本次课有两部分,KNN的模型分析以及回归分析
KNN模型分析
1.K值选取
选择K的时候要特别注意K的大小,适中才最好

要求太高会导致过拟合,低bias(偏差),太低则无法拟合,高bias。
2.训练与测试
收集的数据集,先分成测试集与训练集,一般训练集略大于测试集。
训练集用来训练模型(fit the model)
测试集则用来检测训练效果,使用模型测试数据,与提供的标签进行比较,最后计算误差判断效果。
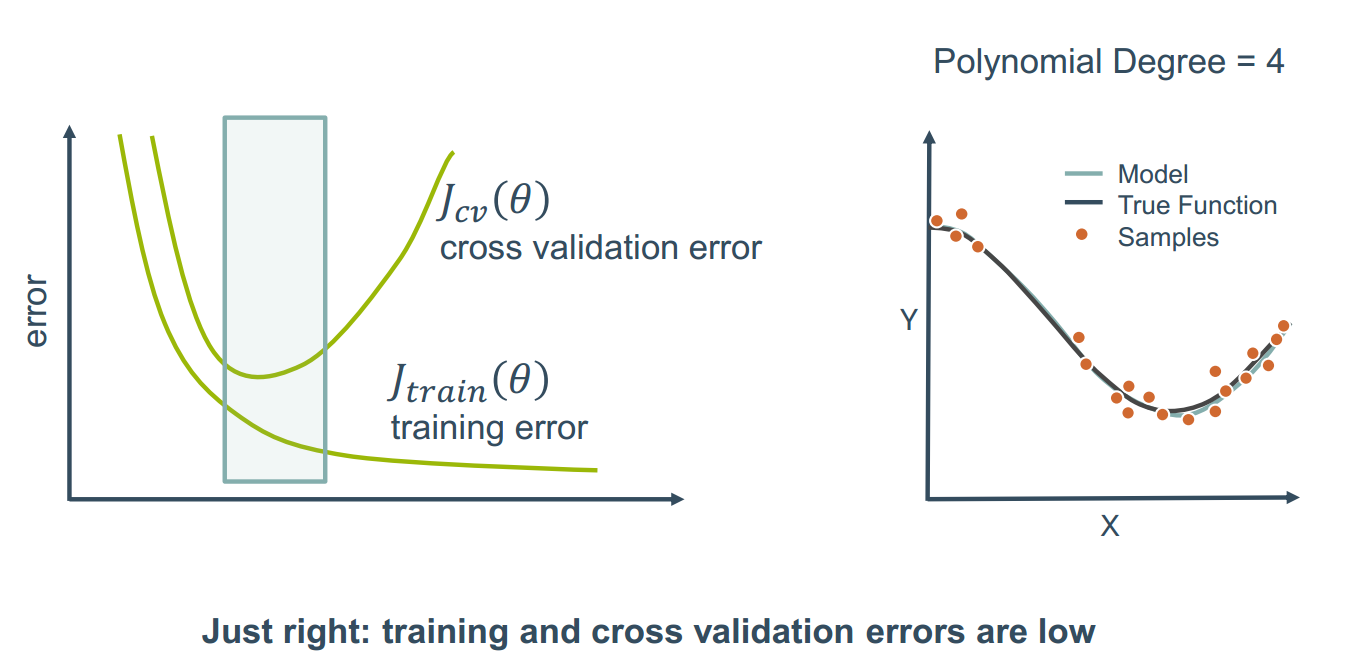
训练模式如下图


3.错误分析
模型复杂程度与错误率有一定关系

cross validation error 是交叉验证错误,发生在训练好的模型在测试的时候
training error 是训练错误,发生在训练模型的时候
从这个角度再去看拟合不足,适中与过拟合的情况


