什么是Solr
solr是Apache下的一个顶级开源项目,采用java开发,它基于Lucene的全文搜索服务器。solr提供了比Lucene更为丰富的查询语言,同时实现了可配置,可拓展,并对索引,搜索性能进行了优化。
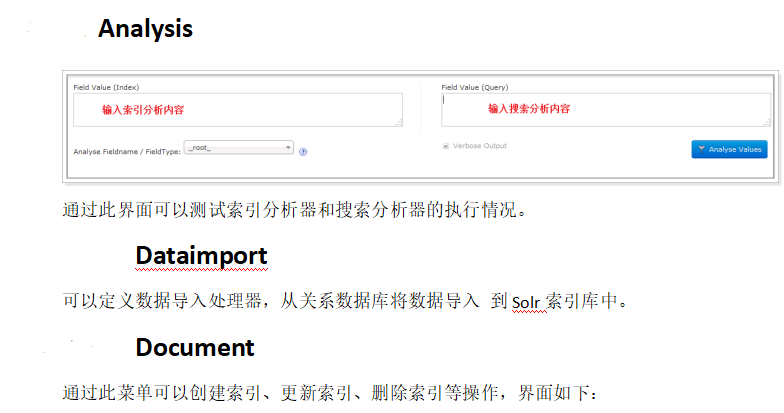
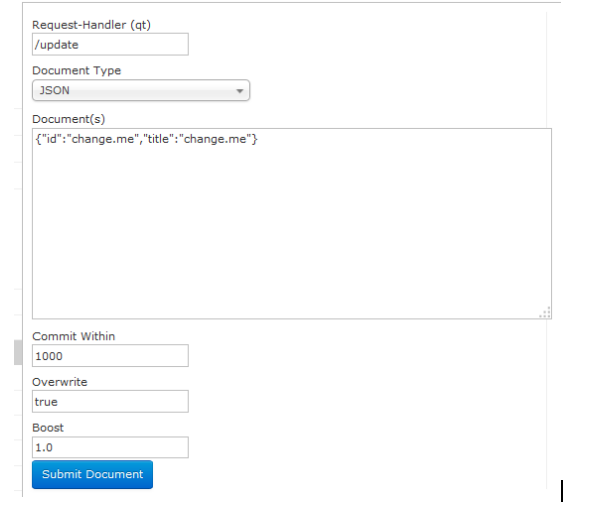
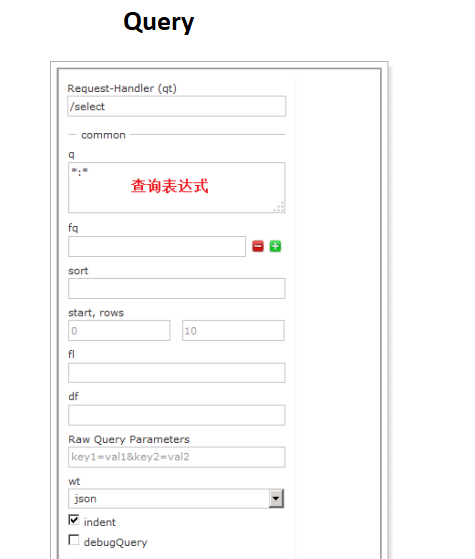
solr可以独立运行,运行在Jetty,Tomcat等这些Servlet容器中,Solr索引实现方法很简单,用post方法向服务器发送一个描述Field及其内容的XML文档,Solr根据xml文档添加,删除,跟新索引,solr搜索只需要发送HTTP GET请求,然后对solr返回XML,JSON等格式的查询结果进行解析,组织页面布局。sorl不提供构建UI的功能,solr提供了一个管理界面,通过管理界面可以查询solr的配置和运行情况。
solr和Lucene的区别:
Lucene是一个开源的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或以Lucene为基础构建全文检索引擎。
solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过solr可以非常快速的构建企业的搜索引擎,通过solr也可以高效的完成站内搜索功能。
