import pandas as pd df = pd.read_json('/Users/chenyi/Documents/News_Category_Dataset.json', lines=True) df.head()
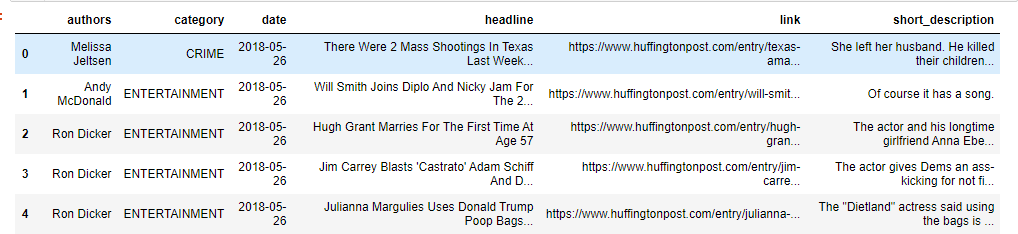
categories = df.groupby('category') print("total categories: ", categories.ngroups) print(categories.size())
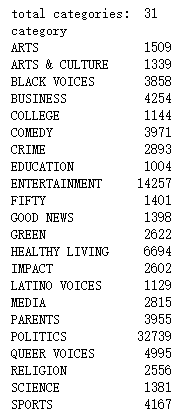
df.category = df.category.map(lambda x:"WORLDPOST" if x == "THE WORLDPOST" else x)
categories = df.groupby('category') print("total categories: ", categories.ngroups) print(categories.size())
from keras.preprocessing import sequence from keras.preprocessing.text import Tokenizer, text_to_word_sequence, one_hot df['text'] = df.headline + " " + df.short_description # 将单词进行标号 tokenizer = Tokenizer() tokenizer.fit_on_texts(df.text) X = tokenizer.texts_to_sequences(df.text) df['words'] = X
#记录每条数据的单词数 df['word_length'] = df.words.apply(lambda i: len(i)) #清除单词数不足5个的数据条目 df = df[df.word_length >= 5] df.word_length.describe()

def word2Frequent(sequences): word_index = {} for sequence in sequences: for word in sequence: word_index[word] = word_index.get(word, 0) + 1 return word_index word_index = word2Frequent(df.words) count = 10000 #将单词按照频率按照升序排序,然后取出排在第一万位的单词频率 s = [(k, word_index[k]) for k in sorted(word_index, key=word_index.get, reverse=True)] print(s[0]) frequent_to_index = {} for i in range(count): frequent_to_index[s[i][0]] = 9999 - i

# 将分类进行编号 categories = df.groupby('category').size().index.tolist() category_int = {} int_category = {} for i, k in enumerate(categories): category_int.update({k:i}) int_category.update({i:k}) df['c2id'] = df['category'].apply(lambda x: category_int[x])
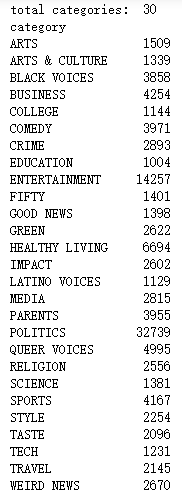
import numpy as np import keras.utils as utils from sklearn.model_selection import train_test_split import numpy as np def vectorize_sequences(sequences, dimension=10000): results = np.zeros((len(sequences), dimension)) for i in range(len(sequences)): for word in sequences[i]: if frequent_to_index.get(word, None) is not None: pos = frequent_to_index[word] results[i, pos] = 1.0 return results X = np.array(df.words) X = vectorize_sequences(X) print(X[0]) Y = utils.to_categorical(list(df.c2id)) # 将数据分成两部分,80%用于训练,20%用于测试 seed = 29 x_train, x_val, y_train, y_val = train_test_split(X, Y, test_size=0.2, random_state=seed)
from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(10000,))) model.add(layers.Dense(64, activation='relu')) #当结果是输出多个分类的概率时,用softmax激活函数,它将为30个分类提供不同的可能性概率值 model.add(layers.Dense(len(int_category), activation='softmax')) #对于输出多个分类结果,最好的损失函数是categorical_crossentropy model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
history = model.fit(x_train, y_train, epochs=20, validation_data=(x_val, y_val), batch_size=512)

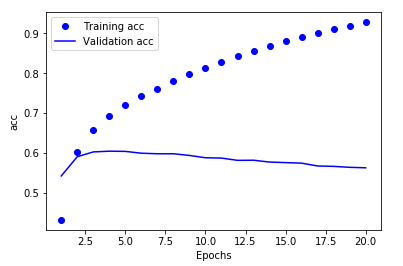
import matplotlib.pyplot as plt acc = history.history['acc'] val_acc = history.history['val_acc'] epochs = range(1, len(loss) + 1) plt.plot(epochs, acc, 'bo', label='Training acc') plt.plot(epochs, val_acc, 'b', label='Validation acc') plt.xlabel('Epochs') plt.ylabel('acc') plt.legend() plt.show()
from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(10000,))) model.add(layers.Dense(4, activation='relu')) #当结果是输出多个分类的概率时,用softmax激活函数,它将为30个分类提供不同的可能性概率值 model.add(layers.Dense(len(int_category), activation='softmax')) #对于输出多个分类结果,最好的损失函数是categorical_crossentropy model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) history = model.fit(x_train, y_train, epochs=20, batch_size=512)

results = model.evaluate(x_val, y_val) print(results)