计算交叉错误得分

线性回归
1.简介
即尝试寻找一条直线用来预测输入X与输出Y的关系,训练完成后,通过输入想要预测的X就可以获得预测值Y。

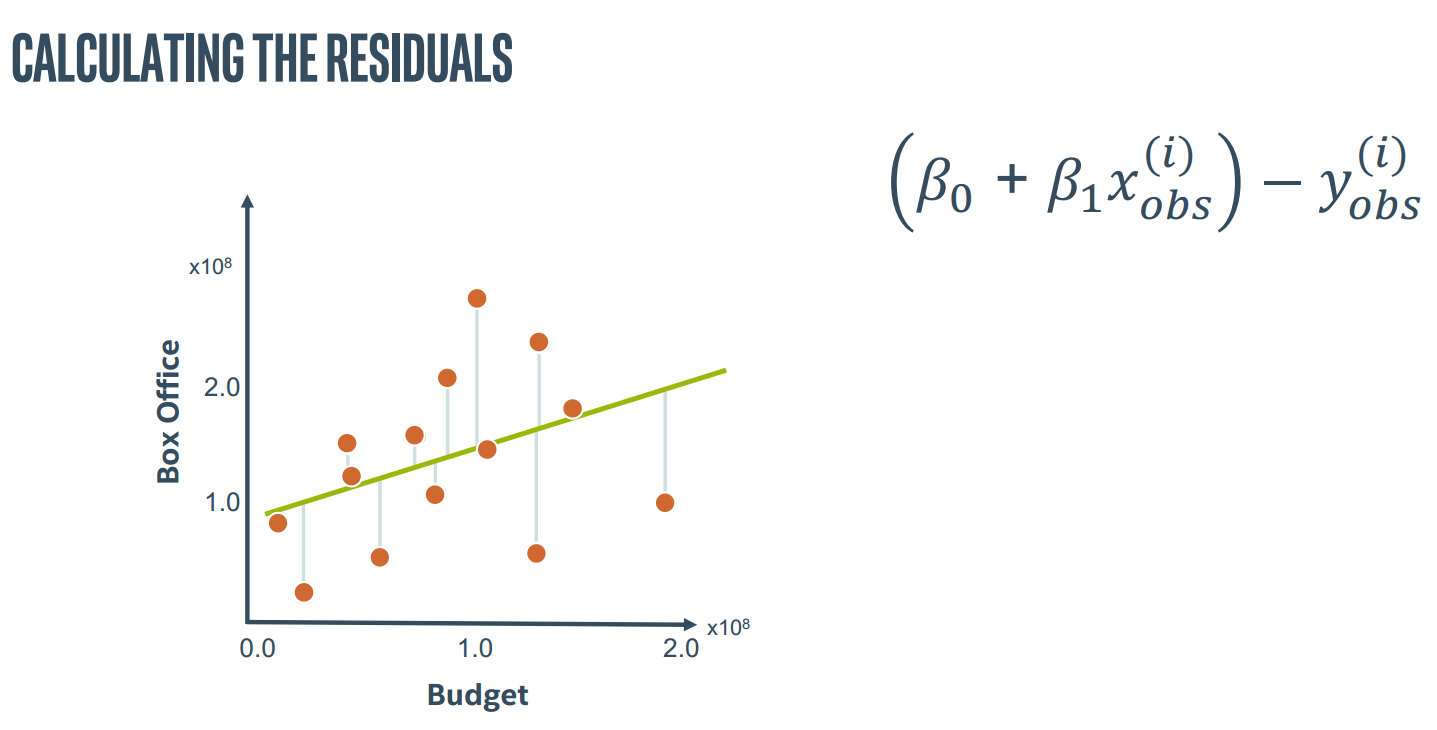
2.偏差
计算偏差可以是简单的Y_predict-Y_observe
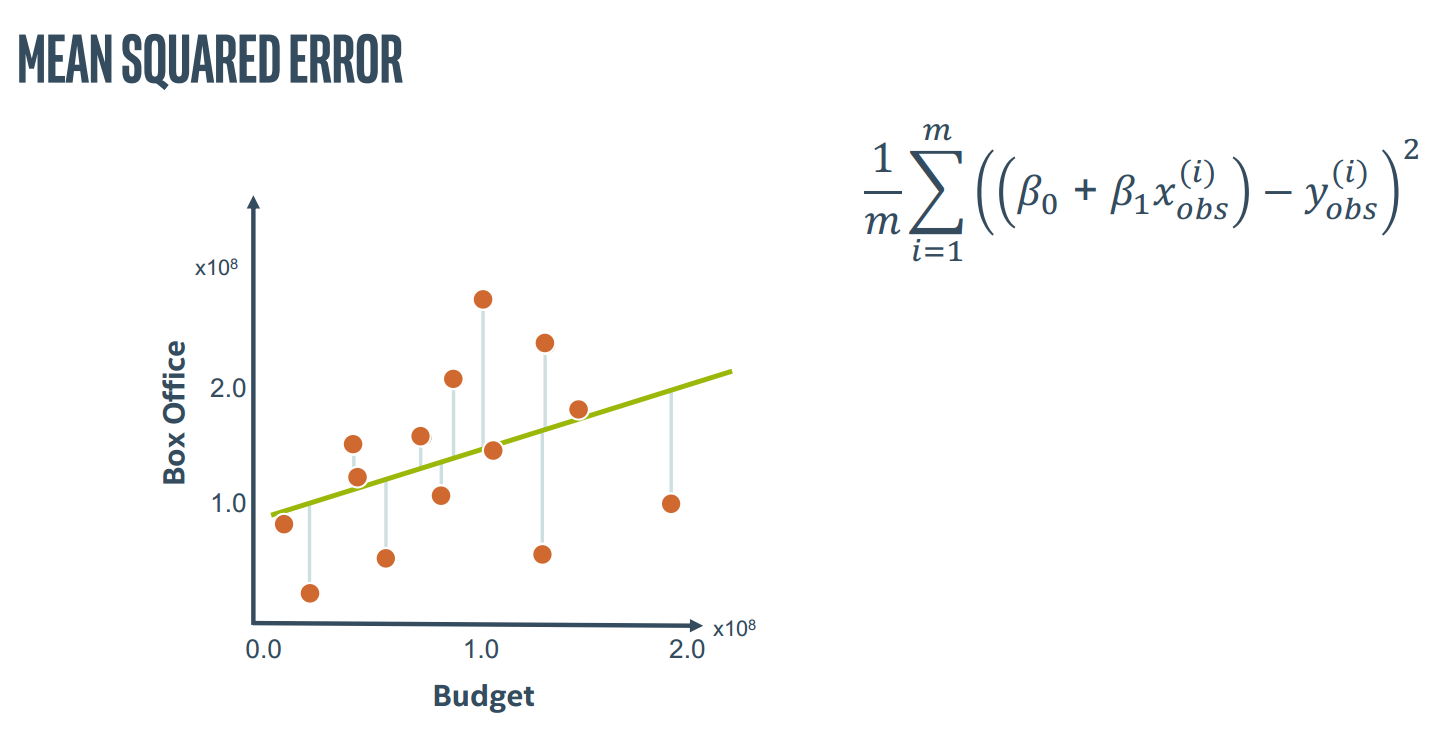
可以计算错误平均方差
这里引入成本函数的概念,通过该函数判断 β0与β1是否合适

