今天透一透java线程池底层
怎么用
创建线程池
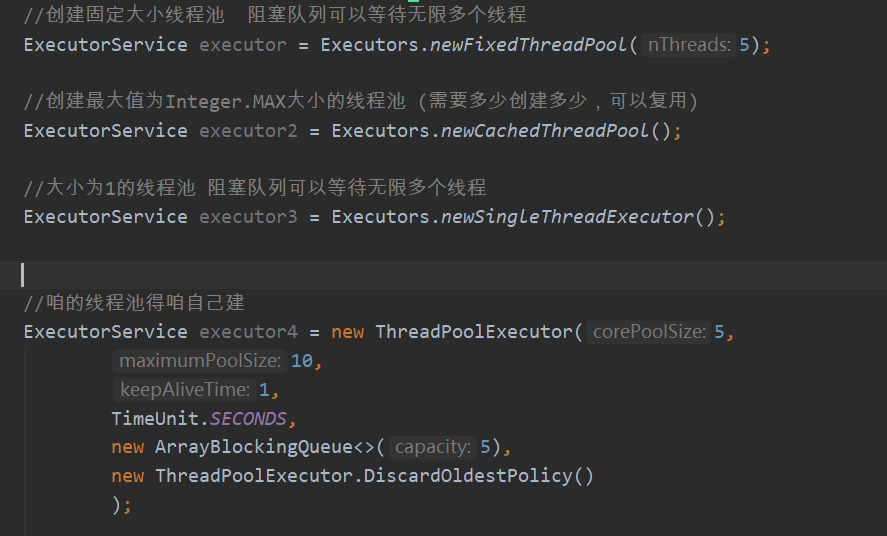
官方Executors工具类提供了三种创建方法 (but 阿里开发手册一种都不让用,因为各有弊端 不太适用于当前业务开发 so 让我们自己填参数创建,下边可以分析为啥不让)
executor4 就是自己创建线程池 需要参数(核心线程数,最大线程数,超过核心线程数存活时间,时间规格,阻塞队列,拒绝策略)
常用的·线程池使用方法

都是字面意思,无需多解释
源码分析
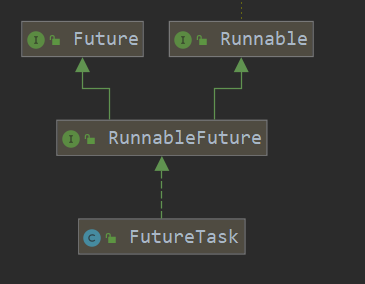
先看一下JUC下线程池继承关系
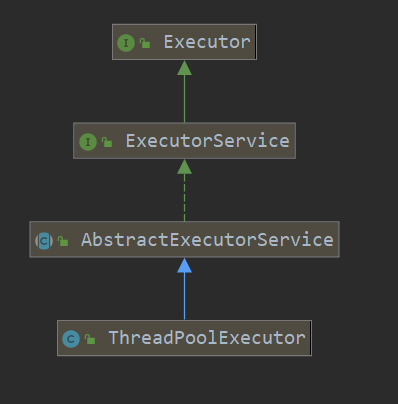
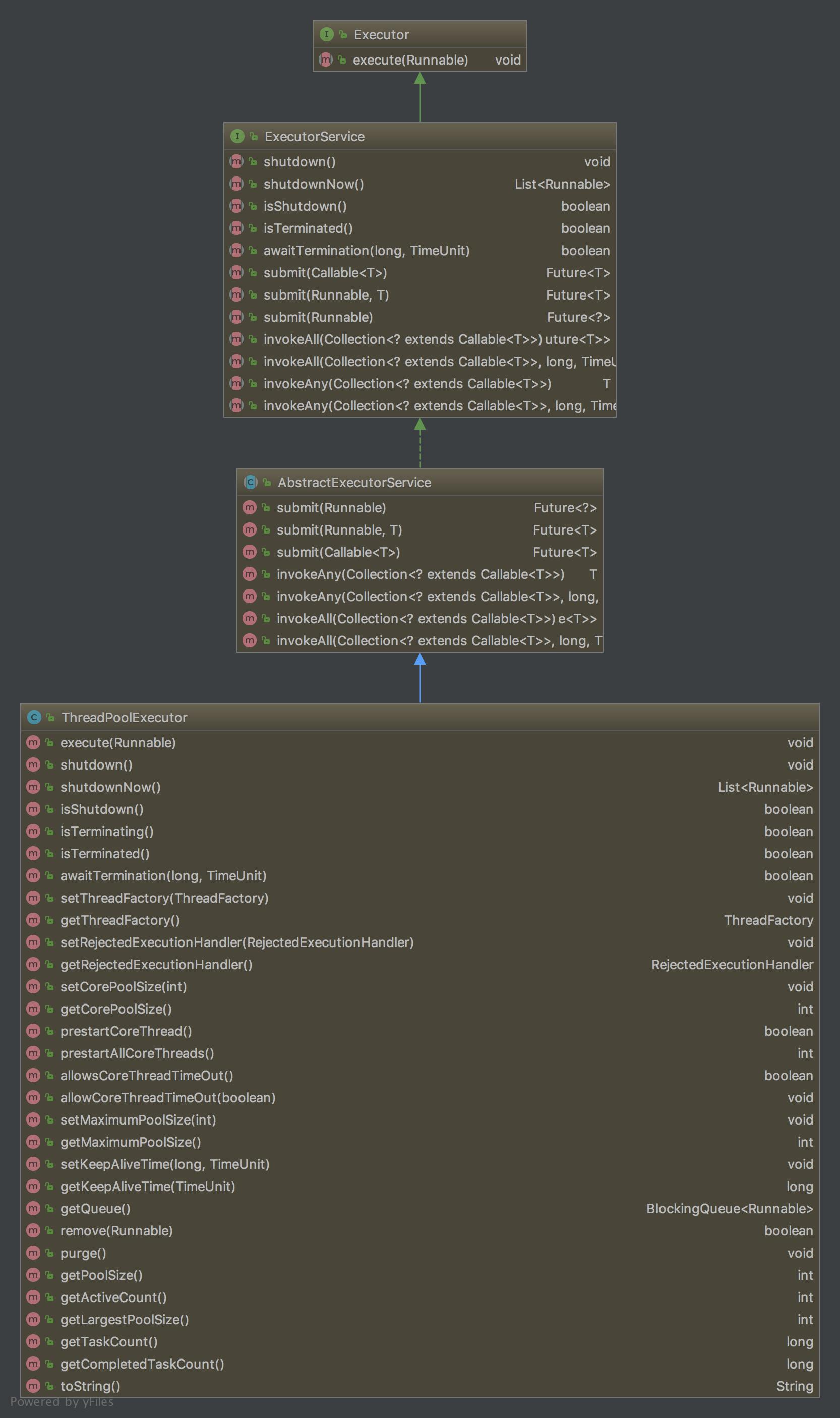
Executor接口就定义了一个execute()执行
ExecutorService接口定义了一系列线程池基本操作 三种submit()提交任务方式 关闭线程
AbstractExetutorService实现了三种submit()
ThreadPoolExecutor 该实现方法的都实现了
下面把ThreadPoolExecutor理一理
重要属性:

Doug Lea 采用一个 32 位的整数来存放线程池的状态和当前池中的线程数,其中高 3 位用于存放线程池状态,低 29 位表示线程数
