dict__。另外注意的是,这里还计算了类对象A对应的实例对象所需要的内存大小信息,换言之,我们通过a = A()这样的表达式创建一个instance对象时,需要为这个实例对象申请多大的内存空间呢?对于A(对任何继承object的class对象也成立)来说,这个大小为PyBaseObject_Type->tp_basicsize + 16。其中的16是2 * sizeof(PyObject *)。为什么后面要跟着两个PyObject *的空间,而且这些空间的地址被设置给了tp_dictoffset和tp_weaklistoffset了呢?这些留到以后解析。
最后,python虚拟机还会调用PyType_Ready对class A进行和内建对象一样的初始化动作,到此A对应的class对象才算正式创建完毕。那么内建对象和class对象在内存布局上面有什么区别呢?毕竟都是类对象。

本质上,无论用户自定义的class对象还是内建对象,在python虚拟机内部,都可以用一个PyTypeObject来表示。但不同的是,内建对象的PyTypeObject以及与其关联的PyNumberMethods等属性的内存位置都是在编译时确定的,它们在内存中的位置是分离的。而用户自定义的class对象的PyTypeObject和PyNumberMethods等内存位置是连续的,必须在运行时动态分配内存。
现在我们算是对python中可调用(callable)这个概念有一个感性任性了,在python中可调用这个概念是一个相当通用的概念,不拘泥于对象、大小,只要对象定义了tp_call操作,就能进行调用操作。我们已经看到,python中的对象class对象是调用metaclass创建。那么显然,调用class对象就能得到实例对象。
13.4 从class对象到instance对象
上一章剖析函数机制的时候,真的是写了我好长一段时间,当初剖析函数机制的时候,我就在想,函数都这么多,那类不得搞死我啊。事实上也确实如此,我现在也快写烦了,这个类什么时候才能到头啊,但即便如此也不要放弃,会柳暗花明的,也请你们坚持读下去。
我们费了老鼻子劲创建了class对象,但仅仅是万里长征的第一步。因为python虚拟机执行时,在内存中兴风作浪的是一个个的实例对象,而class只是幕后英雄。
class A:
name = "Python"
def __init__(self):
print("A->__init__")
def f(self):
print("A->self")
def g(self, value):
self.value = value
print(self.value)
a = A()
a.f()
a.g(10)
我们只看模块的字节码,因为其它的已经看过了,就不贴了
1 0 LOAD_BUILD_CLASS
2 LOAD_CONST 0 (<code object A at 0x000001995CDA7C90, file "a.py", line 1>)
4 LOAD_CONST 1 ('A')
6 MAKE_FUNCTION 0
8 LOAD_CONST 1 ('A')
10 LOAD_NAME 0 (object)
12 CALL_FUNCTION 3
14 STORE_NAME 1 (A)
16 16 LOAD_NAME 1 (A)
18 CALL_FUNCTION 0
20 STORE_NAME 2 (a)
17 22 LOAD_NAME 2 (a)
24 LOAD_METHOD 3 (f)
26 CALL_METHOD 0
28 POP_TOP
18 30 LOAD_NAME 2 (a)
32 LOAD_METHOD 4 (g)
34 LOAD_CONST 2 (10)
36 CALL_METHOD 1
38 POP_TOP
40 LOAD_CONST 3 (None)
42 RETURN_VALUE
我们看到在将A build成类之后,通过14 STORE_NAME 1 (A)将刚刚创建的class对象存放到了globals(locals)命名空间中,并且符号也是A。然后16 LOAD_NAME 1 (A)重新将class对象取出压入到运行时栈中,显然从字节码指令18 CALL_FUNCTION 0可以看出,是通过取出来的class对象来创建instance对象、也就是该类对象的实例对象,但是我们发现这个指令居然是CALL_FUNCTION,难道不是类吗?其实最一开始看字节码的时候我们就说了,即便是类和函数一样,都是要先将PyCodeObject变成PyFunctionObject,然后对于类来说,再将PyFunctionObject对象通过LOAD_BUILD_CLASS指令build成一个类,因此在调用的时候,类和函数一样,也是CALL_FUNCTION就很好理解了。python虚拟机在创建instance对象的时候,会通过指令20 STORE_NAME 2 (a)将(a, instance)组成一个entry存放在globals命名空间中,另外插一嘴,由于模块级别的globals和locals命名空间是一个东西,但是对于函数来说globals和locals则不是一个东西,因此为了避免混淆,对于模块来说,我只用globals命名空间,不用locals,尽管这两者是一样的,当用locals的时候,都会指函数或者类的locals。所以当这行代码执行完毕之后,globals命名空间就会变成这样

在CALL_FUNCTION中,python同样会执行对应类型的tp_call操作。所以创建实例的时候,显然执行PyType_Type的tp_call,因此最终是在PyType_Type.tp_call中调用A.tp_new来创建instance对象的。
需要注意的是,在创建class A这个对象时,python虚拟机调用PyType_Ready对class A进行了初始化,其中一项动作就是集成基类,所以A.tp_new实际上就是object.tp_new,而在PyBaseObject_Type中,这个操作被定义为object_new。创建class对象和创建instance对象的不同之处正是在于tp_new不同。创建class对象,python虚拟机使用的是tp_new,创建instance,python虚拟机则使用object_new。使用类重写__new__的话,应该很容易明白。
因此,由于我们创建的不是class对象,而是instance对象,type_call会尝试进行初始化的动作
static PyObject *
type_call(PyTypeObject *type, PyObject *args, PyObject *kwds)
{
PyObject *obj;
...
