在前面的章节中,我们介绍了如何爬取单个网页和多个网页。所提取页面标签内容基本都是使用find方法。
在本章节,我们将对访问页面标签、属性和值进行一个系统的介绍,使用的url是https://www.ppzuowen.com/book/antushengtonghua/7403.html
1.使用绝对路径访问标签
在前面我们已经介绍过,HTML页面本质上是一棵DOM树,形状结构如下图所示:

使用绝对路径访问,就是从HTML页面的根结点html开始,按照顺序访问对应的标签位置。比如,我们需要访问上图中的h1标签,那么我们设置的绝对访问路径就为html.body.div.h1。
根据上面的介绍,我们来做一个实际的练习。
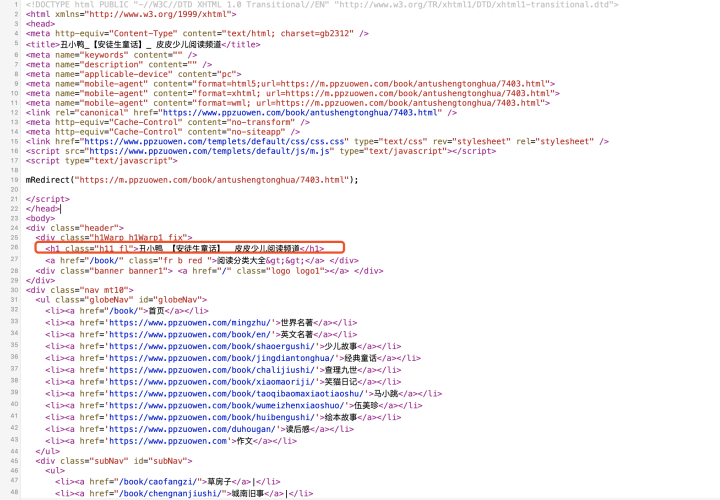
比如我们要访问目标页面中的h1标签,那么我们需要设置的访问路径就是html.body.div.div.h1,获取标签的文本内容使用get_text方法,获取属性的值使用xxTag.attrs[xx]。
我们可以使用urllib包或requests包来抓包。
urllib抓包代码实现如下:
# 请求库
from urllib.request import urlopen
import requests
# 解析库
from bs4 import BeautifulSoup
# 爬取的网页链接
url=r"https://www.ppzuowen.com/book/antushengtonghua/7403.html"
html=urlopen(url)
html.encoding=None
bs=BeautifulSoup(html.read(),'html.parser')
# print(bs.html.title.get_text())
print('标签:',bs.html.div.div.h1)
print('class属性:',bs.html.div.div.h1.attrs['class'])
print('标签值:',bs.html.div.div.h1.get_text())
requests抓包代码实现如下:
# 请求库
from urllib.request import urlopen
import requests
# 解析库
from bs4 import BeautifulSoup
# 爬取的网页链接
url=r"https://www.ppzuowen.com/book/antushengtonghua/7403.html"
html=requests.get(url)
html.encoding=None
bs=BeautifulSoup(html.text,'html.parser')
# print(bs.html.title.get_text())
print('标签:',bs.html.div.div.h1)
print('class属性:',bs.html.div.div.h1.attrs['class'])
print('标签值:',bs.html.div.div.h1.get_text())
得到的结果如下:
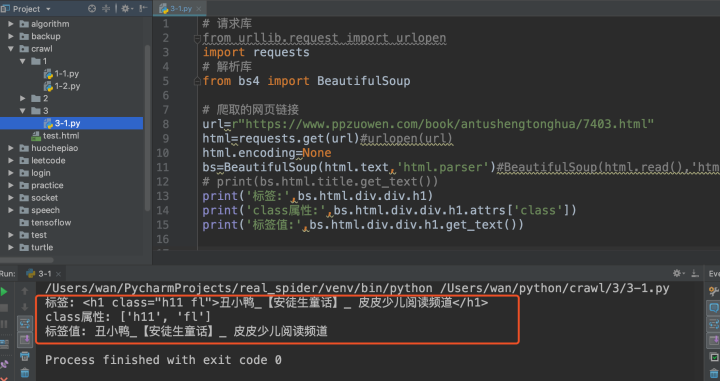
虽然在实际应用中使用绝对路径访问任意标签都是可以做到的,但是万一碰到的页面非常复杂,那么通过这种绝对路径访问标签就显得非常笨重与麻烦,影响工作效率,这是一般会采用相对路径的方式进行访问。
2.相对路径访问
2.1 find() 和 findAll() 访问
在相对路径访问中,BeautifulSoup 里的 find() 和 findAll() 可能是你最常用的两个函数。
借助它们,你可以通过标签的不同属性轻松地过滤 HTML 页面,查找需要的标签组或单个标签。这两个函数非常相似,BeautifulSoup 文档里两者的定义就是这样:
findAll(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)
- 标签参数 tag:可以传一个标签的名称或多个标签名称组成的 Python列表做标签参数。例如,下面的代码将返回一个包含 HTML 文档中所有标题标签的列表:
.findAll({"h1","h2","h3","h4","h5","h6"}) - 属性参数 attributes: 是用一个 Python 字典封装一个标签的若干属性和对应的属性值。例如,下面这个函数会返回 HTML 文档里红色与绿色两种颜色的 span 标签:
.findAll("span", {"class":{"green", "red"}}) - 递归参数 recursive: 是一个布尔变量。你想抓取 HTML 文档标签结构里多少层的信息?如果recursive 设置为 True,findAll 就会根据你的要求去查找标签参数的所有子标签,以及子标签的子标签。如果 recursive 设置为 False,findAll 就只查找文档的一级标签。findAll默认是支持递归查找的(recursive 默认值是 True);一般情况下这个参数不需要设置,除非你真正了解自己需要哪些信息,而且抓取速度非常重要,那时你可以设置递归参数。
