一、复习
反射 必须会 必须能看懂 必须知道在哪儿用
hasattr getattr setattr delattr
内置方法 必须能看懂 能用尽量用
__len__ len(obj)的结果依赖于obj.__len__()的结果,计算对象的长度
__hash__ hash(obj)的结果依赖于obj.__hash__()的结果,计算对象的hash值
__eq__ obj1 == obj2 的结果依赖于obj.__eq__()的结果,用来判断值相等
__str__ str(obj) print(obj) '%s'%obj 的结果依赖于__str__,用来做输出、显示
__repr__ repr(obj) '%r'%obj的结果依赖于__repr__,还可以做str的备胎
__format__ format() 的结果依赖于__format__的结果,是对象格式化的
__call__ obj()相当于调用__call__,实现了__call__的对象是callable的
__new__ 构造方法,在执行__init__之前执行,负责创建一个对象,在单例模式中有具体的应用
__del__ 析构方法,在对象删除的时候,删除这个对象之前执行,主要用来关闭在对象中打开的系统的资源
class A:
def __getitem__(self, item):
print(item)
a = A()
a['bbb'] # 对象['值'] 触发了__getitem__
执行输出:
bbb
__getitem__ 对象[]的形式对对象进行增删改查 __setitem__ __delitem__ __delattr__ del obj.attr 用来自定义删除一个属性的方法
单例模式
只有一个对象 只开了一个内存空间
创建一个类 单例模式中的对象属性编程类中的静态属性,所有的方法变成类方法
java的单例模式,是依赖__new__来完成的
设计模式 —— java
python中的单例模式 是使用__new__
只要执行了析构函数,说明对象要删除了
delattr不需要重写,python自带
面试题:
写一个类 定义100个对象
拥有三个属性 name age sex
如果两个对象的name 和 sex完全相同
我们就认为这是一个对象
忽略age属性
做这100个对象的去重工作
可哈希,跟不可变没有直接关系
开发这个算法的人,叫哈希
hash算法 一个值 进行一系列的计算得出一个数字在一次程序执行中总是不变
来让每一个不同的值计算出的数字都不相等
创建一个对象
class Person:
def __init__(self,name,age,sex):
self.name = name
self.age = age
self.sex = sex
def __hash__(self):
# hash算法本身就存在了 且直接在python中就能调用
# 姓名相同 性别相同的对象的hash值应该相等才行
# 姓名性别都是字符串
return hash(self.name+self.sex)
def __eq__(self, other):
if self.name == other.name and self.sex == other.sex:
return True
obj_lst = []
#手动创建8个对象,将对象写入列表
obj_lst.append(Person('alex', 80, 'male'))
obj_lst.append(Person('alex', 70, 'male'))
obj_lst.append(Person('alex', 60, 'male'))
obj_lst.append(Person('boss_jin', 50, 'male'))
obj_lst.append(Person('boss_jin', 40, 'male'))
obj_lst.append(Person('boss_jin', 30, 'male'))
obj_lst.append(Person('nezha', 20, 'male'))
obj_lst.append(Person('nezha', 10, 'male'))
#列表去重
obj_lst = set(obj_lst)
#打印列表
for obj in obj_lst:print(obj.name)
执行输出:
alex
boss_jin
nezha
set对一个序列对象(有索引的对象)去重,依赖于这个对象的两个方法 hash和wq
key hash 数字 --》 内存地址 --》 value
set hash 数字 --》 内存地址 --》 set中的元素
'aaa' hash A
如果值存在,则覆盖
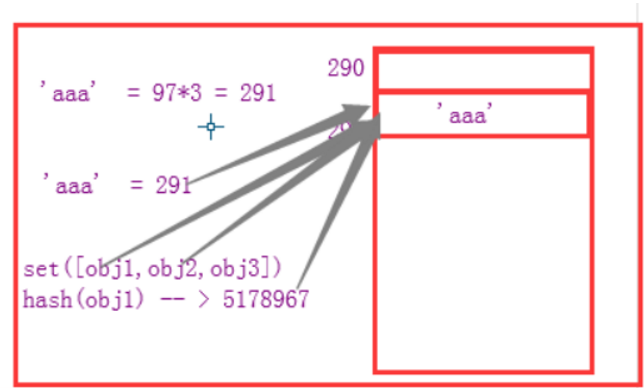
那么问题来了:
判断第100个元素时,需要做100次__eq__
set 对一个对象序列去重,如何判断这2个值是否相等
值a进行hash --> 存值
值b进行hash --> 判断值是否相等 -相等-> 说明是一样的
