一、excel数据的读取与保存
读取
简单文件


import pandas as pd #pandas是数据处理模块,import是导入,as pd是命名别名 amazon_data = pd.read_excel(r'D:datapythonamazon-fine-foodsamazon_data.xlsx',sheetname='data')
多数据表文件
#方式1: import pandas as pd io = pd.io.excel.ExcelFile(r'D:datapythonamazon-fine-foodsamazon_data.xlsx') amazon_data = pd.read_excel(io,sheetname='data') price = pd.read_excel(io,sheetname='price') io.close() #方式2: import pandas as pd amazon_data = pd.read_excel(r'D:datapythonamazon-fine-foodsamazon_data.xlsx',sheetname='data') price = pd.read_excel(r'D:datapythonamazon-fine-foodsamazon_data.xlsx',sheetname='price') #在数据量大、sheet多的情况下,方式1的速度大于方式2的速度
保存
单表格保存
import pandas as pd amazon_data = pd.read_excel(r'D:datapythonamazon-fine-foodsamazon_data.xlsx',sheetname='data') amazon_data.to_excel(r'D:data ew.xlsx') #存入D盘的data文件夹
多数据表保存为不同excel文件
import pandas as pd writer=pd.ExcelWriter(r'D:datapython存储数据.xlsx') amazon_data .to_excel(writer,sheet_name='data') price.to_excel(writer,sheet_name='price') writer.save()
二、数据的预览
查看列名:amazon_data.columns 查看行数列数:amazon_data.shape 查看前5行/后5行数据: amazon_data.head(5)、amazon_data.tail(5) 查看每列的数据格式:amazon_data.dtypes 数据的索引: 列的索引:amazon_data['Id']或者amazon_data.loc[:, 'Id'] 数据ID列 行的索引:amazon_data.loc[0, :] 读取第1行(Python的索引从0开始) 某行某列:amazon_data.loc[2, 'Id'] ID列的第3个 数据描述:amazon_data.describe() 索引:amazon_data['Id'].describe() 数据信息:http://amazon_data.info() 如果查看某列数据,用amazon_data['Id']是可以的。但是如果要修改这列,最好使用amazon_data.loc[:,'Id']这种写法。 当然还有 amazon_data.iloc[ ] ,这是根据物理位置索引。比如第3行第5列,可以写 amazon_data.iloc[ 2, 4 ],注意索引都是从0开始的。 多行多列,可用 amazon_data.iloc[ 2:8, 1:3]
三、数据的清洗
格式修改、去除空格、替换、分列、合并。
字符串转日期
'%Y/%m/%d %H:%M'格式与amazon_data['Time']格式要一致。
amazon_data['Time'][0] 值为2018/3/23 9:43 类型为str amazon_da阿ta.loc[:,'日期date'] = amazon_data['Time'].apply(lambda x: datetime.datetime.strptime(x,'%Y/%m/%d %H:%M'))
去除空格
比如“电脑”、“电 脑”,要把“电 脑”的空格去掉。
amazon_data.loc[:,'ProfileName无空格'] = amazon_data['ProfileName'].str.replace(' ','')
amazon_data['ProfileName'].str.strip(' ')
但这个只能去除字符串前后两端的空格,无法去除中间的空格。如果要去除所有空格,就需要用replace替换。

分列
‘四川省 成都市’,在统计中只需要‘四川省’,根据空格进行分列,然后取省份那列。
amazon_data.loc[:,'ProfileName分列'] = amazon_data['ProfileName'].str.split(' ').str[0]
合并
本例子中,data表的productid对应 price中的productid,现在需要把data中的产品价格加进来。用到merge方法。 #合并 amazon_data = pd.merge(left=amazon_data,right=price,on='ProductId') pd.merge(left=df1, right=df2, left_on=’key1’, right_on=’key2’, how=’left’) left左表,right右表,left_on左表的连接键,right_on右表连接键,how是连接方式:左连left,右连right,外连outer,内连inner(默认)。
