SQL语句的历程
通常,数据库就如同一个黑匣子,我们输入 SQL 语句给它,它负责反馈执行结果给我们。尤其是 SQL 又是一种入门极简单的语言,使用者只要能看懂英语就能熟练写出增删改查的简单语句,对于刚入门的用户来说肯定感觉是极好的。
在数据量比较少时,用户对数据库操作得比较随意,数据库也不会提出反对意见。但是随着数据量的增加,若是再胡乱地拼凑几个查询,并期望数据库给出一个完美的结果,那只能一首《凉凉》送给你——数据库罢工了。这时用户会查阅手册或者咨询一些资深的 DBA,期望得到一个"合理的解释",但往往针对特定问题只能得到特定解决方案,下次遇到其他状况仍旧无从下手。
所谓求人不如求己,若用户对一个 SQL 语句进入数据库究竟经历了怎样的历程了如指掌,则可以在书写 SQL 的时候就避免 freestyle,即使遇到问题也能胸有成竹地解决。既然前景如此美好,让我们就从最简单的一个 SQL 语句开始看看,一个 SQL 语句在进入数据库之后,到底经历了什么。
语法分析
要查询一个表中的一部分数据,用最简单的 SELECT 查询就可以了:
SELECT * FROM TEST_A;
这是一个单表查询语句,SELECT 告诉我们这是一个查询操作,FROM TEST_A 告诉我们 TEST_A 是要查询的表,而*则表示要输出的内容是 TEST_A 表的所有列的内容。
当用户将语句输入客户端工具(比如 psql)之后,客户端工具会将这个语句发送给数据库服务器,这时候 SQL 语句就进入了黑匣子里面,那么黑匣子如何处理它呢?
首先,黑匣子会通过 Lex 工具对 SQL 语句进行词法分析并产生 token,这些 token 都带有固定的词性,比如 token 可以是关键字、标识符、常量、运算符或边界符等。下面的内容展示了 SQL 语句被拆解成 token 之后的词性:
SELECT 关键字
* 常量
FROM 关键字
TEST_A 常量
; 边界符
语法分析器则接收词法分析产生的 token,并结合它的词性开始按照定义好的语法规则产生语法树。语法分析的规则在虽然算是内核中的源码,但是定义起来是非常简单的,这是因为语法分析使用的是 Yacc 工具。这个工具负责真正的语法分析,而使用者只需要定义语法规则即可,我们从中摘取一小部分语法规则来看一下:
simple_select:
SELECT opt_all_clause opt_target_list
into_clause from_clause where_clause
group_clause having_clause window_clause
{
SelectStmt *n = makeNode(SelectStmt);
n->targetList = $3;
n->intoClause = $4;
n->fromClause = $5;
n->whereClause = $6;
n->groupClause = $7;
n->havingClause = $8;
n->windowClause = $9;
$$ = (Node *)n;
}
如果熟悉 SQL 语法的规则,那么很容易从上面的代码中看出各个部分的含义。Yacc 工具就结合上面的规则同时根据 token 的内容产生语法树,比如 Lex 交给 Yacc 一个 SELECT 关键字,Yacc 就可以找到上面的 simple_select 规则,并最终根据规则创建一个查询类型的语法树结点。
如示例中的 SQL 语句中的投影列是*,也就是说要把 TEST_A 表中所有的列都投影出来,但 Yacc 工具并不了解这些,所以它直接把一个*保存成列信息。
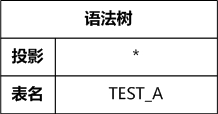
经过语法分析,原来的 SQL 语句就转变成一棵语法树,这棵语法树包含下面的内容:
是 SELECT 查询操作
-> 投影,目前的内容是 “*”
-> 要查询的表,目前的内容是表名 TEST_A
当然,如果用户在写 SQL 语句的时候显式地指定了具体的投影列,比如:
SELECT a, b, c, d FROM ...