...
obj = type->tp_new(type, args, kwds);
obj = _Py_CheckFunctionResult((PyObject*)type, obj, NULL);
if (obj == NULL)
return NULL;
/* Ugly exception: when the call was type(something),
don't call tp_init on the result. */
if (type == &PyType_Type &&
PyTuple_Check(args) && PyTuple_GET_SIZE(args) == 1 &&
(kwds == NULL ||
(PyDict_Check(kwds) && PyDict_GET_SIZE(kwds) == 0)))
return obj;
/* If the returned object is not an instance of type,
it won't be initialized. */
if (!PyType_IsSubtype(Py_TYPE(obj), type))
return obj;
type = Py_TYPE(obj);
if (type->tp_init != NULL) {
int res = type->tp_init(obj, args, kwds);
if (res < 0) {
assert(PyErr_Occurred());
Py_DECREF(obj);
obj = NULL;
}
else {
assert(!PyErr_Occurred());
}
}
return obj;
}
对于基于class A创建的instance对象obj,其ob_type当然也在PyType_GenericAlloc中被设置为指向class A,其tp_init在PyType_Ready时会继承PyBaseObject_Type的object_init操作。但正如我们之前说的那样,因为A中的定义重写了__init__,所以在fixup_slot_dispatchers中,tp_init会指向slotdef中指定的与__init__对应的slot_tp_init:
static int
slot_tp_init(PyObject *self, PyObject *args, PyObject *kwds)
{
_Py_IDENTIFIER(__init__);
int unbound;
//虚拟机会通过lookup_method从class对象及其mro列表中搜索属性__init__对应的操作
PyObject *meth = lookup_method(self, &PyId___init__, &unbound);
//返回结果
PyObject *res;
if (meth == NULL)
return -1;
if (unbound) {
res = _PyObject_Call_Prepend(meth, self, args, kwds);
}
else {
res = PyObject_Call(meth, args, kwds);
}
Py_DECREF(meth);
if (res == NULL)
return -1;
//如果返回的不是None,那么报错,这个信息熟悉不
if (res != Py_None) {
PyErr_Format(PyExc_TypeError,
"__init__() should return None, not '%.200s'",
Py_TYPE(res)->tp_name);
Py_DECREF(res);
return -1;
}
Py_DECREF(res);
return 0;
}
所以如果你在定义class时,重写了__init__操作,那么搜索的结果就是你写的操作,如果没有重写那么执行object的__init__操作,而在object的__init__中,python虚拟机则什么也不做,而是直接返回。所以我们通过a = A()的方式来创建一个instance对象,实际上是没有进行任何初始化的动作,因为我根本就没有头发,(⊙o⊙)…,因为A里面根本没有__init__函数。
到了这里可以小结一下,从class对象创建instance对象的两个步骤:
instance = class.__new__(class, *args, **kwargs)
class.__init__(instance, *args, **kwargs)
需要注意的是,这两个步骤同样也适用于从metaclass对象创建class对象,因为从metaclass对象创建class对象的过程其实和从class对象创建instance对象是一样的,我们说class具有二象性。
13.5 访问instance对象中的属性
在前面的章节中我们讨论命名空间时就提到,在python中,形如x.y形式的表达式称之为"属性引用",其中x为对象,y为对象的某个属性,这个属性可以是很多种,比如:整数、字符串、函数、类、甚至是模块等等。在之前的a.py中,估计有人忘了,我们一共调用了两个class A的成员函数,一个是不需要参数、一个是需要参数,当然有人会问不是还有__init__吗?那个是在创建实例对象的时候自动调用的,我们就忽略了。
这是调用两个成员函数的字节码
17 22 LOAD_NAME 2 (a)
24 LOAD_METHOD 3 (f)
26 CALL_METHOD 0
28 POP_TOP
18 30 LOAD_NAME 2 (a)
32 LOAD_METHOD 4 (g)
34 LOAD_CONST 2 (10)
36 CALL_METHOD 1
38 POP_TOP
40 LOAD_CONST 3 (None)
42 RETURN_VALUE
我们先来看看不需要参数的成员函数的调用过程是怎么样的。
我们看到虚拟机首先通过LOAD_NAME将a对应的instance对象load进来、压入运行时栈。接下来我们看到了一个LOAD_METHOD,是属性、更精确的说应该是方法访问机制的关键所在,它会从instance中获取与符号f对应的对象,这个f是一个函数,所以这是一个PyFunctionObject对象。
//ceval.c
TARGET(LOAD_METHOD) {
/* Designed to work in tamdem with CALL_METHOD. */
//这个name为PyUnicodeObject对象"f"
PyObject *name = GETITEM(names, oparg);
//而obj显然是运行时栈中的那个instance对象
PyObject *obj = TOP();
//meth是一个PyObject *指针,显然它要指向一个函数
PyObject *meth = NULL;
//这里是获取方法,因此要获取obj中符号的为name的函数,让后让meth指向它
//所以meth是一个指针, 这里又传入一个二级指针,然后让meth存储的地址变成指向对应方法(函数)的地址
int meth_found = _PyObject_GetMethod(obj, name, &meth);
//如果是NULL,说明没有设置成功,在obj中找不到名为name的函数
if (meth == NULL) {
/* Most likely attribute wasn't found. */
goto error;
}
//另外还返回了一个meth_found
if (meth_found) {
/* We can bypass temporary bound method object.
meth is unbound method and obj is self.
meth | self | arg1 | ... | argN
*/
//如果meth_found为1,说明meth是一个未绑定的方法,obj就是self
//关于绑定和未绑定我们后面会详细介绍
//那么结果会变成这样,相当于f(A, arg1, arg2...)
SET_TOP(meth);
PUSH(obj); // self
}
else {
/* meth is not an unbound method (but a regular attr, or
something was returned by a descriptor protocol). Set
the second element of the stack to NULL, to signal
CALL_METHOD that it's not a method call.
NULL | meth | arg1 | ... | argN
*/
//否则meth不是一个未绑定的方法,而是一个描述符协议返回的一个普通属性、亦或是其他的什么东西
//那么栈的第二个元素就会设置为NULL
//因此结果就会变成这样:f(None, arg1, arg2...)
