通过前面章节的介绍,我们对什么是爬虫有了初步的认识,同时对如何爬取网页有了一个大概的了解。从本章起,我们将从理论走向实践,结合实际操作来进一步深化理解。
由于使用python进行爬虫抓取页面可供使用的工具众多,比如requests、scrapy、PhantomJS、Splash等,并且对于抓取的页面解析的工具也很多。我们这里从最简单的开始,使用requests库和beautifSoup工具进行静态页面抓取和解析。
等基本功扎实之后,我们可以使用更灵活多变的工具,不仅可以静态抓取,还可以动态抓取;不仅可以抓取单页面,还可以递归深度抓取。同时结合其他的渲染、存储、机器学习等工具,我们可以对数据进行处理、加工、建模、展示。
废话不多说,让我们开始今天的例子,抓取安徒生童话故事中的名篇《丑小鸭》。“工欲善其事,必先利其器”,在开始之前我们需要把准备工作做好,下载pycharm,并安装requests库和beautifSoup。安装结果如下:

开始爬虫的第一步,找到含有《丑小鸭》这篇童话故事的链接,我们这里使用的链接是:https://www.ppzuowen.com/book/antushengtonghua/7403.html。

在找到我们的目标链接之后,第二步就是分析网页。分析什么呢?当然是分析我们要爬取的内容在哪里。
根据我们前面的介绍,我们此次爬虫的目的是爬取丑小鸭这篇课文。根据这一目标,我们需要先来研究网页的构成。那么如何查看网页呢?一般是在浏览器的开发者模式下进行,对于chrome浏览器,我们可以使用快捷键F12进行查看,如图所示:
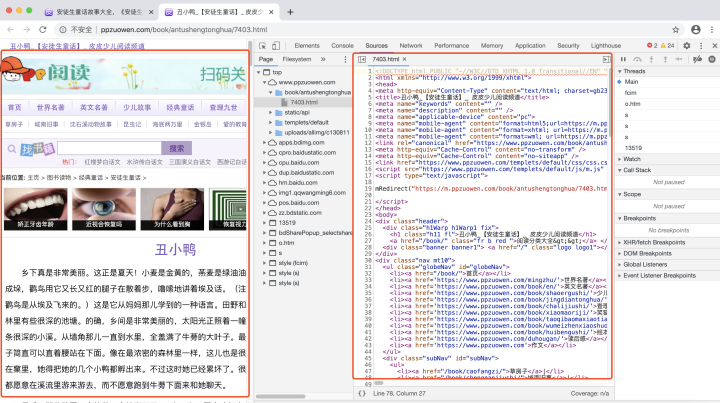
左边的是网页显示的内容,右边是网页的HTML文档。
通过对右边页面的分析,我们可以观察到,我们需要抓取的页面内容在一个<p></p>标签中:

既然页面找到了,需要抓取的内容的位置也找到了,那么现在我们需要解决的一个问题是:如何使用代码快速的进行目标内容的位置定位?
在理想的情况下,我们希望这个<p></p>标签有一个唯一的属性(通常为id或class),那么我们就可以直接通过这个属性进行位置定位。
但是很遗憾的是,在我们这个目标标签<p></p>中,它没有任何属性,更别谈唯一属性了。既然直接访问的愿望落空了,那么只能使用间接的。
通常间接的方法有两种:第一种是找跟它相邻的某个可以快速定位的标签,然后再根据这两个标签tag之间的位置关系进行间接访问。在本次操作中,我们很容易找到<p></p>标签的父标签div拥有唯一的class属性articleContent;第二种方式是一次把所有<p></p>标签都找出来,然后使用挨个遍历的方式,找到目标的标签。事实上,在实际爬取过程中,这两种方式都有使用。
至于哪个更好,我们会根据实际情况进行分析、选择。在这里我们对两种方式都进行演示。
第一种方式:
我们根据<p></p>标签的父标签div拥有唯一的class属性articleContent找到div标签,然后根据父子关系找到p标签,再通过正则表达式对无用内容进行过滤,得到最终结果。
# 请求库
import requests
# 解析库
from bs4 import BeautifulSoup
import re
# 爬取的网页链接
url=r"https://www.ppzuowen.com/book/antushengtonghua/7403.html"
r= requests.get(url)
r.encoding=None
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result, 'lxml')
psg = bs.select('.articleContent > p')
title = bs.select('title')[0].text.split('_')[0]
# print(title)
txt = ''.join(str(x) for x in psg)
res = re.sub(r'<.*?>', "", txt)
result=res.split("(1844年)")[0]
print('标题:',title)
print('原文内容:',result)
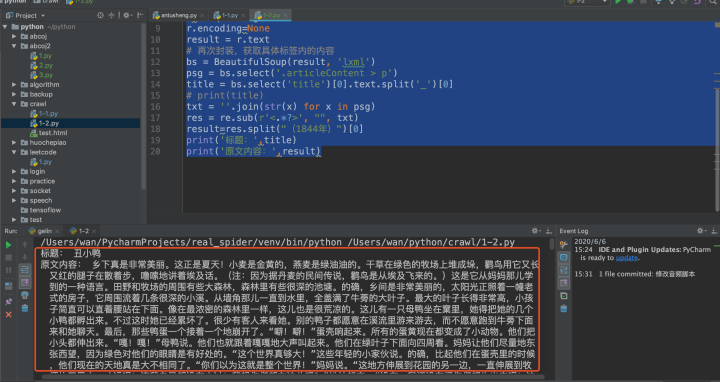
最终的结果:
实现的代码主要分为两部分:第一部分是页面的抓取,如:
# 爬取的网页链接
url=r"https://www.ppzuowen.com/book/antushengtonghua/7403.html"
r= requests.get(url)
r.encoding=None
result = r.text
print(result)