Yacc 就会用一个链表来表示需要进行投影的列,这个链表中有 4 个结点,这 4 个结点分别保存的是列名:a、b、c、d。
FROM 作为一个关键字,表示对 SQL 语句的解析进入了新的状态,FROM 后面接着的就是要查询的表——TEST_A,这时虽然语法分析器能知道 TEST_A 是一个表,但它对这个表掌握的信息也只有表名而已,我们在查询某个表的时候有时候还会指定这个表属于哪个 schema,这些和表名一样,统统都以记录名字的方式记录下来。
语义分析
语法分析器实际上是很懒的,它只专注于对 SQL 语句做解析,获得的信息也全部来源自 SQL 语句,其他的一概不管。比如在 SQL 语句中遇到要查询的表,就把表的名字记下来了,但是这个表是不是真的存在,它并不去检查。语法树生成之后,语法分析器就成功地把锅甩给了语义分析器。语义分析器接到这样一个“烂摊子”,就开始它的工作——检查和转换:
先检查这些对象是不是真的存在,如果用户输入了错误的表名和列名,语义分析器的小拳拳就会锤你胸口——把错误从黑匣子中抛出来;如果这些对象真的存在的话,就转换成内部形式来保存。
要转成内部形式来保存的原因是,这个查询语句实在是太简单了,信息严重不足,要对一个表进行查询,至少要知道这个表的结构吧?比如它有几个列属性、每个属性是什么类型、它是一个什么类型的表、这个表上有没有索引之类的,上述这些信息在一个简单的 SQL 语句里都没有表达出来,这都依赖于语义分析器从数据库的元数据中读取。
PostgreSQL 有很多系统表来保存这些元数据信息,比如 PG_CLASS 系统表保存了所有表的描述信息,PG_ATTRIBUTE 系统表则用来保存每个表的所有的列属性信息,再比如 PG_INDEX 用来保存索引的信息等,所谓一方有难八方支援,当我们知道要查询一个表的名字的时候,我们需要把和这个表名相关的这些元数据组织起来。用有组织的元数据来代表这个表,这个过程就是语义分析。
在语法树中我们已经明确了每个对象的含义,因此可以借助遍历语法树来进行检查和转换的工作。
比如在语法树中遇到 TEST_A 就知道它是个表名而非列名,所以就可以去 PG_CLASS 里获取到这个表的基本信息,然后再根据 PG_CLASS 里的基本信息分别获取各种其他信息。通常数据库为了提高性能,会将这些表的信息缓存到主存里,所以每次获取表的元信息不一定都需要从磁盘上读取。
再比如在语法树的投影中遇到*,语义分析器就知道需要把它展开,这个展开的过程就需要去 PG_ATTRIBUTE 系统表中找到 TEST_A 表所对应的列属性的信息,用这些列属性信息把*替换掉。在 PG_ATTRIBUTE 表中记录了这些列的位置,也就是它们各自属于 TEST_A 的“第几列”。这个“第几列”就可以用来表示对应的列属性,而不再使用列名了。下面示例中的 attnum 就是表示列名对应的列是表的“第几列”(注:请忽略这些显示为负数的列,它们是“伪列”,如果不显式地在投影列中指定的话,是不会投影出来的):
postgres=# select attname, attnum
from pg_attribute
where attrelid =
(select oid
from pg_class
where relname = 'test_a');
attname | attnum
----------+--------
tableoid | -7
cmax | -6
xmax | -5
cmin | -4
xmin | -3
ctid | -1
a | 1
b | 2
c | 3
d | 4
(10 rows)
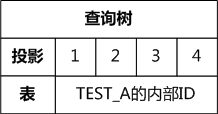
在经过语义分析之后,我们就可以获得一个查询树了,查询树和语法树本质上应该是等价的,但是他们表示信息的方式发生了变化:
是 SELECT 查询操作
-> 投影,“*”已经被展开成为具体的列,
不只记录列名,而是通过
该列在所在表的“第几列”来表示
->第 1 列是 a,第 2 列是 b,第 3 列是 c,第 4 列是 d
-> 要查询的表,通过表名找到该表的OID
并且将表的所有信息组织成一个描述符

查询重写
在语义分析之后,还需要对查询树做一个重写(rewrite)操作,PostgreSQL 数据库可以让用户自己制定规则对查询树进行改写,不过最常用这种规则的还是对视图的改写,比如我们创建一个视图:
CREATE VIEW TEST_A_VIEW AS SELECT * FROM TEST_A;
如果针对这个视图进行查询:
SELECT * FROM TEST_A_VIEW;
虽然我们创建的视图也会在 PG_CLASS 系统表里建立一个“虚”的表,但是它没有存储结点,没有办法写入数据,也没有办法使用视图直接访问磁盘上的数据,所以最终还是要通过 TEST_A_VIEW 和 TEST_A 之间的映射关系把对视图的查询转化到对表的查询上。因此,创建视图的时候,同时创建了重写(rewrite)规则,这些规则保存在 PG_REWIRTE 系统表中,创建 TEST_A_VIEW 会在 PG_REWRITE 系统表中记录“SELECT * FROM TEST_A”的查询树,由于查询树的内容比较长,我们就不在这里展示了,读者可以通过下面的 SQL 语句来一睹查询树的芳容:
SELECT *
FROM PG_REWRITE
WHERE EV_CLASS =
(SELECT OID
FROM PG_CLASS
WHERE RELNAME = 'TEST_A');
对查询树进行视图重写的过程就是将这棵查询树替换到“SELECT * FROM TEST_A_VIEW”产生的查询树中的过程,也就形成了类似下面的结构:
SELECT 查询操作,针对 TEST_A_VIEW 视图
-> 投影,通过在视图中的“第几列”来表示
->第 1 列是 a,第 2 列是 b,第 3 列是 c,第 4 列是 d
-> 要查询的视图
-> SELECT 查询操作,针对 TEST_A 表
-> 通过在表中的“第几列”表示
-> 第 1 列是 a,第 2 列是 b,第 3 列是 c,第 4 列是 d
-> 要查询的 TEST_A 表

实际上目前这棵查询树和下面的语句是等价的,视图相当于一个子查询:
SELECT * FROM (SELECT * FROM TEST_A) ta;
查询树在经历了重写之后,语义分析器就举办一个简单的交接仪式,正式把查询树转交给优化器了。优化器对查询树先进行逻辑优化,也就是按照优化规则进行优化,这是一种精准的微整容,在优化的过程中它还保留查询树的基本样貌,只是垫垫鼻子,削削下巴,比如视图会被当做子查询放到查询树里,在逻辑优化阶段就会查看一下这个子查询是不是能提升,也就是说子查询能不能消除掉,比如我们这里的两个查询实际上是完全等价的:
postgres=# EXPLAIN SELECT * FROM TEST_A;
QUERY PLAN
-----------------------------------------------------------
Seq Scan on test_a (cost=0.00..28.50 rows=1850 width=16)
(1 row)
postgres=# EXPLAIN SELECT * FROM TEST_A_VIEW;
QUERY PLAN
-----------------------------------------------------------
Seq Scan on test_a (cost=0.00..28.50 rows=1850 width=16)
(1 row)
postgres=# EXPLAIN SELECT * FROM (SELECT * FROM TEST_A) A;
QUERY PLAN
-----------------------------------------------------------
Seq Scan on test_a (cost=0.00..28.50 rows=1850 width=16)
(1 row)
逻辑优化就是做等价的逻辑变换,借由这种逻辑变换,将一棵低效的查询树转换成为一棵高效的查询树。逻辑优化之后就进入了物理优化阶段,它会生成很多的查询路径,比如顺序扫描、索引扫描之类的,并且计算这些路径的代价。
以对 TEST_A 表的查询为例,可以生成哪些查询路径呢?
