聚类——无监督学习的一种算法
K-means算法 最为广泛使用的聚类算法
选择两个聚类中心
簇分配:根据每个样本更接近哪个聚类中心进行样本的分配
簇中心移动:计算出所有的红点类的均值点,移动原始聚类中心到这个点,蓝点类同理
进行不断地迭代直到收敛
输入:K个簇类和训练集样本数据
注意:不需要X0项,为n维向量

算法的描述:
如果最终有个簇中心没有任何点分配给他那么直接移除就可以

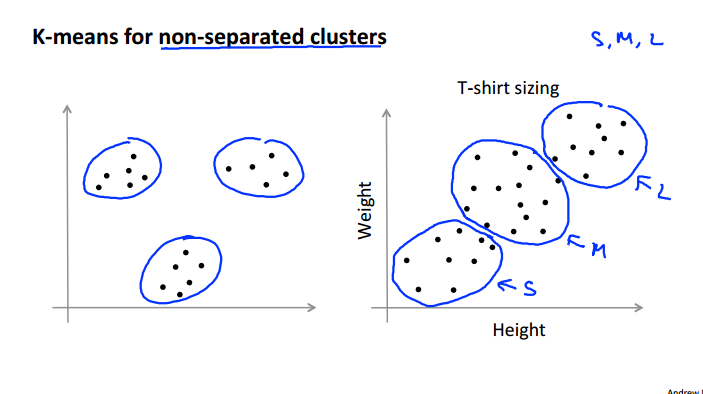
K-means常常适用于右侧这种看不出来结构的混乱的数据的聚类的,所以并不是都是左图如此理想的环境
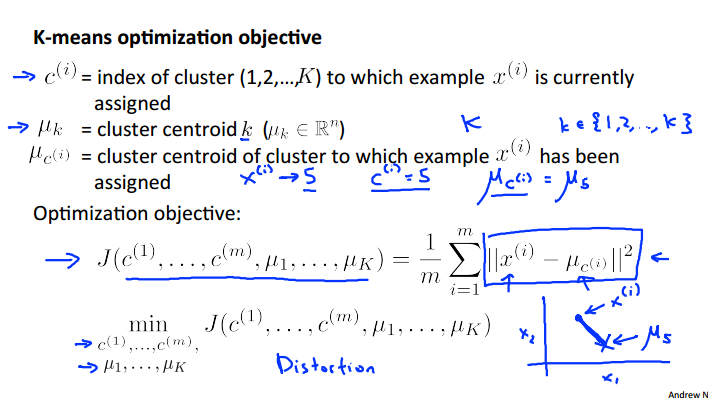
最优化的目标函数
参数们:
每个训练样本被归类的簇号
簇中心编号
x所属的族的族编号
优化目标:每个样本到所属的簇中心的距离的累加和越小越好
随机初始化
K 应该 小于M
随机选择K个训练样本作为初始的簇中心


