大数据篇:YARN

YARN是什么?
YARN是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
如果没有YARN!
- 无法管理集群资源分配问题。
- 无法合理的给程序分配合理的资源。
- 不方便监控程序的运行状态及日志。
1 YARN概念
1.1 基本架构

- ResourceManager
- 整个集群只有一个,负责集群资源的统一管理和调度
- 处理客户端请求,启动/监控ApplicationMaster
- 监控NodeManager,汇总上报资源
- 资源分配与调度
- NodeManager
- 整个集群有多个(每个从属节点一个)
- 单个节点上的资源管理和任务管理
- 监控资源使用情况(cpu,memory,disk,network)并向ResourceManager汇报
- 基本思想衍进
- 在MapReduce1.0中 JobTracker = 资源管理器 + 任务调度器
- 拥有yarn后,将资源管理器,任务调度器做了切分
- 资源管理
- 让ResourceManager负责
- 任务调度
- 让ApplicationMaster负责
- 每个作业启动一个
- 根据作业切分任务的tasks
- 向ResourceManager申请资源
- 与NodeManager协作,将分配申请到的资源给内部任务tasks
- 监控tasks运行情况,重启失败的任务
- 让ApplicationMaster负责
- 资源管理
- JobHistoryServer
- 每个集群每种计算框架一个
- 负责搜集归档所有的日志
- Container
- 计算资源抽象为Container
- 任务运行资源(节点、内存、CPU)
- 任务启动命令
- 任务运行环境
1.2 基本架构 YARN运行过程剖析

1. 客户端发送请求,由Resource Manager分析需要多少内存资源。
2. Resource Manager告诉Node Manager用什么样的jar包什么样的启动命令。
3. Node Manager创建Container,在Container启动Application Master。
4. Application Master向Resource Manager发送ResourceRequest请求去Resource Manager申请资源
5. 启动对应的Node Manager进行通信
6. Node Manager找到对应的Container执行Task
1.3 YARN容错性
- 失败类型
- 程序失败 进程崩溃 硬件问题
- 如果作业失败了
- 作业异常会汇报给Application Master
- 通过心跳信号检查挂住的任务
- 一个作业的任务失败比例超过配置,就会认为该任务失败
- 如果Application Master失败了
- Resource Manager接收不到心跳信号时会重启Application Master
- 如果Node Manager失败了
- Resource Manager接收不到心跳信号时会将其移出
- Resource Manager接收Application Master,让Application Master决定任务如何处理
- 如果某个Node Manager失败任务次数过多,Resource Manager调度任务时不再其上面运行任务
- 如果Resource Manager运行失败
- 通过checkpoint机制,定时将其状态保存到磁盘,失败的时候,重新运行
- 通过Zooleeper同步状态和实现透明的HA
1.4 YARN调度框架
- 双层调度框架
- RM将资源分配给AM
- AM将资源进一步分配给各个Task
- 基于资源预留的调度策略
- 资源不够时,会为Task预留,直到资源充足
- 与“all or nothing”策略不同(Apache Mesos)

1.5 YARN资源调度算法
-
集群资源调度器需要解决:
- 多租户(Multi-tenancy):
- 多用户同时提交多种应用程序
- 资源调度器需要解决如何合理分配资源
- 可扩展性:增加集群机器数量可以提高整体集群性能。
- 多租户(Multi-tenancy):
-
Yarn使用列队解决多租户中共享资源的问题
-
root
|---prd
|---dev
|---eng
|---science
-
-
支持三种资源调度器(yarn.resourcemanager.scheduler.class)

