哈喽,大家好!工欲善其事,必先利其器,众所周知,mysql作为一个关系型数据库它为广大java开发者提供了极大地便利,就让我们一起来回味下吧!
一、数据库(database)
1.概念:长期存放在计算机(硬盘)内,有组织、可共享的大量数据的集合,是一个数据“仓库“”。
2.作用:保存、管理数
3.数据库类型:
关系型数据库(SQL):
MySQL、Oracle、SQL Server、SQLite、DB2等
非关系型数据库(NOSQL):
Redis、MongoDB
4.数据库管理系统(Database Management System):数据管理软件,科学
组织 和存储数据、高效地获取和维护数据
二、SQLyog管理工具
1.概念:可手动操作、管理MySQL数据库的软件工具
2.特点:易用、简洁、图形化.
3.其他类型的数据库可视化工具参考:
https://blog.csdn.net/tian330726/article/details/83716337
三、Mysql数据库和表操作
1.概念:是现流行的开源、免费的关系型数据库
2.特点:
- 免费、开源数据库
- 小巧、功能齐全
- 使用便捷
- 可运行于Windows或Linux操作系统
- 可适用于中小型甚至大型网站应用
3.mysql的安装以及启动
详情参考:https://www.cnblogs.com/wangyusu/p/11657539.html
4.创建以及删除数据库
1)创建数据库
Create database <数据库名>character set utf8;
2)删除数据库
drop database <数据库名>;
3)使用数据库
Use database <数据库名>;
注:在创建数据库时要指定编码格式。
5.mysql数据类型
数值类型:MySQL支持所有标准SQL数值数据类型
详情参考:https://zixuephp.net/manual-mysql-1320.html
6. 数据表操作
1)创建表:CREATE TABLE table_name (`字段名 列类型 [ 属性 ] [ 索引 ] [注释] ,);
字段为不为空可以设置字段的属性为 NOT NULL,
设置主键 primary key
设置自增 auto_increment 一般用于主键
设置存储引擎 engine=innob
设置编码格式 set charset=utf-8
Eg:
CREATE TABLE IF NOT EXISTS `score`(
`scid` INT UNSIGNED AUTO_INCREMENT,
`gradeid` int (10) NOT NULL,
`scorename` VARCHAR(40) NOT NULL,
`stuid` int(4),
PRIMARY KEY ( `scid` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
2)删除数据表:DROP TABLE table_name ;
3)修改数据表
修改表名: alter table 旧表名 rename as 新表名
修改列: alter table table_name change 旧列名 新列名 新数据类型(注意:必须加数据类型,否则会报错)
修改属性: alter table table_name modify 列名[数据类型]
添加列: alter table table_name add 列名[数据类型]
删除列: alter table table_name drop 列名[数据类型]
四、mysql外键和数据管理
1.外键
1) 定义:索引的一种,和主键用法类似。
2) 使用条件:
a.两个表必须是InnoDB表,MyISAM表暂时不支持外键
.b.外键列必须建立了索引,MySQL 4.1.2以后的版本在建立外键时会自动创建索引,但如果在较早的版本则需要显式建立;
c.外键关系的两个表的列必须是数据类型相似,也就是可以相互转换类型的列
3)语法:
a. 插入外键
alter table 表名 add constraint FK_ID foreign key(你的外键字段名) REFERENCES 外表表名(对应的表的主键字段名);
几点注意因素:
1、外键字段不能为该表的主键
2、外键字段参考字段必须为参考表的主键
3、两个字段必须具有相同的数据类型和长度
4、两个字段必须具有相同的约束
6、两个字段所在表的引擎都为InnoDB
7、两个字段的字符集必须相同
8、两个字段的核对必须相同
b. 删除外键约束
alter table 表名 drop foreign key 外键别名(FK_ID);
2.数据管理
1)插入数据
插入单条数据:
Insert into table_name ( 字段1, 字段2,...fieldN ) values( value1, value2,...valueN );
插入多条数据:
Insert into table_name ( 字段1, 字段2,...fieldN values( value1, value2,...valueN ),(value1,value2...valueN);
注:插入多条其他参考:https://www.cnblogs.com/myseries/p/11191134.html
