多线程实践分页查询
多线程是个好东西,用好了可以对性能提升很大。之前写了一分页查询的页面,大致的模型是这样的:
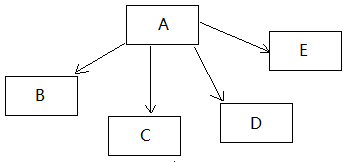
希望对A进行分页查询,但是又想把B,C,D,E的信息也带出来,最开始是没有用多线程,强行查询除了A的List,然后遍历A中的元素,依次查询出对应的B,C,D和E。当时看了一下请求时间大概有700~800ms,确实是肉眼可见的慢。然后想着不行,还是用多线程优化一下吧,然后把查询和A关联的表的信息任务划分一下,交给不同的线程处理,组装数据完毕之后,主线程把最后的List返回到前台。最后的查询时间降低到160ms左右。
为什么需要用线程池
如果不使用线程池的话,大概率使用线程的方式是这样的:

每次使用线程的时候,都要出创建一个线程的实例,最后用完了之后还要销毁它,线程在Linux也叫轻量级进行,虽然有个轻量级前缀,但是它的创建和销毁也是比较消耗系统资源的。想象一下一次创建几十个线程,使用完了在销毁;然后在创建十几个线程,再销毁,这个性能损耗就很客观了(这个暂时是吓唬你的,因为我还没有测过)。除了创建和销毁线程的开销之外,活动的线程也消耗系统资源。在一个 JVM 里创建太多的线程可能会导致系统由于过度消耗内存而用完内存或"切换过度"。
线程池的好处:
- 实现了线程的重用,降低因为重复创建线程而带来的开销
- 任务来到的时候马上就有线程可用,消除了线程创建所带来的延迟,响应更快
这种设计思想在很多地方是可以见到的:
- Integer的享元设计模式
- 数据库的连接池
都是基于性能的考量。
java的线程和操作系统中进程的关系?
这个先留着......
java中的线程池
已经看博客的时候经常会看到java中有四种线程池:
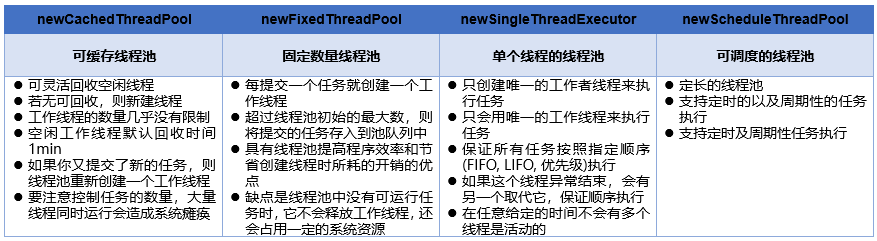
但是今天去看了下java.util.concurrent.Executors的源码,发现了好像不止这四种呀,然后网上看了下有七种!
- newCachedThreadPool :创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
- newFixedThreadPool:创建一个固定数目的、可重用的线程池。
- newScheduledThreadPool:创建一个定长线程池,支持定时及周期性任务执行。
- newSingleThreadExecutor:创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
- newSingleThreadScheduledExcutor:创建一个单例线程池,定期或延时执行任务。
- newWorkStealingPool:创建持有足够线程的线程池来支持给定的并行级别,并通过使用多个队列,减少竞争,它需要穿一个并行级别的参数,如果不传,则被设定为默认的CPU数量。
- ForkJoinPool:支持大任务分解成小任务的线程池,这是Java8新增线程池,通常配合ForkJoinTask接口的子类RecursiveAction或RecursiveTask使用。
线程池的创建
其中有好几种都是通过类java.util.concurrent.ThreadPoolExecutor创建出来的,而它又有好几种构造方法,这里挑一个典型的来分析一下:
1 public ThreadPoolExecutor(int corePoolSize, 2 int maximumPoolSize, 3 long keepAliveTime, 4 TimeUnit unit, 5 BlockingQueue<Runnable> workQueue) { 6 this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, 7 Executors.defaultThreadFactory(), defaultHandler); 8 }
参数解释:
- corePoolSize:一直保留在线程池中的线程数量,即使它们是空闲的也会赖着不走,除非你设置了allowCoreThreadTimeOut
- maximumPoolSize:在线程池中允许最大的线程数量
- keepAliveTime:当线程池中的线程数量比核心多的时候,这个时间是空闲着等待新任务的最长时间,一旦超过这个时间多的线程就会被回收掉
- unit:keepAliveTime的时间单位
- workQueue:让还没有分配线程执行的任务进入等待队列,只有当Runnable任务通过execute方法提交之后才会进入队列
