评价一个算法
当算法预测结果有很大误差的时候,可以进行什么样的尝试:
1. 增大训练集样本数目
2. 更少的特征变量
3. 多项式特征
4. 试着减小或增大lambda

机器学习诊断
确定某些方式是可以改善算法性能而某些并不能够改善

评估假设
把训练样本三七分成训练集和测试集

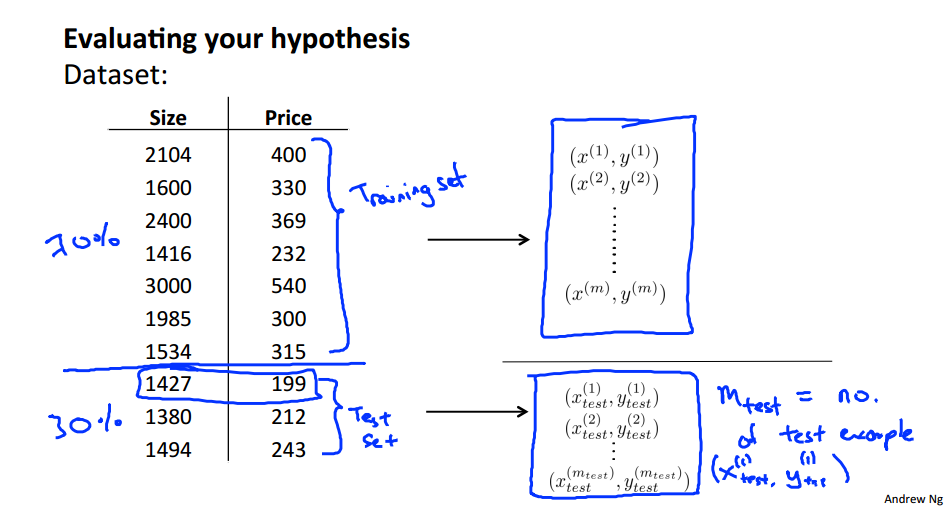
但是我们在选择多项式的阶数时,用同一组训练集去训练,根据测试集得到的误差的大小,选择误差最小的,可是有些不公平




更好的方式是分成训练集、交叉验证集和测试集三部分:



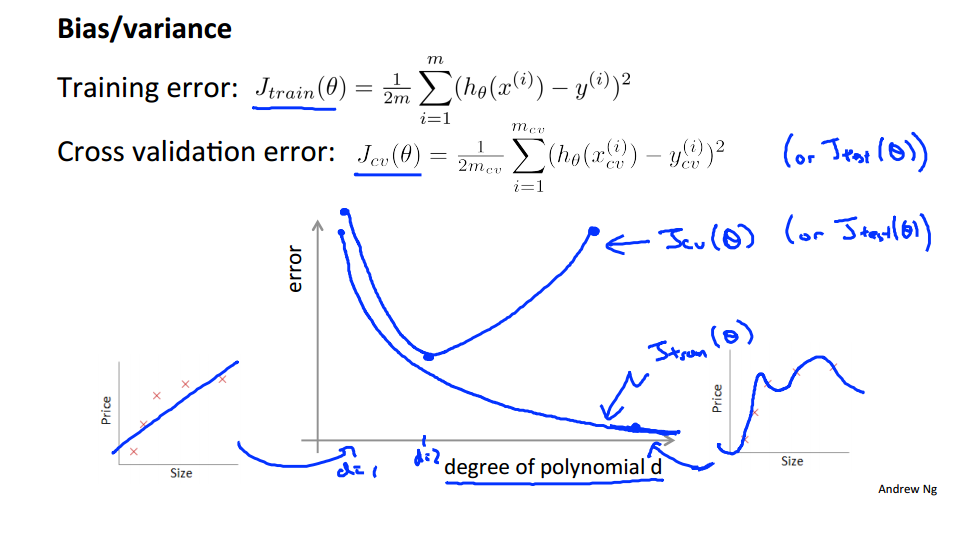
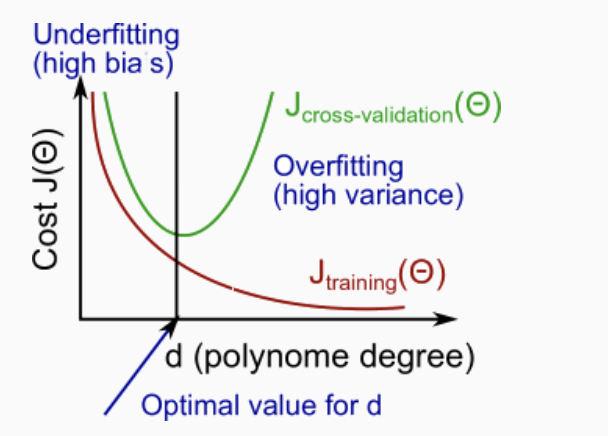
偏差和方差