1. ctl 原子判断当前RUNNNING是否为0
2.count_bits 这个值等于29,至于为什么不直接用29而是 Integer.Size - 3 , 大概是优雅吧 (个人觉得代码里直接用一些魔法值很糟糕)
3. capacity = (1 << 29) - 1 结果为29个1 代表了后29位 也就是线程数最大值 2^29
4. running = -1 << 29 结果相当于高三位的 -1 表示线程池正常运行状态
5. shutdown = 0 << 29 结果相当于高三位的0 表示线程池关闭,不能提交新任务,可以继续执行完队列中剩余任务
6. stop = 1 << 29 结果相当于高三位的1 表示线程池立即关闭,不能提交新任务,队列中剩余任务不再执行
7. runStateOf(int c) 将c的低29位修改为0,得到了线程池运行状态
8.workerCountOf(int c) 将c的高3位修改为0,得到worker的数量,也就是当前线程池的线程个数
一个重要内部类 Worker
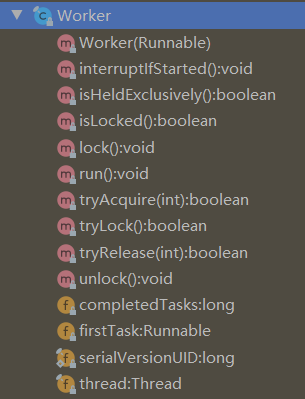
显然,线程池具体负责干活的就是Worker,一个Worker内部存着一个线程thread,通过内部thread来做任务,还有一个属性firstTask可以用来临时存一下任务
Worker又继承了AQS,实现了lock() unlock()等方法,独占锁,这个锁主要控制当该Worker执行任务时,避免被中断.
