楔子
在上一章中,我们介绍了Python虚拟机中常见的字节码指令。但我们的流程都是从上往下顺序执行的,在执行的过程中没有任何变化,但是显然这是不够的,因为怎么能没有流程控制呢。下面我们来看看Python所提供的流程控制手段,其中也包括异常检测机制。
Python虚拟机中的if控制流
if字节码
if语句算是最简单也是最常用的控制流语句,那么它的字节码是怎么样的呢?当然我们这里的if语句指的是if、elif、elif...、else整体,里面的if、某个elif或者else叫做该if语句的分支。
s = """
gender = "男"
if gender == "男":
print("nice muscle")
elif gender == "女":
print("白い肌")
else:
print("秀吉")
"""
if __name__ == '__main__':
import dis
dis.dis(compile(s, "man", "exec"))
反编译得到的字节码指令比较多,我们来慢慢分析。
注意:到了现在,相信对字节码指令都已经熟悉了,因此之前说过的指令我们就不详细展开说了,只会简单提一下。
2 0 LOAD_CONST 0 ('男') //加载字符串常量
2 STORE_NAME 0 (gender)//建立符号和对象的映射关系
4 4 LOAD_NAME 0 (gender)//加载变量gender
6 LOAD_CONST 0 ('男')//加载字符串常量
8 COMPARE_OP 2 (==)//将gender和"男"进行==操作
10 POP_JUMP_IF_FALSE 22//这里的22表示如果为False, 就跳转到字节码偏移量、或者字节码的索引为22的地方
//显然是下面的22 LOAD_NAME 0 (gender), 即:该if下面的elif
5 12 LOAD_NAME 1 (print) //如果gender == "男"成立, 那么不会跳转, 直接往下执行, 加载符号print
14 LOAD_CONST 1 ('nice muscle')//加载字符串常量
16 CALL_FUNCTION 1//函数调用
18 POP_TOP //将函数返回值从栈顶弹出去
20 JUMP_FORWARD 26 (to 48)//if语句只会执行一个分支, 一旦执行了某个分支, 整个if语句就结束了
//所以跳转到字节码偏移量为48的位置, 这里的22就表示相对于当前位置向前跳转了多少
6 >> 22 LOAD_NAME 0 (gender) //显然这是elif的分支, 加载变量gender
24 LOAD_CONST 2 ('女')//加载字符串常量"女"
26 COMPARE_OP 2 (==)//将gender和"女"进行==判断
28 POP_JUMP_IF_FALSE 40//如果不成立就跳转到字节码偏移量为40的地方, 显然是elif下面的else
//如果elif下面还有elif, 那么就跳转到下一个elif, 总之就是一个分支一个分支的往下跳转
7 30 LOAD_NAME 1 (print)//走到这里说明gender == "女"成立, 加载变量print
32 LOAD_CONST 3 ('白い肌')//加载字符串常量"白い肌"
34 CALL_FUNCTION 1//函数调用, 参数为1个
36 POP_TOP//将函数返回值从栈顶弹出去
38 JUMP_FORWARD 8 (to 48)//整个if语句结束, 还是跳转到字节码偏移量为48的位置
//这里参数是8, 所以if的跳转是采用相对跳跃, 分支不同跳跃的指令数也不同
9 >> 40 LOAD_NAME 1 (print) //走到这里说明执行的是else分支, 加载符号print
42 LOAD_CONST 4 ('秀吉')//加载字符串常量"秀吉"
44 CALL_FUNCTION 1//函数调用
46 POP_TOP//将函数返回值从栈顶弹出去,如果是执行else分支并且执行完毕, 显然就不需要再跳转了,
//因为else分支位于整个if语句的最后面
>> 48 LOAD_CONST 5 (None)//这里便是整个if语句结束后的第一条指令, 加载常量None
50 RETURN_VALUE//返回
我们看到字节码中 "源代码行号" 和 "字节码偏移量" 之间有几个>>这样的符号,这是什么呢?仔细看一下应该就知道,这显然就是if语句中的每一个分支开始的地方,当然最后的>>是返回值。
但是经过分析,我们发现整个if语句的字节码指令还是很简单的。从上到下执行分支,如果某个分支成立,就执行该分支的代码,执行完毕后直接跳转到整个if语句下面的第一条指令;分支不成立那么就跳转到下一个分支。
核心指令就在于COMPARE_OP、POP_JUMP_IF_FALSE和JUMP_FORWARD,从结构上我们不难分析:
COMPARE_OP: 进行比较操作POP_JUMP_IF_FALSE: 跳转到下一个分支JUMP_FORWARD:跳转到整个if语句结束后的第一条指令
我们首先分析COMPARE_OP,我们看到COMPARE_OP后面也是有参数的,比如 8 COMPARE_OP 2 (==),显然oparg`(字节码指令参数)`就是2,那么这个2代表啥呢?其实想都不用想,肯定代表的是==,因为都已经告诉我们了。
// object.h
/* Rich comparison opcodes */
#define Py_LT 0 //小于
#define Py_LE 1 //小于等于
#define Py_EQ 2 //等于
#define Py_NE 3 //不等于
#define Py_GT 4 //大于
#define Py_GE 5 //大于等于
//opcode.h
enum cmp_op {PyCmp_LT=Py_LT, PyCmp_LE=Py_LE, PyCmp_EQ=Py_EQ, PyCmp_NE=Py_NE,
PyCmp_GT=Py_GT, PyCmp_GE=Py_GE, PyCmp_IN, PyCmp_NOT_IN,
PyCmp_IS, PyCmp_IS_NOT, PyCmp_EXC_MATCH, PyCmp_BAD};
下面我们来看看,虚拟机中是如何进行比较操作的。另外本章中如果没有指定源码位置,那么默认是在Python/ceval.c里面
static PyObject *
cmp_outcome(int op, PyObject *v, PyObject *w)
{
int res = 0;
switch (op) {
//python中的is, 在C的层面直接判断两个指针是否相等即可
case PyCmp_IS:
res = (v == w);
break;
//python中的is not, , 在C的层面直接判断两个指针是否不相等即可
case PyCmp_IS_NOT:
res = (v != w);
break;
//python中的in, 调用PySequence_Contains
case PyCmp_IN:
res = PySequence_Contains(w, v);
if (res < 0)
return NULL;
break;
//python中的not in, 调用PySequence_Contains再取反
case PyCmp_NOT_IN:
res = PySequence_Contains(w, v);
if (res < 0)
return NULL;
res = !res;
break;
//python中的异常
case PyCmp_EXC_MATCH:
//这里判断给定的类是不是异常类, 比如我们肯定不能except int as e, 异常类一定要继承BaseException
//如果是元组的话, 那么元组里面都要是异常类
if (PyTuple_Check(w)) {
Py_ssize_t i, length;
length = PyTuple_Size(w);
for (i = 0; i < length; i += 1) {
PyObject *exc = PyTuple_GET_ITEM(w, i);
if (!PyExceptionClass_Check(exc)) {
PyErr_SetString(PyExc_TypeError,
CANNOT_CATCH_MSG);
return NULL;
}
}
}
else {
if (!PyExceptionClass_Check(w)) {
PyErr_SetString(PyExc_TypeError,
CANNOT_CATCH_MSG);
return NULL;
}
}
//判断指定的异常能否捕获相应的错误
res = PyErr_GivenExceptionMatches(v, w);
break;
default:
//然后进行比较操作, 传入两个对象以及操作符, 即上面的Py_LT、Py_LE...之一
return PyObject_RichCompare(v, w, op);
}
//Py_True和Py_False就相当于Python中的True和False, 本质上是一个PyLongObject
//根据res的结果返回True和False
v = res ? Py_True : Py_False;
Py_INCREF(v);
return v;
}
里面的比较函数PyObject_RichCompare很重要,我们来看一下,该函数位于Object/object.c中。
//首先有一个PyObject_RichCompareBool, 它是用来判断两个对象是否相等或不等的
int
PyObject_RichCompareBool(PyObject *v, PyObject *w, int op)
{
PyObject *res;
int ok;
//如果v和w相等的话, 说明这两个变量指向同一个对象
if (v == w) {
//那么如果op是==, 显然返回True
if (op == Py_EQ)
return 1;
//如果op是!=, 显然返回False
else if (op == Py_NE)
return 0;
}
//可能有人问如果我们重写了__eq__怎么办? 所以这个方法只适用于内建的类的实例对象
//如果是我们自定义的类会直接调用这里的PyObject_RichCompare
//另外我们看到即便是内置的类的实例对象, 如果两个对象不相等, 或者相等、但是op不是==和!=的时候也会走这里的PyObject_RichCompare
res = PyObject_RichCompare(v, w, op);
//通过PyObject_RichCompare进行比较
if (res == NULL)
return -1;
//如果返回的是布尔值, 那么判断是否和Py_True相等, 返回的是True那么比较的结果也是True, 否则是False
if (PyBool_Check(res))
ok = (res == Py_True);
else
//返回的不是布尔值, 那么调用PyObject_IsTrue, 显然这相当于Python中的bool(res)
//不是0的整数、长度不为0的字符串、元组、列表等等也是True
ok = PyObject_IsTrue(res);
Py_DECREF(res);
//返回
return ok;
}
//重点来了, 我们来看看PyObject_RichCompare
PyObject *
PyObject_RichCompare(PyObject *v, PyObject *w, int op)
{
PyObject *res;
//首先会对op进行判断, 要确保Py_LT <= op <= Py_GE, 即0 <= op <= 5, 要保证op是几个操作符中的一个
assert(Py_LT <= op && op <= Py_GE);
//首先v和w不能是C的空指针, 要确保它们都指向一个具体的PyObject, 但是说实话底层的这些检测我们在Python的层面基本不会遇到
if (v == NULL || w == NULL) {
if (!PyErr_Occurred())
PyErr_BadInternalCall();
return NULL;
}
//所以核心是下面的do_richcompare, 但是在do_richcompare之前我们看到这里调用了Py_EnterRecursiveCall
//这和函数和递归有关, 比如我们在__eq__中又对self使用了==, 那么会不断调用__eq__, 这是会无限递归的
if (Py_EnterRecursiveCall(" in comparison"))
//所以Py_EnterRecursiveCall是让解释器追踪递归的深度的
//如果递归层数过多, 超过了指定限制(默认是999, 可以通过sys.getrecursionlimit()查看), 那么能够及时抛出异常, 从递归中摆脱出来
return NULL;
//调用do_richcompare, 还是这三个参数, 得到比较的结果
res = do_richcompare(v, w, op);
//离开递归调用
Py_LeaveRecursiveCall();
//返回res, 执行PyObject_RichCompareBool中下面的逻辑
return res;
}
//所以我们看到核心其实是do_richcompare, 我们需要继续往下看
static PyObject *
do_richcompare(PyObject *v, PyObject *w, int op)
{
richcmpfunc f; //富比较函数
PyObject *res; //比较结果
int checked_reverse_op = 0;
//如果type(v)和type(w)不一样 && type(w)是type(v)的子类 && type(w)中定义了tp_richcompare
if (v->ob_type != w->ob_type &&
PyType_IsSubtype(w->ob_type, v->ob_type) &&
(f = w->ob_type->tp_richcompare) != NULL) {
checked_reverse_op = 1;
//那么直接调用type(w)的to_richcompare进行比较
res = (*f)(w, v, _Py_SwappedOp[op]);
if (res != Py_NotImplemented)
return res;
Py_DECREF(res);
}
//type(v)和type(w)不同, 或者 type(w) 不是 type(v) 的子类, 或者type(w)中没有定义tp_richcompare
//如果type(v)定义了tp_richcompare
if ((f = v->ob_type->tp_richcompare) != NULL) {
//调用type(v)的tp_richcompare方法
res = (*f)(v, w, op);
if (res != Py_NotImplemented)
return res;
Py_DECREF(res);
}
//type(w) 不是 type(v) 的子类 && type(v)中没有定义tp_richcompare && type(w)中定义了tp_richcompare
if (!checked_reverse_op && (f = w->ob_type->tp_richcompare) != NULL) {
//那么执行w的tp_richcompare
res = (*f)(w, v, _Py_SwappedOp[op]);
if (res != Py_NotImplemented)
return res;
Py_DECREF(res);
}
//所以以上三种情况就相当于: 如果type(w) 是 type(v) 的子类, 那么优先调用w的tp_richcompare
//否则,type(v) 和 type(w) 中谁的tp_richcompare不为空就调用谁的
//如果都没有那么就走下面的逻辑了
switch (op) {
//直接比较两者是否相等
case Py_EQ:
res = (v == w) ? Py_True : Py_False;