因此我们就有了如下训练方案
(1)使用成本函数判断当前模型效率
(2)设计多种不同的模型
(3)比较这些模型得出效果最好的那一个
关于错误检测还有其他三种方法

3.线性回归与KNN比较
| 线性回归 | KNN |
| 拟合时设计最小化成本(速度慢) | 拟合时设计存储训练数据(速度快) |
| 模型参数少(记忆效率高) | 模型参数多(记忆密集) |
| 预测速度快 | 预测速度慢 |
4.线性回归实例

高级线性回归
1.转换
比例尺缩放本身就是一种特征转换

我们往往以为我们提供的数据是正态分布的,但可能它们其实是很偏的,数据转换就可以解决这个问题
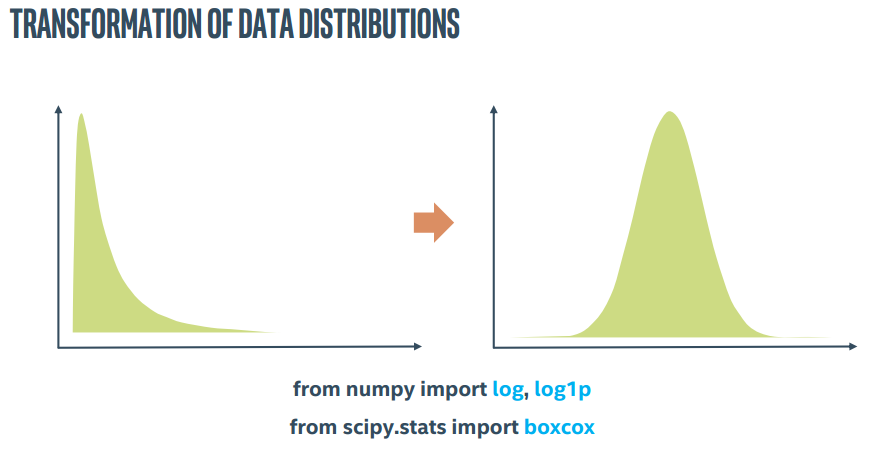
特征的类型可能是连续的数值类型,对应转换可变成标准缩放、最大最小缩放
也可能是二元类型(eg:真、假),可转换为01(one-hot encoding)
from sklearn.preprocessing import LabelEncoder, LabelBinarizer, OneHotEncoder
也可能是离散的有序类型(比如电影差、一般、普通、良、优秀评级),对应转换为(1,2,3,4,5)
from sklearn.feature_extraction import DictVectorizer
from pandas import get_dummies
2.多项式特征
回归分析不一定建立的是一条回归直线