Solr的下载
从Solr官方网站(http://lucene.apache.org/solr/ )下载Solr4.10.3,根据Solr的运行环境,Linux下需要下载lucene-4.10.3.tgz,windows下需要下载lucene-4.10.3.zip。
Solr使用指南可参考:https://wiki.apache.org/solr/FrontPage。
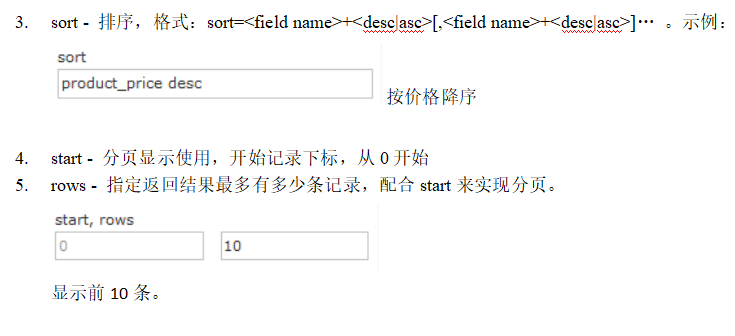
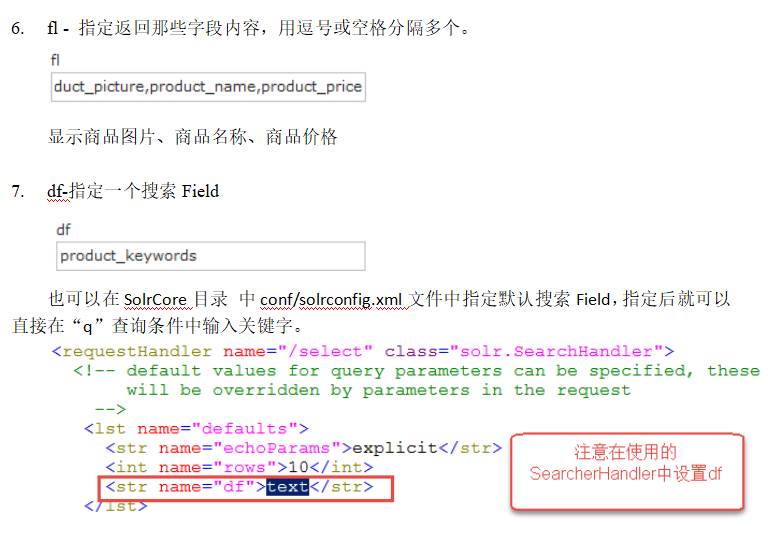
bin:solr的运行脚本
contrib:solr的一些贡献软件/插件,用于增强solr的功能。
dist:该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。
docs:solr的API文档
example:solr工程的例子目录:
l example/solr:
该目录是一个包含了默认配置信息的Solr的Core目录。
l example/multicore:
该目录包含了在Solr的multicore中设置的多个Core目录。
l example/webapps:
该目录中包括一个solr.war,该war可作为solr的运行实例工程。
licenses:solr相关的一些许可信息
Solr整合tomcat
