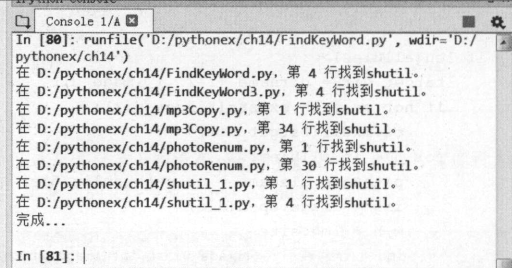
在多个文本文件中查找
我们首先来学习文本文件的查找字符 。 我们通过 os.walk 扩大查找范围,
查找指定目录和子目录下的文件。
应用程序总览
读取 当 前目录及子目录下的所有 PY 和 txt 文本文件,搜索这些文件中是否包含
指定的字符“ shutil ”。
import os
cur_path=os.path.dirname(__file__) # 取得当前路径
sample_tree=os.walk(cur_path)
keyword="shutil"
for dirname,subdir,files in sample_tree:
allfiles=[]
for file in files: # 取得所有 .py .txt 文件,存入 allfiles 列表中
ext=file.split('.')[-1]
if ext=="py" or ext=="txt":
allfiles.append(dirname +'/'+file)
if len(allfiles)>0:
for file in allfiles: # 读取 allfiles 列表所有文件
try:
fp = open(file, "r", encoding = 'UTF-8')
article = fp.readlines()
fp.close
line=0
for row in article:
line+=1
if keyword in row:
print("在 {},第 {} 行找到{}。".format(file,line,keyword))
except:
print("{} 无法读取..." .format(file))
print("完成...")
在 Word 文件中查找指定字符
接着我们来学习在 Word 文件中查找指定 的 字符。 对以 docx 为后缀 的 文件进行
搜索 , 需要先安装 python-docx 包 :
安装完毕后导入 do cx 包 , 再用 docx.Document() 方法创建 docx 对象来读取指
定的 do c x 文件,每个 doc x 文件包含多个 paragraphs 段落 , 可通过 text 属性来读取
paragraph s 段落的内容 。
例如 : 读取“简介 .do cx ”文件并显示所有段落内容。
import docx
doc = docx.Document("简介.docx")
for p in doc.paragraphs:
print(p.text)
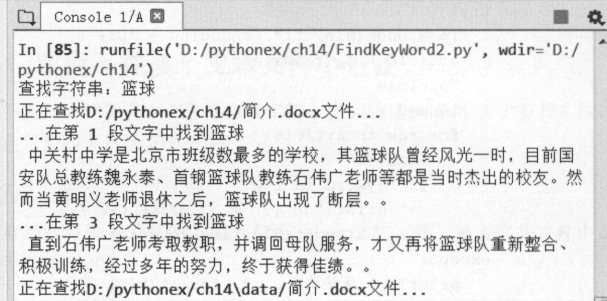
应用程序总览
读取当前目录及子目录下所有 docx 格式的 Word 文件,井在这些文件中查找是否
包含 “ 篮球 ” 字符。
import os,docx
cur_path=os.path.dirname(__file__) # 取得当前路径
sample_tree=os.walk(cur_path)
keyword="篮球"
print("查找字符串:{}" .format(keyword))
for dirname,subdir,files in sample_tree:
allfiles=[]
for file in files: # 取得所有.docx文件并存入 allfiles 列表中
ext=file.split('.')[-1]
if ext=="docx": # get *.docx to allfiles
allfiles.append(dirname +'/'+file)
for file in allfiles:
print("正在查找{}文件...".format(file))
try:
doc = docx.Document(file)
line=0
for p in doc.paragraphs:
line+=1
if keyword in p.text:
print("...在第 {} 段文字中找到{}
{}。".format(line,keyword,p.text))
except:
print("无法读取 {} 文件..." .format(file))
print("
查找完毕...")
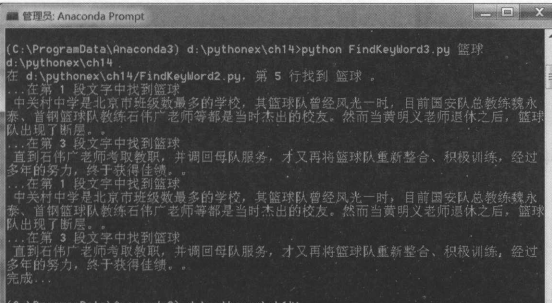
另 一种比较好的查找方式是在 Anaconda Prompt 窗口中 , 通过 python FindK.ey
Word3.py 命令行来执行查找字符的程序 。
例如:查找“ shutil ”字符 。

注意 : Python 应用程序 FindK.eyWord3.py 的路 径中不能包含中文路径,即 D: pythonex chl2 , 然后再在
Anaconda Prompt 窗口中进行执行 。 如下图:
import os,docx,sys
if len(sys.argv) == 1:
keyword="shutil"
print("语法:python FindKeyWord3.py 查找字符串
")
else:
keyword=sys.argv[1]
#cur_path=os.path.dirname(__file__) # 取得当前路径
cur_path=os.getcwd()
sample_tree=os.walk(cur_path)
print(cur_path)
for dirname,subdir,files in sample_tree:
allfiles=[]
for file in files: # 取得所有 .py .txt .docx文件,存入allfiles列表中
ext=file.split('.')[-1]
if ext=="py" or ext=="txt" or ext=="docx":
allfiles.append(dirname +'/'+file)
if len(allfiles)>0:
for file in allfiles: # 读取 allfiles 列表所有文件
try:
if file.split('.')[-1]=="docx": # .docx
doc = docx.Document(file)
line=0
for p in doc.paragraphs:
line+=1
if keyword in p.text:
print("...在第 {} 段文字中找到{}
{}。".format(line,keyword,p.text))
else: # .py or .txt
fp = open(file, "r", encoding = 'UTF-8')
article = fp.readlines()
fp.close
line=0
for row in article:
line+=1
if keyword in row:
print("在 {},第 {} 行找到 {} 。".format(file,line,keyword))
except:
print("{} 无法读取..." .format(file))
print("完成...")