break;
//比较两者是否不等
case Py_NE:
res = (v != w) ? Py_True : Py_False;
break;
//显然此时的两个对象只能判断相等或者不等, 如果是比大小那么显然是报错的, 下面的信息你一定很熟悉
default:
PyErr_Format(PyExc_TypeError,
"'%s' not supported between instances of '%.100s' and '%.100s'",
opstrings[op],
v->ob_type->tp_name,
w->ob_type->tp_name);
return NULL;
}
Py_INCREF(res);
//返回
return res;
}
另外,这里面又出现了tp_richcompare,如果我们自定义的类没有重写的话,那么默认调用的是基类object的tp_richcompare,包括内置的类也是调用object的tp_richcompare,有兴趣可以看一下。
然后我们再来看看POP_JUMP_IF_FALSE
2 0 LOAD_CONST 0 ('男')
2 STORE_NAME 0 (gender)
4 4 LOAD_NAME 0 (gender)
6 LOAD_CONST 0 ('男')
8 COMPARE_OP 2 (==)
10 POP_JUMP_IF_FALSE 22
5 12 LOAD_NAME 1 (print)
14 LOAD_CONST 1 ('nice muscle')
16 CALL_FUNCTION 1
18 POP_TOP
20 JUMP_FORWARD 26 (to 48)
6 >> 22 LOAD_NAME 0 (gender)
24 LOAD_CONST 2 ('女')
26 COMPARE_OP 2 (==)
28 POP_JUMP_IF_FALSE 40
7 30 LOAD_NAME 1 (print)
32 LOAD_CONST 3 ('白い肌')
34 CALL_FUNCTION 1
36 POP_TOP
38 JUMP_FORWARD 8 (to 48)
9 >> 40 LOAD_NAME 1 (print)
42 LOAD_CONST 4 ('秀吉')
44 CALL_FUNCTION 1
46 POP_TOP
>> 48 LOAD_CONST 5 (None)
50 RETURN_VALUE
我们看一下10 POP_JUMP_IF_FALSE 22这条字节码,这表是if语句不成立,那么会跳转到字节码偏移量为22的位置,所以这里有一个指令跳跃的动作。那么Python虚拟机是如何完成指令跳跃的呢?关键就在于一个名为 predict 的宏里面。
#if defined(DYNAMIC_EXECUTION_PROFILE) || USE_COMPUTED_GOTOS
#define PREDICT(op) if (0) goto PRED_##op
#else
#define PREDICT(op)
do{
_Py_CODEUNIT word = *next_instr;
opcode = _Py_OPCODE(word);
if (opcode == op){
oparg = _Py_OPARG(word);
next_instr++;
goto PRED_##op;
}
} while(0)
#endif
#define PREDICTED(op) PRED_##op:
在Python中,有一些字节码指令通常都是按照顺序出现的,通过上一个字节码指令直接预测下一个字节码指令是可能的。比如COMPARE_OP的后面通常都会紧跟着POP_JUMP_IF_TRUE或者POP_JUMP_IF_FALSE,这在上面的字节码中可以很清晰的看到。
为什么要有这样的一个预测功能呢?因为当字节码之间的指令搭配出现的概率非常高时,如果预测成功,能够省去很多无谓的操作,使得执行效率大幅提高。我们可以看到, PREDICTED(POP_JUMP_IF_FALSE);实际上就是检查下一条待处理的字节码是否是POP_JUMP_IF_FALSE。如果是,那么程序会直接跳转到PRED_POP_JUMP_IF_FALSE那里,如果将COMPARE_OP这个宏展开,可以看得更加清晰。
if (*next_instr == POP_JUMP_IF_FALSE)
goto PRED_POP_JUMP_IF_FALSE;
if (*next_instr == POP_JUMP_IF_TRUE)
goto PRED_POP_JUMP_IF_TRUE
但是问题又来了,PRED_POP_JUMP_IF_TRUE和PRED_POP_JUMP_IF_FALSE这些标识在哪里呢?我们知道指令跳跃的目的是为了绕过一些无谓的操作,直接进入POP_JUMP_IF_TRUE或者POP_JUMP_IF_FALSE指令对应的case语句之前。
首先if gender == "男"这条字节码序列中,存在POP_JUMP_IF_FALSE指令,那么在COMPARE_OP指令的实现代码的最后,将执行goto PRED_POP_JUMP_IF_FALSE;,而显然这句代码要在POP_JUMP_IF_FALSE之前执行。
PREDICTED(POP_JUMP_IF_FALSE);
TARGET(POP_JUMP_IF_FALSE) {
//取出之前比较的结果。
PyObject *cond = POP();
int err;
//比较结果为True,顺序执行
if (cond == Py_True) {
Py_DECREF(cond);
FAST_DISPATCH();
}
//比较结果为False,进行跳转
if (cond == Py_False) {
Py_DECREF(cond);
JUMPTO(oparg);
FAST_DISPATCH();
}
//异常检测
err = PyObject_IsTrue(cond);
Py_DECREF(cond);
if (err > 0)
;
else if (err == 0)
JUMPTO(oparg);
else
goto error;
DISPATCH();
}
我们看到这里的调用跳转使用的JUMPTO,在for循环中我们还会见到,这是一个宏。
#define JUMPTO(x) (next_instr = first_instr + (x) / sizeof(_Py_CODEUNIT))
/*
_Py_CODEUNIT 是 uint16_t 的别名 typedef uint16_t _Py_CODEUNIT,占两个字节;
从名字也能看出这表示字节码的指令单元, 一条指令两个字节, 所以字节码指令对应的偏移量是0 2 4 6 8..., 每次增加2
另外这里的first_str指向字节码偏移量为0的位置, 也就是第一条指令
next_str表示在first_str基础上跳转之后的指令, 所以如果x是12的话, 那么next_str = 0 + 6, 显然就是第7条指令
*/
Python虚拟机中的for循环控制流
我们在if语句中已经见识了最基本的控制,但是我们发现if里面只能向前,不管是哪个分支,都是通过JUMP_FORWARD。下面介绍for循环,我们会见到指令时可以回退的。但是在if语句的分支中,我们看到无论哪个分支、其指令的跳跃距离通常都是当前指令与目标指令的距离,相当于向前跳了多少步。那么指令回退时,是不是相当于向后跳了多少步呢?带着疑问,我们来往下看。
for字节码
我们来看看一个简单的for循环的字节码。
s = """
lst = [1, 2]
for item in lst:
print(item)
"""
if __name__ == '__main__':
import dis
dis.dis(compile(s, "for", "exec"))
2 0 LOAD_CONST 0 (1) //加载常量1
2 LOAD_CONST 1 (2) //加载常量2
4 BUILD_LIST 2 //构建PyListObject对象, 元素个数为2
6 STORE_NAME 0 (lst) //使用符号"lst"保存
3 8 LOAD_NAME 0 (lst) //加载变量lst
10 GET_ITER //获取对应的迭代器
>> 12 FOR_ITER 12 (to 26)//开始for循环, 循环结束跳转到字节码偏移量为26的地方
14 STORE_NAME 1 (item) //将元素迭代出来, 使用符号"item"保存
4 16 LOAD_NAME 2 (print) //加载函数print
18 LOAD_NAME 1 (item) //加载变量item
20 CALL_FUNCTION 1 //函数调用
22 POP_TOP //从栈顶弹出print函数的返回值, 这里是None
24 JUMP_ABSOLUTE 12 //for循环遍历一圈之后, 继续跳转回去, 遍历下一圈, 直到结束
>> 26 LOAD_CONST 2 (None) //走到这里for循环就结束了, 加载常量None, 然后返回
28 RETURN_VALUE
我们再来详细分析一下上面的指令:
lst = [1, 2]我们就不分析了,当 for item in lst:的时候,肯定首先要找到lst,所以指令是LOAD_NAME是没问题的。但是下面出现了GET_ITER,从字面上我们知道这是获取迭代器,其实即使不从源码的角度,我相信有的小伙伴对于for循环的机制也不是很了解。实际上我们for循环遍历一个对象的时候,首先要满足后面的对象是一个可迭代对象,遍历这个对象的时候,会先调用这个对象的__iter__方法,把它变成一个迭代器。然后不断地调用这个迭代器的__next__方法,一步一步将里面的值全部迭代出来,然后再进行一次迭代出现StopIteration异常,for循环捕捉,然后退出。注意:for item in lst是先将lst对应的迭代器中的元素迭代出来,然后交给变量item。所以字节码中先是
12 FOR_ITER,然后才是14 STORE_NAME。因此10个元素的迭代器,是需要迭代11次才能结束的,因为Python不知道迭代10次就能结束,它需要再迭代一次发现没有元素可以迭代、从而抛出StopIteration异常、再被for循环捕捉之后才能结束。所以for循环后面如果跟的是一个迭代器,那么直接调用__next__方法,如果是可迭代对象,会先调用其内部的__iter__方法将其变成一个迭代器,然后再调用该迭代器的__next__方法。
from typing import Iterable, Iterator
lst = [1, 2]
# 列表、字符串、元组、字典、集合等等都是可迭代对象
# 但它们不是迭代器
print(isinstance(lst, Iterable)) # True
print(isinstance(lst, Iterator)) # False
# 需要调用__iter__之后才是一个迭代器, 当然迭代器也是可迭代对象
print(isinstance(iter(lst), Iterable)) # True
print(isinstance(iter(lst), Iterator)) # True
然后我们看到 24 JUMP_ABSOLUTE,它是跳转到字节码偏移量为12、也就是FOR_ITER的位置,并没有跳到GET_ITER那里,所以for循环在遍历的时候只会创建一次迭代器。
lst = [1, 2]
lst_iter = iter(lst)
for item in lst_iter:
print(item, end=" ") # 1 2
print()
for item in iter(lst):
print(item, end=" ") # 1 2
# 我们看到结果是一样的, for item in iter(lst)和for item in lst是等价的
# 都会先创建迭代器, 并且只创建一次, 然后遍历这个迭代器
list迭代器
Python虚拟机通过LOAD_NAME 0 (lst)指令,将刚创建的PyListObject对象压入运行时栈。然后再通过GET_ITER指令来获取PyListObject对象的迭代器。
case TARGET(GET_ITER): {
/* before: [obj]; after [getiter(obj)] */
//从运行时栈获取PyListObject对象
PyObject *iterable = TOP();
//获取该PyListObject对象的iterator
PyObject *iter = PyObject_GetIter(iterable);
Py_DECREF(iterable);
//将iterator压入栈中, 设置在栈顶
SET_TOP(iter);
if (iter == NULL)
goto error;
PREDICT(FOR_ITER);
PREDICT(CALL_FUNCTION);
DISPATCH();
}
我们看到获取迭代器是调用了PyObject_GetIter函数,我们看看这个函数长什么样子。
//Objects/object.h
typedef PyObject *(*getiterfunc) (PyObject *);
//Objects/abstract.c
PyObject *
PyObject_GetIter(PyObject *o)
{
//获取对象的类型
PyTypeObject *t = o->ob_type;
//一个函数指针, 接收一个PyObject *, 返回一个PyObject *
getiterfunc f;
//调用类型对象的tp_iter
f = t->tp_iter;
if (f == NULL) {
//如果f是NULL, 并且还不是序列型对象, 那么直接抛出异常, 'xxx' object is not iterable
if (PySequence_Check(o))
return PySeqIter_New(o);
return type_error("'%.200s' object is not iterable", o);
}
else {
//调用tp_iter, 传入对象获取迭代器。我们获取迭代器是通过iter(lst)或者lst.__iter__()
//但是在底层相当于list.__iter__(lst), 所以"实例.方法(*args, **kwargs)"等价于"类.函数(self, *args, **kargs)"
PyObject *res = (*f)(o);
//如果res不为空、并且还不是迭代器
if (res != NULL && !PyIter_Check(res)) {
//那么报错TypeError, __iter__返回了一个非迭代器
PyErr_Format(PyExc_TypeError,
"iter() returned non-iterator "
"of type '%.100s'",
res->ob_type->tp_name);
Py_DECREF(res);
res = NULL;
}
return res;
}
}
因此我们可以看到,PyObject_GetIter是调用对象对应的类型对象中的tp_iter操作来获取与对象关联的迭代器的。我们说Python一切皆对象,那么这些迭代器也是一个实实在在的对象,那么也必然会有对应的类型对象,因为Python中对象对应的结构体都继承了PyObject,所以任何一个对象都有引用计数和类型。
//listobject.c
typedef struct {
PyObject_HEAD //迭代器显然是不可变对象
Py_ssize_t it_index; //迭代的元素的索引, 初始为0, 每迭代1个元素it_index就加1
PyListObject *it_seq; //指向一个PyListObject对象, 显然迭代的就是这个PyListObject对象里面的元素, 当元素迭代完毕之后it_seq会被设置成NULL
} listiterobject;
PyTypeObject PyListIter_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"list_iterator", /* tp_name */
...
