一、读写分离
什么是数据库读写分离?
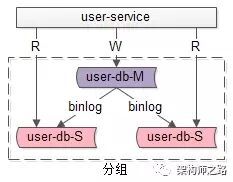
答:一主多从,读写分离,主动同步,是一种常见的数据库架构,一般来说:
-
主库,提供数据库写服务
-
从库,提供数据库读服务
-
主从之间,通过某种机制同步数据,例如mysql的binlog
一个组从同步集群通常称为一个“分组”。
分组架构究竟解决什么问题?
答:大部分互联网业务读多写少,数据库的读往往最先成为性能瓶颈,如果希望:
-
线性提升数据库读性能
-
通过消除读写锁冲突提升数据库写性能
此时可以使用分组架构。
一句话,分组主要解决“数据库读性能瓶颈”问题,在数据库扛不住读的时候,通常读写分离,通过增加从库线性提升系统读性能。
二、水平切分
什么是数据库水平切分?
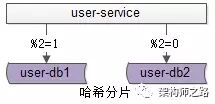
答:水平切分,也是一种常见的数据库架构,一般来说:
-
每个数据库之间没有数据重合,没有类似binlog同步的关联
-
所有数据并集,组成全部数据
-
会用算法,来完成数据分割,例如“取模”
一个水平切分集群中的每一个数据库,通常称为一个“分片”。
水平切分架构究竟解决什么问题?
答:大部分互联网业务数据量很大,单库容量容易成为瓶颈,如果希望:
-
线性降低单库数据容量
-
线性提升数据库写性能
此时可以使用水平切分架构。
一句话总结,水平切分主要解决“数据库数据量大”问题,在数据库容量扛不住的时候,通常水平切分。
三、为什么不喜欢读写分离
对于互联网大数据量,高并发量,高可用要求高,一致性要求高,前端面向用户的业务场景,如果数据库读写分离:
-
数据库连接池需要区分:读连接池,写连接池
-
如果要保证读高可用,读连接池要实现故障自动转移
-
有潜在的主库从库一致性问题
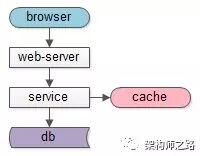
-
如果面临的是“读性能瓶颈”问题,增加缓存可能来得更直接,更容易一点
-
关于成本,从库的成本比缓存高不少
-
对于云上的架构,以阿里云为例,主库提供高可用服务,从库不提供高可用服务
所以,上述业务场景下,楼主建议使用缓存架构来加强系统读性能,替代数据库主从分离架构。
当然,使用缓存架构的潜在问题:如果缓存挂了,流量全部压到数据库上,数据库会雪崩。不过幸好,云上的缓存一般都提供高可用的服务。
四、总结
-
读写分离,解决“数据库读性能瓶颈”问题
-
水平切分,解决“数据库数据量大”问题
-
对于互联网大数据量,高并发量,高可用要求高,一致性要求高,前端面向用户的业务场景,微服务缓存架构,可能比数据库读写分离架构更合适
双机热备:
为了确保数据库产品的稳定性,很多数据库拥有双机热备功能。也就是,第一台数据库服务器,是对外提供增删改查业务的生产服务器;第二台数据库服务器,仅仅接收来自第一台服务器的备份数据
读写分离:
主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),从数据库处理SELECT查询操作。
数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
简单的说就是把对数据库读和写的操作分开对应不同的数据库服务器,这样能有效地减轻数据库压力,也能减轻io压力。主数据库提供写操作,从数据库提供读操作。当主数据库进行写操作时,数据要同步到从的数据库,这样才能有效保证数据库完整性。
读写分离诞生原因:
1、为了确保数据库产品的稳定性,很多数据库拥有双机热备功能。也就是,第一台数据库服务器,是对外提供增删改查业务的生产服务器;第二台数据库服务器,仅仅接收来自第一台服务器的备份数据(注意,不同数据库产品,第一台数据库服务器,向第二台数据库服务器发送备份数据的方式不同)。当第一台数据库崩溃后,第二台数据库服务器,可以立即上线来代替第一台数据库服务器,并且,在第一台数据库服务器崩溃后,宝贵的数据,依然会存在于第二台数据库服务器里(根据目前业界的备份数据发送方式来看,当第一台数据库崩溃后,第一台数据库里的仍然会有少量的新数据,没能来得及被发送到第二台数据库服务器,所以,这部分数据就丢失了)。
2、 一般来说,为了配置方便,以及稳定性,这两台数据库服务器,都用的是相同的配置(思考一下,如果两台服务器的配置不同,会导致什么结果)。
3、从上文的描述中,大家能看到,在实际运行中,第一台数据库服务器的压力,远远大于第二台数据库服务器。因此,很多人希望合理利用第二台数据库服务器的空闲资源。那么,第二台数据库服务器能做些什么事情呢?