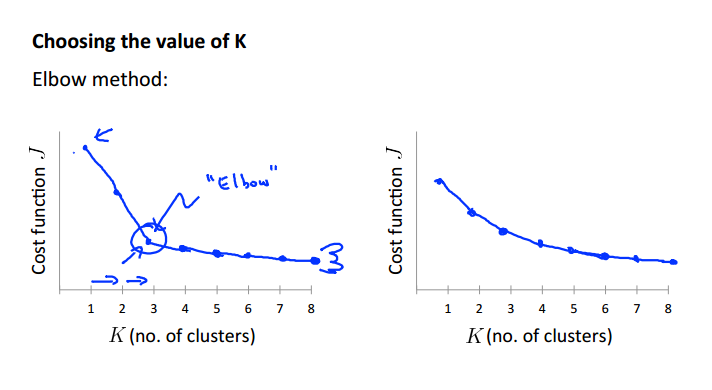
如何选择K的数目
看聚类产生的结果来手动选择聚类的数目
肘部法则:绘制随着聚类数目增多的cost曲线,选择位于手肘的位置的类数
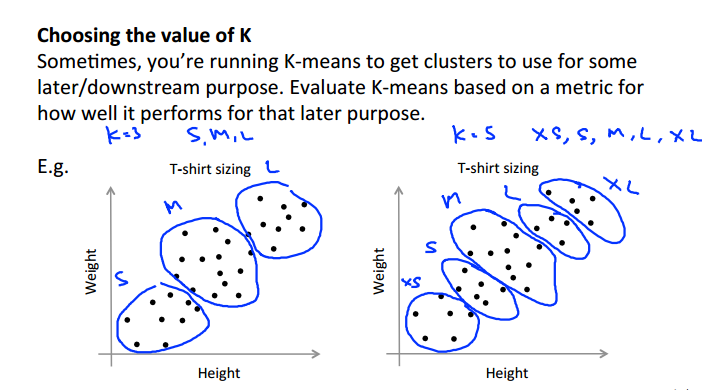
衣服尺码的选择
第二种非监督算法 维数约减
一个物体用厘米英寸两种变量表示,其实冗余了,可以降维一次
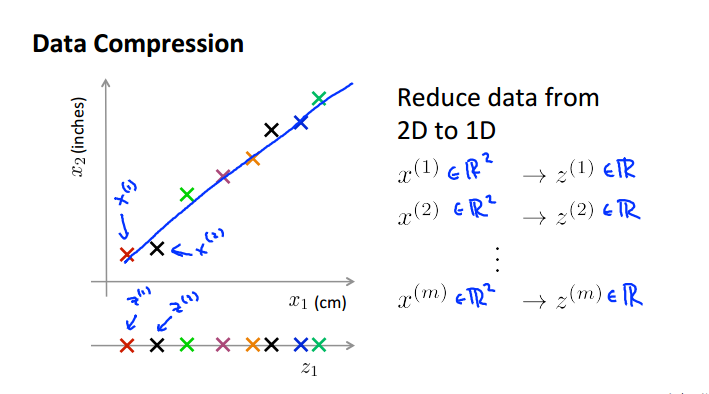

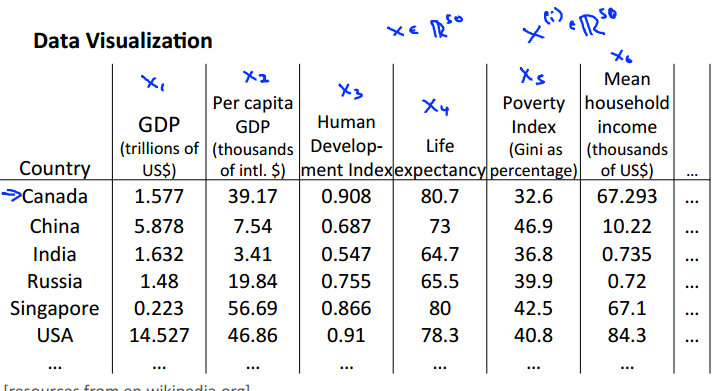
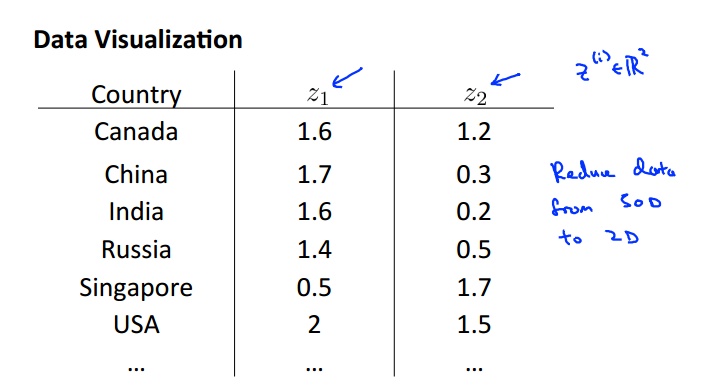
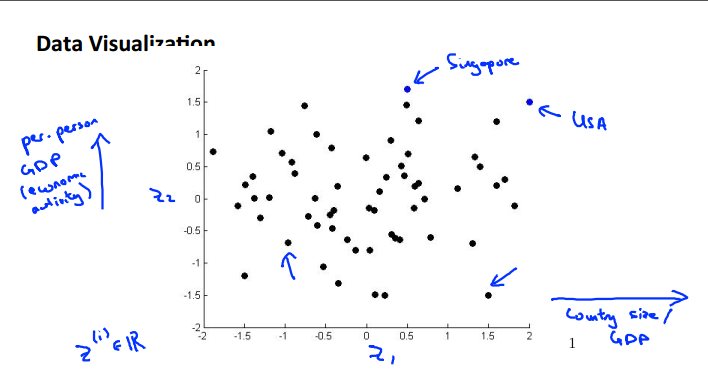
可视化数据
从高纬度降到2/3维从而可以实现可视化
主成分分析法降维
找到一条线把所有的点投射到这条直线上,每个点到投影点的距离非常小,也就是找一个低维度的面,使这些小蓝色断线投影误差(的和最小)
首先一定要进行特征维度的均值归一化
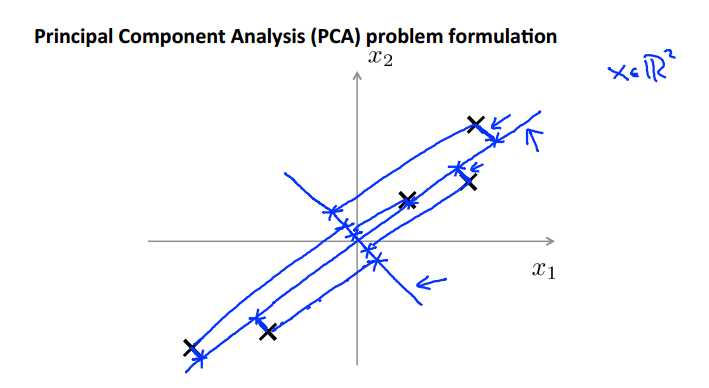
找到一个方向进行投影
在3D上则是找到两个方向确定一个平面