使用tomcat作为servlet容器,Solr4.10.3要求jdk使用1.7以上,Solr默认提供Jetty(java写的Servlet容器)。
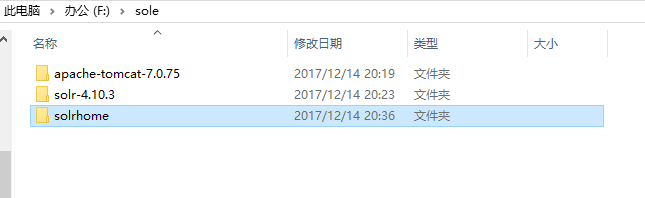
1---解压tomcat,solr,创建solrhome文件夹。
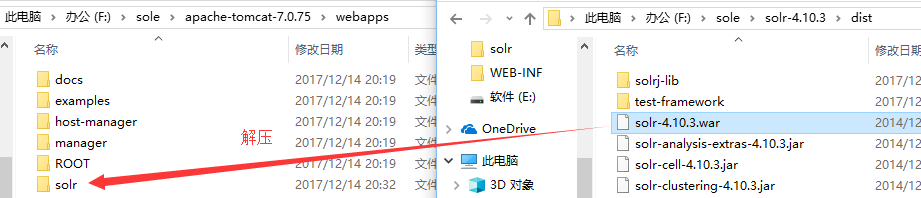
2--把solr的war包复制到tomcat 的webapp目录下。把solr-4.10.3distsolr-4.10.3.war 复制到F:apache-tomcat-7.0.53webapps下。改名为solr.war,解压
或solr-4.10.3examplewebapps位置也可 复制到F:apache-tomcat-7.0.53webapps下。解压。
注:解压之后删除solr.war压缩包
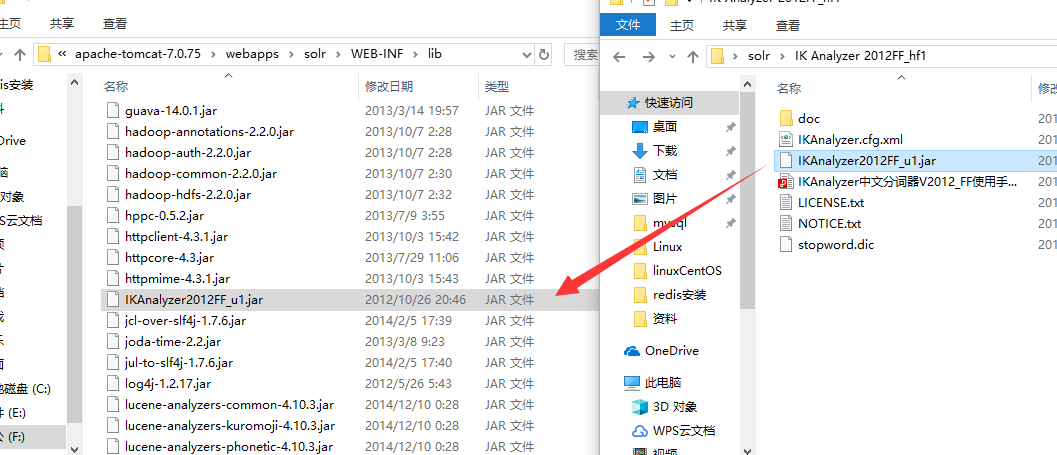
3--把solr-4.10.3examplelibext目录下的所有的jar包添加到solr工程中

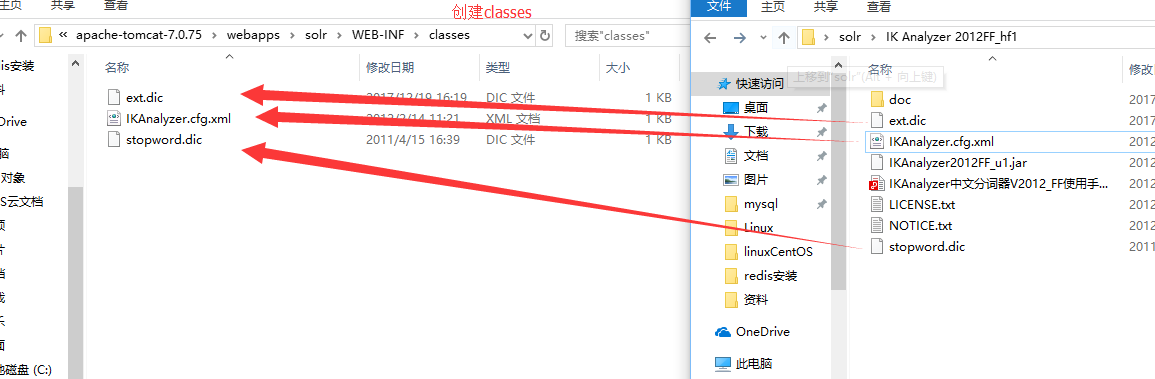
4--把第一步创建的solrhome(存放solr所有配置文件的一个文件夹)路径复制到solr工程的web.xml里。
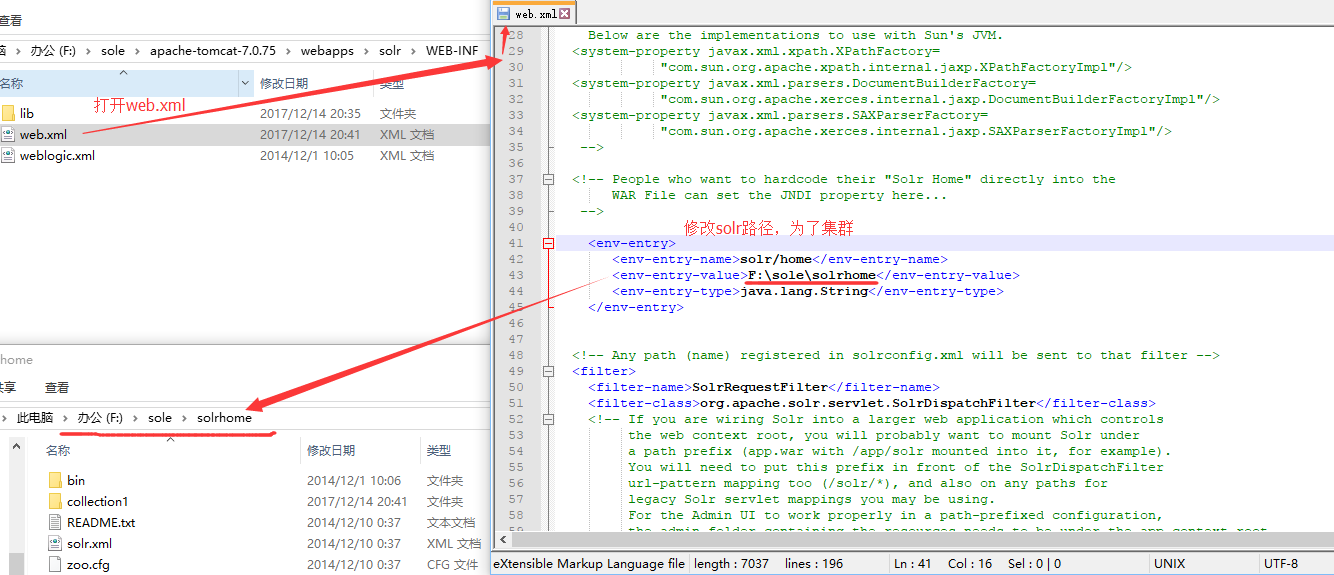