它可以生成一个顺序扫描路径,因为要返回 TEST_A 表的所有元组,所以把 TEST_A 表从头到尾扫描一遍是很合理的。还可以生成一个索引扫描路径(假如 TEST_A 上有索引),借助索引间接进行数据访问。
代价估算系统就可以根据上面两种路径(顺序扫描路径和索引扫描路径)对数据的访问方式,估计出来一个可比较的代价,这样优化器就可以和所有可能的执行路径一一确认眼神,终于遇见对的人,最后把最优路径转换成具体的执行计划。
打印执行计划的参数
如果各位有兴趣,PostgreSQL 数据库也提供了 GUC 参数让我们查看查询树和执行计划树,通过打开这些参数,查询树和执行计划就能打印出来。但是查询树和执行计划树的具体结构是“偏内核”的,通常对于 PostgreSQL 的内核开发人员是比较有用的。我们这里只把这些参数简单列出来,至于查询树和执行计划树中每个结点的含义,则需要结合 PostgreSQL 源代码的分析才能说清楚,对源码分析有兴趣的读者可以查阅《PostgreSQL 技术内幕:查询优化深度探索》。
- debug_pretty_print:打开该参数在打印查询树和执行计划时会以结构化的方式来展示,便于对查询树进行分析;
- debug_print_parse:打开该参数可以打印查询树;
- debug_print_rewritten:打开该参数可以打印重写(视图)之后的查询树;
- debug_print_plan:打开该参数可以打印执行计划。
用户可以通过 SET 命令来指定这些参数:
postgres=# SET DEBUG_PRINT_PLAN = ON;
SET
执行计划由执行器来执行。执行器实现了很多算子,比如我们刚才说的顺序扫描就有一个对应的顺序扫描算子,索引扫描也有一个对应的索引扫描算子。执行器根据执行计划选定的执行路径找到对应的执行算子进行数据的“计算”,我们就不再深究执行器是如何执行的了,但是我们接下来可以看看如何查看一个执行计划。
小结
通过查看一个 SQL 语句的“一生”,有助于了解 SQL 语句在数据库内部的演变过程。不同的查询树产生不同的执行计划,但不同的查询树之间可能是等价的,也就代表着不同的执行计划之间也可能是等价的。因此,我们可以尝试等价地变化查询树,这就是逻辑优化(基于规则的优化)的主要工作。
读者可以尝试通过打开 GUC 参数的方式来查看数据库内部究竟是如何保存一个语法树、查询树和执行计划的,这将有助于提高对优化器的理解能力。
解读执行计划
SQL 语句在转换成查询树之后,就会进入优化器。优化器通过对查询树进行逻辑优化和物理优化后挑选出一个最优的执行计划,这个执行计划就会交给执行器来执行。因此,在使用 PostgreSQL 数据库的过程中,如果你在执行一个 SQL 语句时期望优化器给你带来的是卖家秀,结果实际上收到一个买家秀,那二话不说就先要看看这个 SQL 语句到底产生了一个什么样的执行计划,是不是因为优化器一时发昏选了一个比较“傻”的执行计划。
不同的执行算子示例
执行计划是一个非完全的二叉树,每个父结点至少有一个子结点(叶子结点除外),最多有两个子结点。PostgreSQL 数据库的查询执行器通过对这个二叉树迭代执行来获得查询结果,它的执行过程我们通常叫它火山模型。
在 PostgreSQL 中,可以使用 EXPLAIN 语句来展示查询语句的执行计划,例如:
INSERT INTO STUDENT SELECT i, repeat('A', i%5 + 1), i%2 FROM GENERATE_SERIES(1,10000) i;
ANALYZE STUDENT;
postgres=# EXPLAIN SELECT * FROM STUDENT;
QUERY PLAN
--------------------------------------------------------------
Seq Scan on student (cost=0.00..155.00 rows=10000 width=12)
(1 row)
由于上面的示例是对 STUDENT 表进行查询,获取 STUDENT 表中的所有数据,因而就需要用一个 Seq Scan 就够了,它会把 STUDENT 表中的数据全部遍历一遍,但是假如要进行连接操作:
postgres=# EXPLAIN SELECT * FROM STUDENT, (SELECT * FROM SCORE) as sc;
QUERY PLAN
------------------------------------------------------------------------
Nested Loop (cost=0.00..1250335.00 rows=100000000 width=24)
-> Seq Scan on student (cost=0.00..155.00 rows=10000 width=12)
-> Materialize (cost=0.00..205.00 rows=10000 width=12)
-> Seq Scan on score (cost=0.00..155.00 rows=10000 width=12)
(4 rows)
我们从语句中可以看出这是一个单表和一个子查询进行连接,但是从执行计划可以看出,子查询已经没有了,而是直接变成了 STUDENT 表和 SCORE 的物化表的连接。这是因为优化器认为这里的子查询和直接使用 SCORE 表是等价的,这个执行计划对应的二叉树应该如下图所示:
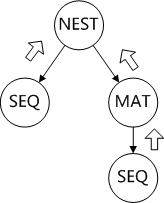
我们把每个结点的输出都可以看做是一个“临时表”,因此对于嵌套循环连接而言,它的左侧是对 STUDENT 表的顺序扫描,而右侧则可以看做是“临时表”的 Materialize 表,也就是说对于嵌套循环连接来说它的两个子结点“就是两个表”。
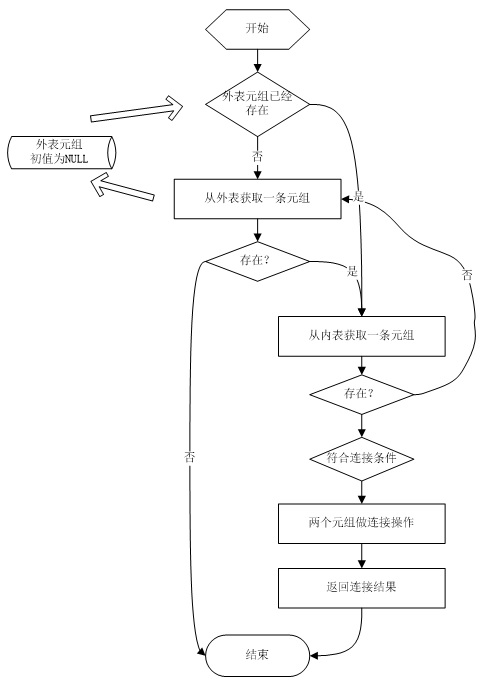
嵌套循环连接的执行流程是这样的:
1.如果不存在外表元组,从外边获得一条元组;2.如果外表元组是 NULL,连接操作结束;3.从内表获得一条元组;4.如果内表元组是 NULL,跳转到步骤 1;5.外表和内表元组做连接,返回连接结果。
嵌套循环连接的时间复杂度是一个 O(MN),所以它通常只适用于如下一些情况:
没有什么可用的连接条件内表有索引,可以通过索引扫描加速
EXPLAIN 执行计划的解读