不相等-> 在开辟一个空间 来存放b
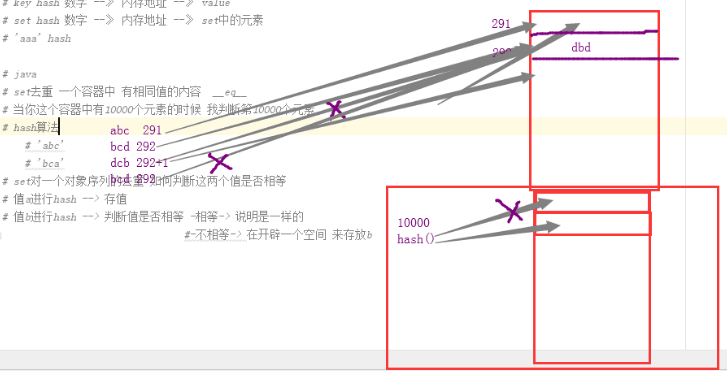
因为set依赖__hash__和__eq__
所以在类里面,重新定义这2个方法,可以做个性化需求
最终得到我们想要的结果。
二、序列化模块json,pickle,shelve
什么是模块?
常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
简单来说,py文件就是模块
python之所以好用,就是因为模块多
比如:
itchat 微信模块,模拟微信操作,自动回复
beautiful soap 爬虫工具
selenium 网页自动化测试工具
diango tornado web前段框架
所有和python有关的模块,都在这个网站上面
https://pypi.org/
python模块分为3种:
1.内置模块 python安装时自带的
2.扩展模块 比如上面提到的itchat 等等
3.自定义模块 自己写的模块
什么叫序列化——将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。
序列化的目的
1、以某种存储形式使自定义对象持久化;
2、将对象从一个地方传递到另一个地方。
3、使程序更具维护性。
比如a发送一个数据给b
由于发送数据,必须是二进制的。所以需要经历编码到解码的过程
dic = {'a':(1,2,3)}
s = str(dic).encode(encoding='utf-8') # 编码
ret = s.decode(encoding='utf-8') # 解码
print(ret) # 查看数据
print(type(ret)) # 查看类型
print(type(eval(ret))) # 还原为字典
执行输出:
{'a': (1, 2, 3)}
<class 'str'>
<class 'dict'>
使用eval不安全,有可能是病毒,接收方,啪的一些,就执行了。
这个时候,就需要用到序列化了。
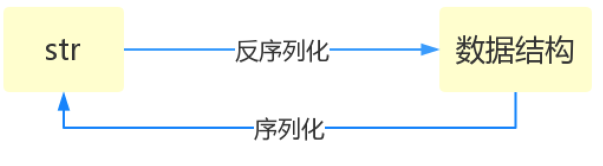
dic --> 字符串 序列化
字符串 --> dic 反序列化
序列化 == 创造一个序列 ==》创造一个字符串
实例化 == 创造一个实例
python中的序列化模块
json 所有的编程语言都通用的序列化格式
它支持的数据类型非常有限 数字 字符串 列表 字典
pickle 只能在python语言的程序之间传递数据用的
pickle支持python中所有的数据类型
shelve python3.* 之后才有的
Json
Json模块提供了四个功能:dumps、dump、loads、load
序列化
import json # 导入模块
dic = {"慕容美雪":(170,60,'赏花')}
ret = json.dumps(dic) # 序列化
print(type(dic),dic) # 查看原始数据类型
print(type(ret),ret) # 查看序列化后的数据
执行输出:
<class 'dict'> {'慕容美雪': (170, 60, '赏花')}
<class 'str'> {"u6155u5bb9u7f8eu96ea": [170, 60, "u8d4fu82b1"]}
从结果中,可以看出:
原始数据类型是字典,序列化之后,就是字符串类型。而且中文变成了看不懂的字符串。
这是因为json.dumps 序列化时对中文默认使用的ascii编码。
想输出真正的中文需要指定ensure_ascii=False
import json # 导入模块
dic = {"慕容美雪":(170,60,'赏花')}
ret = json.dumps(dic,ensure_ascii=False) # 序列化时,不使用ascii码
print(type(dic),dic) # 查看原始数据类型
print(type(ret),ret) # 查看序列化后的数据
执行输出:
<class 'dict'> {'慕容美雪': (170, 60, '赏花')}
<class 'str'> {"慕容美雪": [170, 60, "赏花"]}
由于json不识别元组,json认为元组和列表是一回事,所以变成了列表。
在json中,引号,统一使用双引号
反序列化
import json # 导入模块
dic = {"慕容美雪":(170,60,'赏花')}
ret = json.dumps(dic,ensure_ascii=False) # 序列化时,不使用ascii码
res = json.loads(ret) # 反序列化
print(type(res),res) # 查看反序列化后的数据
执行输出:
<class 'dict'> {'慕容美雪': [170, 60, '赏花']}
从结果中,可以看出,原来的单引号由还原回来了。
反序列化,比eval要安全。所以eval尽量少用。
dump和load 是直接将对象序列化之后写入文件
