有时候,手工生成 Pandas 的 DataFrame 数据是件非常麻烦的事情,所以我们通
常会先把数据保存在 Excel 或数据库中,然后再把数据导入 Pandas 。 另 一种情况是抓
取网页中成千上万的表格数据导入 Pandas ,作为 DataFrame 数据。
Pandas 常用的导入数据方法有:

下面,我们示范用 read html 方法抓取网页中的表数据。
Pandas 的 read_html 方法会用到 html5lib 套件,可通过命令来安装:pip install html5lib
以 http://value500.com/M2GDP.html 网页中的中国历年 GDP 数据表为例
进行说明 :
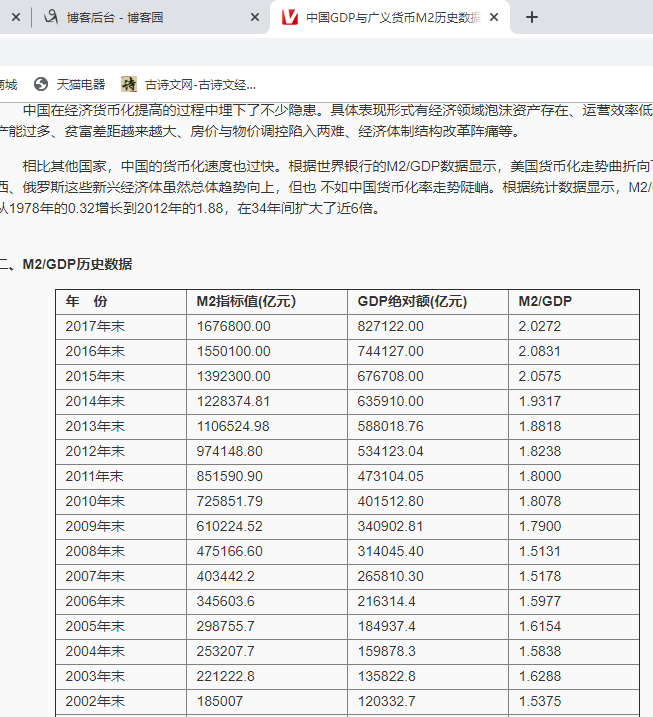
现在我们只需两行代码就能抓到网页中所有的表格数据 : import pandas as pd tables= pd . read html ( ” http://value500.com/M2GDP .html”)
其中, read html 方法返回 DataFrame 列表,每一个元素是网页中 一个表格。网
页中的表格很多,如何知道哪一个表格才是我们要抓取的呢?这需要我们以手动方
式在网页的原代码中通过“<table ”搜索, 查看第几个表格才是要抓取的 。手动方式
既麻烦又不精确,以下程序可显示所有表格的前 5 行数据:
import pandas as pd tables = pd.read_html("http://value500.com/M2GDP.html") n = 1 for table in tables: print("第 " + str(n) + " 个表格:") print(table.head()) print() n += 1

............

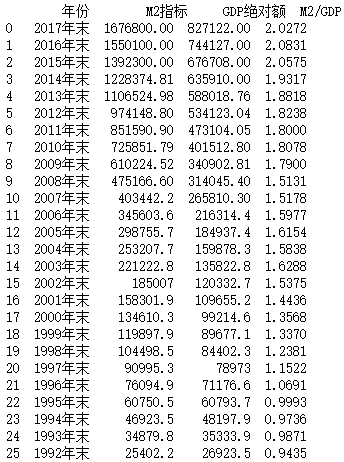
浏览程序的执行结果,我们可以看到要抓取的表格是第20个表,系统自动编号 作为行、列标题,数据的第 l 行是标题行,第 2 行开始才是表格数据 。 了解了所抓表格的结构以后,即可抓取表格并将数据处理为需要的格式了!
在网页中抓取我国历年 GDP 数据
要求:先以 read htm l 方法抓取网页中包含我国历年 GDP 数据的表格,并删除
第 1 行数据,然后重新设置行、列标题
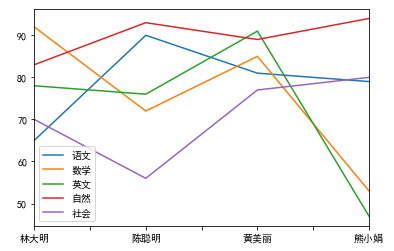
import pandas as pd tables = pd.read_html("http://value500.com/M2GDP.html") table = tables[19] table = table.drop(table.index[0:1]) table.columns = ["年份", "M2指标", "GDP绝对额", "M2/GDP"] table.index = range(len(table.index)) print(table)
绘制图形
为了让表格数据看起来一 日了然,有时我们需要把表数据绘制成统计图 。
Pandas 提供了图形绘制的功能,语法为 :
import pandas as pd datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]] indexs = ["林大明", "陈聪明", "黄美丽", "熊小娟"] columns = ["语文", "数学", "英文", "自然", "社会"] df = pd.DataFrame(datas, columns=columns, index=indexs) print(df) df.plot()