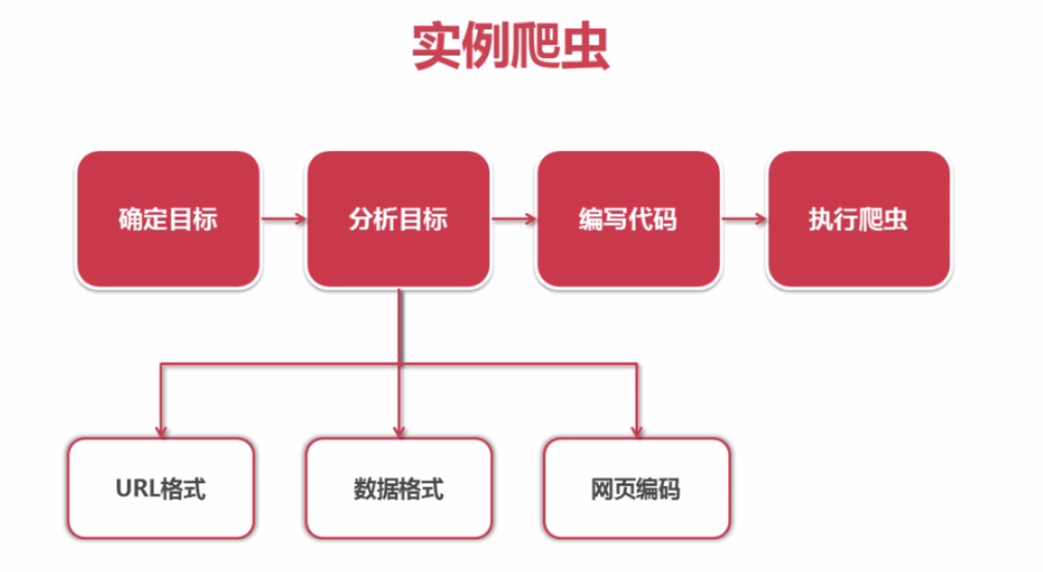
实战演练:爬取百度百科1000个页面的数据

对于新手来说,可以把spider_main.py代码中的try和except去掉,运行报错就会在控制台出现,根据错误去调试自己的程序
发现以下错误:
requests.exceptions.TooManyRedirects: Exceeded 30 redirects
错误提示是requests库有太多的重定向:超过了30个重定向。
查找别人的解决方式:
我是通过steam的appid来进行遍历的,但是steam不是所有appid都对应一个游戏,也就是说有一些是空的。这种情况下steam会重定向至steam主页,就会产生这个问题。
所以,我最终的解决方案就是仅请求不允许重新定向,因为重新定向中没有我需要的信息。在requests请求中添加一个对应的字段就ok了:
req=requests.get(url,headers=header,allow_redirects=False)这样就不会弹出上面的错误提示了,但是也关闭了重定向的功能。
发现以下错误:
Traceback (most recent call last):
File "D:/PycharmProjects/test/baike_spider/spider_main.py", line 39, in <module>
obj_spider.craw(root_url)
File "D:/PycharmProjects/test/baike_spider/spider_main.py", line 20, in craw
new_urls, new_data = self.parser.parse(new_url, html_cont)
TypeError: 'NoneType' object is not iterable
在20行上加入输出
html_cont = self.downloader.download(new_url) # content存放下载的url