};
然后PyList_Type中tp_iter域被设置为list_iter,显然这是PyObject_GetIter中的那个f,而这也正是创建迭代器的关键所在。
//listobject.c
static PyObject *
list_iter(PyObject *seq)
{
//列表对应的迭代器的指针
listiterobject *it;
//如果seq不是列表,则报错
if (!PyList_Check(seq)) {
PyErr_BadInternalCall();
return NULL;
}
//为listiterobject申请空间
it = PyObject_GC_New(listiterobject, &PyListIter_Type);
if (it == NULL)
return NULL;
//迭代器的索引, 用来遍历列表的, 初始为0
it->it_index = 0;
Py_INCREF(seq);
//这里的seq就是之前的PyListObject对象
it->it_seq = (PyListObject *)seq;
_PyObject_GC_TRACK(it);
return (PyObject *)it;
}
可以看到PyListObject的迭代器对象只是对PyListObject对象做了一个简单的包装,在迭代器中,维护了迭代是要访问的元素在PyListObject对象中的索引:it_index。通过这个索引,listiterobject对象就可以实现PyListObject的遍历。
所以我们看到迭代器的实现真的很简单,创建谁的迭代器就对谁进行一层包装罢了,迭代器内部有一个索引。每迭代1次索引就加1,迭代完毕之后将指针设置为NULL,然后再迭代就抛出异常。
所以任何一个列表对应的迭代器的内存大小都是32字节,PyObject是16字节,再加上一个Py_ssize_t和一个指针,总共32字节。
s = "夏色祭" * 1000
print(s.__sizeof__(), iter(s).__sizeof__()) # 6074 32
lst = [1, 2, 3] * 1000
print(lst.__sizeof__(), iter(lst).__sizeof__()) # 24040 32
tpl = (1, 2, 3) * 1000
print(tpl.__sizeof__(), iter(tpl).__sizeof__()) # 24024 32
# 不光是列表, 包括字符串、元组也是一样的, 都是32字节
但是字典有些特殊,因为它的底层是通过哈希表存储的,它需要额外维护一些信息。
//Objects/dictobject.c
typedef struct {
PyObject_HEAD
PyDictObject *di_dict; /* Set to NULL when iterator is exhausted */
Py_ssize_t di_used;
Py_ssize_t di_pos;
PyObject* di_result; /* reusable result tuple for iteritems */
Py_ssize_t len;
} dictiterobject;
所以字典对应的迭代器是56字节,集合对应的迭代器则是48字节,关于集合可以去源码中查看,看看为什么会占48字节。
d = dict.fromkeys(range(100000), None)
print(d.__sizeof__(), iter(d).__sizeof__()) # 5242952 56
s = set(range(100000))
print(s.__sizeof__(), iter(s).__sizeof__()) # 4194504 48
在指令GET_ITER完成之后,Python虚拟机开始了FOR_ITER指令的预测动作,如你所知,这样的预测动作是为了提高执行的效率。
迭代控制
源代码中的for循环,在虚拟机层面也一定对应着一个相应的循环控制结构。因为无论进行怎样的变换,都不可能在虚拟机层面利用顺序结构来实现源码层面上的循环结构,这也可以看成是程序的拓扑不变性。显然正如我们刚才分析的,当创建完迭代器之后,就正式开始进入for循环了,没错就是从FOR ITER开始,进入了Python虚拟机层面上的for循环。
case TARGET(FOR_ITER): {
//指令预测
PREDICTED(FOR_ITER);
/* before: [iter]; after: [iter, iter()] *or* [] */
/* 从栈顶获取iterator对象 */
PyObject *iter = TOP();
//调用迭代器类型对象的tp_iternext方法、传入迭代器, 迭代出当前索引对应的元素, 然后索引+1, 然后下次迭代下一个元素
PyObject *next = (*iter->ob_type->tp_iternext)(iter);
//如果next不为NULL, 那么将元素压入运行时栈, 显然要赋值给for循环的变量了
if (next != NULL) {
PUSH(next);
PREDICT(STORE_FAST);
PREDICT(UNPACK_SEQUENCE);
DISPATCH();
}
if (_PyErr_Occurred(tstate)) {
//如果出现异常、并且没有捕获到, 那么报错
if (!_PyErr_ExceptionMatches(tstate, PyExc_StopIteration)) {
goto error;
}
//tstate指的是线程对象, 我们会后面分析, 这里与回溯栈相关
else if (tstate->c_tracefunc != NULL) {
call_exc_trace(tstate->c_tracefunc, tstate->c_traceobj, tstate, f);
}
_PyErr_Clear(tstate);
}
/* 走到这里说明本次迭代正常结束
*/
STACK_SHRINK(1);
Py_DECREF(iter);
JUMPBY(oparg);
PREDICT(POP_BLOCK);
DISPATCH();
}
FOR_ITER的指令代码会首先从运行时栈中获得PyListObject对象的迭代器,然后调用迭代器的tp_iternext开始进行迭代,迭代出元素的同时将索引+1。如果抵达了迭代器的结束位置,那么tp_iternext将返回NULL,这个结果预示着遍历结束。
FOR_ITER的指令代码会检查tp_iternext的返回结果,如果得到的是一个有效的元素(next!=NULL),那么将获得的这个元素压入到运行时栈中,并开始进行一系列的字节码预测动作。在我们当前的例子中,显然会预测失败,因此会执行STORE_NAME。那么如何获取迭代器的下一个元素呢?
//listobject.c
static PyObject *
listiter_next(listiterobject *it)
{
PyListObject *seq;
PyObject *item;
assert(it != NULL);
//seq:显然是获取迭代器对象的PyListObject对象的指针
seq = it->it_seq;
if (seq == NULL)
return NULL;
//一定是一个PyListObject对象
assert(PyList_Check(seq));
//当前的索引小于列表的长度、即当前索引小于等于最大索引
if (it->it_index < PyList_GET_SIZE(seq)) {
//获得索引为it_index的对应元素
item = PyList_GET_ITEM(seq, it->it_index);
//调整index, 使其自增1, 然后下一次遍历得到下一个元素
++it->it_index;
//增加引用计数、返回
Py_INCREF(item);
return item;
}
//迭代完毕之后,设置为NULL,所以迭代器只能够顺序迭代一次
it->it_seq = NULL;
Py_DECREF(seq);
return NULL;
}
之后python虚拟机将沿着字节码的顺序一条一条的执行下去,从而完成输出的动作。但是我们知道,for循环中肯定会有指令回退的动作,我们之前从字节码中也看到了,for循环遍历一次之后,会再次跳转到FOR_ITER,而跳转所使用的指令就是JUMP_ABSOLUTE。
case TARGET(JUMP_ABSOLUTE): {
PREDICTED(JUMP_ABSOLUTE);
//显然这里的oparg表示字节码偏移量, 表示直接跳转到偏移量为oparg的位置上
JUMPTO(oparg);
#if FAST_LOOPS
FAST_DISPATCH();
#else
DISPATCH();
#endif
}
#define JUMPTO(x) (next_instr = first_instr + (x) / sizeof(_Py_CODEUNIT))
可以看到和if不一样,for循环使用的是绝对跳跃。JUMP_ABSOLUTE是强制设置next_instr的值,将next_instr设定到距离f->f_code->co_code开始地址的某一特定偏移的位置。这个偏移的量由JUMP_ABSOLUTE的指令参数决定,所以这条参数就成了for循环中指令回退动作的最关键的一点。
2 0 LOAD_CONST 0 (1)
2 LOAD_CONST 1 (2)
4 BUILD_LIST 2
6 STORE_NAME 0 (lst)
3 8 LOAD_NAME 0 (lst)
10 GET_ITER
>> 12 FOR_ITER 12 (to 26)
14 STORE_NAME 1 (item)
4 16 LOAD_NAME 2 (print)
18 LOAD_NAME 1 (item)
20 CALL_FUNCTION 1
22 POP_TOP
24 JUMP_ABSOLUTE 12
>> 26 LOAD_CONST 2 (None)
28 RETURN_VALUE
我们看到JUMP_ABSOLUTE的参数是12,next_str = 0 + 12 / 2 = 6,表示跳转到字节码偏移量为12、或者说第7条指令的位置上,也就是12 FOR_ITER这条指令,那么Python虚拟机的下一步动作就是执行FOR_ITER指令,即通过PyListObject对象的迭代器获取PyListObject对象中的元素,然后依次向前,执行输出,遇到JUMP_ABSOLUTE再跳转回去。因此FOR_ITER指令和JUMP_ABSOLUTE指令之间构造出了一个循环结构,这个循环结构正是对应源码中的for循环结构。
但是我们发现,FOR_ITER后面跟了一个参数,这里是12,可是目前为止我们并没有看到有地方使用了这个12啊,那么它代表啥含义呢。其实,聪明如你肯定能猜到,因为从后面(to 26)也能看到,这是用于终止迭代的。表示从当前位置跳跃12个偏移量、等于24,或者在当前指令的基础上再跳转6条指令,也就是到达26 LOAD_CONST的位置。
终止迭代
"天下没有不散的宴席",for循环也是要退出的,不用想这个退出的动作只能落在FOR_ITER的身上。在FOR_ITER指令执行的过程中,如果通过PyListObject对象的迭代器获取的下一个元素不是有效的元素(会是NULL),这就意味着迭代结束了。这个结果将直接导致Python虚拟机会将迭代器对象从运行时栈中弹出,同时执行一个JUMPBY的动作,向前跳跃,在字节码的层面上是向下,就是字节码偏移量增大的方向。
#define JUMPBY(x) (next_instr += (x) / sizeof(_Py_CODEUNIT))
case TARGET(FOR_ITER): {
/*
...