4、从数据库的基本业务来看,数据库的操作无非就是增删改查这4个操作。但对于“增删改”这三个操作,如果是双机热备的环境中做,一台机器做了这三个操作的某一个之后,需要立即将这个操作,同步到另一台服务器上。单向的同步,不复杂。但如果两台机器都需要向对方进行同步,那逻辑就非常复杂,而且还会大大降低性能。(从保证ACID特性的角度,思考一下为什么双向同步会非常复杂且低性能?而单向同步却不会?)出于这个原因,第二台备用的服务器,就只做了查询操作。进一步,为了降低第一台服务器的压力,干脆就把查询操作全部丢给第二台数据库服务器去做,第一台数据库服务器就只做增删改了。
5、到这一步,就实现了所谓的读写分离。这样做,缺点也非常明显了。本来第二台数据库服务器,是用来做热备的,它就应该在一个压力非常小的环境下,保证运行的稳定性。而读写分离,却增加了它的压力,也就增加了不稳定性。因此,读写分离,实质上是一个在资金比较缺乏,但又需要保证数据安全的需求下,在双机热备方案上,做出的一种折中的扩展方案。
优缺点
(1)数据的实时性差 : 数据不是实时同步到自读服务器上的,当数据写入主服务器后,要在下次同步后才能查询到(负载均衡集群是实时同步的,集群的同步过程是在事务环境下并发完成的)。
(2)数据量大时同步效率差:单表数据量过大时插入和更新因索引,磁盘IO等问题,性能会变的很差。
(3)同时连接多个(至少两个)数据库:至少要连接到两个数据数据库,实际的读写操作是在程序代码中完成的,容易引起混乱
(4)读具有高性能高可靠性和可伸缩:只读服务器,因为没有写操作,会大大减轻磁盘IO等性能问题,大大提高效率;
只读服务器可以采用负载均衡,主数据库发布到多个只读服务器上实现读操作的可伸缩性。
(注意,不同数据库产品,第一台数据库服务器,向第二台数据库服务器发送备份数据的方式不同)
mysql只要是通过二进制日志来复制数据。通过日志在从数据库重复主数据库的操作达到复制数据目的。这个复制比较好的就是通过异步方法,把数据同步到从数据库。
show master STATUS
show slave STATUS
问题1:
mysql怎么样通过二进制日志来复制数据,同步数据的? 假如往主数据库删除数据时再返回记录列表,会不会存在从用来读的数据库数据还没有删除的情况?
答:
所谓的日志复制就是告诉读服务器主服务器做了哪些操作。然后读服务器按照日志也做一遍。延迟是肯定的。属数据库同步无论如何快,也有一个过程。只要这个延迟在可以接受的范围之内就可以。
“假如往主数据库删除数据时再返回记录列表,会不会存在从用来读的数据库数据还没有删除的情况?”
这种情况就是在一个服务器上也会出现的。除非你把事务等级调整到串行读。
做读写分离的时候,延迟的想象肯定是存在的,并且有时候还会出现同步失败,需要通过补偿机制来保证数据的完整性,这个时候延迟就更明显了,所以一般实际应用过程中,对于数据的实时性和正确性要求很强的业务点,写库应该同时作为数据基准库,直接从写库读取数据,而读库的职责只是分担大部分的实时性要求不高的业务点的读操作而已吧?
其实延时数秒对提交非实时订单之类的应用并没什么关系。比如你去网站买书。你提交订单后系统只是告诉你订单已经被提交,正在处理。初步处理后可以在历史记录里看到。那么你看这条信息的时间就有好几秒。那么后台异步只要在这几秒后能让你看到,对你来说没有任何延时。
不同系统对延时的要求是不同的,有些要求非常快的系统对存储速度的要求非常高,但是这些系统毕竟是少数。觉大多数系统对一定的系统延迟都是可以接受的。
问题2:
主从复制中不可避免的由于延迟导致的业务逻辑问题,如何处理?
答:
如果比较着急的地方可以直接读主库,不着急的地方读从库。
由于主从复制的局限性,你可以死命的提高从的性能,无限扩展从的配置,但也不能做到一点都不延迟。能不能在业务层面上想想办法,比如两次交易的时间差有个限制啥的。
实时性强的不应该用主从,应该是集群
实时性要求不是那么严格的时候,复制完全可以满足要求。通常在网络环境和事务大小都比较好的情况下,复制的延时是完全感觉不到的。
可以在SHOW SLAVE STATUS里面查看主从的延时。
比如你在CSDN上面发了个帖子,3秒后转到本帖子。这样的情况各大论坛都这样的。3秒,足够把主的数据写到从上面了。
在机房的服务器都是1000M以上带宽,网络不存在延时,把从机器的硬件配置加上去,CPU和内存也不存在延时。
1) 关键业务查主机(你要求的转入帖子查看页面)
2) 分布数据库解决查主机引起的性能下降
在实现上有两种方式:
- 应用层实现 在应用层,比如使用SpringJDBC/myBatis/Hibernate访问数据库时配置多数据源,这些组件会通过算法把请求分流到不同的数据源。
- 代理实现 这种方式是在应用层和数据库集群之间添加一个代理服务,应用层访问代理,代理根据请求类型(读/写)自动分流到不同的数据库服务器。
Mysql读写分离实现的三种方式
1 程序修改mysql操作类
可以参考PHP实现的Mysql读写分离,阿权开始的本项目,以php程序解决此需求。
优点:直接和数据库通信,简单快捷的读写分离和随机的方式实现的负载均衡,权限独立分配
缺点:自己维护更新,增减服务器在代码处理
2 amoeba
参考官网:http://amoeba.meidusa.com/
优点:直接实现读写分离和负载均衡,不用修改代码,有很灵活的数据解决方案
缺点:自己分配账户,和后端数据库权限管理独立,权限处理不够灵活
3 mysql-proxy
参考 mysql-proxy。
优点:直接实现读写分离和负载均衡,不用修改代码,master和slave用一样的帐号
缺点:字符集问题,lua语言编程,还只是alpha版本,时间消耗有点高
如果你不能安装软件来解决读写分离,那可以尝试阿权的项目解决思路。
如果你可以安装软件,那amoeba是不错的,mysql-proxy不太建议,目前只有alpha版本,效率还不太理想,amoeba目前在阿里巴巴是内部项目,正在生产环境使用的。
http://database.51cto.com/art/201801/563213.htm
https://blog.csdn.net/anzhen0429/article/details/77014565