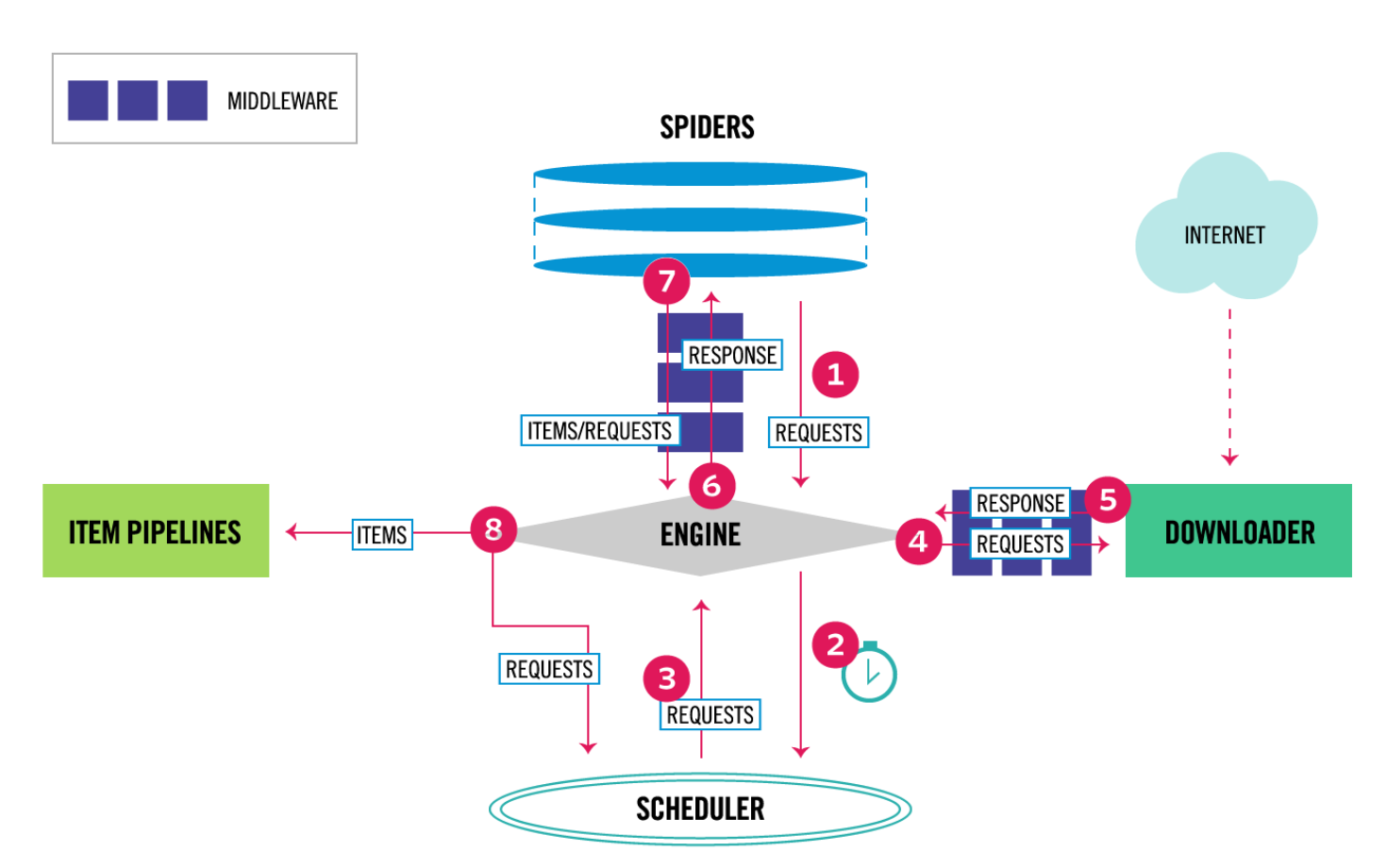
- 首先Spider发送第一个需要爬取的Requests给Engine,然后跳到4
- Engine在Scheduler中对Requests进行调度, 并请求下一个需要爬取的Requests.