//其实造成这种局面无非是你传错实例,比如a = A()
//那么a.f()就相当于A.f(a),但是你传递的不是a,而是其他的什么东西
SET_TOP(NULL);
Py_DECREF(obj);
PUSH(meth);
}
DISPATCH();
}
其实肯定有人想到了,获取方法是LOAD_METHOD,那么获取属性呢?对,获取属性是LOAD_ATTR
//ceval.c
TARGET(LOAD_ATTR) {
//可以看到这个和LOAD_METHOD本质上是类似的,并且还要更简单一些
//name依旧是符号
PyObject *name = GETITEM(names, oparg);
//owner是所有者,为什么不叫obj,因为方法都是给实例用的,尽管类也能调用,但是方法毕竟是给实例用的
//但是属性的话,类和实例都可以访问,各自互不干扰,所以是owner
PyObject *owner = TOP();
//res显然就是获取属性返回的结果了
PyObject *res = PyObject_GetAttr(owner, name);
Py_DECREF(owner);
//设置到栈顶
SET_TOP(res);
if (res == NULL)
goto error;
DISPATCH();
}
LOAD_ATTR和LOAD_METHOD这两个指令集我们都看到了,但是里面具体实现的方法还没有看,LOAD_ATTR调用了PyObject_GetAttr函数,LOAD_METHOD调用了_PyObject_GetMethod,我们来看看这两个方法都长什么样子。首先就从PyObject_GetAttr开始
//object.c
PyObject *
PyObject_GetAttr(PyObject *v, PyObject *name)
{
//*v:instance
//*name:方法名
PyTypeObject *tp = Py_TYPE(v);
//如果传递的name不是一个PyUnicodeObject,直接报错
if (!PyUnicode_Check(name)) {
PyErr_Format(PyExc_TypeError,
"attribute name must be string, not '%.200s'",
name->ob_type->tp_name);
return NULL;
}
//通过tp_getattro获取属性对应的对象
if (tp->tp_getattro != NULL)
return (*tp->tp_getattro)(v, name);
//通过tp_getattr获取属性对应的对象
if (tp->tp_getattr != NULL) {
const char *name_str = PyUnicode_AsUTF8(name);
if (name_str == NULL)
return NULL;
return (*tp->tp_getattr)(v, (char *)name_str);
}
//属性不存在,抛出异常
PyErr_Format(PyExc_AttributeError,
"'%.50s' object has no attribute '%U'",
tp->tp_name, name);
return NULL;
}
在python的class对象中,定义了两个与属性访问相关的操作:tp_getattro和tp_getattr。其中tp_getattro是首先的属性访问动作,而tp_getattr在python中已不推荐使用。而这两者的区别在PyObject_GetAttr中已经显示的很清楚了,主要是在属性名的使用上,tp_getattro所使用的属性名必须是一个PyUnicodeObject对象,而tp_getattr所使用的属性名是一个char *。因此如果某个类型定义了tp_getattro和tp_getattr,那么PyObject_GetAttr优先使用tp_getattro,因为这位老铁写在上面。
在python虚拟机创建class A时,会从PyBaseObject_Type中继承其tp_getattro->PyObject_GenericGetAttr,所以python虚拟机会在这里进入PyObject_GenericGetAttr。不过由于涉及到了python中的描述符,所以看不懂没关系,我们后面会详细介绍描述符。
//object.c
PyObject *
PyObject_GenericGetAttr(PyObject *obj, PyObject *name)
{
return _PyObject_GenericGetAttrWithDict(obj, name, NULL, 0);
}
PyObject *
_PyObject_GenericGetAttrWithDict(PyObject *obj, PyObject *name,
PyObject *dict, int suppress)
{
/* Make sure the logic of _PyObject_GetMethod is in sync with
this method.
When suppress=1, this function suppress AttributeError.
*/
//拿到obj的类型,对于我们的例子来说, 显然是class A
PyTypeObject *tp = Py_TYPE(obj);
PyObject *descr = NULL;
PyObject *res = NULL;
descrgetfunc f;
Py_ssize_t dictoffset;
PyObject **dictptr;
//name必须是str
if (!PyUnicode_Check(name)){
PyErr_Format(PyExc_TypeError,
"attribute name must be string, not '%.200s'",
name->ob_type->tp_name);
return NULL;
}
Py_INCREF(name);
if (tp->tp_dict == NULL) {
if (PyType_Ready(tp) < 0)
goto done;
}
//尝试从mro列表中拿到f,等价于descr = A.f if hasattr(A, 'f') else NULL
descr = _PyType_Lookup(tp, name);
f = NULL;
if (descr != NULL) {
Py_INCREF(descr);
//f = descr.__class__.__get__
f = descr->ob_type->tp_descr_get;
if (f != NULL && PyDescr_IsData(descr)) {
//f不为NULL,并且是数据描述符,那么直接将描述符中__get__方法的结果返回
//这个f就是描述里面的__get__方法,而这个descr就是描述符的一个实例对象
//obj就是实例对象,(PyObject *)obj->ob_type是obj的类型
res = f(descr, obj, (PyObject *)obj->ob_type);
if (res == NULL && suppress &&
PyErr_ExceptionMatches(PyExc_AttributeError)) {
PyErr_Clear();
}
goto done;
}
}
//那么显然要从instance对象自身的__dict__中寻找属性
if (dict == NULL) {
/* Inline _PyObject_GetDictPtr */
dictoffset = tp->tp_dictoffset;
if (dictoffset != 0) {
//但如果dict为NULL,并且dictoffset说明继承自变长对象,那么要调整tp_dictoffset
if (dictoffset < 0) {
Py_ssize_t tsize;
size_t size;
tsize = ((PyVarObject *)obj)->ob_size;
if (tsize < 0)
tsize = -tsize;
size = _PyObject_VAR_SIZE(tp, tsize);
assert(size <= PY_SSIZE_T_MAX);
dictoffset += (Py_ssize_t)size;
assert(dictoffset > 0);
assert(dictoffset % SIZEOF_VOID_P == 0);
}
dictptr = (PyObject **) ((char *)obj + dictoffset);
dict = *dictptr;
}
}
//dict不为NULL,从字典中获取
if (dict != NULL) {
Py_INCREF(dict);
res = PyDict_GetItem(dict, name);
if (res != NULL) {
Py_INCREF(res);
Py_DECREF(dict);
goto done;
}
Py_DECREF(dict);
}
//我们看到这里又判断了一次,但是这次少了个条件
//没错熟悉python描述符的应该知道,上面的需要满足是数据描述符
//这个是非数据描述符
if (f != NULL) {
res = f(descr, obj, (PyObject *)Py_TYPE(obj));
if (res == NULL && suppress &&
PyErr_ExceptionMatches(PyExc_AttributeError)) {
PyErr_Clear();
}
goto done;
}
//返回
if (descr != NULL) {
res = descr;
descr = NULL;
goto done;
}
//找不到,就报错