ThreadPoolExecutor基本原理:
当提交一个任务时,判断当前线程池线程数,如果当前线程数小于coreSize核心线程数,直接创建一个Worker,把任务提交给他让他执行。
如果当前线程数大于coreSize核心线程数,将任务加入到阻塞队列。
如果阻塞队列达到最大值,创建不大于maxSize大小的线程去执行阻塞队列的任务。
如果线程数达到max大小,阻塞队列也满了,直接走拒绝策略。
拒绝策略ThreadPoolExecutor自带内部类有四种:1 直接抛异常,2 不处理,3 用当前调用的线程来执行任务,4 抛弃掉阻塞队列队头任务 加入当前任务。 一般默认 不处理
over,下面进行源码解析
源码分析:
1. submit(Runnbale) submit(Callable) submit(Runnable,T result) AbstractExecutorService重载了submit()三种实现
区别 :没有返回值,返回结果是自己传进来的,用callable的执行结果返回 具体实现都是一样的
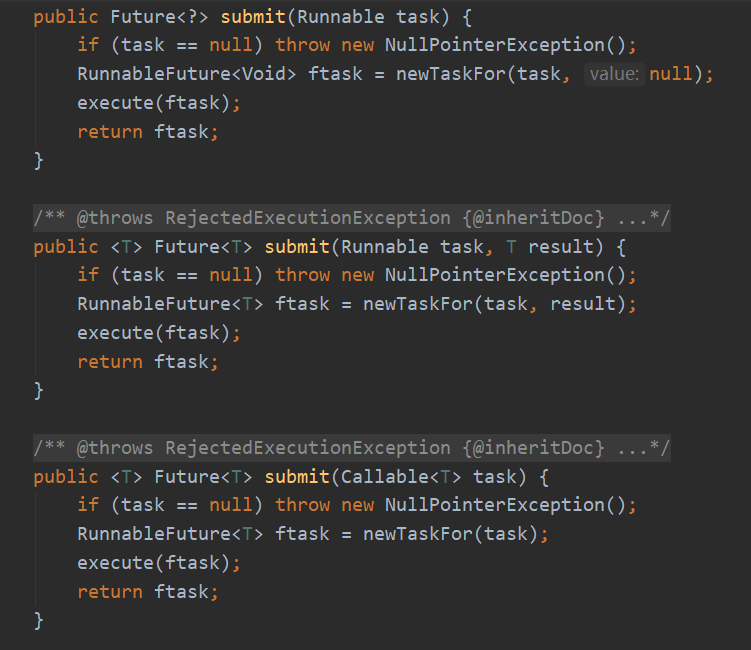
先判断传进来的task是否null
创建了一个RunnableFuture对象,这是个同时继承了Runnable和Future的接口,其子类FutureTask由newTaskFor()创建
包装好的FutureTask这个任务交给execute()方法执行,
最后将FutureTask当作Future的子类返回。
(Runnable的实现负责了做任务,Future的实现负责了获取结果。巧妙FutureTask在将其结合既执行又获取结果,适配器模式是你吗?)
newTaskFor()

new FutureTask()

2.execute(Runnable) 最重要的方法就是这个了,Executor原始接口的本名方法,各种submit()其实最后也是交给他做任务,他为啥这么强?