- 文本参数 text :它是用标签的文本内容去匹配,而不是用标签的属性。假如想查找前面网页中包含“丑小鸭”内容的标签数量,可以把之前的 findAll 方法换成下面的代码:
name=bs.findAll(text='丑小鸭')
print(len(name))
- 范围限制参数 limit,显然只用于 findAll 方法。find 其实等价于 findAll 的 limit 等于1 时的情形。如果你只对网页中获取的前 n 项结果感兴趣,就可以设置它。但是要注意,这个参数设置之后,获得的前几项结果是按照网页上的顺序排序的,未必是你想要的那前几项。
关键词参数 keyword:可以让你选择那些具有指定属性的标签。例如:
bs.findAll(href="/book/")
虽然关键词参数 keyword 在一些场景中很有用,但是,它是 BeautifulSoup 在技术上做的一个冗余功能。任何用关键词参数能够完成的任务,同样可以用其他技术解决。
例如,下面两行代码是完全一样的:
bs.findAll(href="/book/")
bs.findAll("", {"href":"/book/"})
另外,用 keyword 偶尔会出现问题,尤其是在用 class 属性查找标签的时候,因为 class 是 Python 中受保护的关键字。不过,你可以在 class 后面增加一个下划线解决:
bs.findAll(class_="subNav")
2.2 Tag访问
除了通过find() 和 findAll() 方法查找,还可以通过标签查找。正如前面反复强调的,HTML本质是一棵DOM树,因此可以通过某个tag去访问它的父节点、兄弟节点和子节点。
- 处理子标签和其他后代标签
在 BeautifulSoup 库里,孩子(child)和后代(descendant)有显著的不同:子标签就是一个父标签的下一级,而后代标签是指一个父标签下面所有级别的标签。
例如,tr 标签是 table标签的子标签,而 tr、th、td标签都是 table 标签的后代标签。所有的子标签都是后代标签,但不是所有的后代标签都是子标签。
一般情况下,BeautifulSoup 函数总是处理当前标签的后代标签。
bs.p
如果你只想找出子标签,可以用 .children 标签。例如:
ls=bs.find('ul',{'class':'globeNav'}).children
for child in ls:
print(child)
- 处理兄弟标签
next_sibling 和 previous_sibling 函数可以用来返回当前节点的后一个弟节点和前一个兄节点。与 next_siblings 和 previous_siblings的作用类似,只是它们返回的是一组标签,而不是单个标签。例如:
brother=bs.find('div',{'class':'nav mt10'}).div.previous_siblings
for bro in brother:
print('兄节点:',bro)
brother=bs.find('div',{'class':'nav mt10'}).ul.next_siblings
for bro in brother:
print('弟节点:',bro)
- 父标签处理
BeautifulSoup 的父标签查找函数,parent 和 parents。例如:
parents=bs.find('div',{'class':'nav mt10'}).parents
for parent in parents:
print('父节点:',parent)
2.3 通过CSS选择器获取Tag对象
- 通过标签名查找:
bs.select('a') #返回所有的a标签 list - 通过类名查找:
bs.select('.sister') #返回所有包含class="sister"的标签 list
bs.select('a.sister')
- 通过 id 名查找:
bs.select('#link1') #返回所有包含 id="link1"的标签 list
bs.select("p#link1")
- 组合查找:
bs.select('p #link1') #查找所有 p 标签中,id 等于 link1的标签 注意区分soup.select('p#link1')
bs.select("html head title") or bs.select("body a") #逐层查找
bs.select("p > a") #直接子标签查找 注意是子标签不是子孙标签
- 通过是否存在某个属性和属性的值来查找:
bs.select('a[href]')
bs.select('a[href="http://example.com/elsie"]')
bs.select('a[href^="Example Domain"]') # ^= 开头
bs.select('a[href$="tillie"]') # $= 结尾
bs.select('a[href*=".com/el"]') # *= 包含
除此之外,有时查找的对象只需要满足某一类条件即可,这时可以结合正则表达式进行模糊查找。
关于正则表达式的编写,可以参照前面python基础部分的内容,这里不再赘述。