In our last tutorial we learned and understood how data redundancy or repetition can lead to several issues like Insertion, Deletion and Updation anomalies and how Normalization can reduce data redundancy and make the data more meaningful(规范化可以减少数据冗余并使得数据更有意义).
In this tutorial we will learn about the 1st Normal Form which is more like the Step 1 of the Normalization process. The 1st Normal form expects you to design your table in such a way that it can easily be extended(易于拓展) and it is easier for you to retrieve data from it whenever required.
If tables in a database are not even in the 1st Normal Form, it is considered as bad database design(如果不满足第一范式,那么就是一个糟糕的数据库设计).
Rules for First Normal Form
The first normal form expects you to follow a few simple rules while designing your database, and they are:
Rule 1: Single Valued Attributes
Each column of your table should be single valued which means they should not contain multiple values. We will explain this with help of an example later, let's see the other rules for now.(每个列都应该是单值的)
Rule 2: Attribute Domain should not change
This is more of a "Common Sense" rule. In each column the values stored must be of the same kind or type.(对应列的属性和类型应该是相同的)
For example: If you have a column dob to save date of births of a set of people, then you cannot or you must not save 'names' of some of them in that column along with 'date of birth' of others in that column. It should hold only 'date of birth' for all the records/rows.
Rule 3: Unique name for Attributes/Columns
This rule expects that each column in a table should have a unique name. This is to avoid confusion at the time of retrieving data or performing any other operation on the stored data.
If one or more columns have same name, then the DBMS system will be left confused.
Rule 4: Order doesn't matters
This rule says that the order in which you store the data in your table doesn't matter.
Time for an Example
Although all the rules are self explanatory still let's take an example where we will create a table to store student data which will have student's roll no., their name and the name of subjects they have opted for.
Here is our table, with some sample data added to it.
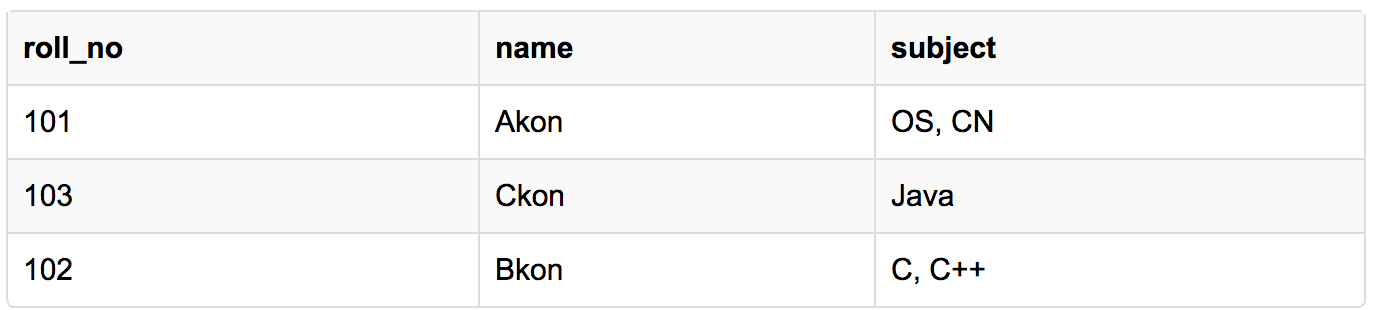
But out of the 3 different students in our table, 2 have opted for more than 1 subject. And we have stored the subject names in a single column. But as per the 1st Normal form each column must contain atomic value.Our table already satisfies 3 rules out of the 4 rules, as all our column names are unique, we have stored data in the order we wanted to and we have not inter-mixed different type of data in columns.
(看到这里毛骨悚然啊,我发现以前的涉及到的表里面好多都是多值,比如像"aaa;bbb;ccc"这种分隔的,查询出来然后split以下,再去查找对应的表)
How to solve this Problem?
It's very simple, because all we have to do is break the values into atomic values.
Here is our updated table and it now satisfies the First Normal Form.
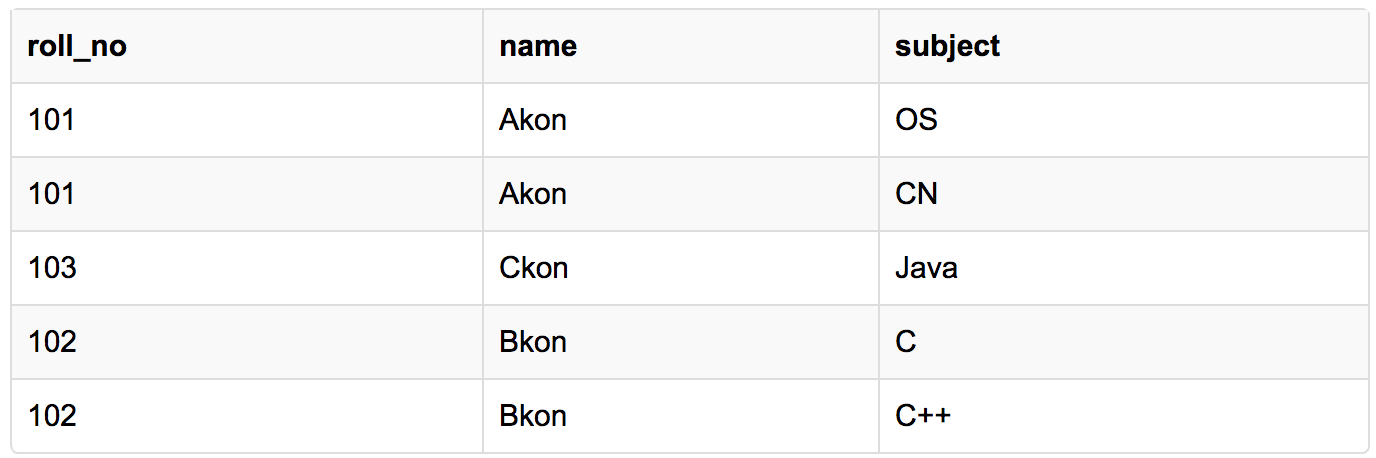
Using the First Normal Form, data redundancy increases, as there will be many columns with same data in multiple rows but each row as a whole will be unique.By doing so, although a few values are getting repeated but values for the subject column are now atomic for each record/row.