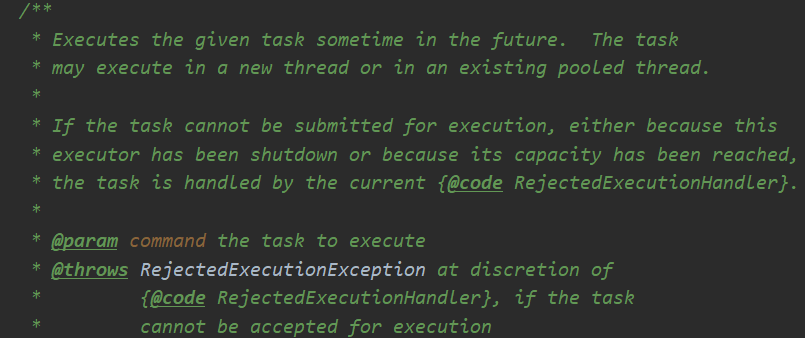 执行给定的任务在某个时候。任务可能交给一个新的线程执行或者已经存在线程池中的线程执行
执行给定的任务在某个时候。任务可能交给一个新的线程执行或者已经存在线程池中的线程执行
如果因为执行者已经关闭了,或者它的容量已经满了导致任务不能提交了,交给拒绝策略处理。
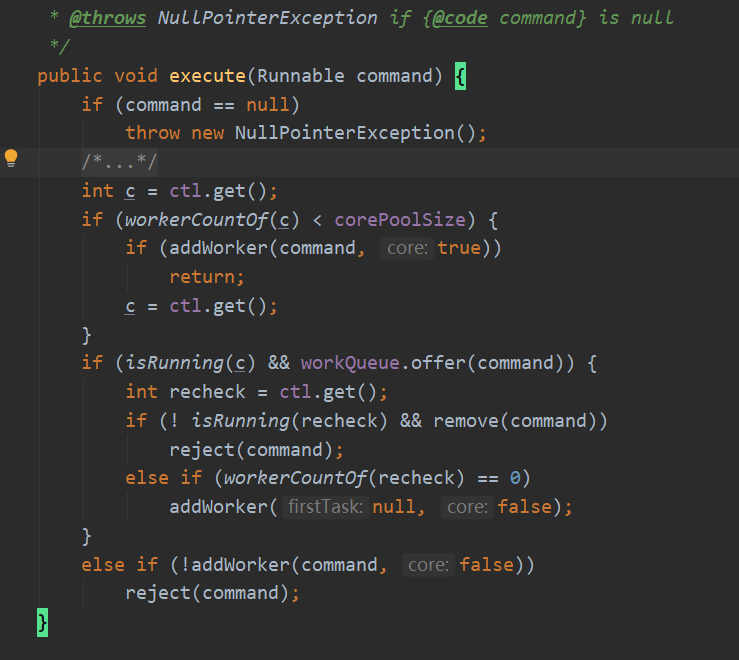
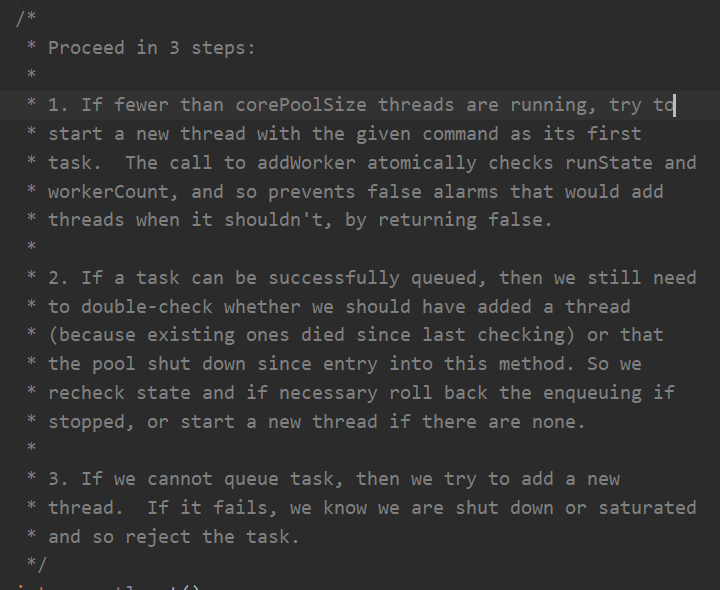
进行下面三个步骤:
1. 如果少于核心线程数的线程正在执行,尝试去开启一个新线程把当前任务当作他的第一个任务。addWorker原子的去检查运行的状态和worker的计数,防止不应该加入线程的时候reture false而失败报警
2.如果一个任务可以成功的入队,我们仍然需要double-check 是否我们应该加入一个线程(因为存在有个线程在上一次check之后就挂了),或者进入这个方法还没执行这时候线程池shut down了。
因此我们再次检查这个状态,如果必要的话就roll back刚才的操作,或者开始一个新线程如果没有线程了
3. 如果我们不能入队任务,就尝试加入一个新线程去处理。如果他失败了,我们知道线程池关闭了或者饱和了,so执行拒绝策略
(很快啊,啪的一下把doc翻译过来了,虽然翻译的有点恶心 不用看)
先判断任务是否为null
int c = clt.get(); 可以理解为 那个整数,能同时表示线程池状态和当前线程数
if( 如果当前线程个数 < 核心线程数){
if(创建新的Worker成功){
return;
}
更新一次 那个整数 (应为中间可能有人创建线程导致达到了coreSize 或者线程池关了 从而导致那个整数变了)
}
