在上一章我们介绍了如何使用BeautifulSoup抓取安徒生童话故事《丑小鸭》,通过一个简单的例子,大家应该对于python如何进行爬取网页内容有了一个初步的认识。
在这一章节,我们将延续上一章的内容进行网页内容的爬取,不过我们将难度提高一点,不再只是抓取一个页面,而是抓取很多个页面的内容。
在这里,我们还是以安徒生的童话故事为例进行讲解,不过今天的内容是抓取所有的安徒生童话故事。具体内容如下图所示,链接为www.ppzuowen.com
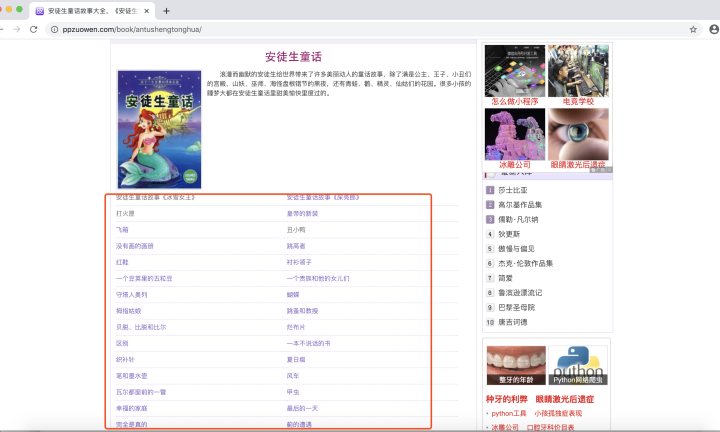
抓取一个单页面很简单,知道对应的url,然后在浏览器的开发者模式下查看需要的内容所在的标签在哪里,然后定位抓取。那么对于多页面的抓取如何进行呢?
思路本质上差不多:首先第一步是找到一个主页面,然后通过主页面与目标页面的关联跳转到对应页面。还记得我们的第一课给的那张爬虫图吗?
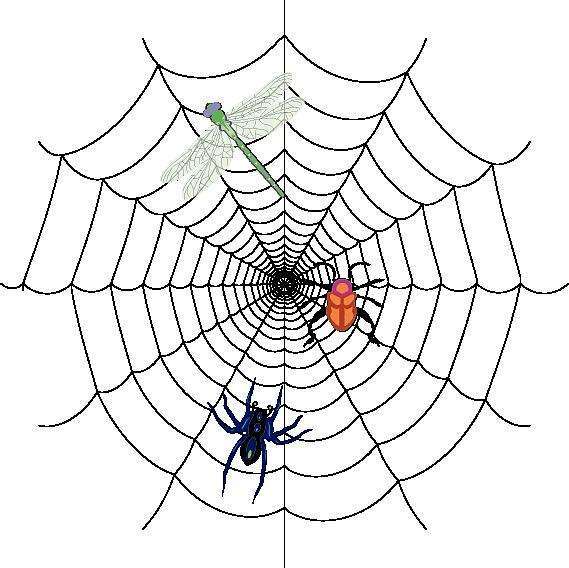
图中的每个节点相当一个页面,节点间是通过蛛丝进行关联的,这个蛛丝通常是一个超链接,即url。
通常,如果要访问整个蛛网有两种思路:第一种是以一个节点为基准,访问与它直连的所有的节点,然后再访问直接的所有节点的所有直连节点,通过这种循环的方式进行访问,我们称之为广度优先搜索;另一种是以一个节点为基准,访问与它直连的某一个节点,然后再访问这个直连节点的某一个直连节点,通过这种递归的方式进行访问,我们称之为深度优先搜索。
通过主页面与目标页面间的超链接,我们能够爬取所有的目标内容。理论上,如果服务器的CPU和内存足够大,我们可以爬取互联网中所有的页面数据。当然,实际中限于算力,我们一般会对爬取的内容进行裁剪,在本文中我们只爬取安徒生童话故事。
根据上面的分析,第二步我们需要做的就是找到所有主页面和目标页面之间的url,然后再对这些url进行再次访问,就可以访问每个页面的内容,最后进行汇总,就能实现我们今天的预期目标。
很显然,今天我们要采用的搜索方式是两种中的广度优先搜索。至于深度优先搜索,我们在后续的例子中进行详细介绍。
在理清了思路之后,我们进行实际操作。
第一步,使用chrome在开发者模式下查看我们需要找的url在哪里。
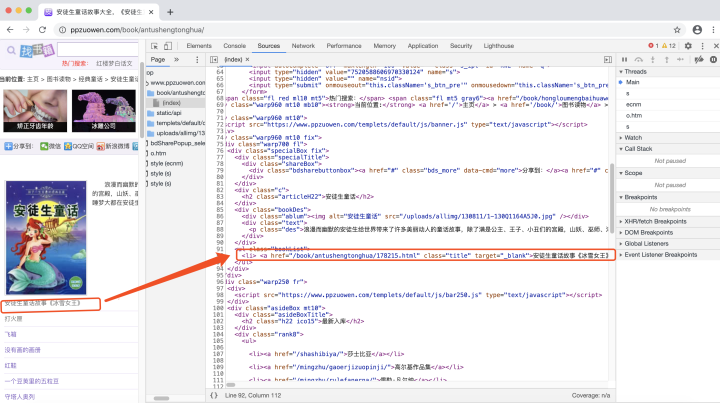
通过分析HTML页面,我们可以发现我们需要找寻的url在a标签的href属性中。并且通过进一步分析,发现我们需要找的url所在的a标签都有同一个class属性,这个class属性值为“title”。
因此第一步定位目标,我们很容易就完成了。事实上,由于前端的开发工程师为了开发的简便和显示的统一,对于同类型的内容通常会使用同样的标签和css样式。
与此对应,对于我们的爬取也是非常简便。
虽然我们能够通过同一个class属性找到我们的目标url,但是我们发现解析出来的url为/book/antushengtonghua/178215.html,而实际的url为https://www.ppzuowen.com/book/antushengtonghua/178215.html。
通过对比分析,我们发现只需要对解析出来的url在前面加一个域名https://www.ppzuowen.com即可。字符串拼接对于我们来说再容易不过,剩下的就是把昨天的代码补充在后面即可。
# 请求库
import requests
# 解析库
from bs4 import BeautifulSoup
# 爬取的网页链接
prefix = r"https://www.ppzuowen.com/"
url = r"https://www.ppzuowen.com/book/antushengtonghua/"
r = requests.get(url)
r.encoding = None
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result, 'html.parser')
# 具体标签
a = {}
# 获取已爬取内容中的script标签内容
data = bs.find_all('a', {"class": "title"})
# 循环打印输出
for link in data:
link = link.get('href')