- threadFactory:executor用于创建新线程的工厂
- handler:当执行受阻之后采取的策略
corePoolSize
核心池的大小,这个参数跟后面讲述的线程池的实现原理有非常大的关系。在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务,除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法,从这2个方法的名字就可以看出,是预创建线程的意思,即在没有任务到来之前就创建corePoolSize个线程或者一个线程。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中。
maximumPoolSize
线程池最大线程数,这个参数也是一个非常重要的参数,它表示在线程池中最多能创建多少个线程;
keepAliveTime
表示线程没有任务执行时最多保持多久时间会终止。默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize,即当线程池中的线程数大于corePoolSize时,如果一个线程空闲的时间达到keepAliveTime,则会终止,直到线程池中的线程数不超过corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0;
unit
参数keepAliveTime的时间单位,有7种取值,在TimeUnit类中有7种静态属性:
1 TimeUnit.DAYS; //天 2 TimeUnit.HOURS; //小时 3 TimeUnit.MINUTES; //分钟 4 TimeUnit.SECONDS; //秒 5 TimeUnit.MILLISECONDS; //毫秒 6 TimeUnit.MICROSECONDS; //微妙 7 TimeUnit.NANOSECONDS; //纳秒
workQueue
一个阻塞队列,用来存储等待执行的任务,这个参数的选择也很重要,会对线程池的运行过程产生重大影响,一般来说,这里的阻塞队列有以下几种选择:
1 ArrayBlockingQueue 2 LinkedBlockingQueue 3 SynchronousQueue
ArrayBlockingQueue和PriorityBlockingQueue使用较少,一般使用LinkedBlockingQueue和Synchronous。线程池的排队策略与BlockingQueue有关。
threadFactory
线程工厂,主要用来创建线程;
handler
表示当拒绝处理任务时的策略,有以下四种取值:
1 ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。 2 ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。 3 ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程) 4 ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
java中线程池类、接口和方法
查看相关的源码之后,画出如下的类图:
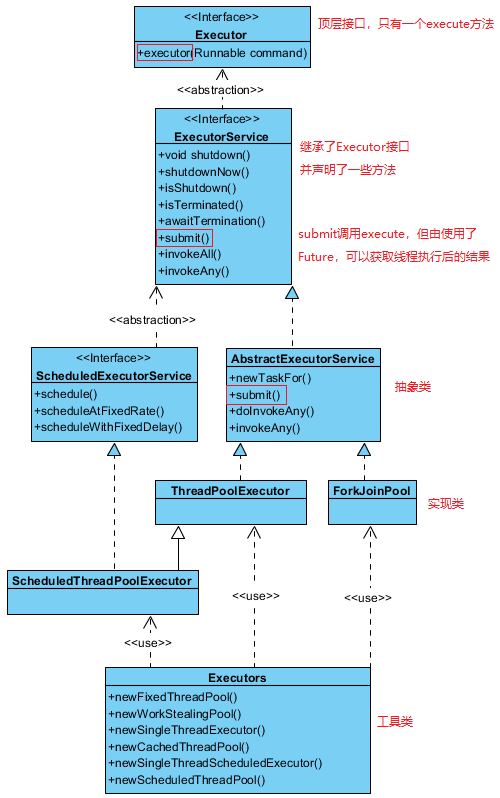
路子还是一样的:先是顶层接口,衍生接口,抽象类,实现类,工具类;这些接口或者类中的方法看一下就知道啥意思,但是内部的原理还要看下源码才能明白。
接下来从以下几方面研究一下线程池:
- 线程池状态
- 任务的执行
- 线程池中的线程初始化
- 任务缓存队列及排队策略
- 任务拒绝策略
- 线程池的关闭
- 线程池容量的动态调整
线程池状态
使用线程池的时候如何阻塞主线程,使线程池中的线程处理完任务之后,主线程接着执行?
如何设计一个线程池?
如何使线程池更加高效?
有哪些开源的线程池实现?
如何确定线程池中线程的数量?
参考
- https://blog.csdn.net/a369414641/article/details/48342253
- https://www.cnblogs.com/dolphin0520/p/3932921.html
- https://www.cnblogs.com/YFYkuner/p/5178684.html
- https://baike.baidu.com/item/MVCC/6298019
- https://www.cnblogs.com/chenpingzhao/p/5065316.html