if(如果线程池还是Running状态 && 任务加入到阻塞队列成功){
int recheck = 再获取一次 那个整数 (防止就在这个节骨眼,有的线程挂了导致当前线程数小于coreSize了,又或者线程池这时候突然关闭了)
if(如果线程池关闭了 && 移除刚才入队的任务){
执行拒绝策略;
}else if(当前线程数 == 0){ //这里我不太懂为啥判断当前线程数==0 才加入新的线程,还不当作核心线程 //再次理解我觉得这里应该仅仅是处理很特殊的情况 线程在此时都关闭了 但是为什么会这样呢?
加入新的线程,作为核心线程数以外的线程
}
}else if(如果加入阻塞队列失败){
说明此时阻塞队列也满了,线程池也满了,该走拒绝策略了
}
3. addWorker(Runnable, core) 加入一个新线程,包装成Worker
![]()
方法比较长 截成了三段

(retry 这个不是关键字,是一种标记,紧跟着循环体,目的是 之后的多层循环里continue,break等语句后跟着 retry 能判断出要跳出的是哪层循环)
第一段代码做校验,是否满足条件创建新线程
for(;; ){ 死循环来一直获取任务做任务
int c = clt.get(); 获取 那个整数
int rs = 获取当前线程池状态
if(进入这里判断 如果 线程池立即关闭状态 && Worker中保存的任务不是null && 阻塞队列为空){
直接return false; 创建新worker失败
}
for(;; ){
int wc = 当前线程数;
if(wc >= 线程数最大值2^29 || wc >= 核心线程数(想创建核心线程时) 或者 wc >= 最大线程数(创建的不是核心线程时)){
return false; 都会创建失败
}
if (CAS设置一下当前线程数自增1){
设置成功 跳出所有循环;
}