- Scheduler接受请求后, 返回下一个Requests给Engine.
- Engine收到Requests后, Requests经过Downloader Middlewares的process_request()后, 传给Downloader.
- Downloader收到Requests后, 开始下载网页, 当网页下载完成, 返回Response(包括了加载完成的网页), Response经过Downloader Middlewares的process_response()后,传给Engine
- Engine从Downloader收到Response后, Response经过Spider Middleware的process_spider_input()后, 传给Spider.
- Spider处理完Response后,返回items和一个新的Requests, 他们经过Spider Middleware的process_spider_output()后, 传给Engine.
- Engine收到items和Requests后, 首先发送处理后的Item给Pipline, 然后发送处理后的Requests给Scheduler, 并请求下一个需要爬取的Requests.
- 不断重复以上2,3,4,5,6,7,8的内容, 当Scheduler中没有requests时退出.
-
Scheduler
- 从Engine接受Request并将他们入队,以便之后Engine请求时提供给Engine
-
Engine
- 负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件
-
Downloader
- 负责获取页面数据并提供给Engine,而后提供给spider
-
Spiders
- 用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类. 每个spider负责处理一个特定(或一些)网站
-
Item Pipeline
- 负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)
-
Downloader middlewares
- 在Engine及Downloader之间的特定钩子(specific hook),处理Downloader传递给Engine的response
- 常用方法
- from_crawler(cls, crawler)
- 返回cls, 用于读取设置爬虫实例配置,和将signal和函数绑定
- process_request(self, request, spider)
- 返回None或Resquest或Response或抛出IgnoreRequest异常
- 返回None则继续处理这个request
- 返回Response,则将Response给Engine
- 返回Resquest则将会处理这个返回的Resquest
- process_response(self, request, response, spider)
- 返回Resquest或Response或抛出IgnoreRequest异常
- 返回Resquest则暂停MiddleWares, 并重新调度返回的Request以便将来下载.
- 返回Response将继续后续处理
- process_exception(self, request, exception, spider)
- 返回None或Resquest或Response,
- 返回None则调用其他的process_exception(),
- 返回Resquest则暂停MiddleWares, 并重新调度返回的Request以便将来下载.
- 返回Response将继续后续处理
- from_crawler(cls, crawler)
- 适用情况
- 在其发送到Downloader之前, 处理Request,(即在将Request发送到网站之前)
- 在其传递给Spider前, 修改处理Request
- 发送一个新的Request,而不是将接收到的Response传递给Spider
- 在没有抓取到网页的情况下将Response传递给Spider
- 丢弃一些Requests
-
Spider middlewares
-
在Engine及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)
-
常用方法
- from_crawler(cls, crawler)
- 返回cls, 用于读取设置爬虫实例配置,和将signal和函数绑定
- process_spider_input(self, response, spider)
- 返回None或抛出异常给process_spider_exception, 用于处理即将传递给spider的response
- process_spider_output(self, response, result, spider)
- 返回Request或dict或Item, 用于处理即将传递给Engine的response
- process_spider_exception(self, response, exception, spider)
- 返回None或Request或dict或Item, 处理spider或process_spider_input抛出的异常
- 返回None则将调用其他的process_spider_exception用于处理异常
- process_start_requests(self, start_requests, spider)
- 返回requests, 用于处理第一个request,即步骤1, 和process_spider_output类似
- spider_opened(self, spider)
- from_crawler(cls, crawler)
-
适用情况
- 对Spider callbacks输出的后期处理(更改/添加/删除Request或Item)
- 对start_requests的后期处理
- 处理Spider异常
- 对于某些Request, 根据response的内容调用errback而不是callback
-
-
参考链接 https://doc.scrapy.org/en/latest/topics/architecture.html#component-scheduler
-
参考链接 https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/architecture.html