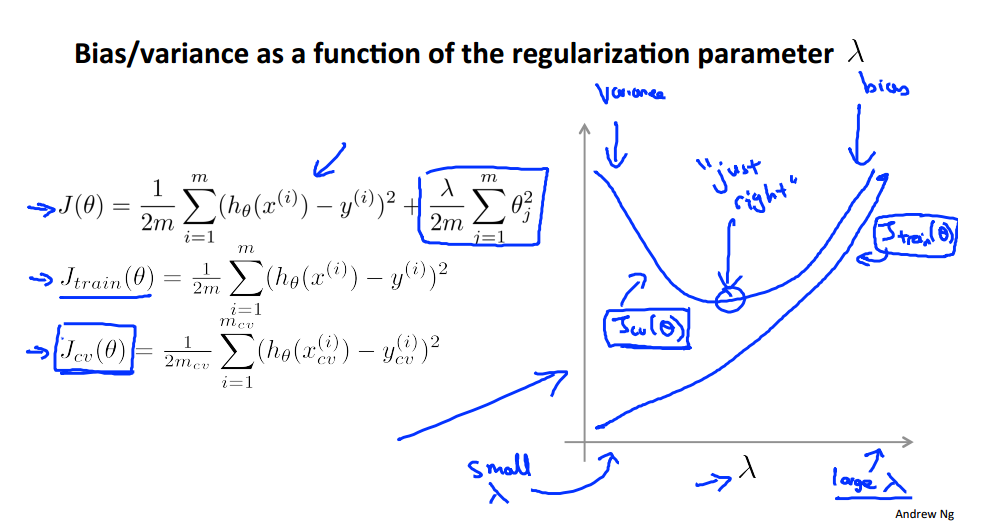
正则化和方差、偏差的关系
正则化可以有效防止过拟合的原因:



lambda和偏差方差的关系,λ小的时候过拟合,大的时候差拟合:
学习曲线
判断偏差方差的方法

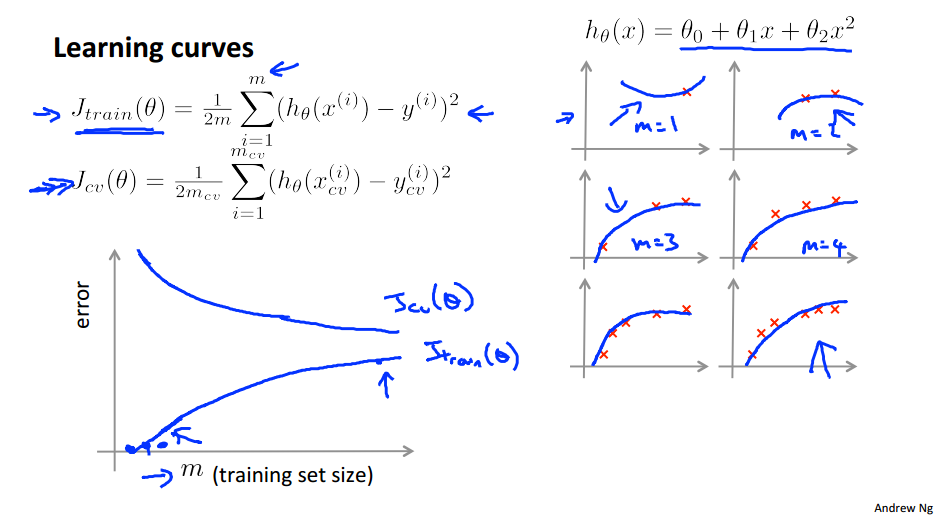


根据方差偏差决定next move

神经网络

垃圾邮件分类器
特征向量的构建过程:

降低误差的方法:
1. 收集大量数据
2. 复杂的特征变量
3. 复杂的算法
4. 单词的识别:discount 和 discounts 是否应该被认为相同?