主成分分析的算法实现:
一组训练数据首先进行特征缩放或者均值归一

计算协方差矩阵的特征向量,svd 奇异值分解 或者 eig命令都可以求特征向量
我们需要的是U矩阵,即为我们需要的u1,u2 and so on ,只需要选取前K列值就可以


总结

PCA作为数据压缩的算法,如何从压缩的数据还原到压缩之前的数据呢?
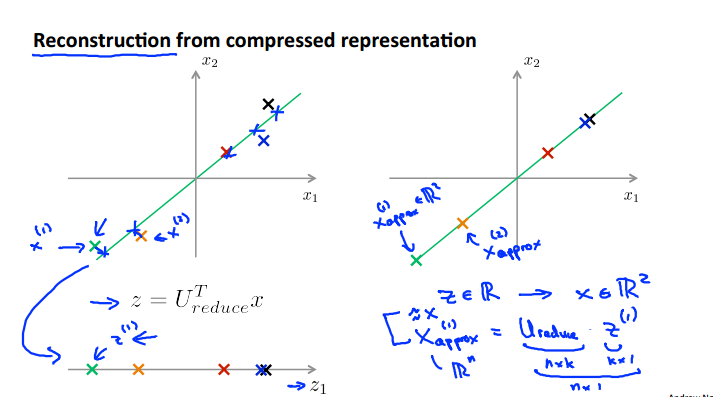
如何选择K最为合适呢?

使用K=1 进行PCA的计算,看是否差异性能够被保留,否则就增大K的值直到选择一个能保留差异性的K值
S是一个N*N的矩阵,对角线以外的元素都是0
左边这个计算公式可以用右边的S矩阵的公式来更简单地计算出来
也就是1- K个对角线元素/N个对角线元素的和

总结一下计算的方法:

PCA如何在实际操作中提高算法的速度
10000维度的特征向量如何降维
首先得到一组没有y的训练样本
然后得到一组降了维度的z和新的训练集

PCA的应用
压缩
加速学习算法

不合适的应用:避免过拟合

当你发现你的运行空间不够或者效果不够好时才需要考虑用PCA来处理一下