执行计划中显示了优化器估算出来的两部分代价、行数和元组的宽度,例如,"(cost=0.00..1250335.00 rows=100000000 width=24)",其中每一部分的含义如下:

“cost=0.00..1250335.00”中的 0.00 代表的是启动代价,1250335.00 代表的是这个结点和它的子结点共同的整体代价。
启动代价是嵌套循环连接返回第一条元组前所消耗的代价。记录启动代价是有意义的,比如在执行计划中可能存在做“预处理”操作的结点,这些操作都会带来启动代价,因为它们要把全部元组预处理完才会返回第一条元组。比如排序操作,它需要把所有的元组都获取到,然后对元组排序,然后再返回第一条元组,所以获取第一条元组之前的排序时间就是启动代价:
postgres=# EXPLAIN SELECT * FROM STUDENT ORDER BY SNAME;
QUERY PLAN
--------------------------------------------------------------------
Sort (cost=819.39..844.39 rows=10000 width=12)
Sort Key: sname
-> Seq Scan on student (cost=0.00..155.00 rows=10000 width=11)
(3 rows)
通过上面的示例可以看出来,Sort 结点——也就是排序操作的启动代价是 819.39,它的执行代价是844.39 − 819.39 = 25.00。因此,在优化器进行最优执行计划选择的时候,启动代价是一个很重要的参考指标。
执行计划中的 rows 代表的是当前结点所产生的结果元组数量,这是一个估计值,实际上每个表针对元组数量都会有一个估计值,它保存在 PG_CLASS 系统表中。从下面的示例可以看出 STUDENT 表中有 10000 条元组,这是符合我们预期的(但实际上这里应该是个估计值,这里的估计比较准确是因为我们还没有对这个表进行过多次的增删改查操作)。
postgres=# select reltuples from pg_class where relname = 'student';
reltuples
-----------
10000
(1 row)
width 则是当前结点做投影的元组的平均宽度,STUDENT 表上的元组的平均宽度需要怎么计算呢?对于定长的属性,比如 INT 类型、BOOL 类型等,我们很容易知道它的长度,通过查询 PG_TYPE 系统表就能知道:
postgres=# SELECT typname, typlen FROM PG_TYPE WHERE TYPNAME='int4';
typname | typlen
---------+--------
int4 | 4
(1 row)
对于非定长的,比如 Varchar 类型、TEXT 类型,它在 PG_TYPE 系统表中的长度是 -1,但是我们有办法获每一列的平均宽度(通过统计信息获得,后续课程会进行介绍),这里我们用一个聚集函数来看一下 sname 列的平均宽度:
postgres=# SELECT AVG(LENGTH(sname)) FROM STUDENT;
avg
--------------------
3.0000000000000000
(1 row)
通过类型的长度以及通过聚集函数得到的平均宽度,我们可以计算得到元组的平均宽度是 4 + 3 + 4 = 11。可是我们从执行计划里看到的平均宽度是 12,这中间差的 1 个字节是搁哪来的呢?这是因为虽然我们用 avg 获得的 sname 的平均宽度是 3,但是在数据库内部,每个变长的数据类型会有一个头部(HEADER,头部的长度有可能是 1,也有可能是 4,取决于字符串具体的长度,我们示例中的字符串的长度都比较短,所以头部的长度是 1 字节)。它的形式是这样的,sname 除了内容的平均宽度是 3 之外,还有 1 个字节的 HEADER 信息,因此它的平均宽度是 4,也就获得了元组的平均宽度是 4 + 4 + 4 = 12。
物化结点的作用
各位是否产生这样一个疑问,执行计划中的 Materialize 这一层是否属于画蛇添足呢?这里对 SCORE 表进行一次物化看上去并不能带来任何效率上的提升,反而因为做物化需要消耗资源把代价从 105 增加到了 255,PostgreSQL 为什么要增加这样的结点呢?我们尝试通过一个 GUC 参数来把物化结点去掉,看看没有物化的执行计划的代价是多少:
postgres=# SET ENABLE_MATERIAL = OFF;
postgres=# EXPLAIN SELECT * FROM STUDENT st, SCORE sc;
QUERY PLAN
-----------------------------------------------------------------------
Nested Loop (cost=0.00..2550155.00 rows=100000000 width=24)
-> Seq Scan on student st (cost=0.00..155.00 rows=10000 width=12)
-> Seq Scan on score sc (cost=0.00..155.00 rows=10000 width=12)
(3 rows)
Time: 0.633 ms
有物化结点和没有物化结点的代价竟然相差这么多,没有物化结点的执行计划的总代价竟升高了足足有一倍,这其中的原因是 PostgreSQL 数据库的代价模型的计算方法的问题。
由于执行计划中的外表有 10000 条元组,在执行嵌套循环连接的时候,就需要对内表重复的扫描 10000 次。对一个表进行重复扫描的代价可能是不同的,比如第一次扫描的时候有些表的某些数据还在磁盘上,需要从磁盘加载到主存。但是在第二次扫描的时候,第一次加载到主存的数据就能够重复利用了,也就是说很可能第二次扫描的代价比第一次扫描的代价要低。
如果内表是 Seq Scan(没有物化的情况),它重复扫描的时候代价估算系统仍然认为代价是 155,也就是仍然按照需要读取磁盘的代价来进行计算。而 Materialize 就不同了,PostgreSQL 会计算物化之后的数据量的大小。如果物化之后的数据量能够完全放到内存里,在第二次扫描物化结点的时候,就可以假设这个结点是在内存里的,就不用考虑读磁盘带来的消耗了,这就是最终优化器认为加上 Materialize 的代价反而低的原因。