target_link = prefix + link
print(target_link)

由于昨天的代码可以看作一个单独的功能,因此我们可以把它定义为一个函数,方便后面调用。
def getStory(url):
'''
获取每个童话故事内容
:param url:
:return:
'''
r = requests.get(url)
r.encoding = None
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result, 'html.parser')
# 具体标签
print("---------解析后的数据---------------")
a = {}
# 获取已爬取内容中的p签内容
data = bs.find_all('p')
result = ''
# 循环打印输出
for tmp in data:
if '皮皮作文网' in tmp.text:
break
result += tmp.text
return result
根据以上思路,我们得到的代码如下:
# 请求库
import requests
# 解析库
from bs4 import BeautifulSoup
def getStory(url):
'''
获取每个童话故事内容
:param url:
:return:
'''
r = requests.get(url)
r.encoding = None
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result, 'html.parser')
# 具体标签
print("---------解析后的数据---------------")
a = {}
# 获取已爬取内容中的p签内容
data = bs.find_all('p')
result = ''
# 循环打印输出
for tmp in data:
if '皮皮作文网' in tmp.text:
break
result += tmp.text
return result
# 爬取的网页链接
prefix = r"https://www.ppzuowen.com/"
url = r"https://www.ppzuowen.com/book/antushengtonghua/"
r = requests.get(url)
r.encoding = None
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result, 'html.parser')
# 具体标签
a = {}
# 获取已爬取内容中的script标签内容
data = bs.find_all('a', {"class": "title"})
# 循环打印输出
for link in data:
link = link.get('href')
target_link = prefix + link
# print(target_link)
result=getStory(target_link)
print(result)
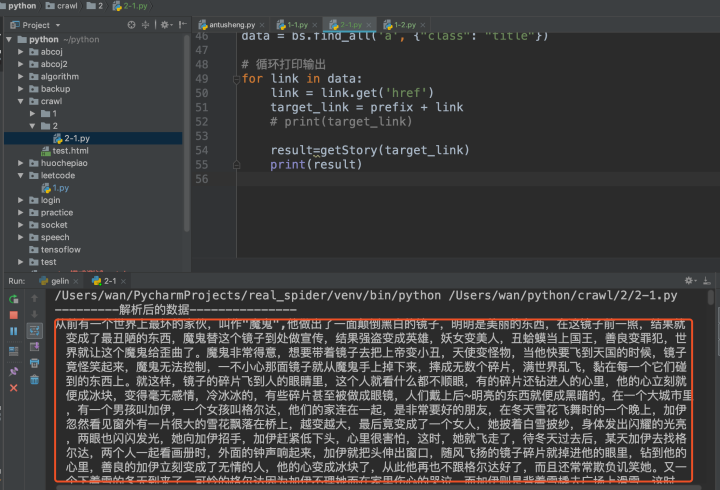
由于打印的内容较多,在控制台上显得的很乱,不方便查看,在这里我们可以使用文件的存起来,文件的名字为童话故事的名字。
修改后的代码如下:
# 请求库
import requests
# 解析库
from bs4 import BeautifulSoup
def getStory(url):
'''
获取每个童话故事内容
:param url:
:return:
'''
r = requests.get(url)
r.encoding = None
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result, 'html.parser')
# 具体标签
print("---------解析后的数据---------------")
a = {}
# 获取已爬取内容中的p签内容
title=bs.find_all('h2', {"class": "articleH2"})[0].text
data = bs.find_all('p')