if (!suppress) {
PyErr_Format(PyExc_AttributeError,
"'%.50s' object has no attribute '%U'",
tp->tp_name, name);
}
done:
Py_XDECREF(descr);
Py_DECREF(name);
return res;
}
属性访问是从PyObject_GetAttr开始,那么下面我们来看看_PyObject_GetMethod
int
_PyObject_GetMethod(PyObject *obj, PyObject *name, PyObject **method)
{
PyTypeObject *tp = Py_TYPE(obj);
PyObject *descr;
descrgetfunc f = NULL;
PyObject **dictptr, *dict;
PyObject *attr;
int meth_found = 0;
assert(*method == NULL);
if (Py_TYPE(obj)->tp_getattro != PyObject_GenericGetAttr
|| !PyUnicode_Check(name)) {
*method = PyObject_GetAttr(obj, name);
return 0;
}
if (tp->tp_dict == NULL && PyType_Ready(tp) < 0)
return 0;
descr = _PyType_Lookup(tp, name);
if (descr != NULL) {
Py_INCREF(descr);
if (PyFunction_Check(descr) ||
(Py_TYPE(descr) == &PyMethodDescr_Type)) {
meth_found = 1;
} else {
f = descr->ob_type->tp_descr_get;
if (f != NULL && PyDescr_IsData(descr)) {
*method = f(descr, obj, (PyObject *)obj->ob_type);
Py_DECREF(descr);
return 0;
}
}
}
dictptr = _PyObject_GetDictPtr(obj);
if (dictptr != NULL && (dict = *dictptr) != NULL) {
Py_INCREF(dict);
attr = PyDict_GetItem(dict, name);
if (attr != NULL) {
Py_INCREF(attr);
*method = attr;
Py_DECREF(dict);
Py_XDECREF(descr);
return 0;
}
Py_DECREF(dict);
}
if (meth_found) {
*method = descr;
return 1;
}
if (f != NULL) {
*method = f(descr, obj, (PyObject *)Py_TYPE(obj));
Py_DECREF(descr);
return 0;
}
if (descr != NULL) {
*method = descr;
return 0;
}
PyErr_Format(PyExc_AttributeError,
"'%.50s' object has no attribute '%U'",
tp->tp_name, name);
return 0;
}
但是我们发现_PyObject_GetMethod和PyObject_GetAttr基本是一致的,毕竟方法也可以看成是一种属性嘛,这里就不介绍了。
13.5.1 instance对象中的_dict_
在属性访问的时候,我们可以通过a.__dict__这种形式访问。但是这就奇怪了,在之前的描述中,我们看到从class A创建instance a的时候,python并没有为instance创建PyDictObject对象。
但是在12.3.2 metaclass的时候,我们说过这样一句话,对于A(对任何继承object的class对象也成立)来说,这个大小为PyBaseObject_Type->tp_basicsize + 16。其中的16是2 * sizeof(PyObject *)。为什么后面要跟着两个PyObject *的空间,而且这些空间的地址被设置给了tp_dictoffset和tp_weaklistoffset了呢?这些留到以后解析。。我们说多出来的两个PyObject *留给了tp_dictoffset和tp_weaklistoffset,难道谜底出现在这里吗?现在是时候揭开谜底了
在创建class A时,我们曾说,python虚拟机设置了一个名为tp_dictoffset的域,从名字推断,这个可能就是instance对象中__dict__的偏移位置

虚线中画出的dict对象就是我们期望中的a.__dict__,这个猜想可以在PyObject_GenericGetAttr中得到证实
//object.c
PyObject *
PyObject_GenericGetAttr(PyObject *obj, PyObject *name)
{
return _PyObject_GenericGetAttrWithDict(obj, name, NULL, 0);
}
PyObject *
_PyObject_GenericGetAttrWithDict(PyObject *obj, PyObject *name,
PyObject *dict, int suppress)
{
//那么显然要从instance对象自身的__dict__中寻找属性
if (dict == NULL) {
/* Inline _PyObject_GetDictPtr */
dictoffset = tp->tp_dictoffset;
if (dictoffset != 0) {
//但如果dict为NULL,并且dictoffset说明继承自变长对象,那么要调整tp_dictoffset
if (dictoffset < 0) {
Py_ssize_t tsize;
size_t size;
tsize = ((PyVarObject *)obj)->ob_size;
if (tsize < 0)
tsize = -tsize;
size = _PyObject_VAR_SIZE(tp, tsize);
assert(size <= PY_SSIZE_T_MAX);
dictoffset += (Py_ssize_t)size;
assert(dictoffset > 0);
assert(dictoffset % SIZEOF_VOID_P == 0);
}
dictptr = (PyObject **) ((char *)obj + dictoffset);
dict = *dictptr;
}
}
如果dictoffset小于0,意味着A是继承自类似str这样的变长对象,python虚拟机会对dictoffset做一些处理,最终仍然会使dictoffset指向a的内存中额外申请的位置。而PyObject_GenericGetAttr正是根据这个dictoffset获得了一个dict对象。更近一步,我们发现函数g中有设置self.value的代码,这个instance对象的属性设置也会访问a.__dict__,而这个设置的动作最终会调用PyObject_GenericSetAttr,也就是a.__dict__最初被创建的地方。
//object.c
int
PyObject_GenericSetAttr(PyObject *obj, PyObject *name, PyObject *value)
{
return _PyObject_GenericSetAttrWithDict(obj, name, value, NULL);
}
int
_PyObject_GenericSetAttrWithDict(PyObject *obj, PyObject *name,
PyObject *value, PyObject *dict)
{
PyTypeObject *tp = Py_TYPE(obj);
PyObject *descr;
descrsetfunc f;
PyObject **dictptr;
int res = -1;
//老规矩,name必须是PyUnicodeObject
if (!PyUnicode_Check(name)){
PyErr_Format(PyExc_TypeError,
"attribute name must be string, not '%.200s'",
name->ob_type->tp_name);
return -1;
}
if (tp->tp_dict == NULL && PyType_Ready(tp) < 0)
return -1;
Py_INCREF(name);
//老规矩,获取属性
descr = _PyType_Lookup(tp, name);
if (descr != NULL) {
Py_INCREF(descr);
f = descr->ob_type->tp_descr_set;
if (f != NULL) {
res = f(descr, obj, value);
goto done;
}
}
if (dict == NULL) {
//这行代码就是PyObject_GenericGetAttr中根据dictoffset获取dict对象的那段代码
dictptr = _PyObject_GetDictPtr(obj);
if (dictptr == NULL) {
if (descr == NULL) {
PyErr_Format(PyExc_AttributeError,