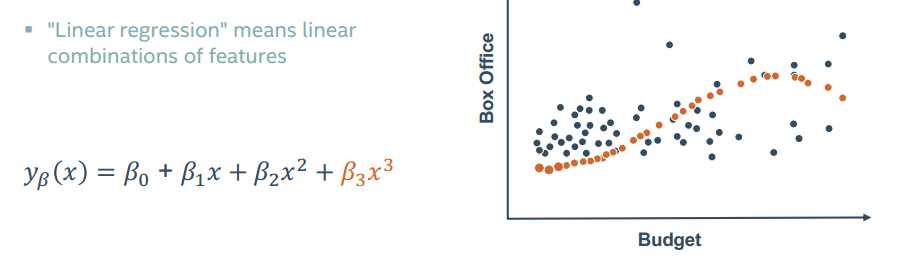
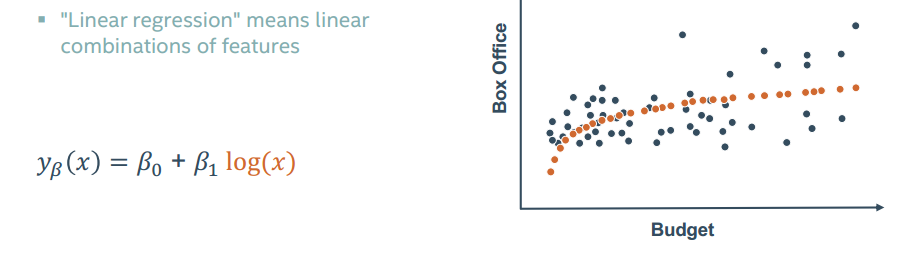
甚至还可以增加变量

那么如何才能选择正确的回归关系呢?
挨个挨个试吧
最后给个实例

Q1

问题1:使用pandas导入数据,销售价格将作为我们的预测值。价差不同数据类型的数量。

Q2

问题2(看不懂啊。。。):处理多列数据时要确保每一列都能正确地编码。

完全不懂。。。
Q3

问题3:让我们创建一个新的数据集,其中所有上述分类特征将是单热编码的。 我们可以拟合这些数据,看看它如何影响结果。使用dataframe .copy()方法为one-hot编码创建数据帧的完全独立副本。在这个新的数据帧上,对每个适当的列进行one-hot编码,然后将其添加回数据帧。 确保已删除原始列。对于非热编码的数据,请删除字符串分类的列。对于第一步数字编码字符串分类,可以使用Scikit-learn; s LabelEncoder或DictVectorizer。 然而,前者可能更容易,因为它不需要为每个类别指定数值,并且我们将对所有数值进行one-hot编码。