5--solr-4.10.3examplesolr目录就是一个标准的solrhome。(将其目录里所有文件拷贝到我们建立的solrhome里)

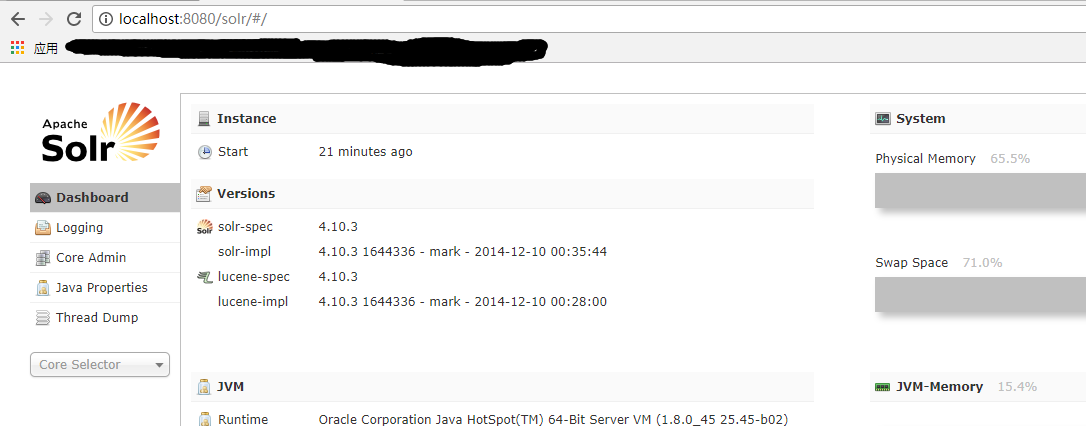
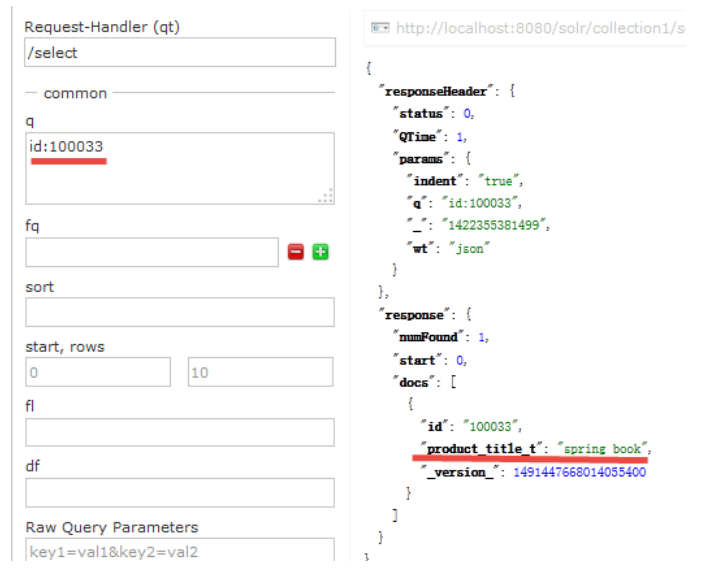
6--启动tomcat访问http://localhost:8080/solr/ 成功如下



****************************************************************************************************







*************************************************************************************

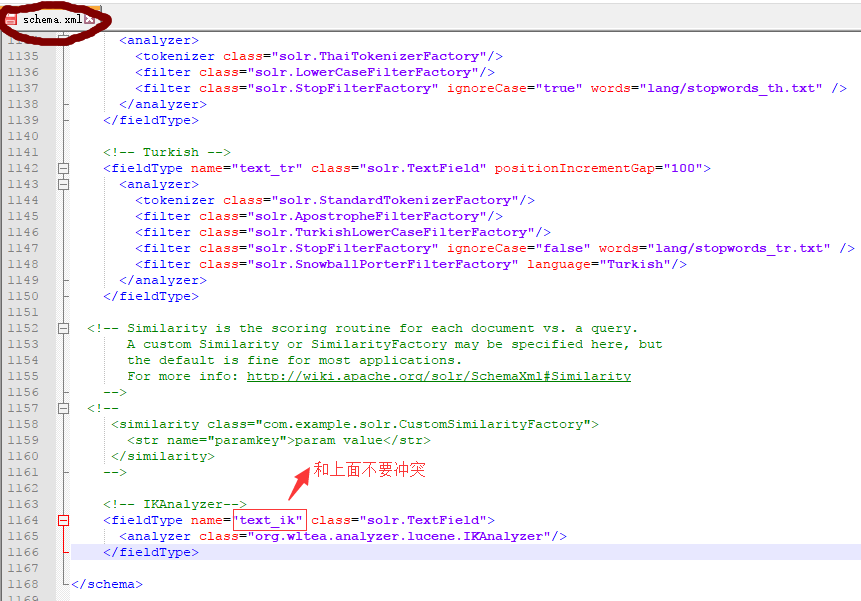


<!-- IKAnalyzer-->
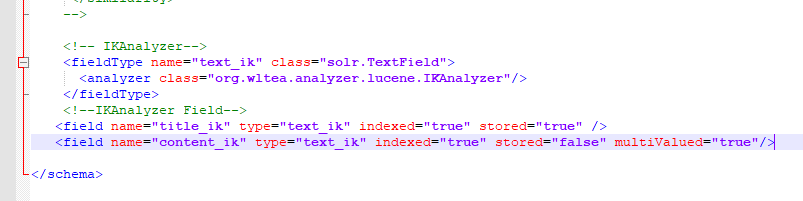
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<!--IKAnalyzer Field-->
<field name="title_ik" type="text_ik" indexed="true" stored="true" />