这部分内容与我们之前在浏览器的开发者模式下看到的HTML源码是一摸一样的。
第二部分是页面的解析。
我们之前介绍过HTLML页面本质上是一棵DOM树,我们采用树遍历子节点的方式遍历HTML页面中的标签,如:
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result, 'lxml')
psg = bs.select('.articleContent > p')
这里先将页面信息转为xml的格式文档(注:HTML文档属于一种特殊类型的xml文档),然后根据css的语法找到p标签的内容。
第二种方式:
我们按照最开始的方式写成的代码是这样的:
# 请求库
import requests
# 解析库
from bs4 import BeautifulSoup
# 爬取的网页链接
url=r"https://www.ppzuowen.com/book/antushengtonghua/7403.html"
r= requests.get(url)
r.encoding=None
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result,'html.parser')
# 具体标签
print("---------解析后的数据---------------")
# print(bs.span)
a={}
# 获取已爬取内容中的p签内容
data=bs.find_all('p')
# 循环打印输出
for tmp in data:
print(tmp)
print('********************')
然后我们查看输出的结果却与预期并不相符,是这样的:
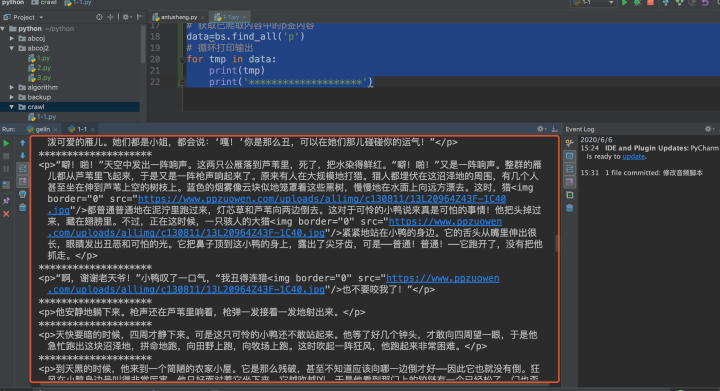
获取的内容是分段的,并且还夹杂很多其他的没用的信息。事实上,这些在实际爬取过程中都是常见的,不是每次爬取都是一步到位,需要不停的调试。
经过分析,我们可以使用表达式对无用信息进行过滤,同时使用字符串拼接函数进行拼接,得到我们预期的内容。
最终的代码如下:
# 请求库
import requests
# 解析库
from bs4 import BeautifulSoup
# 爬取的网页链接
url=r"https://www.ppzuowen.com/book/antushengtonghua/7403.html"
r= requests.get(url)
r.encoding=None
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result,'html.parser')
# 具体标签
print("---------解析后的数据---------------")
# print(bs.span)
a={}
# 获取已爬取内容中的p签内容
data=bs.find_all('p')
result=''
# 循环打印输出
for tmp in data:
if '1844年' in tmp.text:
break
result+=tmp.text
print(result)
以上我们通过两种方式讲解了如何爬取一些简单的网页信息。当然,对于爬取的内容,我们有时不仅是输出,可能还需要进行存储。
通常存储的方式采用的是文件和数据库形式,关于这些内容,我们将在后续进行详细介绍。