2)删除表内数据
删除表数据
delete from table_name where 删除条件;
Eg: delete from student where stuid=1;
清空表数据,但保留表结构:truncate table 表名;
Eg:truncate table student;
3)修改数据
update 表名 set A=新的值,B=新的值,C=新的值,D=新的值 where id=要修改的id的值;
4)查询数据(select语句)
单表查询:
a.简单查询
Select*from table_name(全表查询)
Select [字段1],[字段2]...from table_name (全表查询和某字段查询);
b.条件查询
Select[字段]from table_name where 筛选条件(a=b);
c.去重查询
SELECT DISTINCT <字段> FROM table_name;
d.模糊查询
select 字段列表 from 表名 where 字段 like 'A%'; 表示:查询以A开头的数据
select 字段列表 from 表名 where 字段 like '%A%'; 表示:查询含A的数据
select 字段列表 from 表名 where 字段 like '%A'; 表示:查询以A结尾的数据
select 字段列表 from 表名 where 字段 like '_A_'; 表示:查询三位且中间字母是A
select 字段列表 from 表名 where 字段 like 'A_'; 表示:查询两位且结尾字母是A
select 字段列表 from 表名 where 字段 like '_A'; 表示:查询两位且开头字母是A
e.聚合函数
详情参考: https://www.jianshu.com/p/74f9efb4cbd4
https://www.jb51.net/article/40179.htm
多表查询:
a.内连接:返回连接表中符合连接条件和查询条件的数据行
1.显式内连接:就是用inner join 来连接表关系
select * from a_table a inner join b_table bon a.a_id = b.b_id;
2.隐式内连接:通过外键来连接表关系
select a.name,b.name. from a_table a , b_table b where a.a_id = b.b_id;
注:组合两个表中的记录,返回关联字段相符的记录,也就是返回两个表的交集(阴影)部分。
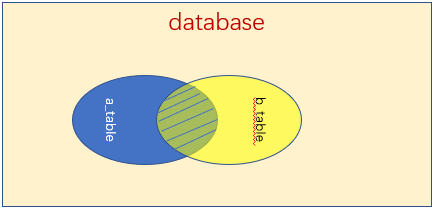
b.外连接:外连不但返回符合连接和查询条件的数据行,还返回不符合条件的一些行。
1.左(外)连接:left join on / left outer join on
select * from a_table a left join b_table bon a.a_id = b.b_id;
注:left join 是left outer join的简写,它的全称是左外连接,是外连接中的一种。左(外)连接,左表(a_table)的记录将会全部表示出来,而右表(b_table)只会显示符合搜索条件的记录。右表记录不足的地方均为NULL。
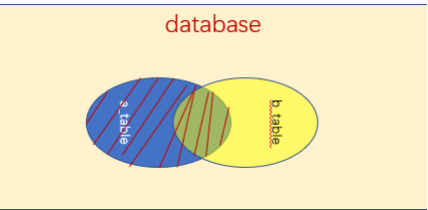
2.右(外)连接:right join on / right outer join on
select * from a_table a right outer join b_table b on a.a_id = b.b_id;
注:ight join是right outer join的简写,它的全称是右外连接,是外连接中的一种。与左(外)连接相反,右(外)连接,左表(a_table)只会显示符合搜索条件的记录,而右 表(b_table)的记录将会全部表示出来。左表记录不足的地方均为NULL。
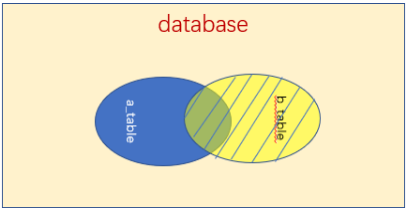
3.全连接
MySQL目前不支持此种方式,可以用其他方式替代解决。
-------------------
参考资料:https://blog.csdn.net/plg17/article/details/78758593
五、MySQL事务、索引、数据恢复和备份
1.MySQL的事务
1)概念:事务就是将一组SQL语句放在同一批次内去执行,如果一个SQL语句出错,则该批次内的所有SQL都将被取消执行。 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。事务用来管理 insert,update,delete 语句。
2)属性(ACID):
原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事 务开始前的状态,就像这个事务从来没有执行过一样。
一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
3)实现步骤:
(1)关闭自动提交 set commit = 0;
(2)开始一个事务,标记事务的起始点 start transction ;
............事务...........