那么优化器是否可以考虑到各种情况呢? 假如把所有的因素都考虑到,那么生成执行计划的时候就会很长。如果生成执行计划要几个小时,即使选出的执行计划很优秀,也是不可接受的。因此,优化器中也需要权衡生成执行计划的时间和执行计划具体的执行时间。
EXPLAIN 语法说明
我们实际地执行一下有 Materialize 结点和没有 Materialize 结点的这两种执行计划,看看是否真的如优化器所估算的那样有很大的差别。恰好 EXPLAIN 有一些 option 选项,我们尝试通过下面这些选项来分析问题。
EXPLAIN [ ( _option_ [, ...] ) ] _statement_
其中的_option_可以是如下内容:
ANALYZE [ _boolean_ ]
VERBOSE [ _boolean_ ]
COSTS [ _boolean_ ]
BUFFERS [ _boolean_ ]
TIMING [ _boolean_ ]
FORMAT { TEXT | XML | JSON | YAML }
ANALYZE:通常通过 EXPLAIN 打印出的执行计划中的代价都是估计代价,如果增加上 ANALYZE 选项之后,还会在执行计划中打印实际的执行时间和实际的元组处理数量,也就是实际的代价。需要注意的是由于打印实际执行的代价也就意味着这个执行计划真正的执行了,而如果没有 ANALYZE 选项,执行计划不会实际地执行。
VERBOSE:通常打印的执行计划更多的关注它的执行路径,对于投影之类的信息不会同时打印出来,增加上 VERBOSE 选项打印的信息会更丰富。
COSTS:PostgreSQL 数据库默认打印代价,可以通过(COSTS OFF)关闭估计代价的打印。本选项默认是打开的,如果只是想看看执行路径,而不关系具体的估计代价,这个选项是可以关闭的。对于 PostgreSQL 数据库的内核开发者而言,这个选项经常用在写测试用例的时候。如果想测试一个语句的执行计划是否正确,自动化测试框架会通过 EXPLAIN 来查看该语句的执行计划。但自动化测试框架运行的主机不同,它产生的估计代价可能也不同,所以这时可以不打印代价的估计值。
BUFFERS:需要和 ANALYZE 同时使用,因为它要打印缓冲区的命中率,而命中率只有实际执行过才知道。数据库为了提高性能,并不是每次读取数据都从磁盘读取,而是将大部分数据缓存在主存里。如果缓存的命中率很低,就要增加换页锁带来的消耗,所以可以通过 BUFFERS 来查看缓冲区的命中率。
TIMING:需要和 ANALYZE 同时使用,ANALYZE 默认会统计各个结点的实际运行时间,通过 TIMING OFF,可以让 ANALYZE 不统计时间,只统计处理的元组的数量。
物化结点的代价模型的缺陷
有了这些选项,我们再来看一下,有 Materialize 结点和没有 Materialize 结点的实际执行代价:
postgres=# SET ENABLE_MATERIAL = ON;
postgres=# explain (analyze,buffers,costs off) SELECT * FROM STUDENT st, SCORE sc;
QUERY PLAN
--------------------------------------------------------------------------------
Nested Loop (actual time=0.054..31231.428 rows=100000000 loops=1)
Buffers: shared hit=110
-> Seq Scan on student st (actual time=0.016..2.951 rows=10000 loops=1)
Buffers: shared hit=55
-> Materialize (actual time=0.000..0.883 rows=10000 loops=10000)
Buffers: shared hit=55
-> Seq Scan on score sc (actual time=0.020..1.778 rows=10000 loops=1)
Buffers: shared hit=55
Planning time: 0.130 ms
Execution time: 38574.290 ms
(10 rows)
postgres=# SET ENABLE_MATERIAL = OFF;
postgres=# explain (analyze,buffers,costs off) SELECT * FROM STUDENT st, SCORE sc;
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (actual time=0.056..34717.028 rows=100000000 loops=1)
Buffers: shared hit=550055
-> Seq Scan on student st (actual time=0.031..1.845 rows=10000 loops=1)
Buffers: shared hit=55
-> Seq Scan on score sc (actual time=0.004..1.208 rows=10000 loops=10000)
Buffers: shared hit=550000
Planning time: 0.174 ms
Execution time: 41996.891 ms
(8 rows)
通过对比发现:
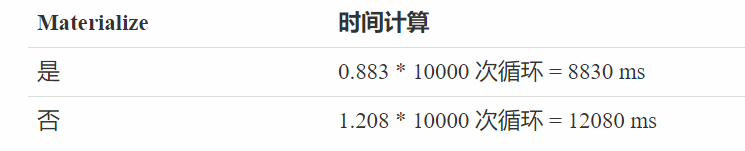
对比总代价的时间差和结点的时间差可以看出的确 Materialize 节省了时间:
估算的总时间差 = 2550155.00 - 1250335.00 = 1299820
实际执行总时间差 = 41996.891 - 38574.290 = 3422.601
实际执行对应结点的时间差 = 12080 - 8830 = 3250