...
...
*/
//走到这里说明循环结束了
STACK_SHRINK(1);
Py_DECREF(iter);
//直接进行跳转
JUMPBY(oparg);
PREDICT(POP_BLOCK);
DISPATCH();
}
python虚拟机中的while循环控制结构
会了if、for,那么再来看while就简单了。不仅如此,我们还要分析两个关键字:break、continue,当然goto就别想了。
s = """
a = 0
while a < 10:
a += 1
if a == 5:
continue
if a == 7:
break
print(a)
"""
if __name__ == '__main__':
import dis
dis.dis(compile(s, "while", "exec"))
指令方面,while和for有很多是类似的。
2 0 LOAD_CONST 0 (0) //加载常量0
2 STORE_NAME 0 (a) //使用变量a存储
3 >> 4 LOAD_NAME 0 (a) //进入while循环了, 首先是a < 10, 加载变量a
6 LOAD_CONST 1 (10) //加载常量10
8 COMPARE_OP 0 (<) //比较操作
10 POP_JUMP_IF_FALSE 50 //为False直接结束循环, 跳转到字节码偏移量为50的位置, 也就是第26条指令
4 12 LOAD_NAME 0 (a) //这里是进入循环了, 加载变量a
14 LOAD_CONST 2 (1) //加载常量1
16 INPLACE_ADD //执行a += 1操作, 这里相当于先执行了a + 1
18 STORE_NAME 0 (a) //然后在重新让变量a指向相加之后的结果
5 20 LOAD_NAME 0 (a) //进入a == 5, 加载变量a
22 LOAD_CONST 3 (5) //加载常量5
24 COMPARE_OP 2 (==) //比较操作
26 POP_JUMP_IF_FALSE 30 //如果为False, 那么直接跳转到偏移量为30的位置, 也就是当前if语句的下一条指令
6 28 JUMP_ABSOLUTE 4 //如果a == 5成立, 那么绝对跳转, 跳到字节码偏移量为4的位置, 所以continue对一个绝对跳转, 目标是循环开始的地方
7 >> 30 LOAD_NAME 0 (a) //走到这里说明a == 5不成立, 判断a == 7, 加载变量a
32 LOAD_CONST 4 (7) //加载常量7
34 COMPARE_OP 2 (==) //比较是否相等
36 POP_JUMP_IF_FALSE 40 //如果为False, 跳转到偏移量为40的位置, 也就是print(a)
8 38 JUMP_ABSOLUTE 50 //如果a == 5成立, 那么也是跳转到字节码偏移量为50的地方, 因为是break, 也是结束循环
9 >> 40 LOAD_NAME 1 (print) //加载变量print
42 LOAD_NAME 0 (a) //加载变量a
44 CALL_FUNCTION 1 //函数调用
46 POP_TOP //从栈顶弹出返回值
48 JUMP_ABSOLUTE 4 //走到这里说明while循环执行一圈了, 那么再度跳转到while a < 10的地方
>> 50 LOAD_CONST 5 (None)
52 RETURN_VALUE
所以有了for循环,再看while循环就简单多了,整体逻辑和for高度相似,当然里面还结合了if。另外我们看到break和continue都是使用了JUMP_ABSOLUTE实现的。JUMP_ABSOLUTE是跳转到指定位置,通过绝对跳转实现的。break是跳转到while语句结束后的第一条指令;continue则是跳转到while循环的开始位置。
然后执行一圈之后,遇到了48 JUMP_ABSOLUTE ,再度跳转回去。当循环不满足的时候,通过10 POP_JUMP_IF_FALSE 50直接结束循环,所以while事实上比for还是要简单一些的。
Python虚拟机中的异常控制流
异常这个东西应该是最常见的了,程序在运行的过程中经常会遇到大量的错误,而Python中也定义了大量的异常类型供我们使用,下面我们来看看Python中的异常机制,因为这也是一个控制语句。
Python中的异常机制
Python虚拟机自身抛出异常
Python有一套内建的异常捕捉机制,即使在python的脚本文件中没有出现try语句,python脚本执行出现的异常还是会被虚拟机捕捉到。首先我们就从ZeroDivisionError这个异常来分析。
s = """
1 / 0
"""
if __name__ == '__main__':
import dis
dis.dis(compile(s, "while", "exec"))
"""
2 0 LOAD_CONST 0 (1)
2 LOAD_CONST 1 (0)
4 BINARY_TRUE_DIVIDE
6 POP_TOP
8 LOAD_CONST 2 (None)
10 RETURN_VALUE
"""
我们看第3条字节码指令,异常也正是在执行这条指令的时候触发的。
case TARGET(BINARY_TRUE_DIVIDE): {
//co_consts -> (0, 1)
PyObject *divisor = POP(); //1
PyObject *dividend = TOP();//0
//调用__truediv__
PyObject *quotient = PyNumber_TrueDivide(dividend, divisor);
Py_DECREF(dividend);
Py_DECREF(divisor);
//将结果设置在栈顶
SET_TOP(quotient);
//如果结果是NULL, 那么就报错了
if (quotient == NULL)
goto error;
DISPATCH();
}
逻辑很简单, 就是获取两个值,然后调用PyNumber_TrueDivide进行除法运算。正常情况下得到的肯定是一个数值,如果不能相除那么就返回NULL,如果接收的quotient是NULL,那么抛异常。因此我们来看看PyNumber_TrueDivide都干了些啥?
//longobject.c
//最终调用的是long_true_divide
//代码很长我们截取一部分
static PyObject *
long_true_divide(PyObject *v, PyObject *w)
{
//都是在计算除法时需要的临时变量
PyLongObject *a, *b, *x;
Py_ssize_t a_size, b_size, shift, extra_bits, diff, x_size, x_bits;
digit mask, low;
int inexact, negate, a_is_small, b_is_small;
double dx, result;
CHECK_BINOP(v, w);
//将v和w中维护的整数值转存到a和b中
a = (PyLongObject *)v;
b = (PyLongObject *)w;
a_size = Py_ABS(Py_SIZE(a));
b_size = Py_ABS(Py_SIZE(b));
negate = (Py_SIZE(a) < 0) ^ (Py_SIZE(b) < 0);
//获取b_size, 就是b对应的ob_size, 我们在分析PyLongObject对象时说过, 如果这个对象维护的值为0,那么ob_size就是0,这是个特殊情况
//并且这个ob_size还可以体现出维护的值的正负
//我们看到如果b_size == 0, 那么抛出PyExc_ZeroDivisionError
if (b_size == 0) {
PyErr_SetString(PyExc_ZeroDivisionError,
"division by zero");
goto error;
}
...
...
}
所以如果除以0,那么直接设置异常信息。另外我们说过Python中一切皆对象,那么异常也是一个对象,是一个PyObject类型。
//pyerrors.h
//这里面定义了大量的异常, 比如:
typedef struct {
PyException_HEAD
} PyBaseExceptionObject; //BaseException, 所有异常的基类, Exception也继承自它
typedef struct {
PyException_HEAD
PyObject *msg;
PyObject *filename;
PyObject *lineno;
PyObject *offset;
PyObject *text;
PyObject *print_file_and_line;
} PySyntaxErrorObject; //语法异常
typedef struct {
PyException_HEAD
PyObject *msg;
PyObject *name;
PyObject *path;
} PyImportErrorObject; //导包异常
typedef struct {
PyException_HEAD
PyObject *encoding;
PyObject *object;
Py_ssize_t start;
Py_ssize_t end;
PyObject *reason;
} PyUnicodeErrorObject;//Unicode异常
typedef struct {
PyException_HEAD
PyObject *value;
} PyStopIterationObject; //StopIteration异常
在线程状态对象中记录异常信息(线程的知识后续会说)
我们之前看到,异常信息是通过PyErr_SetString(异常类型, 异常信息)来设置的,而除了这个PyErr_SetString,还会经过PyErr_SetObject,最终到达PyErr_Restore。在PyErr_Restore中,Python将这个异常放置到了一个安全的地方。
//Python/errors.c
void
PyErr_Restore(PyObject *type, PyObject *value, PyObject *traceback)
{
//获取线程对象
PyThreadState *tstate = _PyThreadState_GET();
_PyErr_Restore(tstate, type, value, traceback);
}
void
_PyErr_Restore(PyThreadState *tstate, PyObject *type, PyObject *value,
PyObject *traceback)
{
//异常类型、异常值、异常的回溯栈, 对应Python中sys.exc_info()返回的元组里面的3个元组
PyObject *oldtype, *oldvalue, *oldtraceback;
//如果traceback不为空并且不是回溯栈, 那么将其设置为NULL
if (traceback != NULL && !PyTraceBack_Check(traceback)) {
Py_DECREF(traceback);
traceback = NULL;
}
//获取以前的异常信息
oldtype = tstate->curexc_type;
oldvalue = tstate->curexc_value;
oldtraceback = tstate->curexc_traceback;
//设置当前的异常信息
tstate->curexc_type = type;
tstate->curexc_value = value;
tstate->curexc_traceback = traceback;
//将之前的异常信息的引用计数分别减1
Py_XDECREF(oldtype);
Py_XDECREF(oldvalue);
Py_XDECREF(oldtraceback);
}
最后在tstate(PyThreadState对象)的curexc_type中存下了PyExc_ZeroDivisionError,而cur_value中存下了字符串division by zero,curexc_traceback存下了回溯栈。
import sys
try:
1 / 0
except ZeroDivisionError as e:
exc_type, exc_value, exc_tb = sys.exc_info()
print(exc_type) # <class 'ZeroDivisionError'>
print(exc_value) # division by zero
print(exc_tb) # <traceback object at 0x000001C43F29F4C0>
# exc_tb也可以通过e.__traceback__获取
print(e.__traceback__ is exc_tb) # True
我们再来看看PyThreadState对象(这里先简单看一下,后续会详细说),这个之前说了是与线程有关的,但是它只是线程信息的一个抽象描述,而真实的线程及状态肯定是由操作系统来维护和管理的。因为Python虚拟机在运行的时候总需要另外一些与线程相关的状态和信息,比如是否发生了异常等等,这些信息显然操作系统是没有办法提供的。而PyThreadState对象正是Python为线程准备的、在虚拟机层面保存线程状态信息的对象(后面简称线程状态对象、或者线程对象)。在这里,当前活动线程(OS原生线程)对应的PyThreadState对象可以通过PyThreadState_GET获得,在得到了线程状态对象之后,就将异常信息存放到线程状态对象中。
展开栈帧
首先我们知道异常已经被记录在了线程的状态中了,现在可以回头看看,在跳出了分派字节码指令的switch块所在的for循环之后,发生了什么动作。
我们知道在Python/ceval.c中有一个 _PyEval_EvalFrameDefault 函数,它是执行字节码指令的。里面有一个for循环,会依次遍历每一条字节码,在这个for循环里面有一个巨型switch,里面case了所有指令出现的情况。当所有指令执行完毕之后,这个for循环就结束了。
但这里还存在一个问题,那就是导致跳出那个巨大的switch块所在的for循环的原因:"1. 可以是执行完了所有的字节码之后正常跳出","2. 也可以是发生异常后跳出",那么Python虚拟机到底如何区分这是哪一种呢?