-
FIFO
- 所有向集群提交的作业使用一个列队
- 根据提交作业的顺序来运行(先来先服务)
- 优点:简单,可以按照作业优先级调度
- 缺点:资源利用率不高,不允许抢占
-
Capacity Scheduler
-
设计思想:资源按照比例分配给各个列队
-
计算能力保证:以列队为单位划分资源,每个列队最低资源保证
-
灵活:当某个列队空闲时,其资源可以分配给其他的列队使用
-
支持优先级:单个列队内部使用的就是FIFO,支持作业优先级调度
-
多租户:
- 考虑多种因素防止单个作业,用户列队独占资源
- 每个列队可以配置一定比例的最低资源配置和使用上限
- 每个列队有严格的访问控制,只能向自己列队提交任务
-
基于资源调度:支持内存资源调度和CPU资源的调度
-
从2.8.0版本开始支持抢占
-
root
|---prd 70%
|---dev 30%
|---eng 50%
|---science 50%
-
-
Fair Scheduler(推荐)
- 设计思想:资源公平分配
- 具有与Capacity Scheduler相似的特点
- 树状队列
- 每个列队有独立的最小资源保证
- 空闲时可以分配资源给其他列队使用
- 支持内存资源调度和CPU资源调度
- 支持抢占
- 不同点
- 核心调度策略不同
- Capacity Scheduler优先选择资源利用率低的列队
- 公平调度器考虑的是公平,公平体现在作业对资源的缺额
- 单独设置列队间资源分配方式
- FAIR(只考虑Mamory)
- DRF(主资源公平调度,共同考虑CPU和Mamory)
- 单独设置列队内部资源分配方式
- FAIR DRF FIFO
- 核心调度策略不同
-
-
多类型资源调度
- 采用DRF算法(论文:“Dominant Resource Fairness: Fair Allocation of
Multiple Resource Types”) - 目前支持CPU和内存两种资源
- 采用DRF算法(论文:“Dominant Resource Fairness: Fair Allocation of
-
多租户资源调度器
- 支持资源按比例分配
- 支持层级队列划分方式
- 支持资源抢占
配置案例
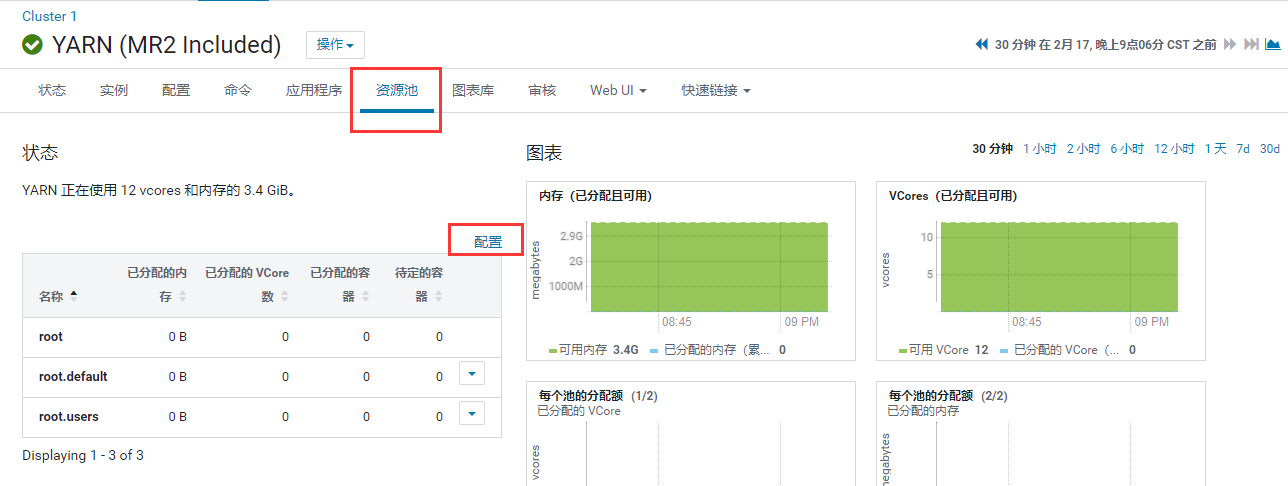


-
调用Wordcount案例,看看效果吧
-
hadoop jar /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop-mapreduce/hadoop-mapreduce-examples-3.0.0-cdh6.2.0.jar wordcount -Dmapreduce.job.queuename="root.default" /word.txt /output #任务2将会失败root.users is not a leaf queue,有了自列队就不能提交 hadoop jar /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop-mapreduce/hadoop-mapreduce-examples-3.0.0-cdh6.2.0.jar wordcount -Dmapreduce.job.queuename="root.users" /word.txt /output1 hadoop jar /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop-mapreduce/hadoop-mapreduce-examples-3.0.0-cdh6.2.0.jar wordcount -Dmapreduce.job.queuename="root.users.dev" /word.txt /output2 hadoop jar /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop-mapreduce/hadoop-mapreduce-examples-3.0.0-cdh6.2.0.jar wordcount -Dmapreduce.job.queuename="root.users.test" /word.txt /output3
1.6 YARN资源隔离方案
- 支持内存和CPU两种资源隔离
- 内存是一种“决定生死”的资源
- CPU是一种“影响快慢”的资源
- 内存隔离
- 基于线程监控的方案
- 基于Cgroups的方案
- CPU隔离
- 默认不对CPU资源进行隔离
- 基于Cgroups的方案
1.7 YARN支持的调度语义
- 支持的语义
- 请求某个特定节点/机架上的特定资源量
- 将某些节点加入(或移除)黑名单,不再为自己分配这些节点上的资源
- 请求归还某些资源
- 不支持的语义
- 请求任意节点/机架上的特定资源量
- 请求一组或几组符合某种特质的资源
- 超细粒度资源
- 动态调整Container资源
1.8 YARN常用命令
- 列出所有的Application: yarn application -list
- 根据Application状态过滤: yarn application -list -appStates ACCEPTED
- Kill掉Application: yarn application -kill [ApplicationId]
- 查看Application日志: yarn logs -applicationId [ApplicationId]
- 查询Container日志:yarn logs -applicationId [ApplicationId] -containerId [containerId] -nodeAddress [nodeAddress]
- 配置是配置文件中:yarn.nodemanager.webapp.address参数指定
2 Hadoop YARN应用
2.1 应用程序种类繁多