依赖一个文件句柄
dump 将序列化内容写入文件
执行程序,查看文件美雪内容为:
{"u6155u5bb9u7f8eu96ea": [170, 60, "u8d4fu82b1"]}
要想文件写入中文,可以加参数ensure_ascii=False
import json # 导入模块
dic = {"慕容美雪":(170,60,'赏花')}
f = open('美雪','w',encoding='utf-8')
json.dump(dic,f,ensure_ascii=False) # 先接收要序列化的对象,再接收文件句柄
f.close()
执行程序,再次查看文件内容:
{"慕容美雪": [170, 60, "赏花"]}
load 读取文件中的序列化内容
import json # 导入模块
dic = {"慕容美雪":(170,60,'赏花')}
f = open('美雪','r',encoding='utf-8')
ret = json.load(f) #接收文件句柄
print(ret) # 查看内容
print(type(ret)) # 查看变量类型
f.close() # 最后记得关闭文件句柄
执行输出:
{'慕容美雪': [170, 60, '赏花']}
<class 'dict'>
其他参数
import json
data = {'username':['李华','二愣子'],'sex':'male','age':16}
json_dic2 = json.dumps(data,sort_keys=True,indent=4,separators=(',',':'),ensure_ascii=False)
print(json_dic2)
执行输出:
{
"age":16,
"sex":"male",
"username":[
"李华",
"二愣子"
]
}
执行结果和PHP的pre输出很相似,也是格式化输出
参数说明:
Skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key
ensure_ascii:,当它为True的时候,所有非ASCII码字符显示为uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。)
indent:应该是一个非负的整型,如果是0就是顶格分行显示,如果为空就是一行最紧凑显示,否则会换行且按照indent的数值显示前面的空白分行显示,这样打印出来的json数据也叫pretty-printed json
separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(',’,’:’);这表示dictionary内keys之间用","隔开,而KEY和value之间用":"隔开。
sort_keys:将数据根据keys的值进行排序。
下面有3个字典,如何写入文件?
dic1 = {"S":(170,60,'唱歌')}
dic2 = {"H":(170,60,'唱歌')}
dic3 = {"E":(170,60,'唱歌')}
使用常规方法json.dump一行行写入,再次读取时,会报错。
下面介绍正确做法
写入多行
import json
dic1 = {"S":(170,60,'唱歌')}
dic2 = {"H":(170,60,'唱歌')}
dic3 = {"E":(170,60,'唱歌')}
f = open('she','a',encoding='utf-8')
f.write(json.dumps(dic1)+'
') # 写入一行内容,注意,一定要加换行符
f.write(json.dumps(dic2)+'
')
f.write(json.dumps(dic3)+'
')
f.close() # 关闭文件句柄
执行程序,查看文件she内容:
{"S": [170, 60, "u5531u6b4c"]}
{"H": [170, 60, "u5531u6b4c"]}
{"E": [170, 60, "u5531u6b4c"]}
读取多行文件内容
import json
f = open('she','r',encoding='utf-8')
for i in f:
print(json.loads(i.strip()))
f.close()
执行输出:
{'S': [170, 60, '唱歌']}
{'H': [170, 60, '唱歌']}
{'E': [170, 60, '唱歌']}
总结:
dumps序列化 loads反序列化 只在内存中操作数据 主要用于网络传输 和多个数据与文件打交道
dump序列化 load反序列化 主要用于一个数据直接存在文件里—— 直接和文件打交道
看下面一段代码:
import json
dic = {(170,60,'唱歌'):"S"}
print(json.dumps(dic))
执行报错:
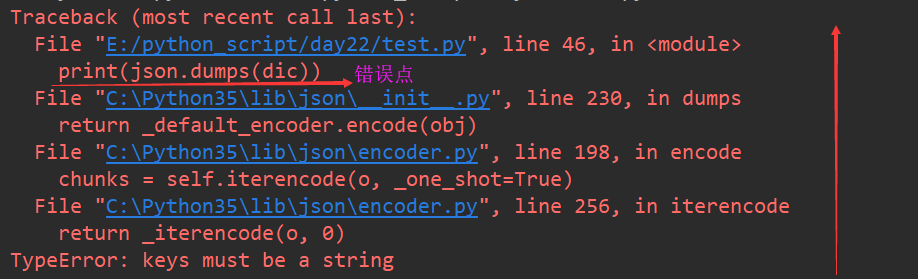
get新知识点:
看python代码错误,要从下向上看。
第一个行,一般是错误点,看到蓝色的字体没有?鼠标单击一下,就会跳转,直接定位到错误在具体的哪一行
点击之后,看到是print这一行报错了
json不支持元组 不支持除了str数据类型之外的key
pickle
用于python特有的类型 和 python的数据类型间进行转换
pickle模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load (不仅可以序列化字典,列表...可以把python中任意的数据类型序列化)
pickle的方法,和json是一样的,有4个
上一个例子的代码,pickle可以序列化
dumps 序列化
import pickle
dic = {(170,60,'唱歌'):"S"}
print(pickle.dumps(dic))
执行输出:
b'x80x03}qx00KxaaK<Xx06x00x00x00xe5x94xb1xe6xadx8cqx01x87qx02Xx01x00x00x00Sqx03s.'
输出结果是bytes类型的
dump 写入文件
文件模式必须带b,因为它是bytes类型
import pickle
dic = {(170,60,'唱歌'):"S"}
f = open('s','wb') #使用dump必须以+b的形式打开文件,编码不需要指定,因为是bytes类型
pickle.dump(dic,f)
f.close() # 注意要关闭文件句柄
执行程序,查看文件,文件内容是乱码的

load 读取文件内容
import pickle
f = open('s','rb') # bytes类型不需要指定编码
print(pickle.load(f))
f.close() # 注意要关闭文件句柄
执行输出:
{(170, 60, '唱歌'): 'S'}
dump 写入多行内容
import pickle
dic1 = {"张靓颖":(170,60,'唱歌')}
dic2 = {"张韶涵":(170,60,'唱歌')}
dic3 = {"梁静茹":(170,60,'唱歌')}
f = open('singer','wb')
pickle.dump(dic1,f)
pickle.dump(dic2,f)
pickle.dump(dic3,f)
f.close()
执行程序,查看文件内容,是乱码的

load 读取文件内容
import pickle
f = open('singer','rb')
print(pickle.load(f))
print(pickle.load(f))
print(pickle.load(f))
print(pickle.load(f)) # 多读取一行,就会报错
f.close()
执行输出:
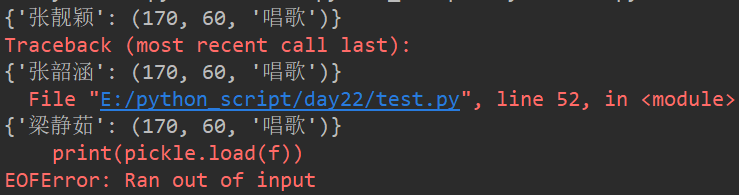
为了解决这个问题,需要用到while循环+try
import pickle
f = open('singer','rb')
while True:
try:
print(pickle.load(f))
except Exception: # 接收一切错误
break # 跳出循环
f.close()
执行输出:
{'张靓颖': (170, 60, '唱歌')}
{'张韶涵': (170, 60, '唱歌')}
{'梁静茹': (170, 60, '唱歌')}
总结:
json 在写入多次dump的时候 不能对应执行多次load来取出数据,pickle可以
json 如果要写入多个元素 可以先将元素dumps序列化,f.write(序列化+'
')写入文件
读出元素的时候,应该先按行读文件,在使用loads将读出来的字符串转换成对应的数据类型
关于序列化自定义类的对象
class A:
def __init__(self,name,age):
self.name=name
self.age=age
a = A('alex',80)
import json
json.dumps(a)
执行报错:
TypeError: <__main__.A object at 0x0000022B1BB2BF28> is not JSON serializable
json不能序列化对象
使用pickle序列化
import pickle
class A:
def __init__(self,name,age):
self.name=name
self.age=age
a = A('alex',80)
ret = pickle.dumps(a) # 序列化对象
print(ret)
obj = pickle.loads(ret) # 反序列化
print(obj.__dict__) # 查看对象属性<br>f.close()
执行输出:
b'x80x03c__main__
A
qx00)x81qx01}qx02(Xx04x00x00x00nameqx03Xx04x00x00x00alexqx04Xx03x00x00x00ageqx05KPub.'