合并表格,除了用merge,还有个方法是concat。concat可以纵向合并,也可以横向合并。
pd.concat([df1, df2] ) 纵向合并,即把df2的数据接到df1后面。
pd.concat([df1, df2], axis=1, join='inner') 横向合并,按索引取交集。
四 数据的统计分析
对数据进行统计分析。如:计数、均值、求和、分组计数求和等。
计数&去重计数
num_goods = len(amazon_data['ProductId'].drop_duplicates()) #商品去重计数 count_goods = amazon_data['ProductId'].count() #商品计数 print('商品去重计数: %d, 未去重计数: %d ' %(num_goods,count_goods)) #打印数据, 是换行符 num_users = len(amazon_data['UserId'].drop_duplicates()) #用户去重计数 count_users = amazon_data['UserId'].count() #用户计数 print('用户去重计数: %d, 未去重计数: %d' %(num_users,count_users))
去重计数的原理,是先将某列删除重复项,即 drop_duplicates(),再用len()函数去求去重列的长度。
求和&均值
sales = amazon_data['price(yuan)'].sum() #求和 avg_price = amazon_data['price(yuan)'].mean() #均值 print('总共售出: %d 元,订单均价: %.2f' %(sales,avg_price))
分组计数、求和、均值
user_order_num = amazon_data.groupby('UserId')['Id'].count() #每个用户购买的订单数 user_sales = amazon_data.groupby('UserId')['price(yuan)'].sum() #每个用户的成交金额 user_avg_price = amazon_data.groupby('UserId')['price(yuan)'].mean() #每个用户的订单均价 print(user_order_num.sort_values(ascending=False)) #购买次数降序排列
五、按条件筛选
根据条件,去筛选数据。
找出购买金额最多的用户
most_sale_user_0 = amazon_data[amazon_data['UserId']=='A3OXHLG6DIBRW8'] #购买金额最多的用户 订单 most_sale_user_1 = amazon_data[amazon_data['UserId']==user_sales.index[0]] #购买金额最多的用户 订单 等同于上一句 这两句话是同等的,只不过后一句更有灵活性,如果换了一批订单数据,后一句仍旧可以使用。
购买金额最多的用户ID是A3OXHLG6DIBRW8,对应user_sales.index[0]
找出大于均价的订单
greater_mean_0 = amazon_data[amazon_data['price(yuan)']>=52.19] greater_mean_1 = amazon_data[amazon_data['price(yuan)']>=amazon_data['price(yuan)'].mean()]
按条件赋值
比如,新增一列叫“类别”,用来判断订单价格是否大于均价。这就涉及到:先筛选出大于均值、小于均值的两组记录,再分别赋值:大于均值、小于均值。 amazon_data.loc[amazon_data['price(yuan)']>=amazon_data['price(yuan)'].mean(),'类别'] = '大于均值' 于是得到了新的一列【类别】,里面大于均值的订单,都已经赋值了。那么小于均值的,就有两种方法: amazon_data.loc[amazon_data['price(yuan)']<amazon_data['price(yuan)'].mean(),'类别'] = '小于均值' #按小于均值填写 amazon_data['类别'].fillna('小于均值',inplace=True) #填充空值,要inplace=True,否则不会改变
找出某几个用户的订单
danger_user = ['A3SGXH7AUHU8GW','A1D87F6ZCVE5NK','ABXLMWJIXXAIN','A395BORC6FGVXV'] #将用户存入list里 danger_order = amazon_data[amazon_data['UserId'].isin(danger_user)] #找出他们的订单 isin()
找出 9月-10月 的订单
date_range_order = amazon_data[(amazon_data['日期date']>='2018-09-01')&(amazon_data['日期date']<'2018-11-01')] # & 代表与, | 代表或
找出包含“good”评价的订单
good_order = amazon_data[amazon_data['Text'].str.contains('good')] 那么如何找出包含 good或great的呢?很简单,求或;如何找出不包含good的呢?取反。 good_great_order = amazon_data[amazon_data['Text'].str.contains('good|great')] #good 或 great no_good_order = amazon_data[~amazon_data['Text'].str.contains('good')] #不包含good 没错,前面加一个小波浪就是取反