"'%.100s' object has no attribute '%U'",
tp->tp_name, name);
}
else {
PyErr_Format(PyExc_AttributeError,
"'%.50s' object attribute '%U' is read-only",
tp->tp_name, name);
}
goto done;
}
res = _PyObjectDict_SetItem(tp, dictptr, name, value);
}
else {
Py_INCREF(dict);
if (value == NULL)
res = PyDict_DelItem(dict, name);
else
res = PyDict_SetItem(dict, name, value);
Py_DECREF(dict);
}
if (res < 0 && PyErr_ExceptionMatches(PyExc_KeyError))
PyErr_SetObject(PyExc_AttributeError, name);
done:
Py_XDECREF(descr);
Py_DECREF(name);
return res;
}
13.5.2 再论descriptor
前面我们看到,在PyType_Ready中,python虚拟机会填充tp_dict,其中与操作名对应的是一个个descriptor,那是我们看到的是descriptor这个概念在python内部是如何实现的。现在我们将要剖析的是descriptor在python的类机制中究竟会起到怎样的作用。
在python虚拟机对class对象或instance对象进行属性访问时,descriptor将对属性访问的行为产生重大的影响。一般而言,对于一个对象obj,如果obj.__class__对应的class对象中存在__get__、__set__、__delete__操作(不要求三者同时存在),那么便可以称之为描述符。在slotdefs中,我们会看到这三种魔法方法对应的操作。
//typeobject,c
TPSLOT("__get__", tp_descr_get, slot_tp_descr_get, wrap_descr_get,
"__get__($self, instance, owner, /)
--
Return an attribute of instance, which is of type owner."),
TPSLOT("__set__", tp_descr_set, slot_tp_descr_set, wrap_descr_set,
"__set__($self, instance, value, /)
--
Set an attribute of instance to value."),
TPSLOT("__delete__", tp_descr_set, slot_tp_descr_set,
wrap_descr_delete,
"__delete__($self, instance, /)
--
Delete an attribute of instance."),
前面我看到了PyWrapperDescrObject、PyMethodDescrObject等对象,它们对应的类对象中分别为tp_descr_get设置了wrapperdescr_get,method_get等函数,所以它们是当之无愧的descriptor。
另外如果细分,descriptor还可以分为两种。(关于python中的描述符,我这里有一篇博客写的很详细,对描述符机制不太懂的话可以先去看看,https://www.cnblogs.com/traditional/p/11714356.html)
data descriptor:数据描述符,对应的__class__中定义了__get__和__set__的descriptorno data descriptor:非数据描述符,对应的__class__中只定义了__get__方法
在python虚拟机访问instance对象的属性时,descriptor的一个作用就是影响python虚拟机对属性的选择。从PyObject_GenericGetAttr源码中可以看到,python虚拟机会在instance对象自身的__dict__中寻找属性,也会在instance对象对应的class对象的mro列表中寻找属性,我们将前一种属性称之为instance属性,后一种属性称之为class属性。在属性的选择上,有如下规律。
python虚拟机优先按照instance属性、class属性的顺序选择属性,即instance属性优先于class属性
如果在class属性中发现同名的data descriptor,那么该descriptor会优先于instance属性被python虚拟机选择。
这两条规则在对属性进行设置时仍然会被严格遵守,换句话说,如果执行a.value = 1,而在A中出现了名为A的数据描述符,那么不好意思,会执行__set__方法,如果是非数据描述符,那么就不再走__set__了,而是设置属性,相当于a.__dict__['value'] = 1。
所以,获取被描述符代理的属性时,会直接调用__get__方法。设置的话,会调用__set__。当然要考虑优先级的问题,至于优先级的问题是什么,这里就不再解释,强烈建立看我上面发的博客链接,对描述符的解析很详细。
13.5.3 函数变身
在A的成员f的def语句中,我们分明看到一个self参数,self在python中是不是一个真正有效的参数呢?还是它仅仅只是一个语法意义是哪个的占位符而已?这一点可以从函数g中看到答案,在g中有这样的语句:self.value = value,这条语句毫无疑问地揭示了self确实是一个实实在在的对象,所以表面上看起来f是一个不需要参数的函数,但实际上是一个货真价值的带参函数,只不过第一个参数自动帮你传递了,根据使用python的经验我们知道,传递给self的就是实例本身。但是现在问题来了,这是怎么实现的呢?我们先再看一遍字节码
17 22 LOAD_NAME 2 (a)
24 LOAD_METHOD 3 (f)
26 CALL_METHOD 0
28 POP_TOP
18 30 LOAD_NAME 2 (a)
32 LOAD_METHOD 4 (g)
34 LOAD_CONST 2 (10)
36 CALL_METHOD 1
38 POP_TOP
40 LOAD_CONST 3 (None)
42 RETURN_VALUE
我们注意到,在LOAD完属性a.f之后,会压入运行时栈,然后直接就CALL_METHOD了,并且参数居然是个0。注意:这里是CALL_METHOD,不是CALL_FUNCTION。因此我们可以有两条路可走,一条是看看CALL_METHOD是什么,另一条是再研究一下PyFunctionObject。我们先来看看CALL_METHOD这个指令长什么样子吧
//ceval.c
TARGET(CALL_METHOD) {
/* Designed to work in tamdem with LOAD_METHOD. */
PyObject **sp, *res, *meth;
sp = stack_pointer;
meth = PEEK(oparg + 2);
if (meth == NULL) {
res = call_function(&sp, oparg, NULL);
stack_pointer = sp;
(void)POP(); /* POP the NULL. */
}
else {
res = call_function(&sp, oparg + 1, NULL);
stack_pointer = sp;
}
PUSH(res);
if (res == NULL)
goto error;
DISPATCH();
}
//为了对比,我们再把CALL_FUNCTION的源码贴出来
TARGET(CALL_FUNCTION) {
PyObject **sp, *res;
sp = stack_pointer;
res = call_function(&sp, oparg, NULL);
stack_pointer = sp;
PUSH(res);
if (res == NULL) {
goto error;
}
DISPATCH();
}
通过对比,发现端倪,这两个都调用了call_function,但是传递的参数不一样,call_function的第二个参数一个oparg+1,一个是oparg,但是这还不足以支持我们找出问题所在。其实在剖析函数的时候,我们放过了PyFunctionObject的class ->PyFunction_Type。在这个PyFunction_Type中,隐藏着一个惊天大秘密。
PyTypeObject PyFunction_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"function",
sizeof(PyFunctionObject),
0,
(destructor)func_dealloc, /* tp_dealloc */
0, /* tp_print */
0, /* tp_getattr */
0, /* tp_setattr */
0, /* tp_reserved */
(reprfunc)func_repr, /* tp_repr */
0, /* tp_as_number */
0, /* tp_as_sequence */
0, /* tp_as_mapping */
0, /* tp_hash */
function_call, /* tp_call */
0, /* tp_str */
0, /* tp_getattro */
0, /* tp_setattro */
0, /* tp_as_buffer */
Py_TPFLAGS_DEFAULT | Py_TPFLAGS_HAVE_GC, /* tp_flags */
