http://impala.apache.org/
Apache Impala is the open source, native analytic database
for Apache Hadoop. Impala is shipped by Cloudera, MapR, Oracle, and Amazon.
Do BI-style Queries on Hadoop
Impala provides low latency低延迟 and high concurrency 高并发for BI/analytic queries on Hadoop (not delivered by batch frameworks such as Apache Hive). Impala also scales linearly, even in multitenant environments.
在Hadoop上执行BI风格的查询
Impala为Hadoop上的BI /分析查询提供了低延迟和高并发性(不是由Apache Hive等批处理框架提供的)。
即使在多租户环境中,Impala也能线性扩展。
Unify Your Infrastructure
Utilize the same file and data formats and metadata, security, and resource management frameworks as your Hadoop deployment—no redundant infrastructure or data conversion/duplication.
统一基础设施 与Hadoop部署一样,利用相同的文件和数据格式以及元数据,安全性和资源管理框架 - 无需冗余基础架构或数据转换/复制。
Implement Quickly
For Apache Hive users, Impala utilizes the same metadata and ODBC driver. Like Hive, Impala supports SQL, so you don't have to worry about re-inventing the implementation wheel.
快速实施 对于Apache Hive用户,Impala使用相同的元数据和ODBC驱动程序。与Hive一样,Impala支持SQL,因此您不必担心重新实现轮子。
Count on Enterprise-class Security
Impala is integrated with native Hadoop security and Kerberos for authentication, and via the Sentry module, you can ensure that the right users and applications are authorized for the right data.
依靠企业级安全 Impala与本地Hadoop安全和Kerberos进行身份验证集成,并且通过Sentry模块,您可以确保正确的用户和应用程序获得正确数据的授权。
Retain Freedom from Lock-in
Impala is open source (Apache License).
保持自由锁定
Impala是开源的(Apache许可证)。
Expand the Hadoop User-verse
With Impala, more users, whether using SQL queries or BI applications, can interact with more data through a single repository and metadata store from source through analysis.
展开Hadoop User-verse
通过Impala,无论使用SQL查询还是BI应用程序,更多用户都可以通过单个存储库和元数据存储从源代码通过分析与更多数据进行交互。
Overview
Impala raises the bar for SQL query performance on Apache Hadoop while retaining a familiar user experience. With Impala, you can query data, whether stored in HDFS or Apache HBase – including SELECT, JOIN, and aggregate functions – in real time. Furthermore, Impala uses the same metadata, SQL syntax (Hive SQL), ODBC driver, and user interface (Hue Beeswax) as Apache Hive, providing a familiar and unified platform for batch-oriented or real-time queries. (For that reason, Hive users can utilize Impala with little setup overhead.)
概观
Impala提高了Apache Hadoop上SQL查询性能的标准,同时保留了熟悉的用户体验。使用Impala,您可以实时查询数据,
无论是存储在HDFS还是Apache HBase中 - 包括SELECT,JOIN和聚合函数。
此外,Impala与Apache Hive一样使用相同的元数据,SQL语法(Hive SQL),
ODBC驱动程序和用户界面(Hue Beeswax),
为面向批处理或实时查询提供熟悉且统一的平台。
(出于这个原因,Hive用户可以在安装开销很小的情况下使用Impala。)
Architecture
To avoid latency, Impala circumvents MapReduce to directly access the data through a specialized distributed query engine that is very similar to those found in commercial parallel RDBMSs. The result is order-of-magnitude faster performance than Hive, depending on the type of query and configuration.
设计
为了避免延迟,Impala规避MapReduce通过专用分布式查询引擎直接访问数据,该引擎非常类似于商业并行RDBMS中的数据。
结果是性能比Hive更高,这取决于查询和配置的类型。
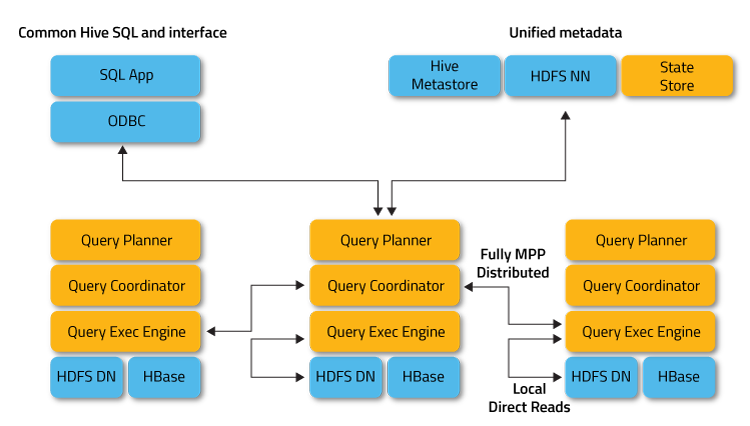
There are many advantages to this approach over alternative approaches for querying Hadoop data, including::
- Thanks to local processing on data nodes, network bottlenecks are avoided.
- A single, open, and unified metadata store can be utilized.
- Costly data format conversion is unnecessary and thus no overhead is incurred.
- All data is immediately query-able, with no delays for ETL.
- All hardware is utilized for Impala queries as well as for MapReduce.
- Only a single machine pool is needed to scale.
这种方法与查询Hadoop数据的其他方法相比有许多优点,包括::
由于数据节点上的本地处理,避免了网络瓶颈。
可以使用单一的,开放的和统一的元数据存储。
昂贵的数据格式转换是不必要的,因此不会产生开销。
所有数据都可以立即查询,而不会延迟ETL。
所有硬件都用于Impala查询以及MapReduce。
只需要一个机器池来扩展。