设置线程数失败了,
if(如果当前线程池的状态不是刚才外层循环获取的状态了){
continue外层循环
}
如果当前线程池的状态没变,继续内层循环就行
}
}
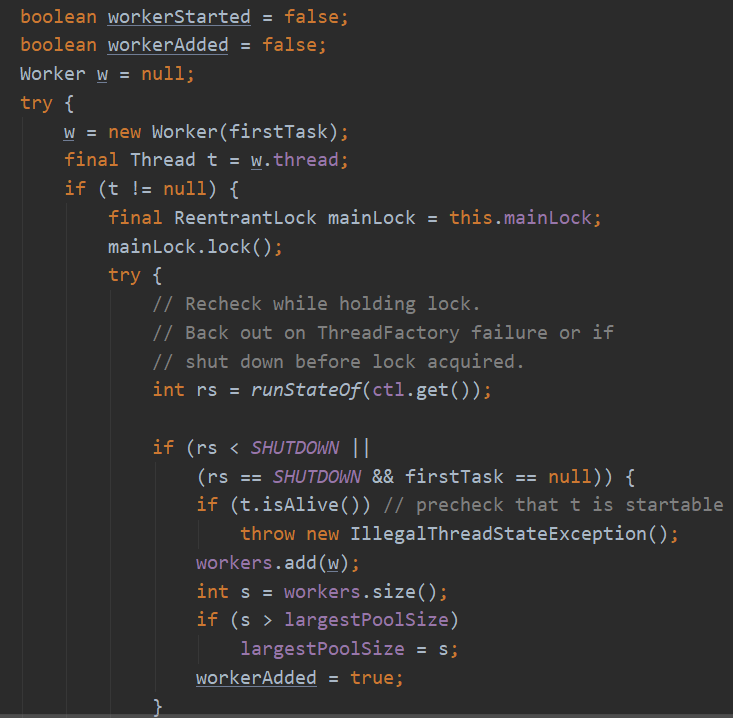
boolean workerStarted 新线程是否启动
boolean workerAdded 新线程是否加入到Workers这个HashSet集合中
Worker w = null;
try{
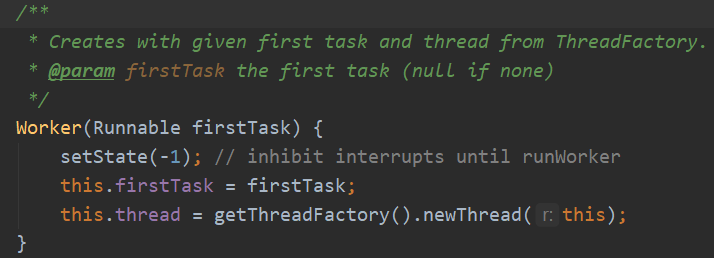
创建Worker,把任务传进去 存成他的firstTask,内部通过ThreadFactory给Worker造了一个线程;
Thread t = Worker内部的线程;
if (t != null){
加了一下ThreadPoolExecutor内部的独占锁; 就为了加入Workers,并且更新一下线程池的最大线程数largestPoolSize
try{
int rs = 获取一下线程池当前状态;
判断一下当前条件是否还适合继续加入Workers
if(当前线程池还是运行状态 || 关闭状态但是阻塞队列里的任务还需要执行){
加入到workers;
更新一下最大线程数记录largestPoolSize;
}
workerAdded = true 加入成功
}
}
}

释放掉独占锁;
如果加入成功了 就直接启动Worker内部的线程。
finally{
如果启动失败了
addWorkerFailed(worker) 将worker加入到失败队列
}
return 是否启动成功;
我对这里不理解,t.start()启动worker内部的线程,但是找来找去worker虽然继承了Runnable,却没有重写run()方法,难道是@Overwite战略省略?