func_new__doc__, /* tp_doc */
(traverseproc)func_traverse, /* tp_traverse */
0, /* tp_clear */
0, /* tp_richcompare */
offsetof(PyFunctionObject, func_weakreflist), /* tp_weaklistoffset */
0, /* tp_iter */
0, /* tp_iternext */
0, /* tp_methods */
func_memberlist, /* tp_members */
func_getsetlist, /* tp_getset */
0, /* tp_base */
0, /* tp_dict */
//注意注意注意注意注意注意注意,看下面这行
func_descr_get, /* tp_descr_get */
0, /* tp_descr_set */
offsetof(PyFunctionObject, func_dict), /* tp_dictoffset */
0, /* tp_init */
0, /* tp_alloc */
func_new, /* tp_new */
};
我们发现与__get__相对应的tp_descr_get被设置成了func_descr_get,这意味着我们得到的是一个描述符,由于没有设置tp_descr_set,所以A.f是一个非数据描述符。另外由于a.__dict__中没有f,那么a.f的返回值将会被descriptor改变,其结果将是A.f.__get__,也就是func_descr_get(A.f, a, A)
//funcobject.c
static PyObject *
func_descr_get(PyObject *func, PyObject *obj, PyObject *type)
{
if (obj == Py_None || obj == NULL) {
Py_INCREF(func);
return func;
}
return PyMethod_New(func, obj);
}
func_descr_get将A.f对应的PyFunctionObject进行了一番包装,通过PyMethod_New,python虚拟机在PyFunctionObject的基础上创建一个新的对象PyMethodObject,到PyMethod_New中一看,那个神秘的对象现身了:
//classobjet.c
PyObject *
PyMethod_New(PyObject *func, PyObject *self)
{
PyMethodObject *im;
if (self == NULL) {
PyErr_BadInternalCall();
return NULL;
}
im = free_list;
if (im != NULL) {
//使用缓冲池
free_list = (PyMethodObject *)(im->im_self);
(void)PyObject_INIT(im, &PyMethod_Type);
numfree--;
}
else {
//不适用缓冲池,直接创建PyMethodObject对象
im = PyObject_GC_New(PyMethodObject, &PyMethod_Type);
if (im == NULL)
return NULL;
}
im->im_weakreflist = NULL;
Py_INCREF(func);
im->im_func = func;
Py_XINCREF(self);
//这里就是self
im->im_self = self;
_PyObject_GC_TRACK(im);
return (PyObject *)im;
}
一切真相大白,原来那个神秘的对象就是PyMethodObject对象,看到free_list这样熟悉的字眼,我们就知道python内部对PyMethodObject的实现和管理中使用缓冲池的技术。现在再来看看这个PyMethodObject
//classobject.h
typedef struct {
PyObject_HEAD
//可调用的PyFunctionObject对象
PyObject *im_func; /* The callable object implementing the method */
//用于成员函数调用的self参数,instance对象
PyObject *im_self; /* The instance it is bound to */
//弱引用列表
PyObject *im_weakreflist; /* List of weak references */
} PyMethodObject;
在PyMethod_New中,分别将im_func,im_self设置了不同的值,对应的就是f对应PyFunctionObject对象、a对应的instance对象。因此通过PyMethodObject对象将PyFunctionObject对象和instance对象结合在一起(通过实例调用成员函数会先调用描述符、然后通过PyMethod_New将func和instance绑定起来得到PyMethodObject对象,调用函数相当于调用的是PyMethodObject,在调用PyMethodObject中会处理自动传参的逻辑。就相当于在调用会自动将instance传递给第一个参数的PyFunctionObject,所以为什么实例调用方法的时候会自动传递第一个参数现在是真相大白了)这个过程称之为成员函数的绑定,就是将实例和方法绑定起来,使之成为一个整体。
class A:
def f(self):
pass
a = A()
print(a.__class__.f) # <function A.f at 0x00000190DD09FF70>
print(a.f) # <bound method A.f of <__main__.A object at 0x00000190DD031F10>>
13.5.4 无参函数调用
17 22 LOAD_NAME 2 (a)
24 LOAD_METHOD 3 (f)
26 CALL_METHOD 0
28 POP_TOP
18 30 LOAD_NAME 2 (a)
32 LOAD_METHOD 4 (g)
34 LOAD_CONST 2 (10)
36 CALL_METHOD 1
38 POP_TOP
40 LOAD_CONST 3 (None)
42 RETURN_VALUE
在LOAD_METHOD指令结束之后,那么便开始了CALL_METHOD,我们知道这个和CALL_FUNCTION之间最大的区别就是,CALL_METHOD调用的是一个PyMethodObject对象,而CALL_FUNCTION调用的一个PyFunctionObject对象。
//ceval.c
Py_LOCAL_INLINE(PyObject *) _Py_HOT_FUNCTION
call_function(PyObject ***pp_stack, Py_ssize_t oparg, PyObject *kwnames)
{
PyObject **pfunc = (*pp_stack) - oparg - 1;
PyObject *func = *pfunc;
PyObject *x, *w;
Py_ssize_t nkwargs = (kwnames == NULL) ? 0 : PyTuple_GET_SIZE(kwnames);
Py_ssize_t nargs = oparg - nkwargs;
PyObject **stack = (*pp_stack) - nargs - nkwargs;
...
...
else {
//从PyMethodObject对象中抽取PyFunctionObject和self参数
if (PyMethod_Check(func) && PyMethod_GET_SELF(func) != NULL) {
/* Optimize access to bound methods. Reuse the Python stack
to pass 'self' as the first argument, replace 'func'
with 'self'. It avoids the creation of a new temporary tuple
for arguments (to replace func with self) when the method uses
FASTCALL. */
//记住这个宏,从名字也能看出来这是获取self的
PyObject *self = PyMethod_GET_SELF(func);
Py_INCREF(self);
func = PyMethod_GET_FUNCTION(func);
Py_INCREF(func);
//self参数入栈,调整参数信息变量
Py_SETREF(*pfunc, self);
//参数个数加一
nargs++;
stack--;
}
else {
Py_INCREF(func);
}
//还记得这个吗?一个是快速通道,一个不是快速通道
//之前我们介绍调用的时候,有时直接就跳到这里了_PyObject_FastCallKeywords
//但是这个函数是通过call_function来调用的。
if (PyFunction_Check(func)) {
x = _PyFunction_FastCallKeywords(func, stack, nargs, kwnames);
}
else {
x = _PyObject_FastCallKeywords(func, stack, nargs, kwnames);
}
Py_DECREF(func);
}
...