实际执行时所节省的时间并没有优化器估算的那么大,这是因为 SCORE 表的体积并不大,在第一次读取之后,也能确保它的所有页面也已经加载到内存中了。从执行计划中也能看出,在没有 Materialize 结点的情况下,SCORE 表中页面在缓存中的命中率为 550000 次,而内表要重复扫描 10000 次。也就是说,平均每次循环命中 55 个页面,而实际上 SCORE 表目前也只有 55 个页面,也就证实了我们的猜想,页面已经全部被缓存。
postgres=# SELECT RELPAGES FROM PG_CLASS WHERE RELNAME = 'score';
relpages
----------
55
(1 row)
小结
执行计划的查看对 DBA 而言是非常重要的。如果一个查询语句执行得比较慢,这是最直接的查看手段,因此能够正确地阅读执行计划是所有 DBA 必须掌握的技能。如果通过查看执行计划发现了问题,进而想调整执行计划,PostgreSQL 也提供了相应的参数给我们来调整。
调整执行计划
通过 EXPLAIN 查看了具体的执行计划之后,我们还能尝试影响优化器,让优化器生成我们想要的执行计划。不过,PostgreSQL 没有像 Oracle 那样通过在 SQL 语句中增加 HINT 信息的方式来影响执行计划的生成。但它也提供了一系列的 GUC 参数,比如在前面的课程中曾使用 enable_material 参数来尝试禁用 material,而且确实达到了禁用的效果。PostgreSQL 针对大部分算子都给出了具体的 GUC 参数,下面先把这些 GUC 参数列出来:
- enable_bitmapscan
- enable_gathermerge
- enable_hashagg
- enable_hashjoin
- enable_indexonlyscan
- enable_indexscan
- enable_material
- enable_mergejoin
- enable_nestloop
- enable_parallel_append
- enable_parallel_hash
- enable_partitionwise_join
- enable_seqscan
- enable_sort
- enable_tidscan
每个 GUC 参数都可以通过下面的方式来设置:
SET GUC_NAME = ON/OFF;
扫描路径的调整
可以先来看一个最简单的情况:
postgres=# EXPLAIN SELECT * FROM STUDENT WHERE sno > 1000;
QUERY PLAN
-------------------------------------------------------------
Seq Scan on student (cost=0.00..180.00 rows=9000 width=12)
Filter: (sno > 1000)
(2 rows)
postgres=# set enable_seqscan = off;
SET
postgres=# EXPLAIN SELECT * FROM STUDENT WHERE sno > 1000;
QUERY PLAN
----------------------------------------------------------------------------------
Index Scan using student_pkey on student (cost=0.29..318.79 rows=9000 width=12)
Index Cond: (sno > 1000)
(2 rows)
从执行计划可以看出,在禁止掉 Seq Scan 之后,优化器选择了通过索引扫描(Index Scan)来对数据进行访问。从两个执行算子的代价来看,索引扫描的代价确实要大于顺序扫描的代价,也就是说在没有禁用 Seq Scan 的时候,优化器对这两种路径是进行过对比的,最终选择了代价低的顺序扫描。
那么如果把索引扫描也禁用掉会如何呢?还可以通过位图扫描的方式来对数据进行访问,通过对比执行计划的代价,发现目前位图扫描的代价“高达” 345.53,在目前已经展示出来的扫描算子中是最高的。因此,如果不禁用 Seq Scan 和 Index Scan,优化器在面对 Bitmap Scan 时“虽然脸上笑嘻嘻,但心里 mmp”,是不可能选择位图扫描的。
postgres=# set enable_indexscan = off;
SET
postgres=# EXPLAIN SELECT * FROM STUDENT WHERE sno > 1000;
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on student (cost=178.03..345.53 rows=9000 width=12)
Recheck Cond: (sno > 1000)
-> Bitmap Index Scan on student_pkey (cost=0.00..175.78 rows=9000 width=0)
Index Cond: (sno > 1000)
(4 rows)
我们进一步追问,如果我们把位图扫描也禁用掉呢?从示例中可以看到,位图扫描关闭之后,执行计划最终又选择回了顺序扫描。
postgres=# set enable_bitmapscan = off;
SET
postgres=# EXPLAIN SELECT * FROM STUDENT WHERE sno > 1000;
QUERY PLAN
-------------------------------------------------------------------------------
Seq Scan on student (cost=10000000000.00..10000000180.00 rows=9000 width=12)
Filter: (sno > 1000)
(2 rows)
虽然我们关闭了顺序扫描,但 PostgreSQL 中的“关闭”(off)并不是真的把这种执行算子给禁止掉,而是选择在优化器内部进行代价估算的时候,提高这种类型执行算子的代价值,这样就能让优化器把这种类型的执行算子筛掉。PostgreSQL 对一个表的扫描路径通常只有 3 种类型——顺序扫描、索引扫描、位图扫描。如果我们把这些路径都完全禁止掉,那优化器就束手无策了,执行计划就生成不出来了。因此,通过增加代价值让优化器对执行路径进行筛选,一方面可以筛掉被禁用的路径,另一方面也可以让优化器在无路可走时柳暗花明。