勉强分析。。应该是对string类型进行统计,编码,然后删掉。快去请卢来佛祖。。。
Q4

问题4:对每个数据集分别切分测试集与训练集,确保使用同样的方式拆分。对于每个数据集进行基本线性回归的你和训练,计算相应模型的测试集与训练集的均方误差。

注意到one-hot编码错误率在训练集与测试集中差别巨大,这是因为过拟合,下一讲介绍如何处理它。
Q5

问题5:对于每个数据集使用标准缩放、最大最小缩放或者最大绝对值缩放来处理非热数据,比较测试集上的误差。

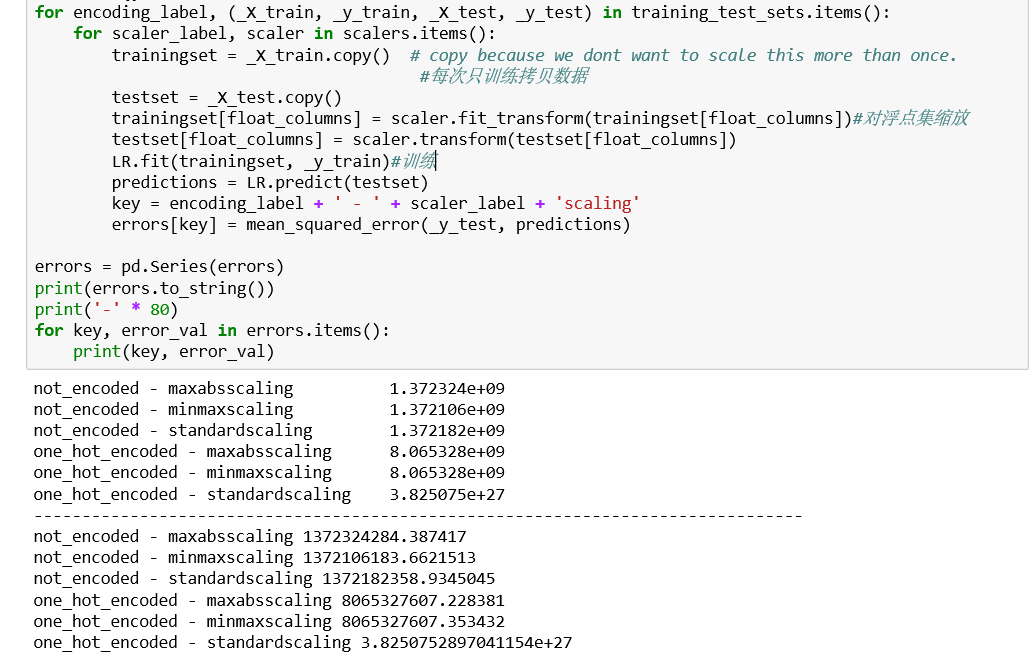
发现缩放对于非热编码影响不大,但是标准缩放对于one-hot编码具有巨大影响,直接不能用了。
Q6

问题6:画图预测模型
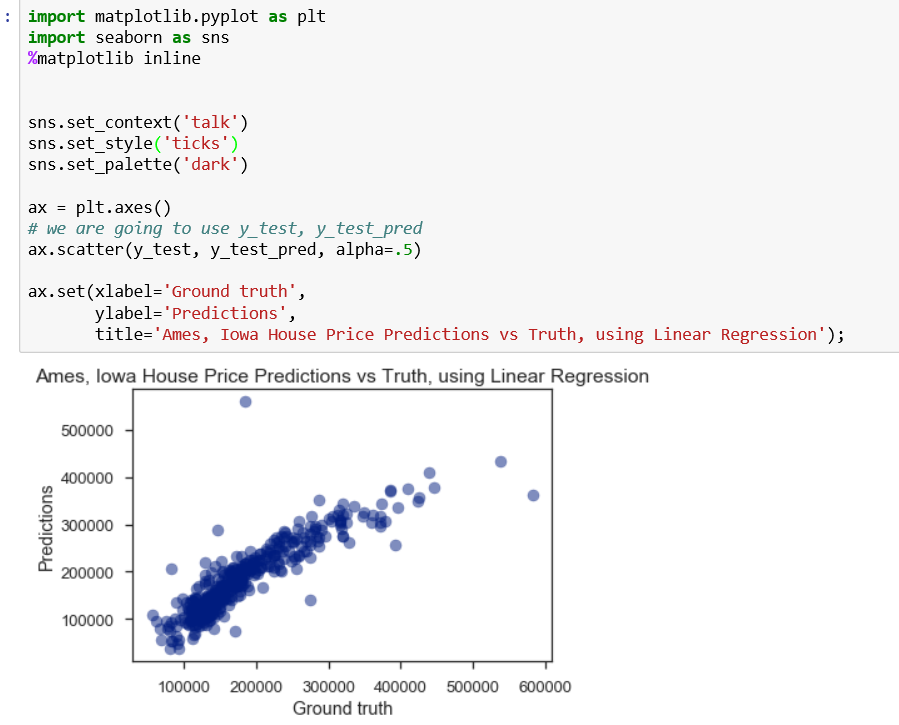
seaborn画图确实好看