...
return x;
}
显然在调用成员函数f的时候,显式传入的参数个数为0,也就是说调用f的时候,python虚拟机没有进行参数入栈的动作。而f显然又是一个需要参数的函数,其参数为self。因此在call_function中,python会为PyMethodObject对象进行了一些参数处理的动作。
当python虚拟机执行a.f()的时候,在call_function中,会执行PyMethod_GET_SELF,因为条件显然是成立的。
#define PyMethod_GET_FUNCTION(meth)
(((PyMethodObject *)meth) -> im_func)
#define PyMethod_GET_SELF(meth)
(((PyMethodObject *)meth) -> im_self)
在call_function中,func变量指向一个PyMethodObject对象,然后会将PyFunctionObject对象和instance对象分别提取出来。
PyObject *self = PyMethod_GET_SELF(func);
...
//self参数入栈,调整参数信息变量
Py_SETREF(*pfunc, self);
在分析函数机制的时候,我们也看到了这个pfunc,它指向的位置正是存放PyMethodObject对象的位置。那么在这个本来属于PyMethodObject的地方存放instance对象究竟有什么作用呢。其实python虚拟机以另一种方式完成了函数参数入栈的动作,而这个本来属于PyMethodObject对象的内存空间现在被用作了函数f的self参数的容身之处。我们先来看看调用call_function后运行时栈的变化情况:

我们观察设置pfunc之前和之后的运行时栈,貌似没什么区别,我们往后看。
在call_function,接着还会通过PyMethod_GET_FUNCTION将PyMethodObject对象中的PyFunctionObject提取出来,随后完成了self的入栈,同时还调整了维护这参数信息的nargs和stack。回忆之前的队函数机制的分析,我们可以发现,调整的函数会获得第一个位置参数,没错,就是self
由于func在if分支之后指向了PyFunctionObject对象,所以接下来python虚拟机将会执行_PyFunction_FastCallKeywords或者_PyObject_FastCallKeywords。到了这里,我们已经可以势如破竹了,因为剩下的动作和我们之前分析的带参函数的调用一致,而a.f实际上就是个带一个位置参数的一般函数的调用。而在_PyFunction_FastCallKeywords中,作为self参数的instance被python虚拟机压入到了运行时栈中。通过之前对函数的分析,我们知道,由于a.f仅仅是个带一个位置参数的函数,所以将会走快速通道,因此会调用_PyFunction_FastCallKeywords,在快速通道中,运行时栈中的这个instance对象会被拷贝到新的PyFrameObject对象的f_localsplus中。还记得快速通道的逻辑吗?
//call.c
PyObject *
_PyFunction_FastCallKeywords(PyObject *func, PyObject *const *stack,
Py_ssize_t nargs, PyObject *kwnames)
{
PyObject **stack = (*pp_stack) - nargs - nkwargs;
...
...
if (co->co_kwonlyargcount == 0 && nkwargs == 0 &&
(co->co_flags & ~PyCF_MASK) == (CO_OPTIMIZED | CO_NEWLOCALS | CO_NOFREE))
{
if (argdefs == NULL && co->co_argcount == nargs) {
//调用function_code_fastcall
//参数stack就是运行时栈
return function_code_fastcall(co, stack, nargs, globals);
}
else if (nargs == 0 && argdefs != NULL
&& co->co_argcount == PyTuple_GET_SIZE(argdefs)) {
stack = &PyTuple_GET_ITEM(argdefs, 0);
return function_code_fastcall(co, stack, PyTuple_GET_SIZE(argdefs),
globals);
}
}
return _PyEval_EvalCodeWithName((PyObject*)co, globals, (PyObject *)NULL,
stack, nargs,
nkwargs ? &PyTuple_GET_ITEM(kwnames, 0) : NULL,
stack + nargs,
nkwargs, 1,
d, (int)nd, kwdefs,
closure, name, qualname);
}
static PyObject* _Py_HOT_FUNCTION
function_code_fastcall(PyCodeObject *co, PyObject *const *args, Py_ssize_t nargs,
PyObject *globals)
{
PyFrameObject *f;
PyThreadState *tstate = PyThreadState_GET();
PyObject **fastlocals;
Py_ssize_t i;
PyObject *result;
assert(globals != NULL);
/* XXX Perhaps we should create a specialized
_PyFrame_New_NoTrack() that doesn't take locals, but does
take builtins without sanity checking them.