不同的列,也可以添加条件
比如,要找时间在9月之后的,评价包含good的,全部框在一起就行了 order = amazon_data[(amazon_data['Text'].str.contains('good|great'))&(amazon_data['日期date']>='2018-09-01')]
其他
查看一列的基本统计信息:
data.columnname.describe()
重命名列名
最终的数据可能是有计算机生成的,那么,列名有可能也是计算机按照一定计算规律生成的。这些列名对计算机没有什么,但是对于人来说可能就不够友好,这时候,我们就需要重命名成对人友好的列名。
data = data.rename(columns = {'title_year':'release_date', 'movie_facebook_likes':'facebook_likes'})
规范化数据类型
有的时候,尤其当我们读取 csv 中一串数字的时候,有的时候数值类型的数字被读成字符串的数字,或将字符串的数字读成数据值类型的数字。
data = pd.read_csv('../data/moive_metadata.csv', dtype={'duration': int}) #告诉 Pandas ‘duration’列的类型是数值类型。
不想要某一列中没有数的数据
data.dropna(subset=['title_year'])
上面的 subset参数允许我们选择想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
数据没有列头
数据没有列头,Pandas 在读取 csv 提供了自定义列头的参数。
# 增加列头 column_names= ['id', 'name', 'age', 'weight','m0006','m0612','m1218','f0006','f0612','f1218'] df = pd.read_csv('../data/patient_heart_rate.csv', names = column_names)
一个列有多个参数
数据中Name 列包含了两个参数 Firtname 和 Lastname。为了达到数据整洁目的,我们决定将 name 列拆分成 Firstname 和 Lastname,再将原来的 Name 列删除。
# 切分名字,删除源数据列 df[['first_name','last_name']] = df['name'].str.split(expand=True) df.drop('name', axis=1, inplace=True)
列数据的单位不统一
Weight 列的单位不统一,有的单位是 kgs,有的单位是 lbs
# 获取 weight 数据列中单位为 lbs 的数据 rows_with_lbs = df['weight'].str.contains('lbs').fillna(False) df[rows_with_lbs] # 将 lbs 的数据转换为 kgs 数据 for i,lbs_row in df[rows_with_lbs].iterrows(): weight = int(float(lbs_row['weight'][:-3])/2.2) df.at[i,'weight'] = '{}kgs'.format(weight)
空行
数据中一行空行,除了 index 之外,全部的值都是 NaN。
# 删除全空的行
df.dropna(how='all',inplace=True)
删除重复数据行
首先校验一下是否存在重复记录。如果存在重复记录,就使用 Pandas 提供的 drop_duplicates() 来删除重复数据。
df.drop_duplicates(['first_name','last_name'],inplace=True)
大型数据集只想读入部分作分析
import pandas as pd
df = pd.read_csv('../data/Artworks.csv').head(100)
df.head(10)
统计日期数据
可以查看年份数据是否统一
df['Date'].value_counts()
日期数据问题
日期是时间范围,如1976-77
数据都是两个年时间范围,我们选择其中的一个年份作为清洗之后的数据。为了简单起见,我们就使用开始的时间来替换这样问题的数据,因为这个时间是一个四位数的数字,如果要使用结束的年份,我们还要补齐前两位的数字。
首先,我们需要找到问题一的数据,这样我们才能将其更新。要保证其他的数据不被更新,因为其他的数据有可能是已经格式化好的,也有可能是我们下面要处理的。
我们要处理的时间范围的数据,其中包含有“-”,这样我们就可以通过这个特殊的字符串来过滤我们要处理的数据,然后,通过 split() 利用“-”将数据分割,将结果的第一部分作为处理的最终结果。
row_with_dashes = df['Date'].str.contains('-').fillna(False) for i, dash in df[row_with_dashes].iterrows(): df.at[i,'Date'] = dash['Date'][0:4] df['Date'].value_counts()
dataframe删除含有特定字符的行
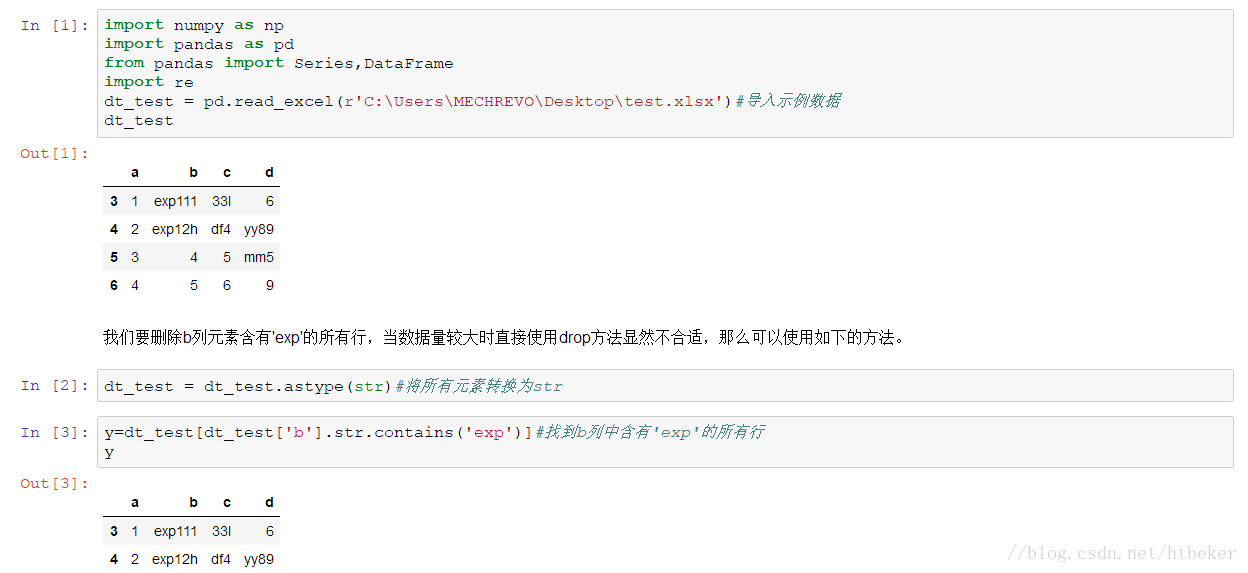

date_list = ["2020/4/{}".format(i + 1) for i in range(30)]