Rollback; 将事务回滚,数据回到本次事务的初始状态
Commit ; 提交一个事务给数据库
(3)开启自动提交 set commit = 1;
2.数据库索引
A. 分类:
1)主键索引(primary key) 数据唯一 不为空
2)唯一索引(unique) 数据不唯一
作用:避免同一个表中某数据列中的值重复
3)常规索引(index)
作用:快速定位特定数据
index和key关键字都可设置常规索引,加在查找条件的字段
缺点:不宜添加太多常规索引,影响数据的插入、删除和修改操作
4)全文索引(fulltext)
作用:快速定位特定数据
注意:只能用于MyISAM类型的数据表,只能用于 CHAR 、 VARCHAR、TEXT数据列类型,
适合大型数据集。
B.索引的语法
1)创建索引
方式一: 创建表时添加
create table table_name(
//省略一些代码.........
索引类型........)
方式二:ALERT TABLE 表名 ADD 索引类型(数据列名)
2)删除索引
Drop index索引名 on 表名
ALTER TABLE 表名 DROP INDEX 索引名
ALTER TABLE 表名 DROP PRIMARY KEY
3)查看索引
SHOW INDEX(或KEYS) FROM 表名
C.索引准则
索引不是越多越好:每添加一条索引都会占用磁盘空间
不要对经常变动的数据加索引:经常变化的字段,添加索引反而降低性能
小数据量的表建议不要加索引
索引一般应加在查找条件的字段
D.解读SQL语句的执行性能
EXPLAIN 表名 (DESC 表名)
EXPLAIN SELECT语句
详情见:https://blog.csdn.net/xifeijian/article/details/19773795
3.MySQL数据库备份和恢复的几种方法
A.数据备份
(1)数据库备份必要性:保证重要数据不丢失,数据转移
(2)备份方法:mysqldump备份工具
数据库管理工具,如SQLyog
直接拷贝数据库文件和相关配置文件
B.数据恢复的方法
(1) SOURCE 方法: SOURCE /path/db_name.sql;
注:path 是绝对路径 ,SOURCE 在MySQL命令行里执行;
(2)用 mysql 客户: mysql –u root –p dbname < /path/db_name.sql;
4. 导入和导出数据
这里只介绍用SQL命令导出数据和导入数据
导出数据: SELECT * INTO OUTFILE 'file_name' FROM tbl_name
导入数据: LOAD DATA INFILE 'file_name ' INTO TABLE tbl_name[FIELDS]
注:输出的文件不能先存在,否则报错
六、设计数据库
1.设计数据库的步骤
1)需求分析:了解用户的数据需求、处理需求、安全性及完整性要求;
2)概念设计:通过数据抽象,设计系统概念模型,一般为E-R模型;
3)逻辑结构设计:设计系统的模式和外模式,对于关系模型主要是基本表和视图;
4)物理结构设计:设计数据的存储结构和存取方法,如索引的设计;
5)系统实施:组织数据入库、编制应用程序、试运行;
6)运行维护:系统投入运行,长期的维护工作。
2.绘制数据库的E-R图
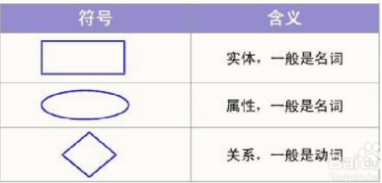
3.何绘制数据库模型图
4.实现数据库设计规范化
第一范式 (1st NF):如果每列都是不可再分的最小数据单元(也称为最小的原子单元),则满足第一范式(1NF)
第二范式 (2nd NF):要求每个表只描述一件事情
第三范式 (3nd NF):如果一个关系满足2NF,并且除了主键以外的其他列都不传递依赖于主键列,则满足第三范式(3NF) 。