1、再次认真思考之后,不再将图片灰度化,图片的通道数仍然保持是3,为了加快运行的速度,并且相应地把图片的尺寸改成了32*32。为了节省时间这里也加入了TensorBoard可视化代码。具体代码如下:







代码运行结果如下(部分输出):
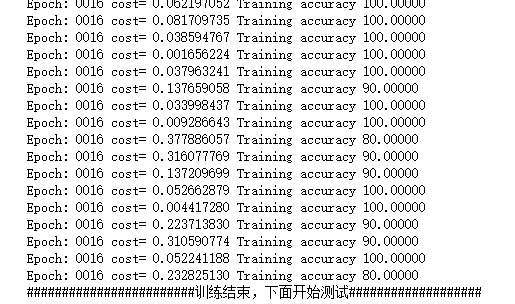

可以看到现在代码的结果非常好了,训练准确率也明显高出了许多,达到了91%左右。而测试的准确率也达到了90%左右。通过多次尝试和修改,我觉得:图片处理应该根据图片的实际情况来搭建神经网络,之前一直都是习惯把图片灰度处理才进行训练,但这次实验的图片明显是修改了图片的通道数,会对图片的训练造成很的特征丢失的问题,所以即使是64*64,100*100这样大尺寸规模的灰度图像训练的结果却比不上彩色三通道尺寸为32*32的训练图片数据效果。
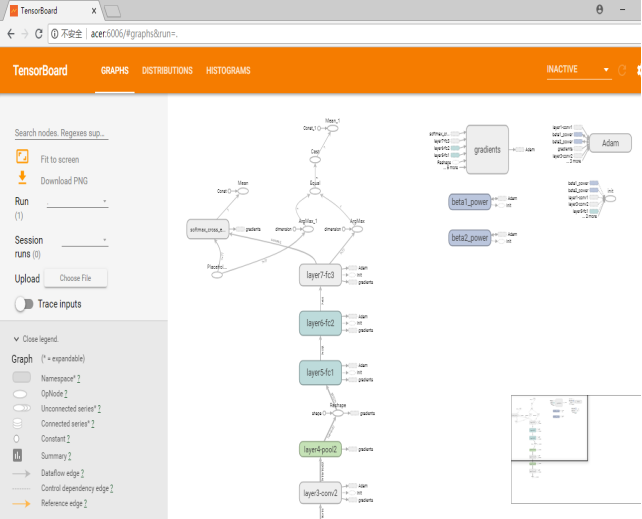
上面的截图展示的是整个神经网络参数的变化过程,也是整个代码运行时的一个流程,展示的内容主要有:卷积层、池化层、全连接层、权值、偏置等参数变化。

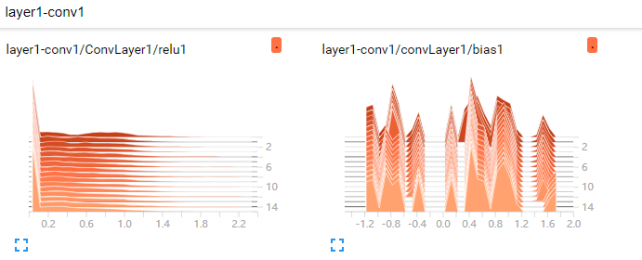
这是第一次卷积relu1和偏置bias1的结果。可以看到偏置基本在这个卷积过程中变化不是很大,波动也不大。而relu1变化不大,但开始与真实值的差距比较明显,后来这个差距就慢慢变小了,从这里也可以看出:随着多次卷积之后准去率提高了。
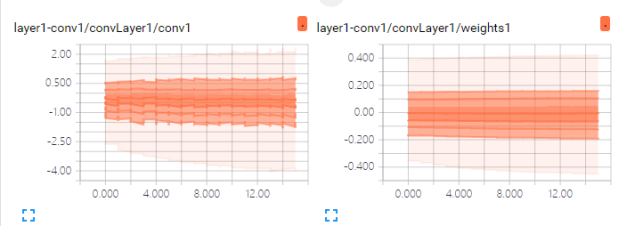

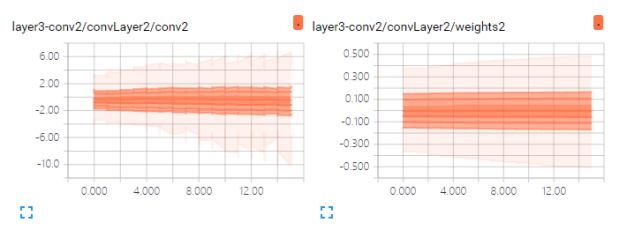
上面两幅图分别是:第一层卷积的结果conv1和第一次卷积的权值weights1的可视化结果。从conv1这幅图中可以很清楚地看到外面的线条波动较大,而里面的相对就平缓许多。并且纵坐标的值很接近于0,而weights1图中,可以看到几乎每次的卷积的第一层卷积的权值几乎都是不变的,并且随着卷积的次数增加,权值慢慢也是趋向0.这是因为每次卷积之后的准确率慢慢提高了。

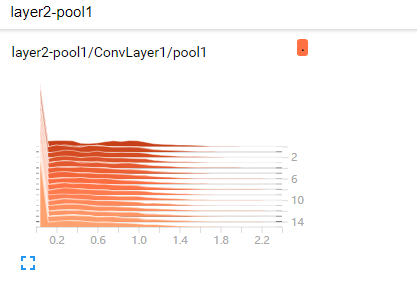
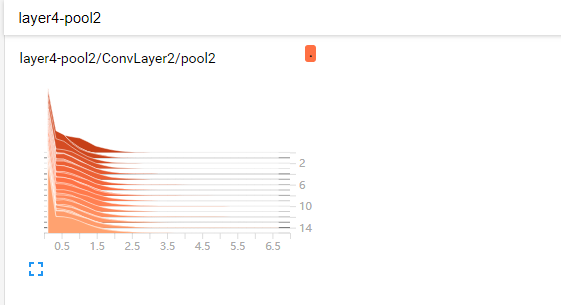
上面这幅是第一次池化数据的可视化参数图。可以看到每次的这层池化数据都保持着稳定的变化。
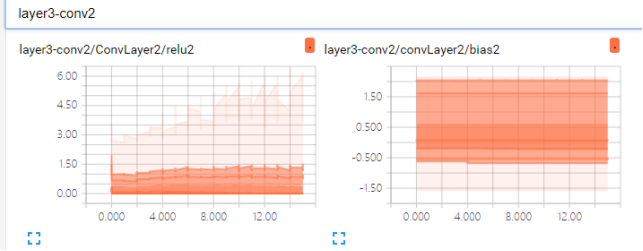
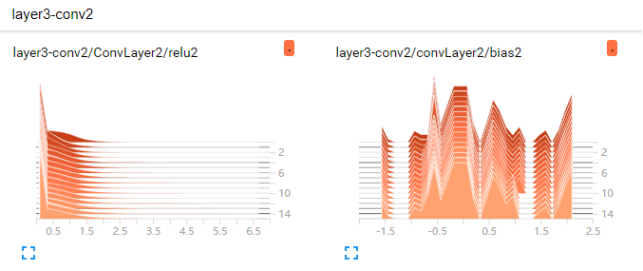
上面的两幅图分别是第二次卷积的relu2值和bias2值可视化的结果。可以看到