print(html_cont)
new_urls, new_data = self.parser.parse(new_url, html_cont)
输出为空None,说明错误在downloader中
使用第三方包requests会导致302重定向问题,原因不明
改为使用urllib的request
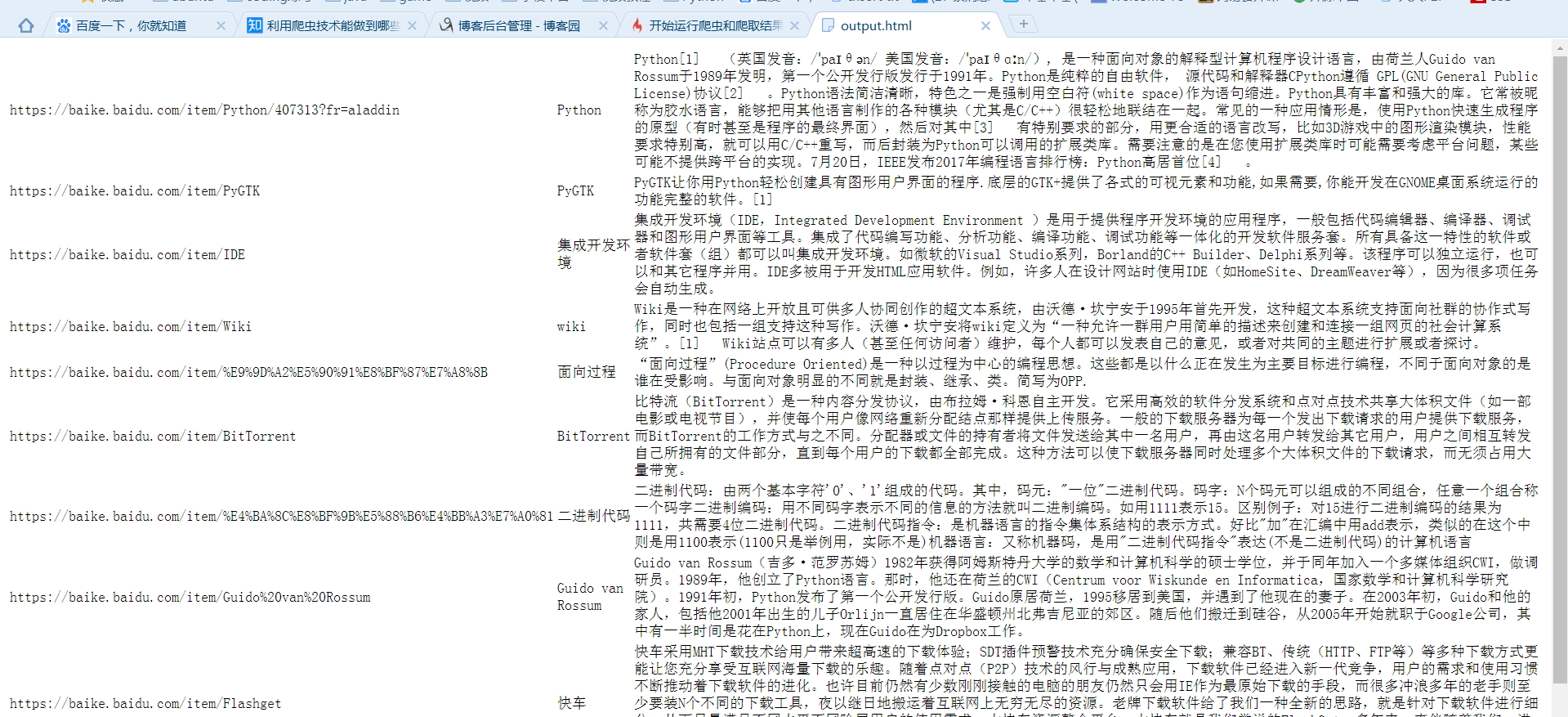
成功爬取
生成的html文件直接打开是乱码,用txt打开则正常
加入语句fout.write('<meta charset="utf-8">')后输出正常
爬取时会遇到两个问题中止程序。a:网址中含有中文,b:有些百科词条中'summary'节点是空的,程序没判断导致get_text出错
a:网址中含有中文使用
url_ = quote(url, safe=string.printable)
解决问题
b:有些百科词条中'summary'节点是空的,程序没判断导致get_text出错添加判断语句解决:
if summary_node is not None:
res_data['summary'] = summary_node.get_text()
查看拼接url:
print('url拼接:', page_url, new_url, new_full_url) # 查看如何拼接
输出为:
url拼接: https://baike.baidu.com/item/Python/407313?fr=aladdin /item/史记·2016?fr=navbar https://baike.baidu.com/item/史记·2016?fr=navbar
可知:
通过正则表达式
links = soup.find_all('a', href=re.compile(r"/item/"))
获得的是/item/及后面部分如/item/史记·2016?fr=navbar