2.2 YARN设计目标
- 通用的统一资源管理系统
- 同时运行长应用程序和短应用程序
- 长应用程序
- 通常情况下,永不停止运行的程序
- Service、HTTP Server等
- 短应用程序
- 短时间(秒级、分钟级、小时级)内会运行结束的程序
- MR job、Spark Job等
2.3 以YARN为核心的生态系统

2.4 运行在YARN上的计算框架
- 离线计算框架:MapReduce
- DAG计算框架:Tez
- 流式计算框架:Storm
- 内存计算框架:Spark
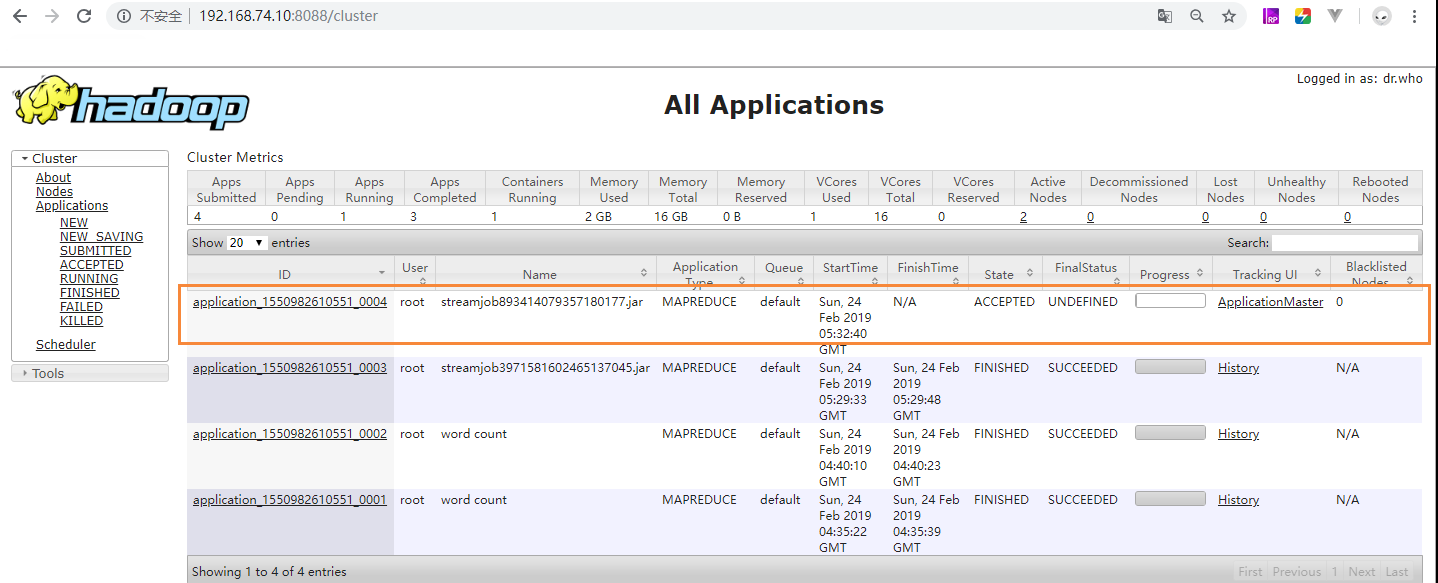
3 监控页面
4 YARN HA

从图中看出yarn的HA相对于HDFS的HA简单很多。原因是YARN在开发的过程中,HDFS才考虑到HA的应用(在出2.0版本),HDFS为了老代码的兼容性,和新代码的可拓展性加入了ZKFailoverController(ZKFC)来处理ZK相关的业务。而YARN就直接将ZK的相关的业务规划进了源架构中,所以架构图看起来比HDFS HA简单很多。
4.1 CDH中YARN配置HA

也很简单,一步完成。
5 参数调优
5.1 内存利用优化
- yarn.nodemanager.resource.memory-mb
单个节点可用内存,表示该节点上YARN可使用的物理内存总量。
- yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量
一般出现资源不够的情况就需要调整上述两个参数,比如前面来了1个G数据,分成10个块,每一个map占用1G内存,那么需要10G,4个reduce任务一个1G内存,这时候yarn.scheduler.maximum-allocation-mb参数就必须大于14G,而如果有2个这种任务,那么yarn.nodemanager.resource.memory-mb参数就必须大于28G。