如果t.start()启动这个run()的话那一切好说,该方法直接调用外部的runWorker(),把自己传进去,让外部来执行自己的任务
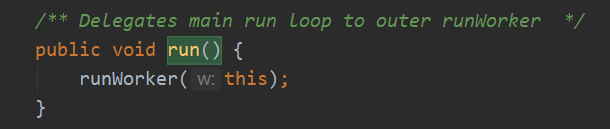
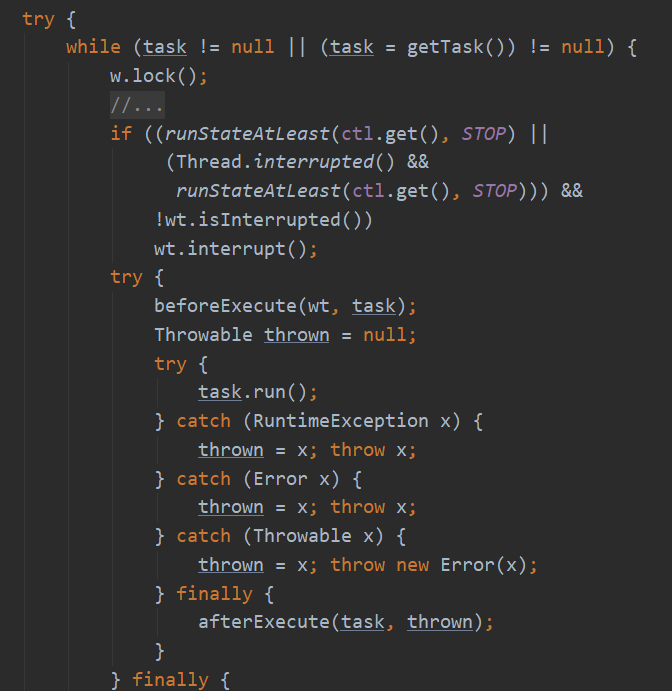
4. runWorker() 搞来搞去 最后到这个方法才是实实在在的接任务,执行任务了. 如果worker内部有任务firstTask 执行这个,执行完再不断循环从任务队列拉任务做
由Worker的run()方法调用,执行人是Worker的内部线程,但是该方法确实在Worker外部 为什么要设计在外部呢呢

Thread wt 获取一下当前线程,也就是worker内部的线程
Runnable task = 暂存一下firstTask
将firstTask置空
w.unlock() 释放一下worker内置锁,允许被中断
try{
while(当刚存的task != null || 从队列里获取task != null)
w.lock(); worker的内置锁,防止执行任务途中被人中断;
if( 先判断一下,如果此时此刻线程池已经是关闭了,或者中断位已经是中断了,就自我中断线程)
try{
beforeExecute(wt, task); 钩子方法,执行前需要做点啥,开发者可以自己实现
try{
task.run(); 搞来搞去终于在这要执行任务了
}catch(捕捉一堆异常 ){
统统抛
}finally{
afterExecute(wt,task); 钩子方法,执行完一个任务干点啥
}
}finally{
task = null;
w.completedTasks++; //累计完成的任务数
w.unlock();
}
// 如果到这里,需要执行线程关闭:
// 1. 说明 getTask 返回 null,也就是说,队列中已经没有任务需要执行了,执行关闭
// 2. 任务执行过程中发生了异常
// 第一种情况,已经在代码处理了将 workCount 减 1,这个在 getTask 方法分析中会说
// 第二种情况,workCount 没有进行处理,所以需要在 processWorkerExit 中处理} finally {
processWorkerExit(w, completedAbruptly);
}
}
5. getTask() 顾名思义,从任务队列获取任务


boolean timeOut = false; 最后一次出队超时了吗?
for(;; ){
老规矩 获取一下线程数和线程池状态;
if(如果线程池是立即关闭状态,或者队列已经空了){
devrementWorkerCount(); CAS Worker数-1
return null;
}
int wc = 当前线程数;
boolean timed = 工人们是否应该扑杀?