连接路径的调整
除了扫描算子,在优化器中还有很重要的 3 种连接算子,我们一一来看一下。首先看一下两个表做连接的情况,从示例中很容易看出,两个表选择了最通用的嵌套循环连接方法。这个示例我们在前面的课程中也使用 enable_material 进行调整过,通过禁用 Materialize 方法,可以产生两个表直接进行嵌套循环连接的执行计划。
postgres=# EXPLAIN SELECT * FROM STUDENT, SCORE;
QUERY PLAN
------------------------------------------------------------------------
Nested Loop (cost=0.00..1250335.00 rows=100000000 width=24)
-> Seq Scan on student (cost=0.00..155.00 rows=10000 width=12)
-> Materialize (cost=0.00..205.00 rows=10000 width=12)
-> Seq Scan on score (cost=0.00..155.00 rows=10000 width=12)
(4 rows)
如果我们把嵌套循环连接方法禁用掉,优化器想必会选择哈希连接或归并连接中的一种吧?
postgres=# set enable_nestloop = off;
SET
postgres=# EXPLAIN SELECT * FROM STUDENT, SCORE;
QUERY PLAN
----------------------------------------------------------------------------
Nested Loop (cost=10000000000.00..10001250335.00 rows=100000000 width=24)
-> Seq Scan on student (cost=0.00..155.00 rows=10000 width=12)
-> Materialize (cost=0.00..205.00 rows=10000 width=12)
-> Seq Scan on score (cost=0.00..155.00 rows=10000 width=12)
(4 rows)
结果事与愿违,优化器还是执着地选择了嵌套循环连接,尽管目前嵌套循环连接的执行代价已经非常大了。这是因为:PostgreSQL 要想生成哈希连接或者归并连接,需要有匹配的约束条件才行,显然我们的示例中是没有约束条件的,那么我们不妨加上约束条件:
postgres=# EXPLAIN SELECT * FROM STUDENT st, SCORE sc WHERE st.sno = sc.sno;
QUERY PLAN
-----------------------------------------------------------------------------
Hash Join (cost=280.00..561.24 rows=10000 width=24)
Hash Cond: (sc.sno = st.sno)
-> Seq Scan on score sc (cost=0.00..155.00 rows=10000 width=12)
-> Hash (cost=155.00..155.00 rows=10000 width=12)
-> Seq Scan on student st (cost=0.00..155.00 rows=10000 width=12)
(5 rows)
加上约束条件,优化器会去识别这个约束条件是否符合做哈希连接的需要,从执行计划可以看出,优化器选择了 st.sno = sc.sno 作为 Hash Cond。
如果继续关闭哈希连接,优化器就会倾向于选择归并连接了,从归并连接的执行计划中可以看出,这次 st.sno = sc.sno 又变成了 Merge Cond:
postgres=# set enable_hashjoin = off;
SET
postgres=# EXPLAIN SELECT * FROM STUDENT st, SCORE sc WHERE st.sno = sc.sno;
QUERY PLAN
--------------------------------------------------------------------------------------------
Merge Join (cost=819.68..1322.67 rows=10000 width=24)
Merge Cond: (st.sno = sc.sno)
-> Index Scan using student_pkey on student st (cost=0.29..328.29 rows=10000 width=12)
-> Sort (cost=819.39..844.39 rows=10000 width=12)
Sort Key: sc.sno
-> Seq Scan on score sc (cost=0.00..155.00 rows=10000 width=12)
(6 rows)
这里有一点需要说明的是,归并连接这种需要排序的执行算子是 B 树索引扫描的“真爱粉”,因为 student_pkey 这样的 B 树索引具有有序的特点。通过这种索引扫描出来的数据天然就是有序的,而归并连接最喜欢的就是有序的数据,这样它就能避免对这份数据再进行显式地排序了。从执行计划可以看出,SCORE 表上就没有索引,所以显式地加上了 Sort 结点,而 STUDENT 表的扫描则借助了索引的有序性,没有显式地增加 Sort 结点。
我们在这里继续禁用 Sort 方法,结果执行计划又出现了走投无路的情况,从执行计划的代价可以看出,这次的 Sort 结点的排序代价是一个“超大值”。
postgres=# set enable_sort = off;
SET
postgres=# EXPLAIN SELECT * FROM STUDENT st, SCORE sc WHERE st.sno = sc.sno;
QUERY PLAN