PyObject* _Py_HOT_FUNCTION
_PyEval_EvalFrameDefault(PyFrameObject *f, int throwflag)
{
for (;;) {
switch (opcode) {
// 一个超大的switch语句
}
error: //一旦出现异常, 会使用goto语句跳转到error标签这里
#ifdef NDEBUG
if (!_PyErr_Occurred(tstate)) {
_PyErr_SetString(tstate, PyExc_SystemError,
"error return without exception set");
}
#else
assert(_PyErr_Occurred(tstate));
#endif
//创建traceback对象
PyTraceBack_Here(f);
if (tstate->c_tracefunc != NULL)
call_exc_trace(tstate->c_tracefunc, tstate->c_traceobj,
tstate, f);
}
}
如果在执行switch语句的时候出现了异常,那么会跳转到error这里,否则会跳转到其它地方。当跳转到error标签的时候就代表出现异常了,注意:是在执行过程中出现异常之后Python虚拟机才获取到异常信息。
那么问题就来了, 如果在在涉及到函数调用的时候发生了异常该怎么办呢?首先在python虚拟机意识到有异常发生后,它就要开始进入异常处理的流程,这个流程会涉及到我们介绍PyFrameObject对象时所提到的那个PyFrameObject对象链表。在介绍PyFrameObject对象的时候,我们说过PyFrameObject实际上就是对栈帧的模拟,当发生函数函数调用,python会新创建一个栈帧,并将其内部的f_back连接到调用者对应的PyFrameObject,这样就形成了一条栈帧链。
def h():
1 / 0
def g():
h()
def f():
g()
f()
"""
Traceback (most recent call last):
File "D:/satori/1.py", line 13, in <module>
f()
File "D:/satori/1.py", line 10, in f
g()
File "D:/satori/1.py", line 6, in g
h()
File "D:/satori/1.py", line 2, in h
1 / 0
ZeroDivisionError: division by zero
"""
这是脚本运行时产生的输出,我们看到了函数调用的信息:比如在源代码的哪一行调用了哪一个函数,那么这些信息是从何而来的呢?而且我们发现输出的信息是一个链状的结构,是不是和栈帧链比较相似啊。没错,在Python虚拟机处理异常的时候,涉及到了一个traceback对象,在这个对象中记录栈帧链表的信息,Python虚拟机利用这个对象来将栈帧链表中的每一个栈帧的状态进行可视化,这个可视化的结果就是上面输出的异常信息。
回到我们的例子,当异常发生时,当前活动的栈帧是函数h对应的栈帧。在Python虚拟机开始处理异常的时候,它首先的动作就是创建一个traceback对象,用于记录异常发生时活动栈帧的状态。
PyObject* _Py_HOT_FUNCTION
_PyEval_EvalFrameDefault(PyFrameObject *f, int throwflag)
{
for (;;) {
switch (opcode) {
// 一个超大的switch语句
}
//......
//创建traceback对象
PyTraceBack_Here(f);
//这里tstate还是我们之前提到的与当前活动线程对应的线程对象
//其中的c_tracefunc是用户自定义的追踪函数,主要用于编写python的debugger。
//但是通常情况下这个值都是NULL,所以不考虑它。
//我们主要看上面的PyTraceBack_Here(f),它到底使用PyFrameObject对象创建了一个怎样的traceback
if (tstate->c_tracefunc != NULL)
call_exc_trace(tstate->c_tracefunc, tstate->c_traceobj,
tstate, f);
}
}
//Python/traceback.c
int
PyTraceBack_Here(PyFrameObject *frame)
{
PyObject *exc, *val, *tb, *newtb;
//获取线程中保存线程状态的traceback对象, 进行设置
PyErr_Fetch(&exc, &val, &tb);
//_PyTraceBack_FromFrame创建新的traceback对象
newtb = _PyTraceBack_FromFrame(tb, frame);
if (newtb == NULL) {
_PyErr_ChainExceptions(exc, val, tb);
return -1;
}
//将新的traceback对象交给线程状态对象
PyErr_Restore(exc, val, newtb);
Py_XDECREF(tb);
return 0;
}
原来traceback对象是保存在线程状态对象之中的,我们来看看这个traceback对象究竟长得什么样:
//Include/cpython/traceback.h
typedef struct _traceback {
PyObject_HEAD
struct _traceback *tb_next;
struct _frame *tb_frame;
int tb_lasti;
int tb_lineno;
} PyTracebackObject;
可以看到里面有一个tb_next,所以很容易想到这个traceback也是一个链表结构。其实这个PyTracebackObject对象的链表结构应该跟PyFrameObject对象的链表结构是同构的、或者说一一对应的,即一个PyFrameObject对象应该对应一个PyTracebackObject对象。我们看看这个链表是怎么产生的,在PyTraceBack_Here函数中我们看到它是通过_PyTraceBack_FromFrame创建的,那么秘密就隐藏在这个函数中:
//Python/traceback.h
PyObject*
_PyTraceBack_FromFrame(PyObject *tb_next, PyFrameObject *frame)
{
assert(tb_next == NULL || PyTraceBack_Check(tb_next));
assert(frame != NULL);
//底层调用了tb_create_raw, 参数分别是下一个traceback、当前栈帧、当前f_lasti、以及源代码行号
return tb_create_raw((PyTracebackObject *)tb_next, frame, frame->f_lasti,
PyFrame_GetLineNumber(frame));
}
static PyObject *
tb_create_raw(PyTracebackObject *next, PyFrameObject *frame, int lasti,
int lineno)
{
PyTracebackObject *tb;
if ((next != NULL && !PyTraceBack_Check(next)) ||
frame == NULL || !PyFrame_Check(frame)) {
PyErr_BadInternalCall();
return NULL;
}
//申请内存
tb = PyObject_GC_New(PyTracebackObject, &PyTraceBack_Type);
if (tb != NULL) {
//建立链表
Py_XINCREF(next);
//这里的tb_next就是下一个traceback
tb->tb_next = next;
Py_XINCREF(frame);
//设置栈帧, 所以我们可以通过e.__traceback__.tb_frame获取栈帧
tb->tb_frame = frame;
//执行完毕时字节码偏移量
tb->tb_lasti = lasti;
//源代码行号
tb->tb_lineno = lineno;
//加入GC追踪, 参与垃圾回收
PyObject_GC_Track(tb);
}
return (PyObject *)tb;
}
从源码中我们看到,tb_next是将两个traceback连接了起来,不过这个和PyFrameObject里面f_back正好相反。f_back指向的是上一个栈帧,而tb_next指向的是下一个traceback。另外在新创建的对象中,还使用tb_frame和对应的PyFrameObject对象建立了联系,当然还有最后执行完毕的字节码偏移量以及其在源代码中对应的行号。话说还记得PyCodeObject对象中的那个co_lnotab吗,这里的tb_lineno就是通过co_lnotab获取的。
Python虚拟机意识到有异常抛出,并创建了traceback对象之后,它会在当前栈帧中寻找except语句,来执行开发人员指定的捕捉异常的动作。如果没有找到,那么Python虚拟机将退出当前的活动栈帧,并沿着栈帧链回退到上一个栈帧,在上一个栈帧中寻找except语句。就像我们之前说的,出现函数调用会创建栈帧,当函数执行完毕或者出现异常的时候,会回退到上一级栈帧。一层一层创建、一层一层返回。至于回退的这个动作,则是在PyEval_EvalFrameEx的最后完成,当然准确的说应该是其内部调用的_PyEval_EvalFrameDefault的最后。
for(;;){
switch(opcode){
//巨型switch
}
exception_unwind:
//如果发生了异常, 这里会将异常进行展开, 然后试图进行捕获
//注意: exception_unwind是位于这个大大的for循环的内部的结束位置
while (f->f_iblock > 0) {
//里面是和异常捕获相关的逻辑, 后面会分析
}
break;
}
//retval表示_PyEval_EvalFrameDefault函数的返回值, 返回值为NULL, 那么表示有异常发生
assert(retval == NULL);
assert(_PyErr_Occurred(tstate));
//......