*/
assert(tstate != NULL);
//创建新的PyFrameObject对象f,tstate是当前线程,后续章节会介绍,包括python的多线程,GIL等等
f = _PyFrame_New_NoTrack(tstate, co, globals, NULL);
if (f == NULL) {
return NULL;
}
//拿到f_localsplut
fastlocals = f->f_localsplus;
//这里的nargs就是上面传递的stack
for (i = 0; i < nargs; i++) {
Py_INCREF(*args);
//拷贝self参数到f_localsplus中
fastlocals[i] = *args++;
}
result = PyEval_EvalFrameEx(f,0);
if (Py_REFCNT(f) > 1) {
Py_DECREF(f);
_PyObject_GC_TRACK(f);
}
else {
++tstate->recursion_depth;
Py_DECREF(f);
--tstate->recursion_depth;
}
return result;
}
在调用_PyFunction_FastCallKeywords之后,参数的数量已经从0变成了1,所以stack指向的位置就和pfunc指向的位置是一致的了。然后为了要将instance作为参数拷贝到函数的参数区fastlocals中,就必须要将它放到栈顶,也就是PyMethodObject对象所在的位置上,这就是前面要执行Py_SETREF(*pfunc, self);将self入栈的原因。
13.5.5 带参函数的调用
分析了类中无参的成员函数的调用,那么带参函数也就水到渠成了,因为流程是一致的,我们看看带参函数的字节码。
17 22 LOAD_NAME 2 (a)
24 LOAD_METHOD 3 (f)
26 CALL_METHOD 0
28 POP_TOP
18 30 LOAD_NAME 2 (a)
32 LOAD_METHOD 4 (g)
34 LOAD_CONST 2 (10)
36 CALL_METHOD 1
38 POP_TOP
40 LOAD_CONST 3 (None)
42 RETURN_VALUE
无视POP_TOP及其下面的指令,我们和无参函数对比下,看看有什么不同。其实就是多了个LOAD_CONST,而这个指令显然不陌生了,就是将一个常量压入的运行时栈中。如果多个参数,就将多个参数压入到运行时栈,这就是无参成员函数和带参成员函数的唯一不同之处,想想无参函数的调用流程,带参函数的调用流程也就迎刃而解了。说白了,不就是将self和我们传入的参数一起压入到运行时栈中嘛。
因此到了这里,我们可以在更高层次俯视一下python的运行模型了,最核心的模型非常简单,可以简化为两条规则:
在某个命名空间中寻找符号对应的对象
对从命名空间中得到的对象进行某些操作
抛开面向对象这些花里胡哨的外表,其实我们发现class对象其实就是一个命名空间,instance对象也是一个命名空间,不过这些命名空间通过一些特殊的规则连接在一起,使得符号的搜索过程变得复杂,从而实现了面向对象这种编程模式,それだけ
13.5.6 bound method和unbound method
在python中,当对作为方法(或者说作为属性的函数)进行引用时,会有两种形式,bound method和unbound method
bound method:这种形式是通过实例对象进行属性引用,就像我们之前说的a.f这样
unbound method:这种形式是通过类对象进行属性引用,比如A.f
当然这两种引用方式是不同的,我们可以看一下字节码指令
class A(object):
def f(self):
pass
a = A()
A.f(a)
a.f()
8 22 LOAD_NAME 1 (A)
24 LOAD_METHOD 3 (f)
26 LOAD_NAME 2 (a)
28 CALL_METHOD 1
30 POP_TOP
9 32 LOAD_NAME 2 (a)
34 LOAD_METHOD 3 (f)
36 CALL_METHOD 0
38 POP_TOP
40 LOAD_CONST 2 (None)
42 RETURN_VALUE
光看字节码好像看不出来什么,还要从LOAD_METHOD指令最终调用type_getattro。在type_getattro中,会在class A的tp_dict中发现f对应的PyFunctionObject,同样因为它是一个descriptor,一次你也会调用其__get__函数进行转变。在之前剖析a.f时,我们看到这个转变是通过func_descr_get(A.f, a, A)完成的,但前提是实例调用。如果是这里的类调用,那么不好意思,就会变成这样,func_descr_get(A.f, NULL, A)。因此虽然A.f调用得到的也是一个PyMethodObject,但其中的im_self确实NULL。
在python中,bound method和unbound method的本质区别就在于PyFunctionObject有没有与instance对象绑定在PyMethodObject对象。bound method完成了绑定动作,而unbound method没有完成绑定动作。
所以在对unbound method进行调用时,我们必须要显示的传递一个instance对象(哪怕这个instance对象不是当前class对象的实例也可以,具体什么意思后面会演示)作为成员函数的第一个参数,因为f无论如何都需要一个self参数,所有才会有A.f(a)这种形式。而无论是对unbound method进行调用,还是对bound method进行调用,python虚拟机的动作本质都是一样的,都是调用带位置参数的一般函数。区别只在于:当调用bound method时,python虚拟机帮我们完成了PyFunctionObject对象和instance对象的绑定,instance对象将自动成为self参数;而调用unbound method时,没有这个绑定,我们需要自己传入self参数。
class A(object):
def f(self):
print(self)
a = A()
A.f(123) # 123
# 我们看到即便传入一个123,不传入a也是可以的
# 这是我们自己传递的,传递什么就是什么
a.f() # <__main__.A object at 0x000001F0FFE81F10>
# 但是a.f()就不一样了,调用的时候会自动将a作为参数传递给self
print(A.f) # <function A.f at 0x000001F0FFEEFF70>
print(a.f) # <bound method A.f of <__main__.A object at 0x000001F0FFE81F10>>
13.6 千变万化的descriptor
当我们调用instance对象的函数时,最关键的一个动作就是从PyFunctionObject对象向PyMethodObject对象的转变,而这个关键的转变就取决于python中的descriptor。当我们访问对象中的属性时,由于descriptor的存在,这种转换自然而然的就发生了。事实上,python中的descriptor很强大,我们可以使用它做很多事情,而在python的内部,也存在各种各样的descriptor,比如property、staticmethod、classmethod等等,这些descriptor给python的类机制赋予了强大的力量。具体源码就不分析了,因为本质上是一样的,staticmethod就是一个类,然后调用的时候,会触发这个类的__get__方法,我们直接通过python代码的层面演示一下,这三种描述符的实现。
实现property
class Property:
def __init__(self, func):
self.func = func
def __get__(self, instance, owner):
if instance is None:
# 如果instance是None说明是实例调用,那么直接返回这个描述符本身
# 这个和内置property的处理方式是一样
return self
res = self.func(instance)
return res
class A:
@Property
def f(self):
return "name: hanser"
a = A()
print(a.f) # name: hanser
print(A.f) # <__main__.Property object at 0x000001FABFE910A0>
实现staticmethod
class StaticMethod:
def __init__(self, func):
self.func = func
def __get__(self, instance, owner):
# 静态方法的话,类和实例都可以用
# 类调用不会自动传参,但是实例会自动传递,因此我们需要把实例调用传来的self给扔掉
# 做法是直接返回self.func即可,注意:self.func是A.func
# 因此调用的时候,是类去调用的,而类调用是不会自动加上参数的。
return self.func
class A:
@StaticMethod
def f():
return "name: hanser"
a = A()
print(a.f()) # name: hanser
print(A.f()) # name: hanser
实现classmethod
class ClassMethod:
def __init__(self, func):
self.func = func
def __get__(self, instance, owner):
# 类方法,目的是在类调用的时候,将类本身作为第一个参数传递进去
# 显然是这里的owner
# 返回一个闭包,然后当调用的时候,接收参数
# 不管是谁调用,最终这个self.func都是A.func,然后手动将cls也就是owner传递进去
def inner(*args, **kwargs):
return self.func(owner, *args, **kwargs)
return inner
class A:
name = "hanser"
@ClassMethod
def f(cls):
return f"name: {cls.name}"
a = A()
print(a.f()) # name: hanser
print(A.f()) # name: hanser
13.7 おしまい
以上就是python关于类的剖析,到此就结束啦。累死我了。。。。。
