1.3 项目计划
第一周:深入学习和了解神经网络的工作原理,学习卷积的相关理论。
第二周:使用python的TensorFlow库,编写神经网络深度学习代码,搭建神经网络层,并且了解其工作原理和相关的计算、相关参数的传递等,到htttps://www.kaggle.com/moltean/fruits下载fruits压缩包,对数据进行初步的处理。
第三周:使用TensorFlow搭建卷积神经网络,采用训练集数据对测试集数据进行预测;完成数据可视化,显示每个文件夹中第5张图片。使用Tensorboard可视化训练过程的一系列参数,并加以分析;使用相同的Optimizer对网络进行优化,并讨论学习率的影响;完成基于Keras使用现成的VGG19网络进行迁移学习,设计并优化全连接层,讨论分类结果。
第四周:演示项目结果,并课堂答辩。
2.项目简介
2.1 数据集介绍
项目文件说明:
1、训练集文件Traning和测试文件Test都有77个子文件,每个子文件代表一种水果类别(Class),故共有77个类别或者说是标签(Label)每个文件夹内包含去除背景的高质量水果图片。项目的目标就是根据训练集Traning训练好的模型对数据集之外的Test进行预测。
2、papers是数据提供者的工作总结,可供大家参考。
3、test-multiply_fruits是项目选作的内容。涉及到图像分割和识别。
2.2 数据可视化
1、导入相应要用到的python包:



1、a、定义一个保存所有训练集图片名称的列表
b、逐个子文件夹读取里面的图片名称
c、逐个对每个子文件夹进行字符串的拆分,并且判断拆分后得到的列表首个字符串是否是数字
d、如果是则把它变为int类型,并且保存到定义的nr列表中
e、如果不是则把它第二个元素变为int类型,并且保存到定义的r列表中
f、对nr列表进行升序排序
g、逐个地读取排序后的元素
h、并且把它变回字符串,拼接成原来训练图片格式命名
i、对r列表进行升序排序
j、逐个地读取排序后的元素
k、并且把它变回字符串,拼接成原来训练图片格式命名
l、对r2列表进行升序排序
m、逐个地读取排序后的元素
n、并且把它变回字符串,拼接成原来训练图片格式命名
o、使用定义的allsortImageName列表使用append方法保存每次上面整合好的列表

部分截图:


可以对比看到:现在列表图片名字的排列顺序和电脑文件夹图片显示图片的顺序是一一对应的了。
1、a、逐个读取每个水果类的子文件夹名称
b、在每个水果类名称的前面加上"label:"这样的子串
c、依次读取每个子文件夹里面的第5张图片
d、将图形分割成11行7列的格子
e、设置每个小格子的尺寸是原来的10倍
f、获取ax对象
g、从上到下,从左到右依次获取每个小格子对象
h、在每个小格子中依次显示每张图片
i、设置每个格子中的每张张图片的x坐标轴为空,也就是不显示x坐标轴
j、设置每个格子中的每张张图片的y坐标轴为空,也就是不显示y坐标轴
k、设置每个格子中的每张图片都不显示四周的框框
l、给每个格子中的每张图片依次设置标题,并设置字体大小为7
m、设置整一个大的画图板11*7的x坐标为空,也就是不显示大画板的x坐标轴
n、设置整一个大的画图板11*7的y坐标为空,也就是不显示大画板的y坐标轴
O、设置整一个大的画图板11*7的边框的颜色为空,也就是不显示外边框

2.3深度学习的训练目标
1、使用TensorFlow搭建卷积神经网络,采用训练集数据对测试集数据进行预测;
2、完成数据可视化,显示每个文件夹中第5张图片。
3、使用Tensorboard可视化训练过程的一系列参数,并加以分析;
4、使用相同的Optimizer对网络进行优化,并讨论学习率的影响;
5、完成基于Keras使用现成的VGG19网络进行迁移学习,设计并优化全连接层,讨论分类结果。
3. 数据预处理
3.1 读取图像数据
读取训练数据集:
a、逐个子文件夹读取训练图片
b、按照之前排好序的图片名字依次读取对应的类别(子文件夹)里面的图片
c、把每个每个子文件夹里面的数据保存到one列表,并且依次把one里面的内容保存到trainData列表
部分输出:

读取测试数据集:
a、读取测试数据集的所有文件名称,并且把所有的子文件夹里面的所有图片名称保存到testallFruitsImageName列表中。

a、定义一个保存所有训练集图片名称的列表
b、逐个子文件夹读取里面的图片名称
c、逐个对每个子文件夹进行字符串的拆分,并且判断拆分后得到的列表首个字符串是否是数字
d、如果是则把它变为int类型,并且保存到定义的nr列表中
e、如果不是则把它第二个元素变为int类型,并且保存到定义的r列表中
f、对nr列表进行升序排序
g、逐个地读取排序后的元素
h、并且把它变回字符串,拼接成原来训练图片格式命名
i、对r列表进行升序排序
j、逐个地读取排序后的元素
k、并且把它变回字符串,拼接成原来训练图片格式命名
l、对r2列表进行升序排序
m、逐个地读取排序后的元素
n、并且把它变回字符串,拼接成原来训练图片格式命名
o、使用定义的testallsortImageName列表使用append方法保存每次上面整合好的列表

读取测试数据集:
a、逐个子文件夹读取训练图片
b、按照之前排好序的图片名字依次读取对应的类别(子文件夹)里面的图片
c、把每个每个子文件夹里面的数据保存到one列表,并且依次把one里面的内容保存到testData列表
部分输出:

3.2 图像数据预处理
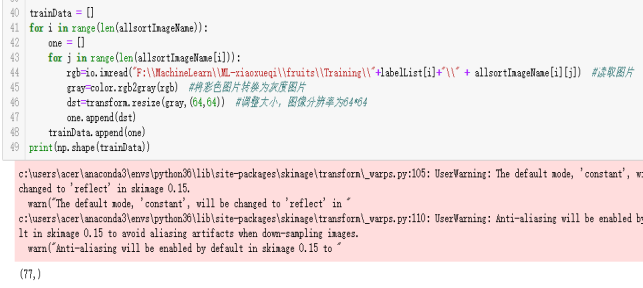
训练集图片转灰度图
(1)逐个子文件夹文件依次读取。
(2)将彩色的图片转变为灰度图
(3)接着再将灰度图片转变成64*64的大小
(4)依次将每个子文件夹里面处理过的灰度图片保存到one列表
(5)最后将每个子文件处理后的图片数据保存的trainData列表里
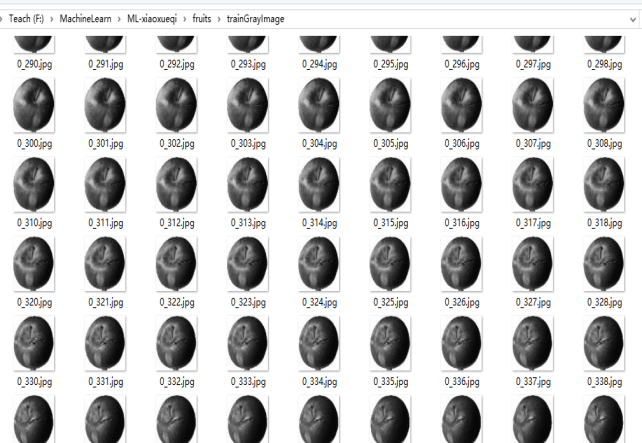
将上面的灰度图数据保存到硬盘
(1)逐行逐列地读取上面trainData的数据,通过io.imsave函数将图片保存,并且将每张图片的类别用数字记录下来。

部分截图:
测试集图片转灰度图
(1)逐个子文件夹文件依次读取。
(2)将彩色的图片转变为灰度图
(3)接着再将灰度图片转变成64*64的大小
(4)依次将每个子文件夹里面处理过的灰度图片保存到one列表
(5)最后将每个子文件处理后的图片数据保存的testData列表里

将上面的测试灰度图数据保存到硬盘
(1)逐行逐列地读取上面testData的数据,通过io.imsave函数将图片保存,并且将每张图片的类别用数字记录下来。

部分截图:

加载保存的训练图片和测试图片数据:
(1)导入相应的python包
(2)读取图片所在的目录,获取每张图片的名称
(3)将每张图片保存到变量trainDataDirList和testDataList列表里面


加载测试图片数据集合训练图片数据集的标签:
(1)直接通过numpy包加载上面保存灰度图片时,一起保存的.npy文件即可。