exit_eval_frame:
if (PyDTrace_FUNCTION_RETURN_ENABLED())
dtrace_function_return(f);
Py_LeaveRecursiveCall();
f->f_executing = 0;
//将线程状态对象中的活动栈帧设置为上一个栈帧, 完成栈帧回退的动作
tstate->frame = f->f_back;
return _Py_CheckFunctionResult(NULL, retval, "PyEval_EvalFrameEx");
如果开发人员没有任何的捕获异常的动作,那么将通过break跳出python执行字节码的那个for循环。最后,由于没有捕获到异常, 其返回值被设置为NULL,同时通过将当前线程状态对象中的活动栈帧,设置为上一级栈帧,从而完成栈帧回退的动作。
此时我们的例子就很好解释了,当虚拟机执行函数f时,它是在PyEval_EvalFrameEx(内部调用的_PyEval_EvalFrameDefault)中执行与f对应的PyFrameObject对象中的字节码指令序列。当在函数f中调用g时,Python虚拟机又会为函数g创建新的PyFrameObject对象,会把控制权交给函数g对应的PyFrameObject,当然调用的也是PyEval_EvalFrameEx,只不过这次是在执行与g对应的PyFrameObject对象中的字节码指令序列了。同理函数g调用函数h的时候,也是一样的。所以当在函数h中发生异常,没有异常捕获、导致PyEval_EvalFrameEx结束时,自然要返回到、或者把控制权再交给与函数g对应的PyFrameObject,由PyEval_EvalFrameEx继续执行。由于在返回时,retval被设置为NULL,所以回到g中,Python虚拟机再次意识到有异常产生,可由于函数g中调用的时候也没有异常捕获,那么同样也要退出,再把PyEval_EvalFrameEx执行栈帧的控制权交给函数f对应的栈帧,如果还没有异常捕获,那么回到py文件对应的栈帧,再没有的话就直接报错了。
这个沿着栈帧链不断回退的过程我们称之为栈帧展开,在这个栈帧展开的过程中,Python虚拟机不断地创建与各个栈帧对应的traceback,并将其链接成链表。
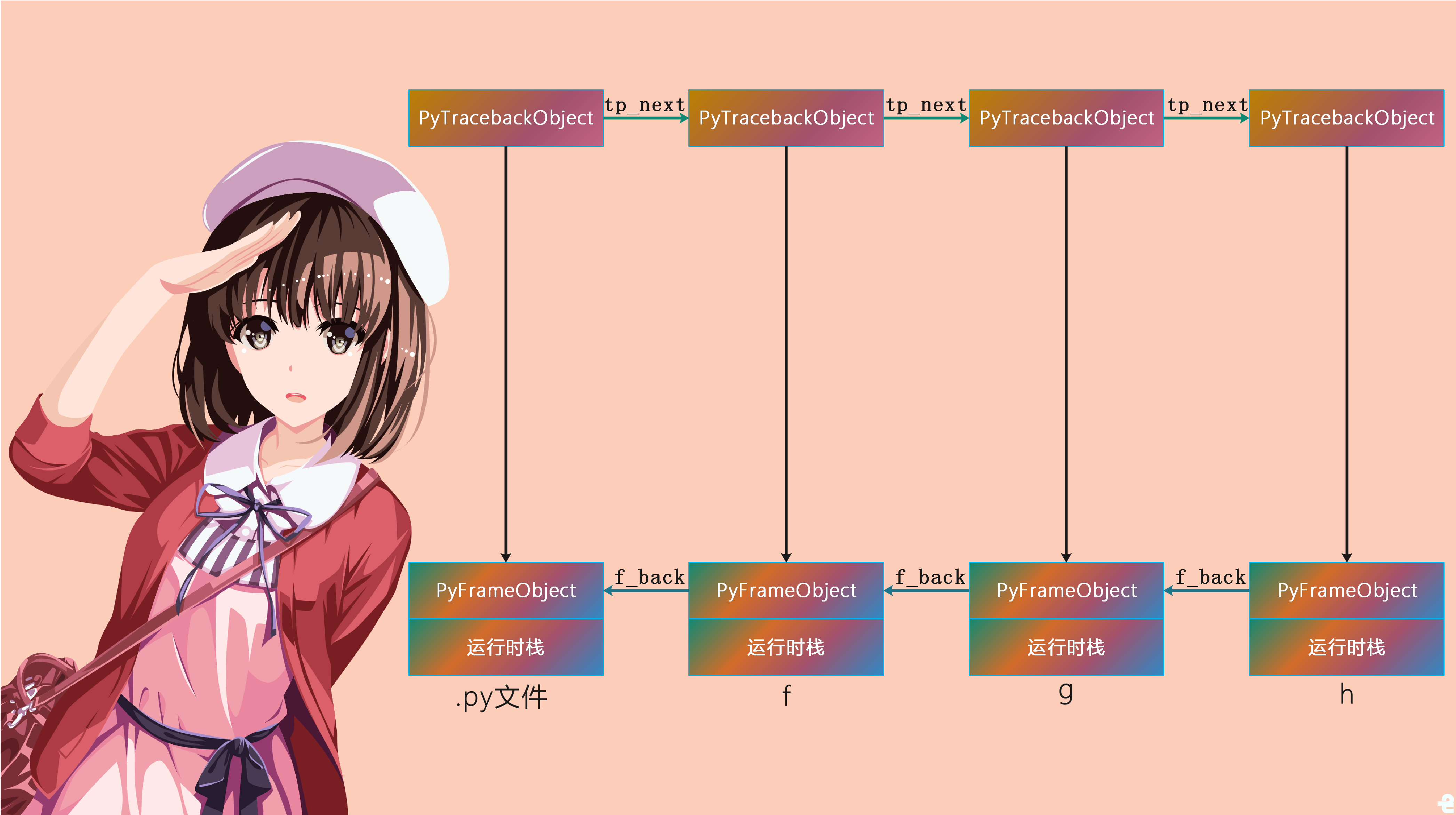
由于我们没有设置任何的异常捕获的代码,那么python虚拟机的执行流程会一直返回到PyRun_SimpleFileExFlags中,这个PyRun_SimpleFileExFlags是干啥的我们先不管,以后分析Python运行时候的初始化时,就可以看到这个函数的作用了。
//Python/pythonrun.c
int
PyRun_SimpleFileExFlags(FILE *fp, const char *filename, int closeit,
PyCompilerFlags *flags)
{
//.......
if (maybe_pyc_file(fp, filename, ext, closeit)) {
//......
//执行pyc文件
} else {
/* When running from stdin, leave __main__.__loader__ alone */
if (strcmp(filename, "<stdin>") != 0 &&
set_main_loader(d, filename, "SourceFileLoader") < 0) {
fprintf(stderr, "python: failed to set __main__.__loader__
");
ret = -1;
goto done;
}
//调用了PyRun_FileExFlags
v = PyRun_FileExFlags(fp, filename, Py_file_input, d, d,
closeit, flags);
}
//......
return ret;
}
PyObject *
PyRun_FileExFlags(FILE *fp, const char *filename_str, int start, PyObject *globals,
PyObject *locals, int closeit, PyCompilerFlags *flags)
{
//......
//调用了run_mod
ret = run_mod(mod, filename, globals, locals, flags, arena);
exit:
Py_XDECREF(filename);
if (arena != NULL)
PyArena_Free(arena);
return ret;
}
static PyObject *
run_mod(mod_ty mod, PyObject *filename, PyObject *globals, PyObject *locals,
PyCompilerFlags *flags, PyArena *arena)
{
//......
//调用run_eval_code_obj
v = run_eval_code_obj(co, globals, locals);
Py_DECREF(co);
return v;
}
static PyObject *
run_eval_code_obj(PyCodeObject *co, PyObject *globals, PyObject *locals)
{
//......
//调用了PyEval_EvalCode
v = PyEval_EvalCode((PyObject*)co, globals, locals);
if (!v && PyErr_Occurred() == PyExc_KeyboardInterrupt) {
_Py_UnhandledKeyboardInterrupt = 1;
}
return v;
}
//Python/ceval.c
PyObject *
PyEval_EvalCode(PyObject *co, PyObject *globals, PyObject *locals)
{
//调用了PyEval_EvalCodeEx
return PyEval_EvalCodeEx(co,
globals, locals,
(PyObject **)NULL, 0,
(PyObject **)NULL, 0,
(PyObject **)NULL, 0,
NULL, NULL);
}
PyObject *
PyEval_EvalCodeEx(PyObject *_co, PyObject *globals, PyObject *locals,
PyObject *const *args, int argcount,
PyObject *const *kws, int kwcount,
PyObject *const *defs, int defcount,
PyObject *kwdefs, PyObject *closure)
{
//调用了_PyEval_EvalCodeWithName
return _PyEval_EvalCodeWithName(_co, globals, locals,
args, argcount,
kws, kws != NULL ? kws + 1 : NULL,
kwcount, 2,
defs, defcount,
kwdefs, closure,
NULL, NULL);
}
PyObject *
_PyEval_EvalCodeWithName(PyObject *_co, PyObject *globals, PyObject *locals,
PyObject *const *args, Py_ssize_t argcount,
PyObject *const *kwnames, PyObject *const *kwargs,
Py_ssize_t kwcount, int kwstep,
PyObject *const *defs, Py_ssize_t defcount,
PyObject *kwdefs, PyObject *closure,
PyObject *name, PyObject *qualname)
{
//......
//调用了PyEval_EvalFrameEx, 里面的f就是在该函数中创建的栈帧对象
//还记得这个返回值retval吗? 如果它是NULL, 那么代表该栈帧中有异常发生了
retval = PyEval_EvalFrameEx(f,0);
fail:
//......
//返回retval
return retval;
}
PyObject *
PyEval_EvalFrameEx(PyFrameObject *f, int throwflag)
{
//创建一个线程对象, 里面会调用其它函数创建一个线程
PyInterpreterState *interp = _PyInterpreterState_GET_UNSAFE();
//执行线程对象的eval_frame
return interp->eval_frame(f, throwflag);
}
//Python/pystate.c
PyInterpreterState *
PyInterpreterState_New(void)
{
//......
//你看到了什么? interp->eval_frame被设置成了_PyEval_EvalFrameDefault
interp->eval_frame = _PyEval_EvalFrameDefault;
//......
}
可以看到兜了这么多圈,最终PyRun_SimpleFileExFlags返回的值就是PyEval_EvalFrameEx返回的那个retval(当然出现异常的话,就是NULL)。所以接下来会调用PyErr_Print,然后在PyErr_Print中,Python虚拟机取出其维护的traceback,并遍历traceback链表,逐个输出其中的信息,也就是我们在python中看到的那个打印的异常信息。并且这个顺序是:.py文件、函数f、函数g、函数h,不是函数h、函数g、函数f、py文件。因为每一个栈帧对应一个traceback,而且是按照顺序遍历的,所以是:.py文件、函数f、g、h的顺序,当然从打印这一点也能看出来。
因为是在函数h中报的错,所以退到函数g的栈帧中寻找异常捕获;如果retval为NULL,那么在退到函数f的栈帧中寻找异常捕获,再没有的话则退到模块对应的栈帧中。
模块中也没有异常捕获,那么报错。所以获取模块栈帧对应的traceback,打印异常信息,然后通过tb_next找到 f 对应的traceback打印其信息,依次下去......。事实上稍微想一下就能理解,虽然是在 h 中报的错,但根本原因是我们在模块中调用了 f,所以依次打印模块、f、g、h中traceback的异常信息。
Python中的异常捕获
目前我们知道了Python中的异常在虚拟机级别是什么,抛出异常这个动作在虚拟机层面上是怎样的一个行为,最后我们还知道了Python在处理异常时候的栈帧展开行为。但这只是Python虚拟机中内建的处理异常的动作,并没有使用Python语言中提供的异常捕获,下面我们就来看一下Python提供的异常捕获机制是如何影响Python虚拟机的异常处理流程的。
s = """
try:
raise Exception("raise an exception")
except Exception as e:
print(e)
finally:
print("finally code")
"""
if __name__ == '__main__':
import dis
dis.dis(compile(s, "exception", "exec"))
2 0 SETUP_FINALLY 60 (to 62)
2 SETUP_FINALLY 12 (to 16)
3 4 LOAD_NAME 1 (Exception)
6 LOAD_CONST 1 ('raise an exception')
8 CALL_FUNCTION 1
10 RAISE_VARARGS 1
12 POP_BLOCK
14 JUMP_FORWARD 42 (to 58)
4 >> 16 DUP_TOP
18 LOAD_NAME 1 (Exception)
20 COMPARE_OP 10 (exception match)
22 POP_JUMP_IF_FALSE 56
24 POP_TOP
26 STORE_NAME 2 (e)
28 POP_TOP
30 SETUP_FINALLY 12 (to 44)
5 32 LOAD_NAME 0 (print)
34 LOAD_NAME 2 (e)
36 CALL_FUNCTION 1
38 POP_TOP
40 POP_BLOCK
42 BEGIN_FINALLY
>> 44 LOAD_CONST 2 (None)
46 STORE_NAME 2 (e)
48 DELETE_NAME 2 (e)
50 END_FINALLY
52 POP_EXCEPT
54 JUMP_FORWARD 2 (to 58)
>> 56 END_FINALLY
>> 58 POP_BLOCK
60 BEGIN_FINALLY
7 >> 62 LOAD_NAME 0 (print)
64 LOAD_CONST 0 ('finally code')
66 CALL_FUNCTION 1
68 POP_TOP
70 END_FINALLY
72 LOAD_CONST 2 (None)
74 RETURN_VALUE
首先这个指令集比较复杂,因为要分好几种情况。try里面没有出现异常;try里面出现了异常、但是except语句没有捕获到;try里面出现了异常,except语句捕获到了。但我们知道无论是哪种情况,都要执行finally。
我们先看上面的SETUP_FINALLY指令,这里为包含finally语句做准备的:
case TARGET(SETUP_FINALLY): {
/* NOTE: If you add any new block-setup opcodes that
are not try/except/finally handlers, you may need
to update the PyGen_NeedsFinalizing() function.