--------------------------------------------------------------------------------------------
Merge Join (cost=10000000819.68..10000001322.67 rows=10000 width=24)
Merge Cond: (st.sno = sc.sno)
-> Index Scan using student_pkey on student st (cost=0.29..328.29 rows=10000 width=12)
-> Sort (cost=10000000819.39..10000000844.39 rows=10000 width=12)
Sort Key: sc.sno
-> Seq Scan on score sc (cost=0.00..155.00 rows=10000 width=12)
(6 rows)
聚集与分组的执行计划调整
PostgreSQL 中提供了两种对数据进行分组的方法,一种是哈希聚集(Hash Cluster),另一种是顺序聚集(Sort Cluster),但是 PostgreSQL 只提供了对 Hash 聚集的禁用方法,却没有提供对 Sort 聚集的禁用方法。实际上 Hash 聚集的这个功能在 PostgreSQL 中实现得比较晚,也就是说在很长一段时间 PostgreSQL 只有 Sort 聚集一种分组方法。
postgres=# EXPLAIN SELECT MAX(DEGREE) FROM SCORE GROUP BY CNO;;
QUERY PLAN
-----------------------------------------------------------------
HashAggregate (cost=205.00..205.05 rows=5 width=8)
Group Key: cno
-> Seq Scan on score (cost=0.00..155.00 rows=10000 width=8)
(3 rows)
postgres=# set enable_hashagg = off;
SET
postgres=# EXPLAIN SELECT MAX(DEGREE) FROM SCORE GROUP BY CNO;;
QUERY PLAN
-----------------------------------------------------------------------
GroupAggregate (cost=819.39..894.44 rows=5 width=8)
Group Key: cno
-> Sort (cost=819.39..844.39 rows=10000 width=8)
Sort Key: cno
-> Seq Scan on score (cost=0.00..155.00 rows=10000 width=8)
(5 rows)
简单调整并行执行计划
所谓并行度就是一个任务同时需要几个并行的后台进程进行处理,用户可以在创建表的时候指定 parallel_workers 参数,例如有 SQL 语句:
CREATE TABLE TEST_A(a INT) WITH (PARALLEL_WORKERS=100);
就可以指定一个并行度是 100 的表,但这并不代表对这个表进行扫描的时候一定会产生一个并行度是 100 的并行扫描路径。一方面非并行路径代价可能低于并行路径的代价,这时就会选择非并行路径;另一方面 PostgreSQL 数据库对并行度也进行了限制,每个查询都有过大的并行度对数据库的整体性能也会带来不利影响。
PostgreSQL 会自适应地计算一个查询需要多少个 worker 来同时工作,它综合考虑了一个表进行顺序扫描所需要的页面数(heap_pages)、进行索引扫描所需要的页面数(index_pages)。另外,PostgreSQL 数据库还增加了几个 GUC 参数来提高并行度设置的灵活性,这样用户就可以自己调节这些参数,根据当前的硬件环境来配置自己的并行度。

如果对一个表进行扫描,如果 heap_pages < min_parallel_table_scan_size 或者 index_pages < min_parallel_index_scan_size,就不启用并行查询。
另外基于 min_parallel_table_scan_size 和 min_parallel_index_scan_size 可以获得一个并行度的参考值:
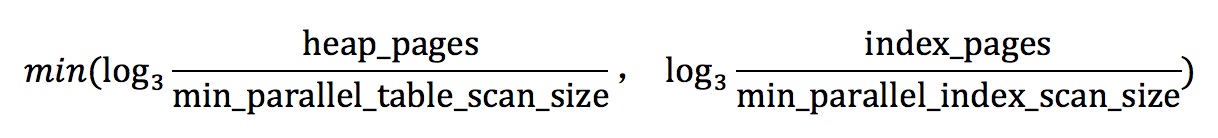
当然,这个并行度还不能超过 max_parallel_workers_per_gather 参数设置的值,如果超过了 max_parallel_workers_per_gather,那么就取 max_parallel_workers_per_gather 的值作为并行度。
另外还有一个 max_parallel_workers 参数,用来控制在同一时间最多有多少并行的进程。
因为我们目前的示例中的数据量都比较小,所以都没有出现并行执行计划的情况,当然 PostgreSQL 也给我们提供了 GUC 参数 force_parallel_mode 来强制增加一个 gather 结点:
postgres=# set force_parallel_mode = on;
SET
postgres=# EXPLAIN SELECT * FROM STUDENT;
QUERY PLAN
--------------------------------------------------------------------
Gather (cost=1000.00..2155.00 rows=10000 width=12)
Workers Planned: 1
Single Copy: true
-> Seq Scan on student (cost=0.00..155.00 rows=10000 width=12)
(4 rows)
小结
了解 SQL 语句的执行过程,能够对执行计划进行解读、数量的调整,是学习优化器的基本要素之一,也是最常用的基本内容。通过这些内容可以反向地理解 PostgreSQL 优化器的实现。实际上,大部分数据库的优化器实现都大同小异,理解 PostgreSQL 的优化器之后,期待各位能举一反三、触类旁通,那么就不虚此行了。