{'name': 'alex', 'age': 80}
将对象a写入文件
import pickle
class A:
def __init__(self,name,age):
self.name=name
self.age=age
a = A('alex',80)
f = open('a','wb')
obj = pickle.dump(a,f)
f.close()
执行程序,查看文件内容,是乱码的
假设是一款python游戏,就可以将人物的属性,写入文件。
再次登录时,就可以重新加载了。用pickle就比较方便了。
当删除一个类的时候(注释代码),再次读取文件,就会报错
import pickle
# class A:
# def __init__(self,name,age):
# self.name=name
# self.age=age
# a = A('alex',80)
f = open('a','rb')
obj = pickle.load(f)
print(obj.__dict__)
f.close()
执行报错
AttributeError: Can't get attribute 'A' on <module '__main__' from 'E:/python_script/day25/test.py'>
提示找不到类A
将对象反序列时,必须保证该对象的类必须存在,否则读取报错
再次打开注释,执行以下,就正常了。
三、shelve
shelve也是python提供给我们的序列化工具,比pickle用起来更简单一些。
shelve只提供给我们一个open方法,是用key来访问的,使用起来和字典类似。
特点:
1、shelve模块是一个简单的key,value将内存数据通过文件持久化的模块。
2、shelve模块可以持久化任何pickle可支持的python数据格式。
3、shelve就是pickle模块的一个封装。
4、shelve模块是可以多次dump和load。
优点:轻量级,键值存储系统;
缺点:
适合读,不适合更新,在writeback时会把所有的数据都重新写入,结果就是可能消耗内存很多,写入耗时;
不能并发的读写,不过可以使用Unix文件锁进行控制(fcntl);
import shelve # python专有的序列化模块
f = shelve.open('shelve_file') # 打开文件
f['key'] = {'int':10, 'float':9.5, 'string':'Sample data'} #直接对文件句柄操作,就可以存入数据
f.close()
执行程序,会产生3个文件
shelve_file.bak
shelve_file.dat
shelve_file.dir
这和MySQL的MyISAM表,有点类似。创建一个表时,也会创建3个文件。
读取文件
import shelve
f1 = shelve.open('shelve_file')
existing = f1['key'] #取出数据的时候也只需要直接用key获取即可,但是如果key不存在会报错
f1.close()
print(existing)
执行输出:
{'string': 'Sample data', 'int': 10, 'float': 9.5}
这个模块有个限制,它不支持多个应用同一时间往同一个DB进行写操作。所以当我们知道我们的应用如果只进行读操作,我们可以让shelve通过只读方式打开DB
import shelve
f = shelve.open('shelve_file', flag='r') # flag = 'r' 表示只读方式
existing = f['key']
f.close()
print(existing)
执行输出:
{'float': 9.5, 'int': 10, 'string': 'Sample data'}
修改变量
import shelve
f = shelve.open('shelve_file', flag='r')
f['key']['int'] = 50 # 修改一个值
existing = f['key'] # 取值
f.close()
print(existing) # 打印结果
执行输出:
{'string': 'Sample data', 'int': 10, 'float': 9.5}
从结果上来,并没有改变,因为此时是只读模式
先把数据覆盖一次
import shelve
f = shelve.open('shelve_file')
f['key'] = {'int':10, 'float':9.5, 'string':'Sample data'}
f.close()
但是下面一种情况,是可以改变的
import shelve
f = shelve.open('shelve_file', flag='r')
f['key']['int'] = 50 # 不能修改已有结构中的值
f['key']['new'] = 'new' # 不能在已有的结构中添加新的项
f['key'] = 'new' # 但是可以覆盖原来的结构