result = ''
# 循环打印输出
for tmp in data:
if '皮皮作文网' in tmp.text:
break
result += tmp.text
return title,result
# 爬取的网页链接
prefix = r"https://www.ppzuowen.com/"
url = r"https://www.ppzuowen.com/book/antushengtonghua/"
r = requests.get(url)
r.encoding = None
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result, 'html.parser')
# 具体标签
a = {}
# 获取已爬取内容中的script标签内容
data = bs.find_all('a', {"class": "title"})
# 循环打印输出
for link in data:
link = link.get('href')
target_link = prefix + link
# print(target_link)
result=getStory(target_link)
fd=open(result[0]+".txt",'w')
fd.write(result[1])
fd.close()
由于爬取的数据过多,效率不高,我们可以使用多线程进行操作,进一步优化代码性能。修改后的代码如下:
# 请求库
import requests
# 解析库
from bs4 import BeautifulSoup
import threading
from queue import Queue
#定义一个线程安全队列,用来保存数据
que=Queue()
def getStory():
'''
获取每个童话故事内容
:param url:
:return:
'''
while not que.empty():
url=que.get()
r = requests.get(url)
r.encoding = None
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result, 'html.parser')
# 具体标签
print("---------解析后的数据---------------")
a = {}
# 获取已爬取内容中的p签内容
title=bs.find_all('h2', {"class": "articleH2"})[0].text
data = bs.find_all('p')
result = ''
# 循环打印输出
for tmp in data:
if '皮皮作文网' in tmp.text:
break
result += tmp.text
with open(title+".txt", 'w') as fo:
fo.write(result)
# 爬取的网页链接
prefix = r"https://www.ppzuowen.com/"
url = r"https://www.ppzuowen.com/book/antushengtonghua/"
r = requests.get(url)
r.encoding = None
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result, 'html.parser')
# 具体标签
a = {}
# 获取已爬取内容中的script标签内容
data = bs.find_all('a', {"class": "title"})
# 循环打印输出
for link in data:
link = link.get('href')
target_link = prefix + link
que.put(target_link)
print(target_link)
# 定义多线程
for i in range(10):
t = threading.Thread(target=getStory)
t.start()
t.join()
以上我们讲解了如何利用广度优先搜索的方式爬取多个网页信息。同时,为了提高爬取效率,我们采用多线程优化了代码,并将结果存入到文件中,方便后期查看。