import tensorflow as tf input1 = tf.constant(1) print(input1) input2 = tf.Variable(2,tf.int32) print(input2) input2 = input1 sess = tf.Session() print(sess.run(input2))
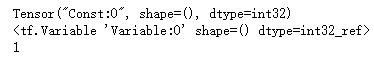
import tensorflow as tf input1 = tf.placeholder(tf.int32) input2 = tf.placeholder(tf.int32) output = tf.add(input1, input2) sess = tf.Session() print(sess.run(output, feed_dict={input1:[1], input2:[2]}))

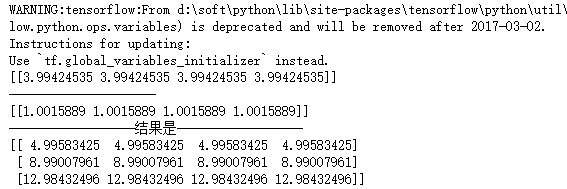
import numpy as np import tensorflow as tf """ 这里是一个非常好的大数据验证结果,随着数据量的上升,集合的结果也越来越接近真实值, 这也是反馈神经网络的一个比较好的应用 这里不是很需要各种激励函数 而对于dropout,这里可以看到加上dropout,loss的值更快。 随着数据量的上升,结果就更加接近于真实值。 """ inputX = np.random.rand(3000,1) noise = np.random.normal(0, 0.05, inputX.shape) outputY = inputX * 4 + 1 + noise #这里是第一层 weight1 = tf.Variable(np.random.rand(inputX.shape[1],4)) bias1 = tf.Variable(np.random.rand(inputX.shape[1],4)) x1 = tf.placeholder(tf.float64, [None, 1]) y1_ = tf.matmul(x1, weight1) + bias1 y = tf.placeholder(tf.float64, [None, 1]) loss = tf.reduce_mean(tf.reduce_sum(tf.square((y1_ - y)), reduction_indices=[1])) train = tf.train.GradientDescentOptimizer(0.25).minimize(loss) # 选择梯度下降法 init = tf.initialize_all_variables() sess = tf.Session() sess.run(init) for i in range(1000): sess.run(train, feed_dict={x1: inputX, y: outputY}) print(weight1.eval(sess)) print("---------------------") print(bias1.eval(sess)) print("------------------结果是------------------") x_data = np.matrix([[1.],[2.],[3.]]) print(sess.run(y1_,feed_dict={x1: x_data}))
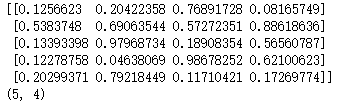
import numpy as np aa = np.random.rand(5,4) print(aa) print(np.shape(aa))
import tensorflow as tf import numpy as np """ 这里是一个非常好的大数据验证结果,随着数据量的上升,集合的结果也越来越接近真实值, 这也是反馈神经网络的一个比较好的应用 这里不是很需要各种激励函数 而对于dropout,这里可以看到加上dropout,loss的值更快。 随着数据量的上升,结果就更加接近于真实值。 """ inputX = np.random.rand(3000,1) noise = np.random.normal(0, 0.05, inputX.shape) outputY = inputX * 4 + 1 + noise #这里是第一层 weight1 = tf.Variable(np.random.rand(inputX.shape[1],4)) bias1 = tf.Variable(np.random.rand(inputX.shape[1],4)) x1 = tf.placeholder(tf.float64, [None, 1]) y1_ = tf.matmul(x1, weight1) + bias1 #这里是第二层 weight2 = tf.Variable(np.random.rand(4,1)) bias2 = tf.Variable(np.random.rand(inputX.shape[1],1)) y2_ = tf.matmul(y1_, weight2) + bias2 y = tf.placeholder(tf.float64, [None, 1]) loss = tf.reduce_mean(tf.reduce_sum(tf.square((y2_ - y)), reduction_indices=[1])) train = tf.train.GradientDescentOptimizer(0.25).minimize(loss) # 选择梯度下降法 init = tf.initialize_all_variables() sess = tf.Session() sess.run(init) for i in range(1000): sess.run(train, feed_dict={x1: inputX, y: outputY}) print(weight1.eval(sess)) print("---------------------") print(weight2.eval(sess)) print("---------------------") print(bias1.eval(sess)) print("---------------------") print(bias2.eval(sess)) print("------------------结果是------------------") x_data = np.matrix([[1.],[2.],[3.]]) print(sess.run(y2_,feed_dict={x1: x_data}))