if(如果当前线程数大于最大线程数了 并且超时或者该杀了,并且线程数大于1 或者队列为空了){
如果CAS -1Worker数成功 return null;
否则的话 continue;
}
}

try{
尝试从任务队列中获取任务
}
四种拒绝策略
拒绝策略接口
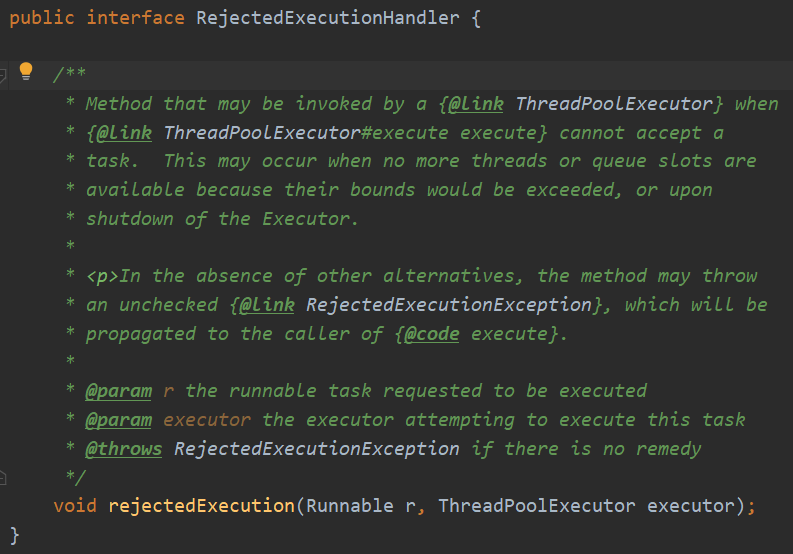
1. AbortPolicy 直接抛异常

2. DiscardPolicy 啥也不做

3. DiscardOldestPolicy 如果线程池没关闭,把任务队列的头任务出队 丢弃,执行现在得任务r

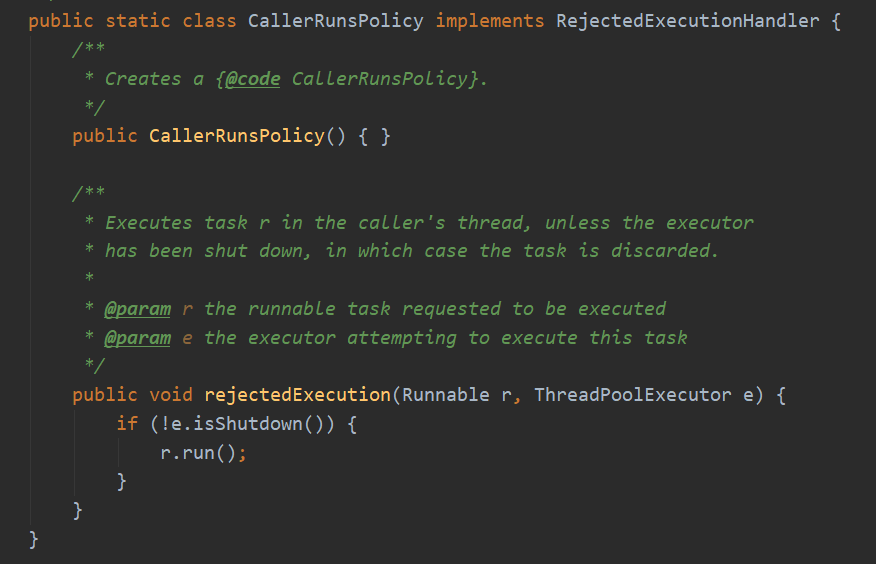
4. CallerRunsPolicy 如果线程池没关闭,把任务交给调用方法的当前线程来执行
Executors提供的三种线程池
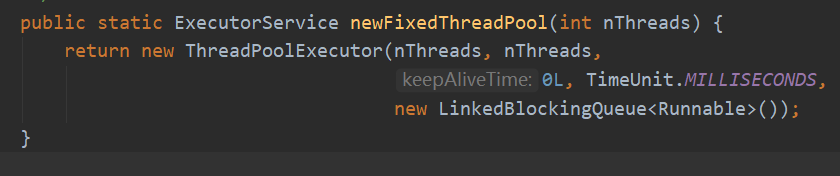
1. newFixedThreadPool 创建固定大小线程池 coreSize = maxSize = 固定大小, 阻塞队列无限
2. newSingleThreadExecutor 只能存在一个线程处理任务,阻塞队列无限

3. newCachedThreadPool() 核心线程数0 也就是说只要来了任务就直接进阻塞队列SynchronousQueue
SynchronousQueue是一种同步队列,讲道理就是入队一个元素,必须同步的有一个出队的操作才能让入队操作返回
SynchronousQueue本身不存储任何元素,也不支持遍历弹出等功能。
作用于线程池时,进入一个任务到SynchronousQueue就会阻塞等待一个Worker来拉任务,也就是说每当产生了一个任务立即就会有线程来执行。Worker也可以复用