<field name="content_ik" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典
-->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
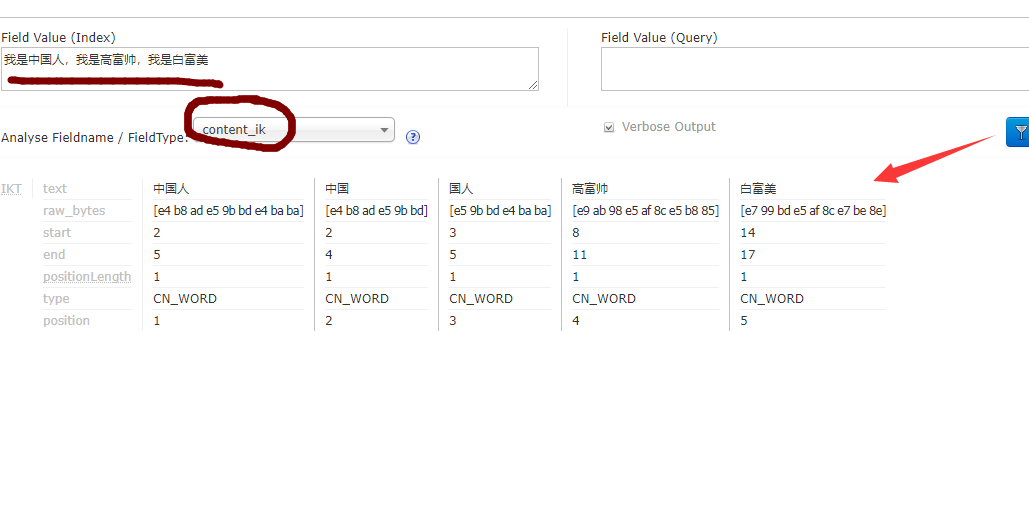
我 是 a an and are as at be but by for if in into is it no not of on or such that the their then there these they this to was will with
高富帅
白富美
中国人

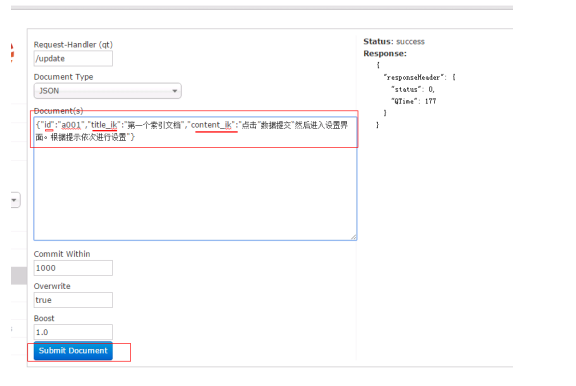
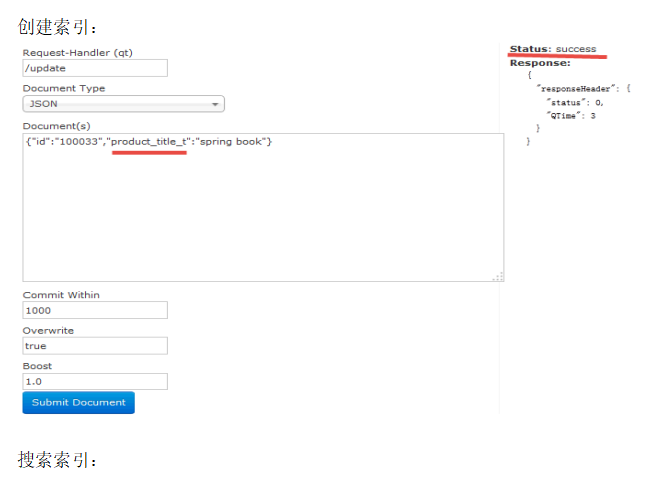
注意:如果id相同那么就是修改(底层是先删除在添加)


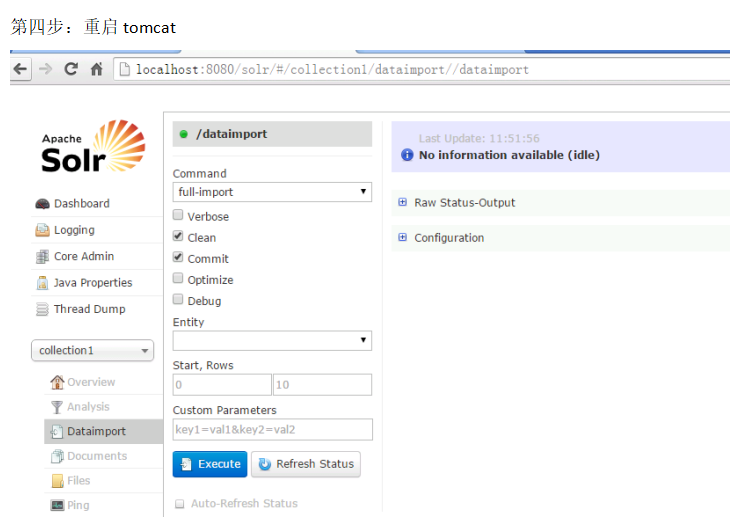
<requestHandler name="/dataimport"
class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