existing = f['key'] # 取值
f.close()
print(existing) # 打印结果
执行输出:
new
明明是只读,却可以改。说明有bug
shelve 尽量少用,有坑
新增一个属性
import shelve
#重新覆盖数据
f = shelve.open('shelve_file')
f['key'] = {'int':10, 'float':9.5, 'string':'Sample data'} #直接对文件句柄操作,就可以存入数据
f.close()
#新增一个属性
f1 = shelve.open('shelve_file')
f1['key']['new_value'] = 'this was not here before'
print(f1['key'])
f1.close()
执行输出:
{'float': 9.5, 'int': 10, 'string': 'Sample data'}
发现新增的属性没有
由于shelve在默认情况下是不会记录待持久化对象的任何修改的,所以我们在shelve.open()时候需要修改默认参数,否则对象的修改不会保存。
import shelve
#新增一个属性
f1 = shelve.open('shelve_file', writeback=True)
f1['key']['new_value'] = 'this was not here before'
print(f1['key'])
f1.close()
执行输出:
{'new_value': 'this was not here before', 'string': 'Sample data', 'int': 10, 'float': 9.5}
新增的属性就出现了
writeback方式有优点也有缺点。优点是减少了我们出错的概率,并且让对象的持久化对用户更加的透明了;但这种方式并不是所有的情况下都需要,首先,使用writeback以后,shelf在open()的时候会增加额外的内存消耗,并且当DB在close()的时候会将缓存中的每一个对象都写入到DB,这也会带来额外的等待时间。因为shelve没有办法知道缓存中哪些对象修改了,哪些对象没有修改,因此所有的对象都会被写入。
shelve由很多坑,不建议使用
推荐使用Json和picker
三、hashlib模块
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
hash算法,每次执行,都会变。跟时间有关系
hash 哈希算法 可hash数据类型——>数字的过程
hashlib —— 摘要算法
也是一些算法的集合,有好多算法
字符串 --> 数字
不同的字符串 --> 数字一定不同
无论在哪台机器上,在什么时候计算,对相同的字符串结果总是一样的
摘要过程不可逆
用法:
文件的一致性校验
密文验证的时候加密
比如文件下载
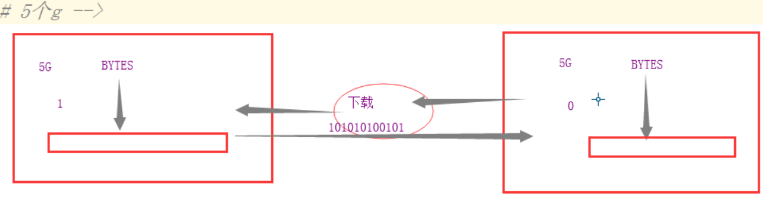
通过对文件做SHA1算法,判断下载的文件,和服务器的文件是否一致。就能知道文件是否下载完成。
密码验证
有一个密码文件,内容如下:
下划线左边是用户名,右边是密码
ALEX|ALEX3714 EGON|123456 NAZHA|9876543
假如这个文件泄露了,那么别人就可以直接登录了。
所有的密码,都不应该明文存储,必须通过算法转换才行
比如把ALEX3714转换成f58be8e9cb357ad3d59ec47b165c2b19
这段32位字符串,是无法解密成ALEX3714的
因为摘要过程不可逆
那么登录的时候,把密码通过算法转换,和文件的内容值做对比。如果一致,则登录成功。
下面介绍2种常用的算法
md5算法 通用的算法
sha算法 安全系数更高,sha算法有很多种,后面的数字越大安全系数越高,
得到的数字结果越长,计算的时间越长。目前最高是sha512
加密密码ALEX3714
import hashlib
m = hashlib.md5()
m.update('ALEX3714'.encode('utf-8')) # update只接收bytes类型
print(m.hexdigest()) # 返回摘要,作为十六进制数据字符串值
执行输出:
f58be8e9cb357ad3d59ec47b165c2b19
返回结果是一个32位长度的十六进制数据字符串,结果是定长的。
hexdigest 这个单词,Pycharm没有自动补全。怎么记呢?hex表示十六进制,digest表示摘要
理论上来讲,md5不能反解
无论在哪台机器上,在什么时候计算,对相同的字符串结果总是一样的
针对这个特点,有专门的md5破解网站,将所有常见的密码,进行md5计算
将返回的摘要结果写入数据库,比如
123 -> 202cb962ac59075b964b07152d234b70 123456 -> e10adc3949ba59abbe56e057f20f883e abc -> 900150983cd24fb0d6963f7d28e17f72 ...