*/
//我们看到仅仅是调用了一个PyFrame_BlockSetup函数
PyFrame_BlockSetup(f, SETUP_FINALLY, INSTR_OFFSET() + oparg,
STACK_LEVEL());
DISPATCH();
}
//Objects/frameobject.c
void
PyFrame_BlockSetup(PyFrameObject *f, int type, int handler, int level)
{
//创建一个PyTryBlock *
PyTryBlock *b;
//这个f_iblock为当前指令在f_blockstack上的索引, 还记得这个f_blockstack吗?我们在介绍栈帧的时候说过的,它可以用于try代码块
//f_blockstack是一个数组, 内部存储了多个PyTryBlock对象
//PyTryBlock f_blockstack[CO_MAXBLOCKS]; CO_MAXBLOCKS是一个宏,为20
if (f->f_iblock >= CO_MAXBLOCKS)
Py_FatalError("XXX block stack overflow");
//这里我们算是真正意义上第一次使用栈帧中的f_blockstack属性
//这里得到的b显然是个PyTryBlock结构体实例
b = &f->f_blockstack[f->f_iblock++];
//设置属性
b->b_type = type;
b->b_level = level;
b->b_handler = handler;
}
//frameobject.h
//我们看看PyTryBlock长什么样
typedef struct {
int b_type; /* what kind of block this is */
int b_handler; /* where to jump to find handler */
int b_level; /* value stack level to pop to */
} PyTryBlock;
//显然PyFrameObject对象中的f_blockstack是一个由PyTryBlock对象组成的数组,而SETUP_FINALLY指令所做的就是从这个数组中获得了一块PyTryBlock对象
//并在这个对象中存放了一些Python虚拟机当前的状态信息。比如当前执行的字节码指令,当前运行时栈的深度等等。
//那么这个结构在try控制结构中起着什么样的作用呢?我们后面就会知晓
//我们注意到PyTryBlock中有一个b_type域,注释写着这个域是用来表示是block的种类, 也就意味着存在着多种不同用途的PyTryBlock对象。
//从PyFrame_BlockSetup中可以看到,这个b_type实际上被设置为当前Python虚拟机正在执行的字节码指令,以字节码指令作为区分PyTryBlock的不同用途
但我们看到开头有两个SETUP_FINALLY,其实在Python3.8之前,第二个SETUP_FINALLY应该是SETUP_EXCEPT,但是在3.8中都变成了SETUP_FINALLY。

在这里分出两块PyTryBlock,肯定是要在捕捉异常的时候用。不过别着急,我们先回到抛出异常的地方看看:10 RAISE_VARARGS 1。在RAISE_VARARGS之前,通过LOAD_NAME、LOAD_CONST、CALL_FUNCTION构造出了一个异常对象,当然尽管Exception是一个类,但调用的指令也同样是CALL_FUNCTION(至于这个指令的剖析和对象的创建后面章节会介绍,这里只需要知道一个异常已经被创建出来了),并将这个异常压入栈中。而RAISE_VARARGS指令的工作就从把这个异常对象从运行时栈取出开始。
case TARGET(RAISE_VARARGS): {
PyObject *cause = NULL, *exc = NULL;
switch (oparg) {
case 2:
cause = POP(); /* cause */
/* fall through */
case 1:
exc = POP(); /* exc */
/* fall through */
case 0:
if (do_raise(tstate, exc, cause)) {
goto exception_unwind;
}
break;
default:
_PyErr_SetString(tstate, PyExc_SystemError,
"bad RAISE_VARARGS oparg");
break;
}
goto error;
}
这里RAISE_VARARGS后面的参数是1,所以直接将异常对象取出赋给exc,然后调用do_raise函数。在do_raise中,最终调用之前的说过的PyErr_Restore函数,将异常对象存储到当前的线程对象中。在经过了一系列繁复的动作之后(比如创建并设置traceback),通过do_raise,Python虚拟机将携带着(f_iblock=2)信息抵达真正捕捉异常的代码,我们看到跳转到了标签为exception_unwind的地方进行异常捕获,并且在最后,Python虚拟机通过一个break的动作跳出了分发字节码指令的那个巨大的switch语句所在的for循环。
exception_unwind:
/* Unwind stacks if an exception occurred */
while (f->f_iblock > 0) {
PyTryBlock *b = &f->f_blockstack[--f->f_iblock];
if (b->b_type == SETUP_FINALLY) {
PyObject *exc, *val, *tb;
int handler = b->b_handler;
_PyErr_StackItem *exc_info = tstate->exc_info;
/* Beware, this invalidates all b->b_* fields */
PyFrame_BlockSetup(f, EXCEPT_HANDLER, -1, STACK_LEVEL());
PUSH(exc_info->exc_traceback);
PUSH(exc_info->exc_value);
if (exc_info->exc_type != NULL) {
PUSH(exc_info->exc_type);
}
else {
Py_INCREF(Py_None);
PUSH(Py_None);
}
_PyErr_Fetch(tstate, &exc, &val, &tb);
/* Make the raw exception data
available to the handler,
so a program can emulate the
Python main loop. */
_PyErr_NormalizeException(tstate, &exc, &val, &tb);
if (tb != NULL)
PyException_SetTraceback(val, tb);
else
PyException_SetTraceback(val, Py_None);
Py_INCREF(exc);
exc_info->exc_type = exc;
Py_INCREF(val);
exc_info->exc_value = val;
exc_info->exc_traceback = tb;
if (tb == NULL)
tb = Py_None;
Py_INCREF(tb);
PUSH(tb);
PUSH(val);
PUSH(exc);
JUMPTO(handler);
/* Resume normal execution */
goto main_loop;
}
} /* unwind stack */
/* End the loop as we still have an error */
break;
} /* main loop */
assert(retval == NULL);
assert(_PyErr_Occurred(tstate));
Python虚拟机首先从当前的PyFrameObject对象中的f_blockstack中弹出一个PyTryBlock来,从代码中能看到弹出的是b_type = SETUP_FINALLY, b_handler=16的PyTryBlock。另一方面,Python虚拟机通过PyErr_Fetch得到了当前线程状态对象中存储的最新的异常对象和traceback对象:
//Python/errors.c
void
PyErr_Fetch(PyObject **p_type, PyObject **p_value, PyObject **p_traceback)
{
PyThreadState *tstate = _PyThreadState_GET();
_PyErr_Fetch(tstate, p_type, p_value, p_traceback);
}
void
_PyErr_Fetch(PyThreadState *tstate, PyObject **p_type, PyObject **p_value,
PyObject **p_traceback)
{
*p_type = tstate->curexc_type;
*p_value = tstate->curexc_value;
*p_traceback = tstate->curexc_traceback;
tstate->curexc_type = NULL;
tstate->curexc_value = NULL;
tstate->curexc_traceback = NULL;
}
回到exception_unwind,我们看到之后python虚拟机调用PUSH将tb、val、exc分别压入运行时栈中,而且Python知道此时程序猿已经为异常处理做好了准备,所以接下来的异常处理工作,则需要交给程序员指定的代码来解决,这个动作通过JUMP_FORWARD(JUMPTO(b->b_handler))来完成。JUMPTO其实仅仅是进行了一下指令的跳跃,将Python虚拟机将要执行的下一条指令设置为异常处理代码编译后所得到的第一条字节码指令。
因为f_blockstack是从后往前弹出的,所以第一个弹出的是PyTryBlock中b_handler为16的SETUP_FINALLY,那么Python虚拟机将要执行的下一条指令就是偏移量为16的那条指令,而这条指令就是DUP_TOP,异常处理代码对应的第一条字节码指令。
case TARGET(DUP_TOP): {
PyObject *top = TOP();
Py_INCREF(top);
PUSH(top);
FAST_DISPATCH();
}
首先我们except Exception,毫无疑问要LOAD_NAME,把这个异常给load进来,然后调用指令COMPARE_OP,这个显然就是比较我们指定捕获的异常和运行时栈中存在的那个被捕获的异常是否匹配。POP_JUMP_IF_FALSE如果为Py_True表示匹配,那么继续往下执行print(e)对应的字节码指令,POP_TOP将异常从栈顶弹出,赋值给e,然后打印等等。如果POP_JUMP_IF_FALSE为Py_False表示不匹配,那么我们发现直接跳转到了56 END_FINALLY,因为异常不匹配的话,那么异常的相关信息还是要重新放回线程对象当中,让Python重新引发异常,而这个动作就由END_FINALLY完成,通过PyErr_Restore函数将异常信息重新写回线程对象中。
case TARGET(END_FINALLY): {
PREDICTED(END_FINALLY);