吴老师推荐的机器学习方法
在24小时内用一种你可以实现的方法去解决问题,并用交叉验证集去测试
绘制学习曲线,分析是否存在高偏差或方差的问题
误差分析

误差分析的作用:
假设500个训练集中有100个分类错误,你可以手动地检查这100个错误,并进行分类:
(1)邮件的种类
(2)有什么新的特征可以加入进去
例如100封邮件中有53封钓鱼邮件,其中不寻常的标点符号规律有32封,我就可以把这个特征作为新的特征变量加入进去

数值化评估的重要性
唯一的解决方法是试一试,用数字的形式进行衡量

偏斜类
癌症预测中如果我们的误差仅仅有1%,我们会以为这是一个分类效果很不错的模型,但是如果真实情况下只有0.5%为癌症患者,我们的预测效果就很糟糕了。这种阳性样本远远大于阴性样本的分类中,较少的那一类便叫做偏斜类。

偏斜类可以用准确率和召回率来进行计算:
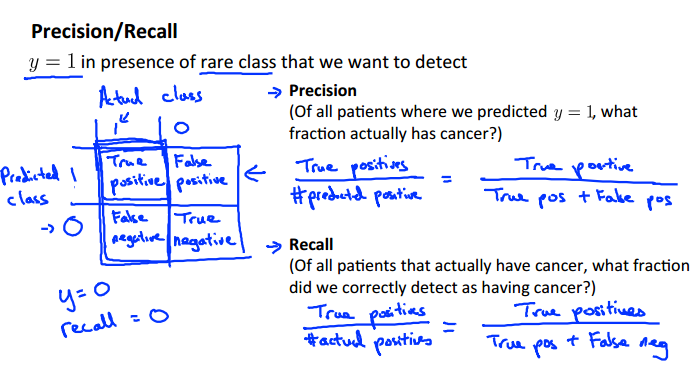
查准率和召回率的关系
当我们的算法设定一个不同的阈值,比如我们想在有0.7的把握判断这个人有癌症的时候作出决定告诉患者,那么此时的就会有高查准率和低召回率,即找到的患者中患有癌症的比例较高但由于设定的阈值高,全部患癌人群中被成功找出的比例就低;同理,较低的阈值则会导致相反的状况发生。

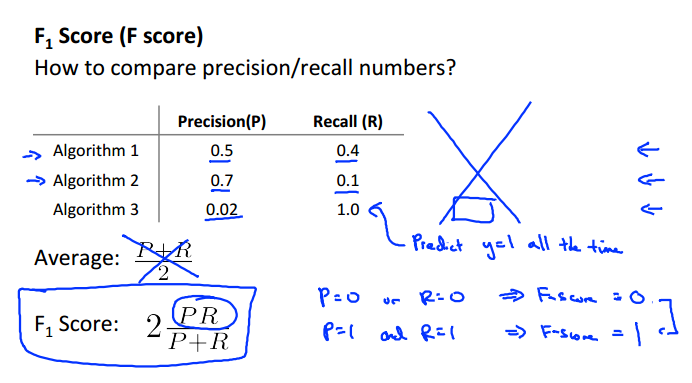
那么我们在不同的算法下如何判断应该使用哪种阈值合适呢?可以用F1-score来计算:
大数据集的问题
有个实验表明四种性能不同的算法在不同数量的数据集上跑出来的准确率随着数据集的增大而增大

优秀的算法:low bia algotithms
large training set : 过拟合的可能性低,low variance