那么就可以通过摘要反向得出对应的密码
这种行为称之为暴力破解和撞库
为了确保存储的用户口令不是那些已经被计算出来的常用口令的MD5
通过对原始口令加一个复杂字符串来实现,俗称"加盐":
hashlib.md5("salt".encode("utf8"))
经过Salt处理的MD5口令,只要Salt不被黑客知道,即使用户输入简单口令,也很难通过MD5反推明文口令。
对12345做加盐处理
import hashlib
m = hashlib.md5('wahaha'.encode('utf-8'))
m.update('123456'.encode('utf-8'))
print(m.hexdigest())
执行输出:
d1c59b7f2928f9b1d63898133294ad2c
将这段密文复制到一下网站
http://www.cmd5.com/
就不那么容易反解出来了
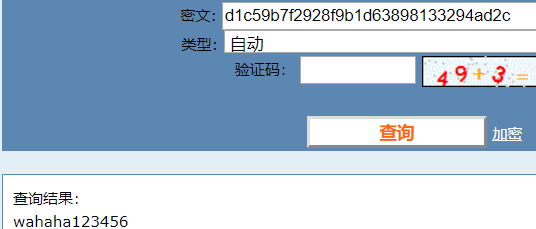
我擦勒,特么的,计算出来了???
请忽略我说的上一句话
注册和登录校验,都要用加盐
就算数据库泄露,也不影响,因为加盐了
除非盐被泄露了,才能破解登录
黑客注册500个用户,密码都不一样
只要拿到数据库,通过一定的规律,也可以反解出来加密盐
那怎么办呢?
有更高级的办法,动态加盐
import hashlib
username = 'alex' # 用户名
m = hashlib.md5(username.encode('utf-8')) # 密码盐为用户名
m.update('123456'.encode('utf-8'))
print(m.hexdigest())
执行输出:
94e4ccf5e2749b0bfe0428603738c0f9
因为每个用户名是不一样的,即便是注册了500个账号,也不能随便破解
再高级一点的密码盐
import hashlib
username = 'alex' # 用户名
m = hashlib.md5(username[:2:2].encode('utf-8')) # 密码盐为用户名
m.update('123456'.encode('utf-8'))
print(m.hexdigest())
执行输出:
dc483e80a7a0bd9ef71d8cf973673924
再试一波看看
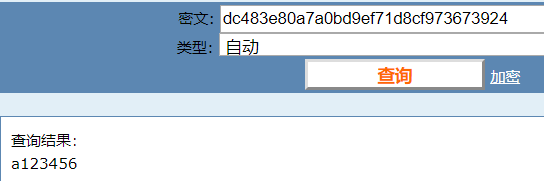
卧槽!不行,我得再升级一下
双层密码盐
import hashlib
username = 'alex' # 用户名
salt = 'what the fuck!叫你破解!叫你破解!你来啊!!!'
m = hashlib.md5((username+salt).encode('utf-8')) # 双层密码盐
m.update('123456'.encode('utf-8'))
print(m.hexdigest())
我就不信这个邪!
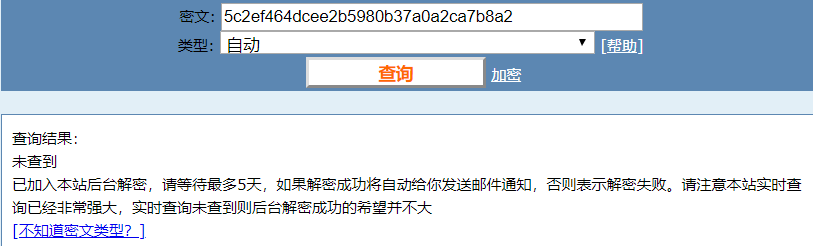
看吧,破解不了吧。
只要加盐方法,不被泄露就行。登录以及注册,务必要加盐。