/* At the top of the stack are 1 or 6 values:
Either:
- TOP = NULL or an integer
or:
- (TOP, SECOND, THIRD) = exc_info()
- (FOURTH, FITH, SIXTH) = previous exception for EXCEPT_HANDLER
*/
PyObject *exc = POP();
if (exc == NULL) {
FAST_DISPATCH();
}
else if (PyLong_CheckExact(exc)) {
int ret = _PyLong_AsInt(exc);
Py_DECREF(exc);
if (ret == -1 && _PyErr_Occurred(tstate)) {
goto error;
}
JUMPTO(ret);
FAST_DISPATCH();
}
else {
assert(PyExceptionClass_Check(exc));
PyObject *val = POP();
PyObject *tb = POP();
//将异常信息又写入到了线程状态对象当中了
_PyErr_Restore(tstate, exc, val, tb);
goto exception_unwind;
}
}
然而不管异常是否匹配,最终处理异常的两条岔路都会在58 POP_BLOCK处汇合。
PREDICTED(POP_BLOCK);
TARGET(POP_BLOCK) {
//这里将当前PyFrameObject的f_blockstack中还剩下的那个与SETUP_FINALLY对应的PyTryBlock对象弹出
//然后python虚拟机的流程就进入了与finally表达式对应的字节码指令了。
PyTryBlock *b = PyFrame_BlockPop(f);
UNWIND_BLOCK(b);
DISPATCH();
}
因此在Python异常机制的实现中,最终要的就是虚拟机状态以及PyFrameObject对象中f_blockstack里存放的PyTryBlock对象了。首先根据Python虚拟机状态可以判断当前是否发生了异常,而PyTryBlock对象则告诉python虚拟机,程序员是否为异常设置了except代码块和finally代码块,python虚拟机异常处理的流程就是在虚拟机所处的状态和PyTryBlock的共同作用下完成的。
还是那句话,在3.8之前Python的指令集中存在一个SETUP_EXCEPT,但是在3.8的时候只有SETUP_FINALLY了。
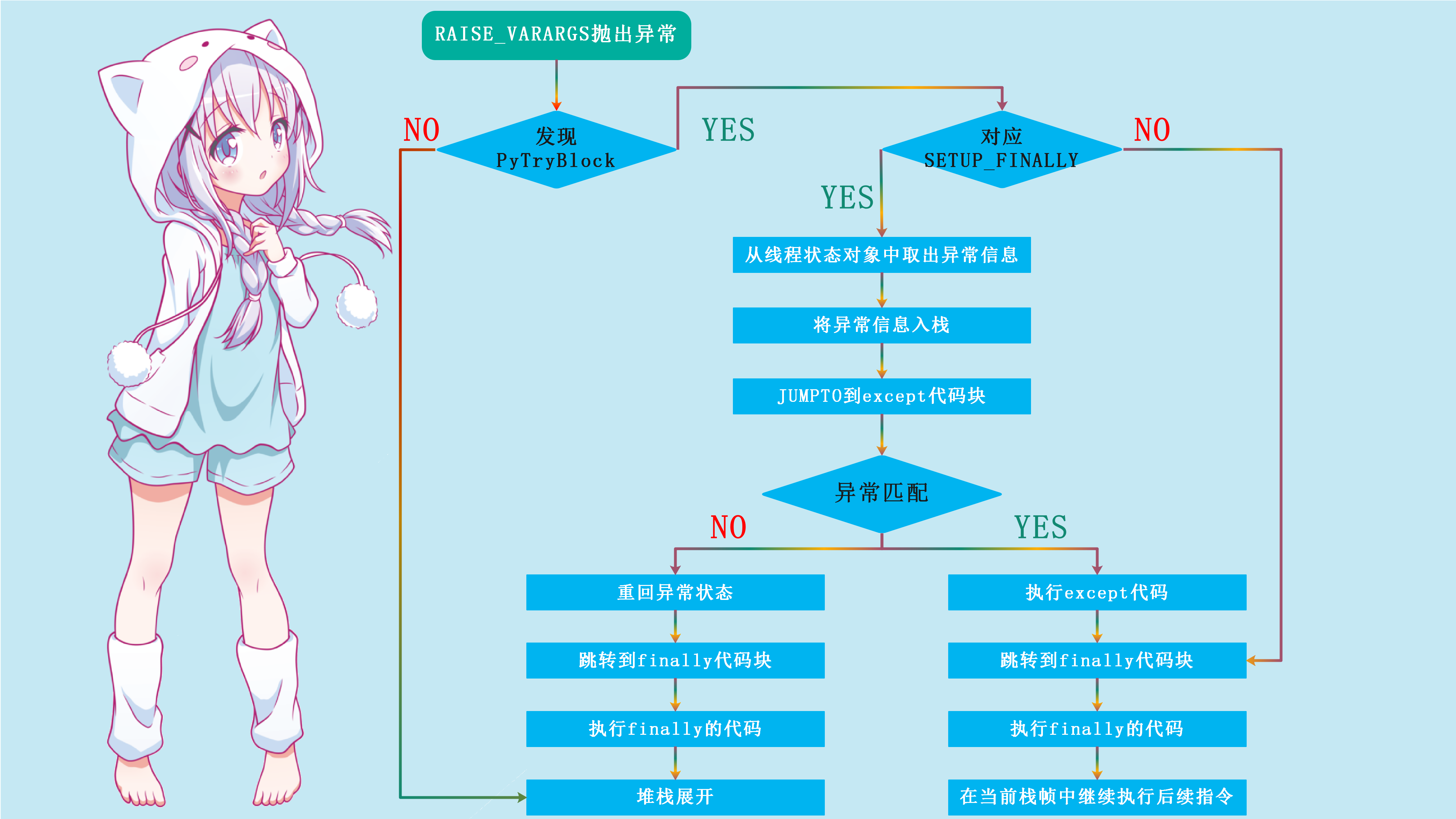
总之Python中一旦出现异常了,那么会将异常类型、异常值、异常回溯栈设置在线程状态对象中,然后栈帧一步一步的后退寻找异常捕获代码(从内向外)。如果退到了模块级别还没有发现异常捕获,那么从外向内打印traceback中的信息,当走到最后一层的时候再将线程中设置的异常类型和异常值打印出来。
def h():
1 / 0
def g():
h()
def f():
g()
f()
# 首先是在模块中调用了f、f调用了g、g调用了h, 所以在h中出现了异常、发现又没有异常捕获, 所以将执行权交给函数g对应的栈帧
# 但是g也没有异常捕获, 所以再将执行权交给函数f对应的栈帧, 所以调用的时候栈帧一层一层创建, 执行完毕、或者出现异常, 栈帧一层一层向后退
# 所以h的f_back指向g、g的f_back指向f、f的f_back指向模块、模块的f_back为None
# 但是对应的traceback则是模块的tb_next指向f、f的tb_next指向g、g的tb_next指向h、h的tb_next为None
# 而我们说栈帧层层后退, 退到模块对应的栈帧的时候要是还没有发现异常捕获, 那么就报错了
# 所以此时会打印模块对应的traceback的信息, 然后依次是f、g、h, 因为栈帧是从"函数h到模块"、但traceback则是从"模块到函数h"
# 所以我们仔细观察一下输出的异常信息, 不难印证我们的结论
"""
Traceback (most recent call last): # traceback回溯栈
File "D:/satori/1.py", line 13, in <module> # 打印模块的traceback
f()
File "D:/satori/1.py", line 10, in f # 打印f的traceback
g()
File "D:/satori/1.py", line 6, in g # 打印g的traceback
h()
File "D:/satori/1.py", line 2, in h # 打印h的traceback
1 / 0
ZeroDivisionError: division by zero # h的tb_next为None, 证明是在h中发生了错误, 所以再将之前设置线程状态对象中异常类型和异常值打印出来即可
"""
至于Python在处理异常的时候都经历哪些历程,我们虽然分析了,但其实还不够详细。因为Python的异常机制牵扯到底层的方方面面,并且涉及到了很多的宏,有兴趣可以自己再仔细深入研究。另外需要注意的是:Python3.8变化还是比较大的,在字节码方面你通过和3.7对比就可以发现。
最后再看一个思考题
e = 2.718
try:
raise Exception("我要引发异常了")
except Exception as e:
print(e) # 我要引发异常了
print(e)
# NameError: name 'e' is not defined
why?我们发现在外面打印e的时候,告诉我们e没有被定义。这是为什么呢?首先可以肯定的是,肯定是except Exception as e导致的,因为我们as的也是e,和外面的e重名了,如果我们as的是e1呢?
e = 2.718
try:
raise Exception("我要引发异常了")
except Exception as e1:
print(e1) # 我要引发异常了
print(e) # 2.718
可以看到as的是e1就没有问题了,但是为什么呢?即便不知道原因,也能推测出来。因为外面的变量叫e,而我们捕获异常as的也是e,此时e的指向就变了,而当异常处理结束的时候,e这个变量就被销毁了,所以外面就找不到了。然而事实上也确实如此。我们可以看一下字节码,通过观察我们上面例子的字节码,就能很清晰地看出端倪了。
1 0 LOAD_CONST 0 (2.718)
2 STORE_NAME 0 (e)
2 4 SETUP_FINALLY 12 (to 18)
3 6 LOAD_NAME 1 (Exception)
8 LOAD_CONST 1 ('我要引发异常了')
10 CALL_FUNCTION 1
12 RAISE_VARARGS 1
14 POP_BLOCK
16 JUMP_FORWARD 42 (to 60)
4 >> 18 DUP_TOP
20 LOAD_NAME 1 (Exception)
22 COMPARE_OP 10 (exception match)
24 POP_JUMP_IF_FALSE 58
26 POP_TOP
28 STORE_NAME 0 (e)
30 POP_TOP
32 SETUP_FINALLY 12 (to 46)
5 34 LOAD_NAME 2 (print)
36 LOAD_NAME 0 (e)
38 CALL_FUNCTION 1
40 POP_TOP
42 POP_BLOCK
44 BEGIN_FINALLY
>> 46 LOAD_CONST 2 (None)
48 STORE_NAME 0 (e)
50 DELETE_NAME 0 (e)
52 END_FINALLY
54 POP_EXCEPT
56 JUMP_FORWARD 2 (to 60)
>> 58 END_FINALLY
>> 60 LOAD_CONST 2 (None)
62 RETURN_VALUE
字节码很长,但是我们只需要看偏移量为50的那个字节码即可。你看到了什么,DELETE_NAME直接把e这个变量给删了,所以我们就找不到了,因此代码相当于下面这样:
e = 2.718
try:
raise Exception("我要引发异常了")
except Exception as e:
try:
print(e)
finally:
del e
因此在异常处理的时候,如果把异常赋予了一个变量,那么这个变量异常处理结束会被删掉,因此只能在except里面使用,这就是原因。但是原因有了,可动机呢?Python这么做的动机是什么?根据官网文档解释:
当使用 as 将目标赋值为一个异常时,它将在 except 子句结束时被清除,这意味着异常必须赋值给一个不同的名称(不同于外部指定的变量),才能在 except 子句之后引用它(外部指定的变量)。异常会被清除是因为在附加了回溯信息的情况下,它们会形成堆栈帧的循环引用,使得所有局部变量保持存活直到发生下一次垃圾回收。
try、except、finally的返回值问题
我们看看这三者的返回值之间的关系:
def f1():
try:
return 123
except Exception:
return 456
# 由于没有发生异常, 所以返回了try指定的返回值
print(f1()) # 123
def f2():
try:
1 / 0
return 123
except Exception:
return 456
# 此时发生异常, 所以返回了except指定的返回值
print(f2()) # 456
def f3():
try:
return 123
except Exception:
return 456
finally:
pass
# 返回的还是try指定的返回值, 因为finally中没有指定返回值
print(f3()) # 123
def f4():
try:
return 123
except Exception:
return 456
finally:
return
# 一旦finally中出现了return, 那么在没有报错的情况下返回的都是finally指定的返回值
print(f4()) # None
def f5():
try:
return 123
except Exception:
return 456
finally:
pass
return 789
# 我们函数一旦出现了return, 那么就表示结束函数直接返回了
# 但是return如果是在try中, 那么可以认为将返回值存起来了, 执行完finally之后再返回
# 如果finally也指定了return, 那么会返回finally指定的返回值, 否则还是返回之前的
# 总之一句话, 只要在try或者except中出现了return(前提是没有异常、或者异常被成功捕获)
# 那么在finally执行完毕之后, 会立即返回, 不会执行finally下面的代码
print(f5()) # 123
def f6():
try:
pass
except Exception:
return 456
finally:
pass
return 789
# 没有异常, 所以except的return没啥卵用, 但是try和finally中也没有return
# 所以程序会继续往下走
print(f6()) # 789
小结
这一次我们就分析了Python的控制语句,if、for、while都比较简单。但Python中的异常捕获算是比较复杂的,主要是牵扯的东西比较多,有时候分析某一个地方需要跳好几个源文件,进行查找。因此有兴趣的话,可以杀进源码中自由翱翔,但是注意Python的版本,我们说3.8版本和3.8之前的版本之间区别还是蛮大的。