<?xml version="1.0" encoding="UTF-8" ?> <dataConfig> <dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/lucene" <!--注意修改数据库--> user="root" password="root"/> <document> <!--查询映射--> <entity name="product" query="SELECT pid,name,catalog_name,price,description,picture FROM products "> <field column="pid" name="id"/> <field column="name" name="product_name"/> <field column="catalog_name" name="product_catalog_name"/> <field column="price" name="product_price"/> <field column="description" name="product_description"/> <field column="picture" name="product_picture"/> </entity> </document> </dataConfig>
注意schema.xml里面没有相关域的配置,故需要添加

<!--product--> <field name="product_name" type="text_ik" indexed="true" stored="true"/> <field name="product_price" type="float" indexed="true" stored="true"/> <field name="product_description" type="text_ik" indexed="true" stored="false" /> <field name="product_picture" type="string" indexed="false" stored="true" /> <field name="product_catalog_name" type="string" indexed="true" stored="true" /> <!--拷贝域,名字和描述都拷贝到keywords里--> <field name="product_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/> <copyField source="product_name" dest="product_keywords"/> <copyField source="product_description" dest="product_keywords"/>

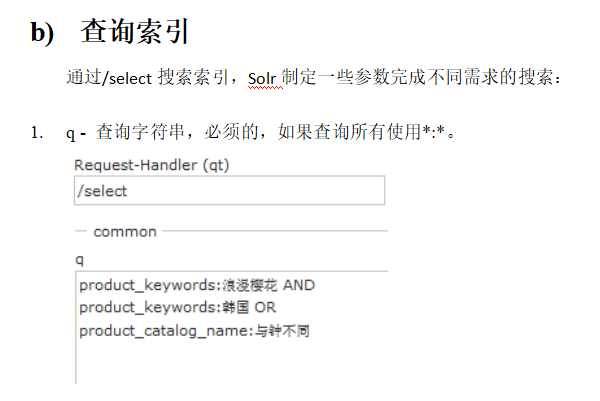
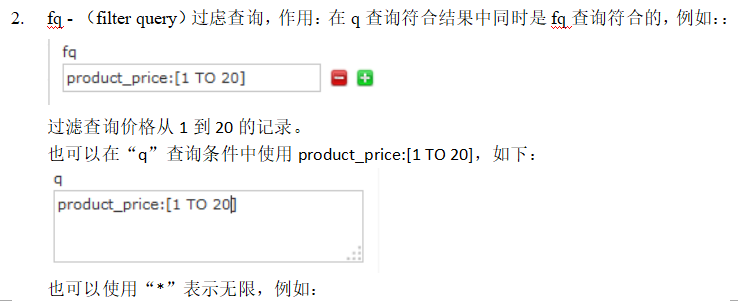
大括号表示不包含,中括号表示包含